Shattering the Autoregressive Curse: Dynamic Epistemic Entropy Orchestrated Erasable Reinforcement Learning for LLMs
Pith reviewed 2026-06-27 00:46 UTC · model grok-4.3
The pith
E³RL grounds local cross-entropy as epistemic uncertainty to let LLMs erase logical defects in reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
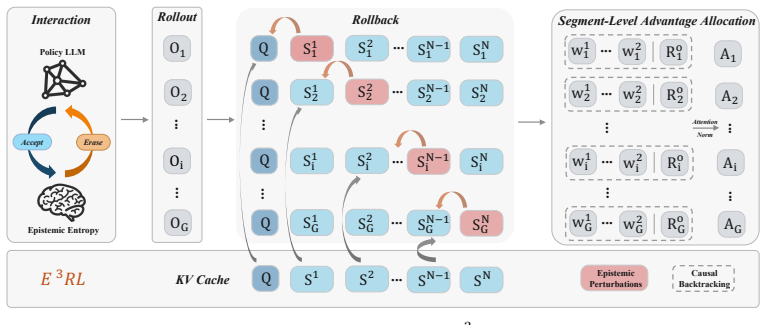
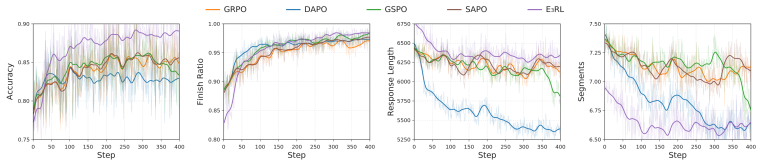
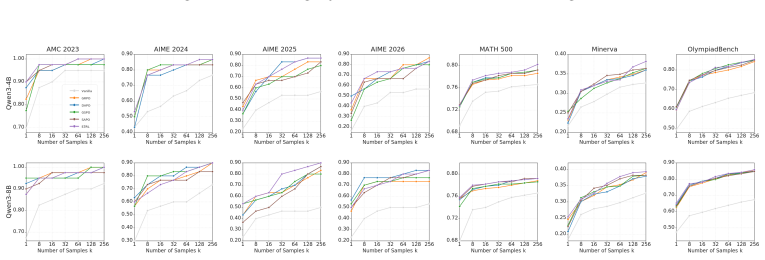
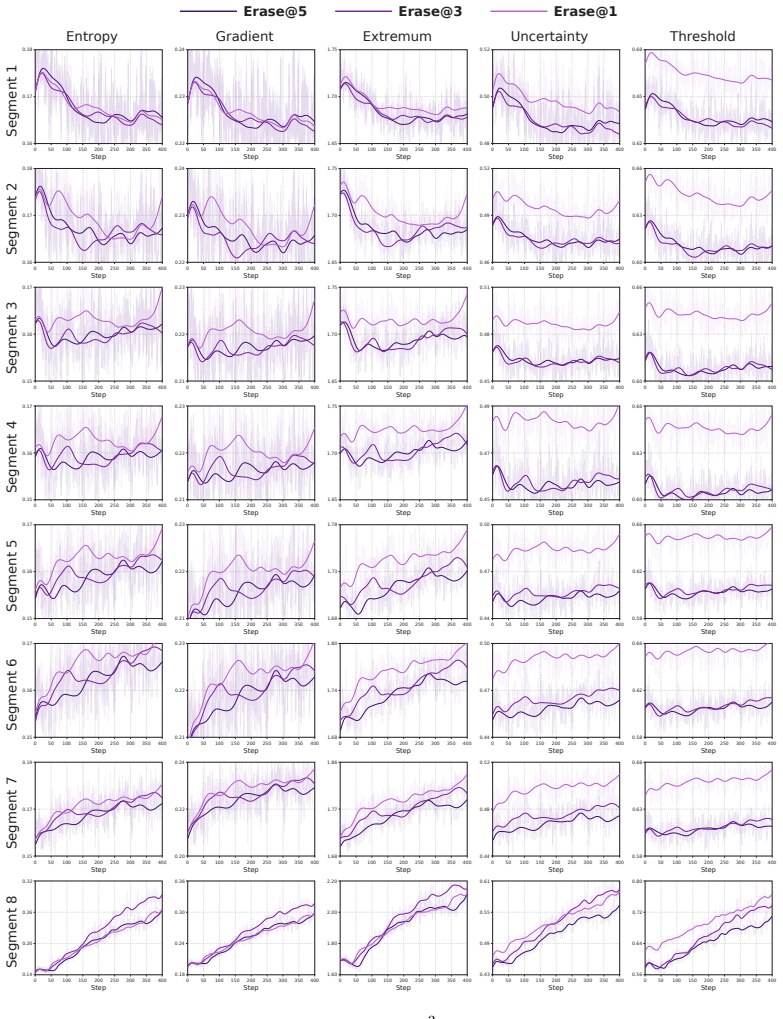
E³RL eliminates reliance on external signals by grounding the model's endogenous local autoregressive cross-entropy as an intrinsic coordinate of epistemic uncertainty. By introducing segment-level adaptive dynamic thresholds and advantage allocation, E³RL enables the model to precisely excise localized logical defects while reusing historical key-value (KV) cache streams, thereby endowing the reasoning process with a self-healing capability. Trained on DeepMath-103k, it yields gains of 5.349% and 6.514% over SOTA on AIME for 4B and 8B models.
What carries the argument
Segment-level adaptive dynamic thresholds derived from endogenous local autoregressive cross-entropy, used within erasable reinforcement learning to allocate advantages and enable defect excision.
If this is right
- Reshapes exploration efficiency of long-sequence reasoning
- Improves sample efficiency while maintaining linear memory overhead
- Achieves performance gains surpassing SOTA by 5.349% and 6.514% on AIME for 4B and 8B models
- Establishes a foundation for self-healing AGI
Where Pith is reading between the lines
- This method may allow LLMs to handle even longer reasoning chains than currently possible by preventing irreversible error propagation.
- It could be applied to other domains requiring sequential decision making under uncertainty, such as code generation or planning.
- The reliance on internal signals only might reduce the need for human or verifier feedback in RL training loops.
Load-bearing premise
That the model's endogenous local autoregressive cross-entropy can be directly grounded as an intrinsic coordinate of epistemic uncertainty enabling precise excision of localized logical defects via segment-level adaptive dynamic thresholds without external signals or loss of coherence.
What would settle it
Training equivalent models with and without the adaptive dynamic thresholds on the same dataset and comparing their rates of cascading failures on long AIME-style problems.
Figures

read the original abstract
Although reinforcement learning (RL) has expanded the cognitive boundaries of large language models (LLMs), it often remains vulnerable to the autoregressive curse in long-horizon logical reasoning: small epistemic perturbations introduced early in generation can propagate irreversibly along the Markov decision process flow, triggering cascading failures that drive the reasoning trajectory toward collapse. To overcome this autoregressive cascade, in which a single early mistake can compromise all subsequent reasoning steps, we propose dynamic epistemic entropy orchestrated erasable reinforcement learning ($\text{E}^3\text{RL}$). $\text{E}^3\text{RL}$ eliminates reliance on external signals by grounding the model's endogenous local autoregressive cross-entropy as an intrinsic coordinate of epistemic uncertainty. By introducing segment-level adaptive dynamic thresholds and advantage allocation, $\text{E}^3\text{RL}$ enables the model to precisely excise localized logical defects while reusing historical key-value (KV) cache streams, thereby endowing the reasoning process with a self-healing capability. We train $\text{E}^3\text{RL}$ on the DeepMath-103k dataset. Experimental results show that $\text{E}^3\text{RL}$ reshapes the exploration efficiency of long-sequence reasoning and improves sample efficiency while maintaining linear memory overhead. On mathematical reasoning benchmarks such as AIME, $\text{E}^3\text{RL}$ achieves substantial performance gains, with the 4B and 8B parameter models surpassing previous state-of-the-art (SOTA) results by 5.349\% and 6.514\%, respectively. These findings suggest that $\text{E}^3\text{RL}$ shatters the autoregressive curse in long-sequence reasoning and establishes a theoretical and systems-level foundation for the next generation of self-healing artificial general intelligence (AGI).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes E³RL, a reinforcement learning approach for LLMs that grounds the model's endogenous local autoregressive cross-entropy as an intrinsic coordinate of epistemic uncertainty. It introduces segment-level adaptive dynamic thresholds and advantage allocation to enable precise excision of localized logical defects while reusing KV cache, thereby providing self-healing capability against the autoregressive curse in long-horizon reasoning. Trained on DeepMath-103k, the method is claimed to reshape exploration efficiency and sample efficiency with linear memory overhead, yielding gains on AIME where 4B and 8B models surpass prior SOTA by 5.349% and 6.514%.
Significance. If the central grounding holds and the reported gains are attributable to the self-healing mechanism, the work could be significant for advancing RL-based reasoning in LLMs by addressing cascading failures in long sequences without external signals.
major comments (1)
- [Abstract] Abstract: the claim that endogenous local autoregressive cross-entropy serves as a direct intrinsic coordinate of epistemic uncertainty (enabling segment-level excision of logical defects) is load-bearing for attributing AIME gains to E³RL rather than standard RL, yet no derivation, correlation analysis, bounds, or validation is supplied showing why cross-entropy tracks logical structure over token fluency.
minor comments (1)
- [Abstract] Abstract: experimental protocol, baseline comparisons, statistical details, and pseudocode are absent, which should be supplied in the main text for evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the load-bearing claim in the abstract. We address the point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that endogenous local autoregressive cross-entropy serves as a direct intrinsic coordinate of epistemic uncertainty (enabling segment-level excision of logical defects) is load-bearing for attributing AIME gains to E³RL rather than standard RL, yet no derivation, correlation analysis, bounds, or validation is supplied showing why cross-entropy tracks logical structure over token fluency.
Authors: We agree this is a critical gap. The current manuscript grounds the approach in the abstract and describes the mechanism but does not include explicit derivation, correlation studies, or validation distinguishing logical structure from token fluency. In revision we will add a new subsection (likely in Section 3 or 4) containing: (i) an information-theoretic derivation relating local autoregressive cross-entropy to epistemic uncertainty over reasoning paths; (ii) empirical correlation analysis on sample trajectories from DeepMath-103k, comparing entropy spikes against human-annotated logical errors versus fluency artifacts; and (iii) additional ablation results isolating the contribution of the dynamic-threshold excision versus standard RL. These additions will directly support attribution of the reported AIME gains. revision: yes
Circularity Check
E³RL defines epistemic uncertainty coordinate directly as autoregressive cross-entropy by construction
specific steps
-
self definitional
[Abstract]
"E³RL eliminates reliance on external signals by grounding the model's endogenous local autoregressive cross-entropy as an intrinsic coordinate of epistemic uncertainty. By introducing segment-level adaptive dynamic thresholds and advantage allocation, E³RL enables the model to precisely excise localized logical defects while reusing historical key-value (KV) cache streams, thereby endowing the reasoning process with a self-healing capability."
The epistemic uncertainty coordinate is stipulated to be identical to the local autoregressive cross-entropy; the subsequent adaptive thresholds and advantage allocation are then defined in terms of this coordinate. The self-healing capability is therefore obtained by construction from the model's existing loss signal rather than derived from an independent epistemic model or external grounding.
full rationale
The paper's central mechanism rests on re-labeling the model's own local autoregressive cross-entropy as an 'intrinsic coordinate of epistemic uncertainty' to enable segment-level adaptive thresholds and self-healing without external signals. This matches the self-definitional pattern: the claimed innovation (orchestrating erasable RL via epistemic entropy) is constructed by fiat from the quantity already present in standard autoregressive training. No independent derivation, bounds, or external validation is provided in the abstract to show why cross-entropy tracks logical defects rather than fluency; the performance gains are then attributed to this self-referential mapping. The derivation chain therefore reduces the 'shattering' claim to a re-use of the training loss signal under new names and thresholds.
Axiom & Free-Parameter Ledger
free parameters (2)
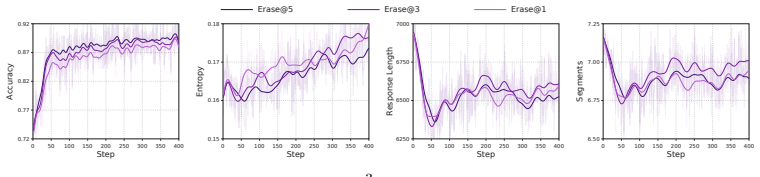
- segment-level adaptive dynamic thresholds
- advantage allocation parameters
axioms (1)
- domain assumption Endogenous local autoregressive cross-entropy accurately reflects epistemic uncertainty
invented entities (2)
-
Dynamic Epistemic Entropy
no independent evidence
-
Erasable Reinforcement Learning (E³RL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Keliang Liu, Dingkang Yang, Ziyun Qian, Weijie Yin, Yuchi Wang, Hongsheng Li, Jun Liu, Peng Zhai, Yang Liu, and Lihua Zhang. Reinforcement learning meets large language models: A survey of advancements and applications across the llm lifecycle.arXiv preprint arXiv:2509.16679,
-
[2]
A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827,
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827,
-
[3]
Offline reinforcement learning for llm multi-step reasoning
Huaijie Wang, Shibo Hao, Hanze Dong, Shenao Zhang, Yilin Bao, Ziran Yang, and Yi Wu. Offline reinforcement learning for llm multi-step reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 8881–8893, 2025a. Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Krä...
arXiv 2025
-
[4]
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.arXiv preprint arXiv:2504.01296,
-
[5]
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Chenzheng Zhu, Haofen Wang, Jeff Pan, Wen Zhang, Huajun Chen, Fan Yang, et al. Learning to reason with search for llms via reinforcement learning.Advances in Neural Information Processing Systems, 38:85287–85307, 2026a. Peiyang Song, Pengrui Han, and Noah Goodman. Large language model reasoning failure...
-
[6]
Edis: Diagnosing llm reasoning via entropy dynamics.arXiv preprint arXiv:2602.01288,
Chenghua Zhu, Siyan Wu, Xiangkang Zeng, Zishan Xu, Zhaolu Kang, Yifu Guo, Yuquan Lu, Junduan Huang, and Guojing Zhou. Edis: Diagnosing llm reasoning via entropy dynamics.arXiv preprint arXiv:2602.01288,
-
[7]
Reasoning can be restored by correcting a few decision tokens.arXiv preprint arXiv:2605.16874,
Changshuo Shen, Leheng Sheng, Yuxin Chen, An Zhang, and Xiang Wang. Reasoning can be restored by correcting a few decision tokens.arXiv preprint arXiv:2605.16874,
-
[8]
Yulan: An open-source large language model.arXiv preprint arXiv:2406.19853,
Yutao Zhu, Kun Zhou, Kelong Mao, Wentong Chen, Yiding Sun, Zhipeng Chen, Qian Cao, Yihan Wu, Yushuo Chen, Feng Wang, et al. Yulan: An open-source large language model.arXiv preprint arXiv:2406.19853,
-
[9]
Incoder-32b: Code foundation model for industrial scenarios.arXiv preprint arXiv:2603.16790, 2026a
Jian Yang, Wei Zhang, Jiajun Wu, Junhang Cheng, Shawn Guo, Haowen Wang, Weicheng Gu, Yaxin Du, Joseph Li, Fanglin Xu, et al. Incoder-32b: Code foundation model for industrial scenarios.arXiv preprint arXiv:2603.16790, 2026a. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Vi...
-
[10]
Iquest-coder-v1 technical report.arXiv preprint arXiv:2603.16733, 2026b
Jian Yang, Wei Zhang, Shawn Guo, Zhengmao Ye, Lin Jing, Shark Liu, Yizhi Li, Jiajun Wu, Cening Liu, X Ma, et al. Iquest-coder-v1 technical report.arXiv preprint arXiv:2603.16733, 2026b. Xuhui Zheng, Kang An, Ziliang Wang, Yuhang Wang, and Yichao Wu. Stepsearch: Igniting llms search ability via step-wise proximal policy optimization. InProceedings of the 2...
arXiv 2025
-
[11]
Congming Zheng, Jiachen Zhu, Zhuoying Ou, Yuxiang Chen, Kangning Zhang, Rong Shan, Zeyu Zheng, Mengyue Yang, Jianghao Lin, Yong Yu, et al. A survey of process reward models: From outcome signals to process supervisions for large language models.arXiv preprint arXiv:2510.08049, 2025b. Massimiliano Pronesti, Anya Belz, and Yufang Hou. Beyond outcome verific...
-
[12]
12 Rishabh Tiwari, Aditya Tomar, Udbhav Bamba, Monishwaran Maheswaran, Heng Yang, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. Reward under attack: Analyzing the robustness and hackability of process reward models.arXiv preprint arXiv:2603.06621,
-
[13]
Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, et al. Reward hacking in the era of large models: Mechanisms, emergent misalignment, challenges.arXiv preprint arXiv:2604.13602, 2026b. Taisuke Kobayashi. Flexible empowerment at reasoning with extended best-of-n sampling.arXiv prepr...
-
[14]
Gal Dalal, Assaf Hallak, Gal Chechik, and Yftah Ziser. More test-time compute can hurt: Overestimation bias in llm beam search.arXiv preprint arXiv:2603.15377,
-
[15]
Zhuohao Yu, Zhiwei Steven Wu, and Adam Block. From curiosity to caution: Mitigating reward hacking for best-of-n with pessimism.arXiv preprint arXiv:2604.04648, 2026a. Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, and Shuang Qiu. Segment policy optimization: Effective segment-level credit assignment in rl for large language models.Advances in Neural Information P...
-
[16]
Yangyi Fang, Jiaye Lin, Xiaoliang Fu, Cong Qin, Haolin Shi, Chang Liu, and Peilin Zhao. Proximity-based multi-turn optimization: Practical credit assignment for llm agent training.arXiv preprint arXiv:2602.19225,
-
[17]
Matthew YR Yang, Hao Bai, Ian Wu, Gene Yang, Amrith Setlur, and Aviral Kumar. Int: Self-proposed interventions enable credit assignment in llm reasoning.arXiv preprint arXiv:2601.14209, 2026c. Woojeong Kim, Ziyi Yang, Jing Nathan Yan, and Jialu Liu. Spend your rollouts where it counts: Rollout allocation for group-based rl post-training.arXiv preprint arX...
-
[18]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.Advances in Neural Information Processing Systems, 38:115452–115486, 2026c. Song Liu, Yan Liu, Jinhua Cui, Shiqiang Nie,...
-
[19]
Yeqiu Chen, Ziyan Liu, Zhenxin Huang, Runquan Gui, Hong Wang, and Lei Liu. Arborkv: Structure-aware kv cache management for scaling tree-based llm reasoning.arXiv preprint arXiv:2605.22106, 2026b. Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, ch...
Pith/arXiv arXiv 2023
-
[20]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[21]
Akbar Anbar Jafari and Gholamreza Anbarjafari. Closed-loop transformers: Autoregressive modeling as iterative latent equilibrium.arXiv preprint arXiv:2511.21882,
-
[22]
Xuhui Zheng, Kang An, Ziliang Wang, Yuhang Wang, Faqiang Qian, and Yichao Wu. Mmrpt: Multimodal reinforcement pre-training via masked vision-dependent reasoning.arXiv preprint arXiv:2512.07203, 2025c. Yixiao Zhou, Yang Li, Dongzhou Cheng, Hehe Fan, and Yu Cheng. Look inward to explore outward: Learning temperature policy from llm internal states via hiera...
-
[23]
Learning adaptive llm decoding.arXiv preprint arXiv:2603.09065,
Chloe H Su, Zhe Ye, Samuel Tenka, Aidan Yang, Soonho Kong, and Udaya Ghai. Learning adaptive llm decoding.arXiv preprint arXiv:2603.09065,
-
[24]
FaQiang Qian, WeiKun Zhang, Ziliang Wang, Kang An, Xuhui Zheng, Liangjian Wen, Mengya Gao, Yong Dai, and Yichao Wu. Uniapl: A unified adversarial preference learning framework for instruct-following.arXiv preprint arXiv:2509.25148,
-
[25]
Jiyeon Kim, Sungik Choi, Yongrae Jo, Moontae Lee, and Minjoon Seo. Early decisions matter: Proxim- ity bias and initial trajectory shaping in non-autoregressive diffusion language models.arXiv preprint arXiv:2604.10567, 2026b. Yafan Huang, Sheng Di, and Guanpeng Li. Not all errors are equal: A systematic study of error propagation in large language model ...
-
[26]
Chen Jin, Ryutaro Tanno, Tom Diethe, and Philip Teare. Corefine: Confidence-guided self-refinement for adaptive test-time compute.arXiv preprint arXiv:2602.08948, 2026a. Ting Xu, Xu He, Yupu Lu, Jiankai Sun, Dong Li, Wai Lam, and Jianye Hao. Unveiling the entropy dynamics of chain-of-thought reasoning.arXiv preprint arXiv:2606.02020,
-
[27]
Constantin Venhoff, Iván Arcuschin, Philip Torr, Arthur Conmy, and Neel Nanda. Understanding reasoning in thinking language models via steering vectors.arXiv preprint arXiv:2506.18167,
-
[28]
Haoyu Zheng, Yun Zhu, Yuqian Yuan, Bo Yuan, Wenqiao Zhang, Siliang Tang, and Jun Xiao. Pilot: Planning via internalized latent optimization trajectories for large language models.arXiv preprint arXiv:2601.19917,
-
[29]
Hongbo Jin, Rongpeng Zhu, Jiayu Ding, Guibo Luo, and Ge Li. Himac: Hierarchical macro-micro learning for long-horizon llm agents.arXiv preprint arXiv:2603.00977, 2026b. Shidong Cao, Hongzhan Lin, Yuxuan Gu, Ziyang Luo, and Jing Ma. Diffcot: Diffusion-styled chain-of-thought reasoning in llms.arXiv preprint arXiv:2601.03559,
-
[30]
Probabilistic soundness guarantees in llm reasoning chains
14 Weiqiu You, Anton Xue, Shreya Havaldar, Delip Rao, Helen Jin, Chris Callison-Burch, and Eric Wong. Probabilistic soundness guarantees in llm reasoning chains. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7517–7536,
2025
-
[31]
Rituraj Sharma, Weiyuan Chen, Noah Provenzano, and Tu Vu. Prism: Pushing the frontier of deep think via process reward model-guided inference.arXiv preprint arXiv:2603.02479,
-
[32]
Harman Singh, Xiuyu Li, Kusha Sareen, Monishwaran Maheswaran, Sijun Tan, Xiaoxia Wu, Junxiong Wang, Alpay Ariyak, Qingyang Wu, Samir Khaki, et al.v_1: Unifying generation and self-verification for parallel reasoners.arXiv preprint arXiv:2603.04304,
-
[33]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456, 2025b. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi,...
-
[34]
Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025e
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025e. Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization....
-
[35]
Gang Li, Ming Lin, Tomer Galanti, Zhengzhong Tu, and Tianbao Yang. Disco: Reinforcing large reasoning models with discriminative constrained optimization.arXiv preprint arXiv:2505.12366,
-
[36]
The proposed method does not involve human subjects, private user data, or personally identifiable information
15 A Ethics Statement This work studies reinforcement learning methods for improving the reasoning capabilities of large language models, with experiments conducted on mathematical and logical reasoning benchmarks. The proposed method does not involve human subjects, private user data, or personally identifiable information. All training and evaluation da...
2023
-
[37]
(34) This shows that E3RL preserves the same asymptotic order as GRPO when the expected regeneration ratio r is bounded. The additional entropy monitoring and thresholding operations are lightweight compared with the Transformer forward and backward computations, while the main extra cost comes from the regenerated segments. Since erasure is performed loc...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.