TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
Pith reviewed 2026-07-01 06:55 UTC · model grok-4.3
The pith
A single generative model produces satellite images from any mix of native geospatial vector primitives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
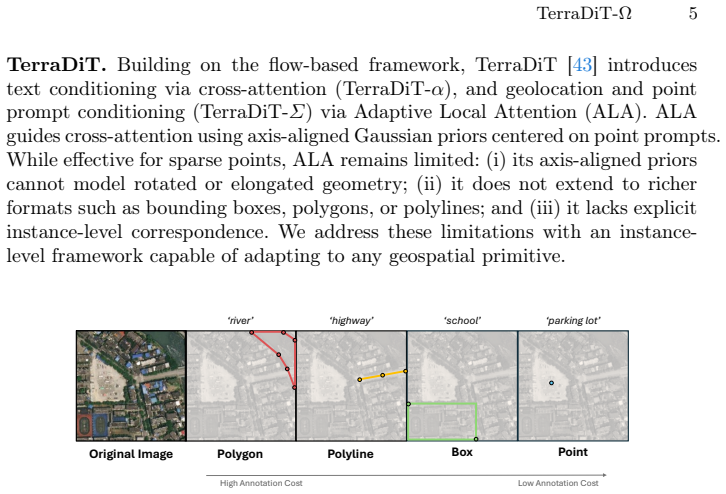
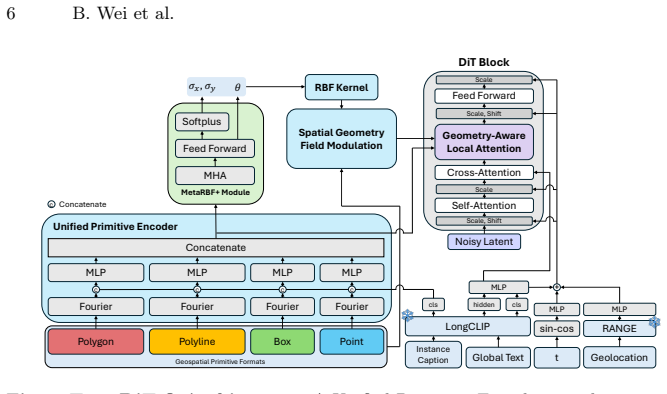
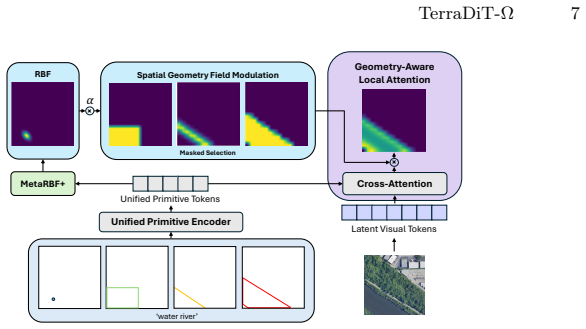
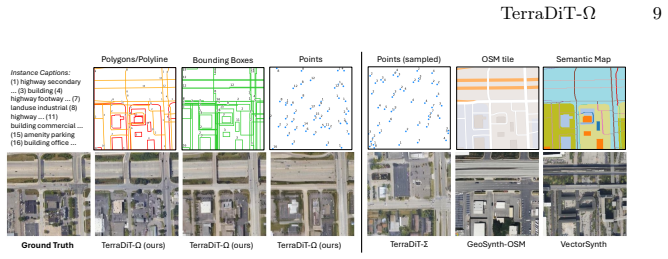
TerraDiT-Ω generates satellite imagery directly from any native geospatial primitive by jointly leveraging precise annotations such as polygons and polylines alongside coarser ones such as bounding boxes and points; the Geometry-Aware Local Attention mechanism injects explicit geometric cues from these mixed-precision inputs into the attention space, yielding consistent outperformance over both dense-control and sparse-control baselines while enabling controllable synthetic data augmentation that raises accuracy on land-cover segmentation, object detection, road graph extraction, and scene classification.
What carries the argument
Geometry-Aware Local Attention, a conditioning mechanism that injects explicit geometric cues from mixed-precision primitives into the attention space.
If this is right
- The model supports controllable layouts across varying annotation budgets without breaking compatibility with vector-based GeoAI pipelines.
- A single set of weights produces synthetic data usable for land-cover segmentation, object detection, road graph extraction, and scene classification.
- Outperformance holds across every tested conditioning format from dense rasters to sparse points.
- The approach remains naturally compatible with end-to-end workflows that already store geographic information as polygons, polylines, or points.
Where Pith is reading between the lines
- Existing GIS vector datasets could be used directly as conditioning inputs, removing an intermediate rasterization step in many remote-sensing pipelines.
- The same trained model might support interactive urban-planning interfaces where a user draws rough polygons or places points and immediately sees generated imagery.
- Downstream gains on multiple tasks suggest the method could reduce the number of separate generative models needed for different remote-sensing applications.
- If the attention injection generalizes, similar conditioning could be tested on non-satellite structured imagery such as medical scans or architectural drawings.
Load-bearing premise
The attention mechanism can embed geometric information from primitives of different precisions into the generation process without task-specific retraining or raster conversion.
What would settle it
Train the model on mixed primitives and test whether images conditioned only on points or only on polygons match the spatial layout of the input primitives at rates no higher than strong sparse-prompt baselines.
Figures





read the original abstract
Generative models have achieved remarkable progress, yet applying them to satellite imagery remains challenging. Unlike natural imagery, satellite scenes are structured by spatially complex and semantically distinct geometries. Prior work addresses this complexity by adapting natural image frameworks using dense rasters or sparse prompts, trading off annotation cost and fidelity while breaking compatibility with vector primitives commonly used to represent geographic information. We introduce TerraDiT-$\Omega$, a unified spatial control framework that generates satellite imagery directly from any native geospatial primitive. By jointly leveraging precise annotations (polygons, polylines) and coarser ones (bounding boxes, points), the model supports controllable layouts across varying annotation budgets, broadening applicability to design tasks such as urban planning while remaining naturally compatible with end-to-end GeoAI workflows. To effectively leverage these primitives during generation, we propose Geometry-Aware Local Attention, a conditioning mechanism that injects explicit geometric cues into the attention space. Across all conditioning formats, our approach consistently outperforms both dense-control and sparse-control baselines. Furthermore, this flexibility enables controllable synthetic data augmentation using a single generative model, improving downstream performance on land-cover segmentation, object detection, road graph extraction, and scene classification. Code, data, and weights are available at https://github.com/mvrl/TerraDiT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TerraDiT-Ω, a unified DiT-based framework for satellite image synthesis conditioned directly on native geospatial primitives (polygons, polylines, bounding boxes, points). It proposes Geometry-Aware Local Attention to inject geometric cues into the attention mechanism and claims consistent outperformance over dense-control and sparse-control baselines, plus gains in downstream tasks (land-cover segmentation, object detection, road graph extraction, scene classification) via controllable synthetic augmentation. Code and weights are stated to be available.
Significance. A working implementation of native-primitive conditioning without mandatory dense rasterization would be a meaningful contribution to controllable generation in remote sensing, as it aligns with standard GIS vector workflows and could reduce annotation overhead across varying budgets. Reproducibility via the linked repository is noted positively, though the absence of any reported metrics leaves the practical impact unassessable.
major comments (2)
- [Abstract] Abstract: the claim that the method 'consistently outperforms both dense-control and sparse-control baselines' across conditioning formats is unsupported by any quantitative metrics, tables, ablation results, or dataset descriptions, which is load-bearing for the central empirical contribution.
- [Abstract] Abstract: the Geometry-Aware Local Attention is described only at a high level as injecting 'explicit geometric cues' from mixed primitives 'without requiring task-specific retraining or dense raster conversion,' yet no equations, pseudocode, architectural details, or ablation isolating this step are provided; this detail is load-bearing for the 'unified' and 'any geospatial primitive' claims, as internal rasterization would collapse the distinction from standard dense control.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify that the abstract must be self-contained and quantitatively supported to substantiate the central claims. We will revise the abstract in the next version to address both points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'consistently outperforms both dense-control and sparse-control baselines' across conditioning formats is unsupported by any quantitative metrics, tables, ablation results, or dataset descriptions, which is load-bearing for the central empirical contribution.
Authors: We agree the abstract claim requires explicit quantitative support. In the revised manuscript we will insert concise numerical results (e.g., FID reductions and downstream-task deltas) drawn from the experimental tables already present in Sections 4 and 5, along with a brief mention of the evaluation datasets and conditioning formats. This will make the performance statement verifiable without lengthening the abstract excessively. revision: yes
-
Referee: [Abstract] Abstract: the Geometry-Aware Local Attention is described only at a high level as injecting 'explicit geometric cues' from mixed primitives 'without requiring task-specific retraining or dense raster conversion,' yet no equations, pseudocode, architectural details, or ablation isolating this step are provided; this detail is load-bearing for the 'unified' and 'any geospatial primitive' claims, as internal rasterization would collapse the distinction from standard dense control.
Authors: We acknowledge that the abstract description is high-level. The revised abstract will include a one-sentence reference to the core formulation (the geometry-aware attention modification) and will explicitly state that the mechanism operates directly on vector primitives. The full equations, pseudocode, architectural diagrams, and isolating ablations already appear in Section 3.2 and the supplementary material; we will ensure the abstract points readers to these sections so the distinction from dense raster control is clear. revision: yes
Circularity Check
No circularity; claims rest on empirical comparisons without mathematical reduction
full rationale
The provided manuscript text contains no equations, derivations, or first-principles claims that reduce to fitted parameters or self-citation chains. The core contribution is a proposed Geometry-Aware Local Attention mechanism described at a high level, with performance claims supported by comparisons to baselines on downstream tasks. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear. The derivation chain is therefore self-contained as an empirical proposal rather than a closed reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Albergo,M.S.,Boffi,N.M.,Vanden-Eijnden,E.:Stochasticinterpolants:Aunifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Avrahami, O., Hayes, T., Gafni, O., Gupta, S., Taigman, Y., Parikh, D., Lischin- ski, D., Fried, O., Yin, X.: Spatext: Spatio-textual representation for controllable image generation. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 18370–18380 (2022) 3
2023
-
[3]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Benidir, Y., Gonthier, N., Mallet, C.: The change you want to detect: Seman- tic change detection in earth observation with hybrid data generation. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 2204–2214 (2025) 2
2025
-
[4]
Benidir, Y., Gonthier, N., Mallet, C.: The change you want to detect: Semantic changedetectioninearthobservationwithhybriddatagenerationf.In:Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2204–2214 (2025) 4
2025
-
[5]
Transportation research record 2291(1), 61–71 (2012) 9
Biagioni, J., Eriksson, J.: Inferring road maps from global positioning sys- tem traces: Survey and comparative evaluation. Transportation research record 2291(1), 61–71 (2012) 9
2012
-
[6]
In: European Conference on Computer Vision
Chen, J., Ge, C., Xie, E., Wu, Y., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., Li, Z.: Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. In: European Conference on Computer Vision. pp. 74–91. Springer (2024) 10, 25
2024
-
[7]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:2310.00426 (2023) 10, 25
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Cher, D., Wei, B., Sastry, S., Jacobs, N.: Vectorsynth: Fine-grained satellite image synthesis with structured semantics. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 7019–7029 (March
-
[9]
2, 3, 5, 9, 10, 11, 25
-
[10]
Journal of Open Source Software7(70), 4101 (2022).https://doi
Detlefsen, N.S., Borovec, J., Schock, J., Jha, A.H., Koker, T., Di Liello, L., Stancl, D., Quan, C., Grechkin, M., Falcon, W.: TorchMetrics - measuring reproducibility in PyTorch. Journal of Open Source Software7(70), 4101 (2022).https://doi. org/10.21105/joss.0410123, 24
-
[11]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dhakal, A., Sastry, S., Khanal, S., Ahmad, A., Xing, E., Jacobs, N.: Range: Re- trieval augmented neural fields for multi-resolution geo-embeddings. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24680–24689 (2025) 8
2025
-
[12]
In: Forty-first international conference on machine learning (2024) 10, 25
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 10, 25
2024
-
[13]
Advances in Neural Information Processing Systems36, 18225–18250 (2023) 3
Feng, W., Zhu, W., Fu, T.j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X.E., Wang, W.Y.: Layoutgpt: Compositional visual planning and generation with large language models. Advances in Neural Information Processing Systems36, 18225–18250 (2023) 3
2023
-
[14]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Gafni, O., Polyak, A., Ashual, O., Sheynin, S., Parikh, D., Taigman, Y.: Make- a-scene: Scene-based text-to-image generation with human priors. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 89–106. Springer Nature Switzerland, Cham (2022) 3 16 B. Wei et al
2022
-
[15]
In: International Conference on Machine Learning (2025) 2
Goktepe, M., Shamseddin, A.H., Uysal, E., Monteagudo, J.M., Drees, L., Toker, A., Asseng, S., von Bloh, M.: Ecomapper: Generative modeling for climate-aware satellite imagery. In: International Conference on Machine Learning (2025) 2
2025
-
[16]
arXiv preprint arXiv:2507.02713 (2025) 3
Guo, Q., Zeng, A., Yue, D., Yang, C., Cao, Y., Guo, H., Shen, F., Liu, W., Liu, X., Xu, D.: Unimc: Taming diffusion transformer for unified keypoint-guided multi- class image generation. arXiv preprint arXiv:2507.02713 (2025) 3
-
[17]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 13, 24, 27, 28, 29
2016
-
[18]
In: European Conference on Computer Vision (2020) 13, 29
He,S.,Bastani,F.,Jagwani,S.,Alizadeh,M.,Balakrishnan,H.,Chawla,S.,Elshrif, M.M., Madden, S., Sadeghi, M.A.: Sat2graph: Road graph extraction through graph-tensor encoding. In: European Conference on Computer Vision (2020) 13, 29
2020
-
[19]
Advances in Neural Information Processing Systems34, 27903–27915 (2021) 2, 4
He, Y., Wang, D., Lai, N., Zhang, W., Meng, C., Burke, M., Lobell, D., Ermon, S.: Spatial-temporal super-resolution of satellite imagery via conditional pixel synthe- sis. Advances in Neural Information Processing Systems34, 27903–27915 (2021) 2, 4
2021
-
[20]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Hessel,J.,Holtzman,A.,Forbes,M.,LeBras,R.,Choi,Y.:CLIPScore:Areference- free evaluation metric for image captioning. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 7514–7528. Association for Computational Linguistics (2021),https://aclanthology.org/2021.emnlp- main.5958, 24
2021
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hetang, C., Xue, H., Le, C., Yue, T., Wang, W., He, Y.: Segment anything model for road network graph extraction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2556–2566 (2024) 13, 29
2024
-
[22]
In: Advances in Neural Information Processing Systems
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. In: Advances in Neural Information Processing Systems. vol. 30, pp. 6626–6637 (2017) 8, 23
2017
-
[23]
In: Proceedings of the 40th International Conference on Machine Learning
Huang, L., Chen, D., Liu, Y., Shen, Y., Zhao, D., Zhou, J.: Composer: creative and controllable image synthesis with composable conditions. In: Proceedings of the 40th International Conference on Machine Learning. pp. 13753–13773 (2023) 2
2023
-
[24]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017) 3
2017
-
[25]
In: Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M
Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M.: An introduction to open- streetmap in geographic information science: Experiences, research, and applica- tions. In: Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M. (eds.) Open- StreetMap in GIScience: Experiences, Research, and Applications, pp. 1–15. Springer, Cham (2015).https://doi.org/10....
-
[26]
Diffusionsat: A generative foun- dation model for satellite imagery. arxiv 2023,
Khanna, S., Liu, P., Zhou, L., Meng, C., Rombach, R., Burke, M., Lobell, D., Ermon, S.: Diffusionsat: A generative foundation model for satellite imagery. arXiv preprint arXiv:2312.03606 (2023) 3, 4, 10, 25
-
[27]
In: Interna- tional Conference on Learning Representations (ICLR) (2015) 29
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Interna- tional Conference on Learning Representations (ICLR) (2015) 29
2015
-
[28]
Li, K., Wan, G., Cheng, G., Meng, L., Han, J.: Object detection in optical remote sensingimages:Asurveyandanewbenchmark.ISPRSJournalofPhotogrammetry and Remote Sensing159, 296–307 (Jan 2020).https://doi.org/10.1016/j. isprsjprs.2019.11.023,http://dx.doi.org/10.1016/j.isprsjprs.2019.11. 02313, 27 TerraDiT-Ω17
work page doi:10.1016/j 2020
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li,Y.,Liu,H.,Wu,Q.,Mu,F.,Yang,J.,Gao,J.,Li,C.,Lee,Y.J.:Gligen:Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22511–22521 (2023) 2, 3, 10, 11, 12, 25, 34
2023
-
[30]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
IEEE Geoscience and Remote Sensing Magazine (2025) 3, 5, 10, 20, 25
Liu, C., Chen, K., Zhao, R., Zou, Z., Shi, Z.: Text2earth: Unlocking text-driven re- mote sensing image generation with a global-scale dataset and a foundation model. IEEE Geoscience and Remote Sensing Magazine (2025) 3, 5, 10, 20, 25
2025
-
[32]
Advances in neural information processing systems30(2017) 3
Liu, M.Y., Breuel, T., Kautz, J.: Unsupervised image-to-image translation net- works. Advances in neural information processing systems30(2017) 3
2017
-
[33]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017) 8, 22, 27, 28
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Remote Sensing16(7), 1154 (2024) 2
Mahara, A., Rishe, N.: Multispectral band-aware generation of satellite images across domains using generative adversarial networks and contrastive learning. Remote Sensing16(7), 1154 (2024) 2
2024
-
[36]
In: AAAI Conference on Artificial Intelligence (2023) 2
Mou, C., Wang, X., Xie, L., Zhang, J., Qi, Z., Shan, Y., Qie, X.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: AAAI Conference on Artificial Intelligence (2023) 2
2023
-
[37]
In: International Conference on Machine Learning
Nash, C., Menick, J., Dieleman, S., Battaglia, P.W.: Generating images with sparse representations. In: International Conference on Machine Learning. pp. 7950–7961. PMLR (2021) 8, 23
2021
-
[38]
Advances in neural informa- tion processing systems29(2016) 3
Van den Oord, A., Kalchbrenner, N., Espeholt, L., Vinyals, O., Graves, A., et al.: Conditional image generation with pixelcnn decoders. Advances in neural informa- tion processing systems29(2016) 3
2016
-
[39]
Pang, B., Zhao, S., Liu, Y.: The use of a stable super-resolution generative ad- versarial network (ssrgan) on remote sensing images. Remote Sensing15(20), 5064 (2023).https://doi.org/10.3390/rs15205064,https://doi.org/10.3390/ rs152050642
-
[40]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 3, 5
2023
-
[41]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 10, 22, 25
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
In: Advances in Neural Information Processing Systems (NeurIPS)
Ravuri, S., Vinyals, O.: Classification accuracy score for conditional generative models. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 12239–12249 (2019),https://papers.neurips.cc/paper/9393-classification- accuracy-score-for-conditional-generative-models.pdf9, 24
2019
-
[43]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015) 13, 28
2015
-
[44]
Sastry, S., Cher, D., Wei, B., Dhakal, A., Khanal, S., Gupta, D., Jacobs, N.: Ter- radit: Point-conditioned diffusion transformer for satellite image synthesis (2026), https://arxiv.org/abs/2603.021722, 3, 4, 5, 7, 8, 10, 11, 12, 14, 21, 22, 25, 34
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sastry, S., Khanal, S., Dhakal, A., Jacobs, N.: Geosynth: Contextually-aware high- resolution satellite image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 460–470 (2024) 2, 3, 9, 10, 11, 25, 28 18 B. Wei et al
2024
-
[46]
In: Forty-second International Conference on Machine Learning (2025) 2
Siampou, M.D., Li, J., Krumm, J., Shahabi, C., Lu, H.: Poly2vec: Polymorphic fourier-based encoding of geospatial objects for geoai applications. In: Forty-second International Conference on Machine Learning (2025) 2
2025
-
[47]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 8, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
2024 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV) pp
Song, J., Chen, H., Yokoya, N.: Syntheworld: A large-scale synthetic dataset for land cover mapping and building change detection. 2024 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV) pp. 8272–8281 (2023) 4
2024
-
[49]
IEEE Transactions on Geo- science and Remote Sensing (2024) 3, 10, 25
Tang, D., Cao, X., Hou, X., Jiang, Z., Liu, J., Meng, D.: Crs-diff: Controllable remote sensing image generation with diffusion model. IEEE Transactions on Geo- science and Remote Sensing (2024) 3, 10, 25
2024
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Tang, D., Cao, X., Wu, X., Li, J., Yao, J., Bai, X., Jiang, D., Li, Y., Meng, D.: Aerogen: Enhancing remote sensing object detection with diffusion-driven data generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3614–3624 (June 2025) 2, 4, 10, 11, 13, 25, 27, 28
2025
-
[51]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Toker, A., Eisenberger, M., Cremers, D., Leal-Taixé, L.: Satsynth: Augmenting image-mask pairs through diffusion models for aerial semantic segmentation. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 27695–27705 (2024) 2, 4, 28
2024
-
[52]
SpaceNet: A Remote Sensing Dataset and Challenge Series
Van Etten, A., Lindenbaum, D., Bacastow, T.M.: Spacenet: A remote sensing dataset and challenge series. arXiv preprint arXiv:1807.01232 (2018) 9
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
In: Advances in Neural Information Processing Systems
Wang, D., Zhang, J., Du, B., Xu, M., Liu, L., Tao, D., Zhang, L.: Samrs: Scaling-up remote sensing segmentation dataset with segment anything model. In: Advances in Neural Information Processing Systems. vol. 36, pp. 8815–8827 (2023) 4
2023
-
[54]
In: Vanschoren, J., Ye- ung, S
Wang, J., Zheng, Z., Ma, A., Lu, X., Zhong, Y.: Loveda: A remote sensing land- cover dataset for domain adaptive semantic segmentation. In: Vanschoren, J., Ye- ung, S. (eds.) Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. vol. 1. Curran Associates, Inc. (2021),https: //datasets- benchmarks- proceedings.neurips.c...
2021
-
[55]
Computers, Environment and Urban Systems122, 102339 (2025) 4
Wang, Q., Liang, Y., Zheng, Y., Xu, K., Zhao, J., Wang, S.: Generative ai for urban planning: Synthesizing satellite imagery via diffusion models. Computers, Environment and Urban Systems122, 102339 (2025) 4
2025
-
[56]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wang, T.C., Liu, M.Y., Zhu, J.Y., Tao, A., Kautz, J., Catanzaro, B.: High- resolution image synthesis and semantic manipulation with conditional gans. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 8798–8807 (2018) 3
2018
-
[57]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Wang, X., Darrell, T., Rambhatla, S.S., Girdhar, R., Misra, I.: Instancediffusion: Instance-level control for image generation. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 6232–6242 (2024) 2, 3, 10, 11, 12, 25, 34
2024
-
[58]
IEEE Transactions on Geoscience and Remote Sensing62, 1–20 (2023) 4
Wang, Y., Zhang, B., Zhang, W., Hong, D., Zhao, B., Li, Z.: Cloud removal with sar-optical data fusion using a unified spatial–spectral residual network. IEEE Transactions on Geoscience and Remote Sensing62, 1–20 (2023) 4
2023
-
[59]
Wang, Z., Prabha, R., Huang, T., Wu, J., Rajagopal, R.: Skyscript: A large and semantically diverse vision-language dataset for remote sensing. Proceedings of the AAAI Conference on Artificial Intelligence38(6), 5805–5813 (Mar 2024).https:// doi.org/10.1609/aaai.v38i6.28393,https://ojs.aaai.org/index.php/AAAI/ article/view/283934 TerraDiT-Ω19
-
[60]
IEEE Transactions on Image Process- ing13(4), 600–612 (2004) 24
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Process- ing13(4), 600–612 (2004) 24
2004
-
[61]
IEEE Transactions on Geoscience and Remote Sensing55(7), 3965–3981 (2017) 13, 29
Xia, G.S., Hu, J., Hu, F., Shi, B., Bai, X., Zhong, Y., Zhang, L., Lu, X.: Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing55(7), 3965–3981 (2017) 13, 29
2017
-
[62]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Xia, J., Yokoya, N., Adriano, B., Broni-Bediako, C.: Openearthmap: A bench- mark dataset for global high-resolution land cover mapping. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6254–6264 (2023) 2, 4, 13, 28
2023
-
[63]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xu, T., Zhang, P., Huang, Q., Zhang, H., Gan, Z., Huang, X., He, X.: Attngan: Fine-grained text to image generation with attentional generative adversarial net- works. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1316–1324 (2018) 3
2018
-
[64]
IEEE Trans- actions on Image Processing32, 5737–5750 (2023) 3, 10, 25
Xu, Y., Yu, W., Ghamisi, P., Kopp, M., Hochreiter, S.: Txt2img-mhn: Remote sensing image generation from text using modern hopfield networks. IEEE Trans- actions on Image Processing32, 5737–5750 (2023) 3, 10, 25
2023
-
[65]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940 (2024) 8, 22
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
In: European conference on computer vision
Zhang, B., Zhang, P., Dong, X., Zang, Y., Wang, J.: Long-clip: Unlocking the long- text capability of clip. In: European conference on computer vision. pp. 310–325. Springer (2024) 6, 8, 22
2024
-
[67]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023) 2, 3, 28
2023
-
[68]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018) 8, 24
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018) 8, 24
2018
-
[69]
arXiv preprint arXiv:2305.12410 (2023) 4
Zhang, X., Tian, S., Wang, G., Zhou, H., Jiao, L.: Diffucd: Unsupervised hyper- spectral image change detection with semantic correlation diffusion model. arXiv preprint arXiv:2305.12410 (2023) 4
-
[70]
Advances in Neural Information Processing Systems34, 27196–27208 (2021) 3
Zhang, Z., Ma, J., Zhou, C., Men, R., Li, Z., Ding, M., Tang, J., Zhou, J., Yang, H.: Ufc-bert: Unifying multi-modal controls for conditional image synthesis. Advances in Neural Information Processing Systems34, 27196–27208 (2021) 3
2021
-
[71]
IEEE Transactions on Geoscience and Remote Sensing62, 1–23 (2024) 3, 10, 25
Zhang, Z., Zhao, T., Guo, Y., Yin, J.: Rs5m and georsclip: A large-scale vision- language dataset and a large vision-language model for remote sensing. IEEE Transactions on Geoscience and Remote Sensing62, 1–23 (2024) 3, 10, 25
2024
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16965–16974 (2024) 13, 27
2024
-
[73]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, G., Zhou, X., Li, X., Qi, Z., Shan, Y., Li, X.: Layoutdiffusion: Controllable diffusion model for layout-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22490–22499 (2023) 24
2023
-
[74]
In: Proceedings of the IEEE interna- tional conference on computer vision
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 2223–f232 (2017) 3 TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive – Supplementary Material – A Addition...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.