STC: Reversible Digit-Context Decomposition for BWT-Family Text Compression
Pith reviewed 2026-06-28 08:12 UTC · model grok-4.3
The pith
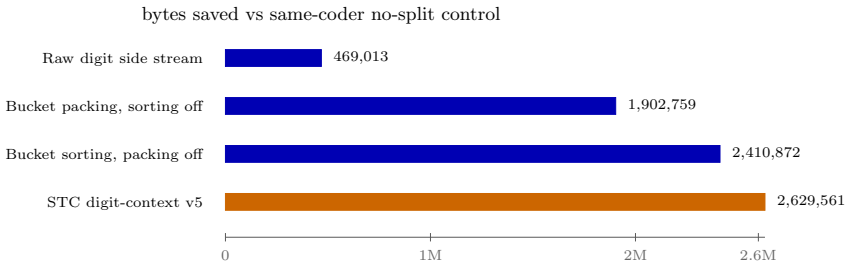
Digit-context decomposition before BWT reduces the enwik9 archive by 2.6 million bytes relative to the unsplit control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
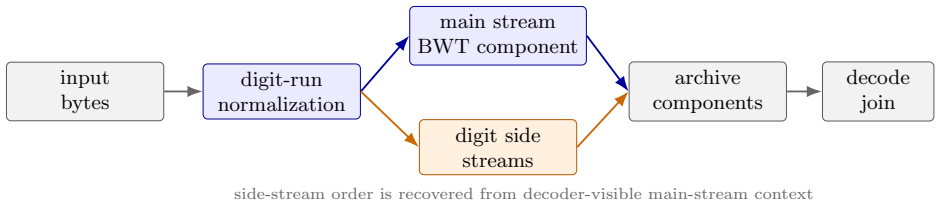
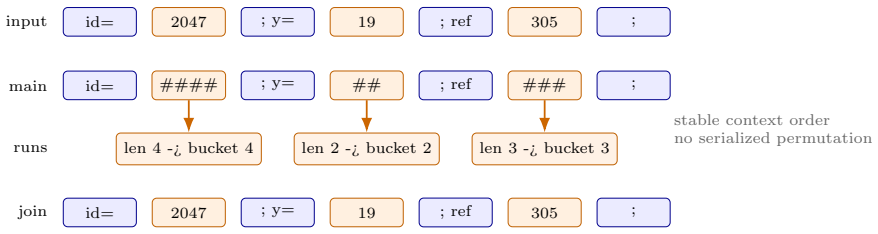
STC replaces digit runs in the input with unambiguous placeholders, stores the removed digits in length- and context-conditioned side streams that use stable bucket ordering and compact digit packing, and feeds the resulting streams to a fixed internal BWT/M03-style coder; on enwik9 the resulting archive is 157,388,188 bytes with a 183,174-byte decoder source package.
What carries the argument
Reversible digit-context decomposition that substitutes digit runs with placeholders in the main stream and packs the digits into ordered side streams.
If this is right
- The digit-context split reduces the main archive by 2,629,561 bytes on full enwik9.
- The combined archive plus decoder source totals 157,571,362 bytes under the local LTCB-style accounting.
- No separate permutation data is required because the side-stream design reconstructs run order deterministically.
- Full decode followed by SHA-256 verification confirms that the original text is recovered exactly.
Where Pith is reading between the lines
- The same placeholder-plus-side-stream pattern could be applied to other varying numeric fields such as dates or coordinates without changing the core BWT stage.
- Because the decomposition is placed before the transform, it is independent of the particular BWT implementation and could be tested with any other BWT-family coder.
- The method may produce larger gains on corpora that contain more identifier-style numeric runs than natural-language text.
Load-bearing premise
The side streams preserve stable bucket ordering and compact digit packing so that the decoder can recover the exact original run order from the normalized main stream alone.
What would settle it
An input where applying the digit-context split produces a larger total archive size than the no-split control, or where the decoder output fails a byte-for-byte match with the original file.
Figures
read the original abstract
Burrows-Wheeler-transform-based compressors rely on local context regularity, but structured text also contains dates, counters, identifiers, coordinates, and other digit runs whose values vary differently from their surrounding tokens. STC is a practical BWT-family compressor that separates this source of variation before the component BWT stage. It replaces digit runs in the main stream with an unambiguous placeholder and stores the removed digits in length- and context-conditioned side streams. The side streams use stable bucket ordering and compact digit packing, so the decoder can reconstruct the original run order from the normalized main stream without storing a separate permutation. The resulting components are encoded by a fixed internal BWT/M03-style component coder. On enwik9, STC produces a 157,388,188-byte archive with a 183,174-byte decoder source package, giving a local LTCB-style total of 157,571,362 bytes. A full-enwik9 same-coder ablation shows that the digit-context decomposition reduces the archive by 2,629,561 bytes relative to the no-split control. The result is locally verified by full decode and SHA-256 matching; official benchmark status requires independent maintainer-side verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents STC, a BWT-family text compressor that performs reversible digit-context decomposition: digit runs are replaced by placeholders in the main stream and stored in length- and context-conditioned side streams that use stable bucket ordering and compact packing to enable reconstruction without an explicit permutation. The components are then encoded by a fixed internal BWT/M03-style coder. On enwik9 the method yields a 157,388,188-byte archive plus a 183,174-byte decoder package (LTCB-style total 157,571,362 bytes) and an ablation shows a 2,629,561-byte reduction relative to the identical coder without the split; the pipeline is verified by full decode plus SHA-256 match.
Significance. If the reported sizes and ablation hold, the work supplies a concrete, locally verified technique for isolating digit-run variation that is orthogonal to the core BWT stage, producing a measurable net saving on a standard corpus while keeping the decoder self-contained. The same-coder ablation and end-to-end verification strengthen the empirical claim.
minor comments (4)
- [abstract, §3] The abstract and §3 (side-stream design) state that context conditioning and stable bucket ordering suffice for reconstruction, but provide no pseudocode or parameter values for the conditioning function; a short algorithmic description would improve reproducibility.
- [§2] No comparison is given against prior published methods for handling numeric runs inside BWT compressors (e.g., digit-aware preprocessing in other LTCB entries); adding a brief related-work paragraph would situate the 2.63 MB gain.
- [§4] The ablation reports a single aggregate saving; stating the per-component byte counts (main stream vs. side streams) for both the split and control runs would make the source of the improvement explicit.
- [abstract] The decoder source size (183,174 bytes) is included in the LTCB total, but the manuscript does not indicate whether this size was measured with the same compiler flags and library versions used for the archive; a one-sentence clarification would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed summary, positive significance assessment, and recommendation of minor revision. No specific major comments were provided in the report, so there are no individual points requiring point-by-point rebuttal or changes at this stage. We remain available to address any additional concerns the editor or referee may wish to raise.
Circularity Check
No significant circularity; empirical ablation result stands on measured sizes
full rationale
The manuscript presents a compression technique whose central claim is an empirical size reduction (2.63 MB on enwik9 via same-coder ablation) together with a decoder reconstruction path that is exercised by full decode + SHA-256 verification. No equations, fitted parameters, or self-citations are shown that would reduce the reported savings or the side-stream reconstruction to a definitional identity. The side-stream design (stable bucket ordering, compact packing) is described as an implementation choice whose correctness is directly tested by the reported verification step, not assumed without evidence. This is a standard empirical engineering result with an explicit control; the derivation chain contains no load-bearing self-referential step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BWT-family compressors rely on local context regularity that digit runs disrupt
- domain assumption Digit runs can be unambiguously identified and replaced by placeholders while preserving decodability via side streams
Reference graph
Works this paper leans on
-
[1]
1994 , url =
A Block-Sorting Lossless Data Compression Algorithm , author =. 1994 , url =
1994
-
[2]
An Analysis of the
Manzini, Giovanni , journal =. An Analysis of the. 2001 , doi =
2001
-
[3]
, journal =
Fenwick, Peter M. , journal =. The. 1996 , doi =
1996
-
[4]
High-Performance
Trinca, Daniel , journal =. High-Performance. 2005 , url =
2005
-
[5]
Efficient Construction of the
D. Efficient Construction of the. Information and Computation , volume =. 2023 , doi =
2023
-
[6]
2020 , doi =
Niemi, Arto and Teuhola, Jukka , journal =. 2020 , doi =
2020
-
[7]
Adjeroh, Donald and Bell, Timothy and Mukherjee, Amar , publisher =. The. 2008 , doi =
2008
-
[8]
1990 , url =
Text Compression , author =. 1990 , url =
1990
-
[9]
2007 , doi =
Data Compression: The Complete Reference , author =. 2007 , doi =
2007
-
[10]
2017 , url =
Introduction to Data Compression , author =. 2017 , url =
2017
-
[11]
2026 , url =
bzip2 and libbzip2 , author =. 2026 , url =
2026
-
[12]
2026 , url =
libbsc: Block Sorting Compressor , author =. 2026 , url =
2026
-
[13]
bsc-m03: Experimental Block Sorting Compressor Based on
Grebnov, Ilya , year =. bsc-m03: Experimental Block Sorting Compressor Based on
-
[14]
On Bijective Variants of the
Kufleitner, Manfred , journal =. On Bijective Variants of the. 2009 , url =
2009
-
[15]
A Bijective String Sorting Transform
A Bijective String Sorting Transform , author =. arXiv preprint arXiv:1201.3077 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
An Extension of the
Mantaci, Sabrina and Restivo, Antonio and Rosone, Giovanna and Sciortino, Marinella , journal =. An Extension of the. 2007 , doi =
2007
-
[17]
Constructing the Bijective and the Extended
Bannai, Hideo and Karkkainen, Juha and Koppl, Dominik and Piatkowski, Martin , journal =. Constructing the Bijective and the Extended. 2019 , url =
2019
-
[18]
In-Place Bijective
Koppl, Dominik and Sadakane, Kunihiko , journal =. In-Place Bijective. 2020 , url =
2020
-
[19]
Fully Functional Suffix Trees and Optimal Text Searching in
Gagie, Travis and Navarro, Gonzalo and Prezza, Nicola , journal =. Fully Functional Suffix Trees and Optimal Text Searching in. 2020 , doi =
2020
-
[20]
Bijective
Badkobeh, Golnaz and Bannai, Hideo and Koppl, Dominik , journal =. Bijective. 2024 , url =
2024
-
[21]
Bit Catastrophes for the
Boucher, Christina and Cenzato, Davide and Lipt. Bit Catastrophes for the. Theory of Computing Systems , year =
-
[22]
On the Compressiveness of the
Bannai, Hideo and I, Tomohiro and Nakashima, Yuto , booktitle =. On the Compressiveness of the. 2025 , doi =
2025
-
[23]
Proceedings of SEA 2025 , series =
Adler, Isabel and Cenzato, Davide and Lipt. Proceedings of SEA 2025 , series =. 2025 , doi =
2025
-
[24]
Decomposing Words for Enhanced Compression: Exploring the Number of Runs in the Extended
Ingels, Florian and Denis, Ana. Decomposing Words for Enhanced Compression: Exploring the Number of Runs in the Extended. arXiv preprint arXiv:2506.04926 , year =
-
[25]
Theoretical Computer Science , volume =
A New Class of Searchable and Provably Highly Compressible String Transformations , author =. Theoretical Computer Science , volume =. 2018 , url =
2018
-
[26]
and Shapira, Dana , journal =
Fruchtman, Amir and Gross, Yossi and Klein, Shmuel T. and Shapira, Dana , journal =. Weighted. 2021 , url =
2021
-
[27]
Software: Practice and Experience , volume =
Revisiting Dictionary-Based Compression , author =. Software: Practice and Experience , volume =. 2005 , doi =
2005
-
[28]
1999 , url =
Browsing and Searching Compressed Documents , author =. 1999 , url =
1999
-
[29]
2000 , doi =
Liefke, Hartmut and Suciu, Dan , booktitle =. 2000 , doi =
2000
-
[30]
and Haritsa, Jayant R
Tolani, Parag M. and Haritsa, Jayant R. , booktitle =. 2002 , doi =
2002
-
[31]
Path Queries on Compressed
Buneman, Peter and Grohe, Martin and Koch, Christoph , booktitle =. Path Queries on Compressed. 2003 , url =
2003
-
[32]
Proceedings of SIGMOD , pages =
Integrating Compression and Execution in Column-Oriented Database Systems , author =. Proceedings of SIGMOD , pages =. 2006 , doi =
2006
-
[33]
Stonebraker, Michael and Abadi, Daniel J. and Batkin, Adam and Chen, Xuedong and Cherniack, Mitch and Ferreira, Miguel and Lau, Edmond and Lin, Amerson and Madden, Samuel and O'Neil, Elizabeth and O'Neil, Patrick and Rasin, Alex and Tran, Nga and Zdonik, Stanley , booktitle =. 2005 , url =
2005
-
[34]
Proceedings of the VLDB Endowment , volume =
Dremel: Interactive Analysis of Web-Scale Datasets , author =. Proceedings of the VLDB Endowment , volume =. 2010 , doi =
2010
-
[35]
Proceedings of ICDE , pages =
Compressing Relations and Indexes , author =. Proceedings of ICDE , pages =. 1998 , doi =
1998
-
[36]
Super-Scalar
Zukowski, Marcin and Heman, Sandor and Nes, Niels and Boncz, Peter , booktitle =. Super-Scalar. 2006 , doi =
2006
-
[37]
Software: Practice and Experience , volume =
Decoding Billions of Integers per Second through Vectorization , author =. Software: Practice and Experience , volume =. 2015 , doi =
2015
-
[38]
Lemire, Daniel and Kurz, Nathan and Rupp, Christoph , journal =. Stream. 2018 , doi =
2018
-
[39]
Proceedings of the VLDB Endowment , volume =
Gorilla: A Fast, Scalable, In-Memory Time Series Database , author =. Proceedings of the VLDB Endowment , volume =. 2015 , doi =
2015
-
[40]
Computer , volume =
A Technique for High-Performance Data Compression , author =. Computer , volume =. 1984 , doi =
1984
-
[41]
1999 , url =
Managing Gigabytes: Compressing and Indexing Documents and Images , author =. 1999 , url =
1999
-
[42]
Asymmetric Numeral Systems: Entropy Coding Combining Speed of
Duda, Jarek , journal =. Asymmetric Numeral Systems: Entropy Coding Combining Speed of. 2013 , url =
2013
-
[43]
Generalized
Rissanen, Jorma , journal =. Generalized. 1976 , doi =
1976
-
[44]
Communications of the ACM , volume =
Arithmetic Coding for Data Compression , author =. Communications of the ACM , volume =. 1987 , doi =
1987
-
[45]
Proceedings of the IRE , volume =
A Method for the Construction of Minimum-Redundancy Codes , author =. Proceedings of the IRE , volume =. 1952 , doi =
1952
-
[46]
IEEE Transactions on Information Theory , volume =
A Universal Algorithm for Sequential Data Compression , author =. IEEE Transactions on Information Theory , volume =. 1977 , doi =
1977
-
[47]
IEEE Transactions on Information Theory , volume =
Compression of Individual Sequences via Variable-Rate Coding , author =. IEEE Transactions on Information Theory , volume =. 1978 , doi =
1978
-
[48]
IEEE Transactions on Communications , volume =
Data Compression Using Adaptive Coding and Partial String Matching , author =. IEEE Transactions on Communications , volume =. 1984 , doi =
1984
-
[49]
2026 , url =
Rules for the Large Text Compression Benchmark , author =. 2026 , url =
2026
-
[50]
Hutter, Marcus , year =. The
-
[51]
2026 , url =
Reproducible Builds , author =. 2026 , url =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.