Discrete Tilt Matching
Pith reviewed 2026-05-21 00:24 UTC · model grok-4.3
The pith
Discrete Tilt Matching allows likelihood-free fine-tuning of masked diffusion LLMs by matching tilted local unmasking posteriors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
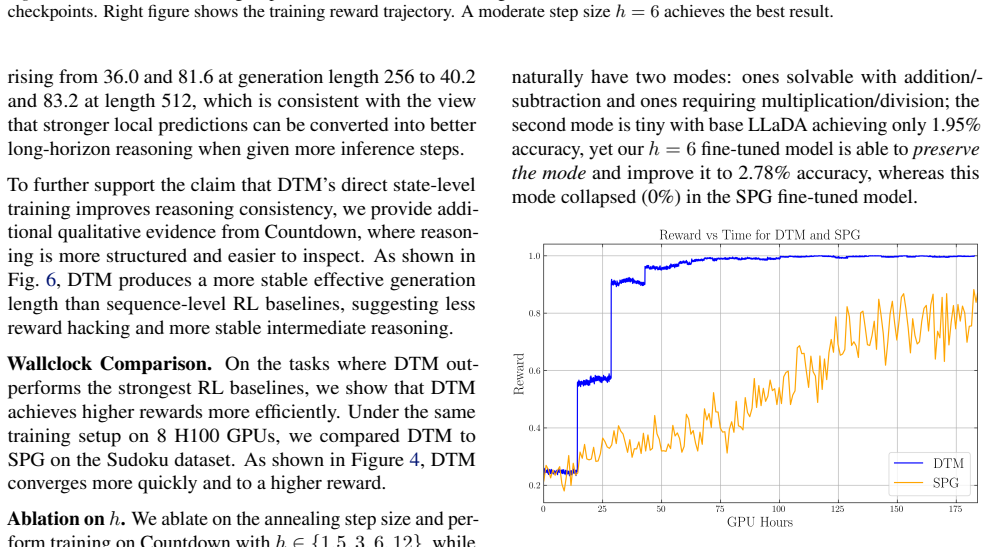
The central discovery is that Discrete Tilt Matching recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting. This produces a likelihood-free weighted cross-entropy loss with an explicit solution and control variates that enhance training stability. On synthetic tasks, annealing and control variates help avoid mode collapse. At scale, the approach delivers strong gains on Sudoku and Countdown after fine-tuning LLaDA-8B-Instruct, while staying competitive on MATH500 and GSM8K.
What carries the argument
Discrete Tilt Matching, which matches local unmasking posteriors under reward tilting using a weighted cross-entropy objective with control variates.
If this is right
- DTM provides an explicit minimizer for the fine-tuning objective without needing sequence marginals.
- Control variates can be used to improve training stability in dLLM RL.
- Fine-tuning with DTM leads to performance gains on planning tasks like Sudoku and Countdown.
- The method remains competitive on math reasoning benchmarks such as MATH500 and GSM8K.
Where Pith is reading between the lines
- DTM might extend to other generative modeling settings where sequence likelihoods are hard to access.
- The state-level focus could lead to more efficient optimization in high-dimensional reward landscapes.
- Adjusting the tilting function or masking schedule may require careful validation to avoid unintended biases.
Load-bearing premise
Matching state-level local unmasking posteriors under reward tilting is sufficient to optimize the sequence-level objective without bias from the masking schedule or tilting function.
What would settle it
Demonstrating that DTM-optimized models achieve lower rewards than a feasible sequence-level RL baseline on a small-scale dLLM task, or showing performance degradation when the masking schedule changes independently of the tilt.
Figures










read the original abstract
Masked diffusion large language models (dLLMs) are a promising alternative to autoregressive generation. While reinforcement learning (RL) methods have recently been adapted to dLLM fine-tuning, their objectives typically depend on sequence-level marginal likelihoods, which are intractable for masked diffusion models. To address this, we derive Discrete Tilt Matching (DTM), a likelihood-free method that recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting. DTM takes the form of a weighted cross-entropy objective with explicit minimizer, and admits control variates that improve training stability. On a synthetic maze-planning task, we analyze how DTM's annealing schedule and control variates affect training stability and prevent mode collapse. At scale, fine-tuning LLaDA-8B-Instruct with DTM yields strong gains on Sudoku and Countdown while remaining competitive on MATH500 and GSM8K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Discrete Tilt Matching (DTM) for fine-tuning masked diffusion large language models (dLLMs). It derives DTM as a likelihood-free weighted cross-entropy objective that matches state-level local unmasking posteriors under reward tilting, claiming an explicit minimizer and support for control variates to improve stability. The work analyzes annealing schedules and control variates on a synthetic maze task to address mode collapse and stability, then applies DTM to fine-tune LLaDA-8B-Instruct, reporting strong gains on Sudoku and Countdown while remaining competitive on MATH500 and GSM8K.
Significance. If the derivation establishes that local posterior matching under tilting is equivalent to sequence-level reward optimization without systematic bias from the masking schedule or tilting function, DTM would offer a practical, tractable alternative to intractable marginal-likelihood RL methods for dLLMs. The explicit minimizer and control variates are strengths that support stability and reproducibility; the maze analysis and large-scale results on reasoning tasks indicate potential impact for non-autoregressive generative models.
major comments (2)
- [§2 (DTM Derivation)] §2 (DTM Derivation), paragraph on equivalence: The central claim that recasting dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting optimizes the intractable sequence-level objective requires that the masking schedule and tilting function induce no bias. The abstract notes analysis of annealing and control variates on the maze task but provides no explicit bound, exact equivalence proof, or generalization to the LLaDA experiments; this is load-bearing for interpreting the Sudoku/Countdown gains as true reward optimization.
- [§3.2 (Maze Analysis)] §3.2 (Maze Analysis), control variates paragraph: The introduction of control variates and the annealing schedule lacks ablations that isolate their contribution from the core weighted cross-entropy objective or external benchmarks, which is needed to substantiate the stability and mode-collapse prevention claims before scaling to 8B models.
minor comments (2)
- [Abstract] Abstract: The phrase 'strong gains' on Sudoku and Countdown is not quantified with specific metrics or baselines; adding deltas or absolute scores would improve precision.
- [§4 (Large-scale Experiments)] §4 (Large-scale Experiments): The tilting function and its parameterization across tasks are not fully specified (e.g., functional form or hyperparameter ranges), which could affect reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and detailed comments on the manuscript. We address each major comment below with clarifications and indicate where revisions will be made to strengthen the presentation of the theoretical claims and empirical analyses.
read point-by-point responses
-
Referee: [§2 (DTM Derivation)] §2 (DTM Derivation), paragraph on equivalence: The central claim that recasting dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting optimizes the intractable sequence-level objective requires that the masking schedule and tilting function induce no bias. The abstract notes analysis of annealing and control variates on the maze task but provides no explicit bound, exact equivalence proof, or generalization to the LLaDA experiments; this is load-bearing for interpreting the Sudoku/Countdown gains as true reward optimization.
Authors: We appreciate the referee's emphasis on rigorously establishing the lack of bias in the equivalence. The derivation in §2 shows that the weighted cross-entropy objective matches the tilted local unmasking posteriors by direct construction, with the masking schedule entering as a fixed distribution independent of the reward tilt; this yields an explicit minimizer without requiring marginal likelihoods. We acknowledge that the current manuscript does not include an explicit bias bound or full proof of zero bias under arbitrary schedules. In the revised version, we will add a dedicated paragraph stating the assumptions (uniform masking and consistent local tilting) under which the sequence-level equivalence holds, along with a brief discussion of potential residual biases and how the maze-task analysis empirically supports generalization to the LLaDA-8B experiments, where the identical DTM formulation produces the reported gains on Sudoku and Countdown. revision: yes
-
Referee: [§3.2 (Maze Analysis)] §3.2 (Maze Analysis), control variates paragraph: The introduction of control variates and the annealing schedule lacks ablations that isolate their contribution from the core weighted cross-entropy objective or external benchmarks, which is needed to substantiate the stability and mode-collapse prevention claims before scaling to 8B models.
Authors: We agree that clearer isolation of components strengthens the stability claims. Section 3.2 already reports results across annealing schedules and with/without control variates on the maze task, showing reduced variance and mode collapse relative to the base objective. To address the request for dedicated ablations, the revised manuscript will include additional experiments that directly compare (i) the core weighted cross-entropy, (ii) the same objective plus annealing only, and (iii) the full DTM with both annealing and control variates. These will report quantitative stability metrics (loss variance across seeds, success rate, and mode-collapse indicators) and will be presented prior to the 8B-scale results to better substantiate the contributions. revision: yes
Circularity Check
No significant circularity; DTM is a derived objective with independent content
full rationale
The paper presents DTM as a first-principles derivation that recasts sequence-level reward optimization for dLLMs into a tractable state-level weighted cross-entropy matching of local unmasking posteriors under tilting, with an explicit minimizer. This construction does not reduce to a fitted parameter renamed as a prediction, nor does it rely on self-citation chains or imported uniqueness theorems for its load-bearing steps. The annealing schedule and control variates are introduced and analyzed on a separate synthetic maze task rather than presupposed in the core equivalence. Downstream gains on Sudoku and Countdown are reported as empirical outcomes, not inputs to the derivation. The central claim therefore remains self-contained against external benchmarks and does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- annealing schedule
- control variates
axioms (1)
- domain assumption Local unmasking posteriors exist and can be tilted by a reward function without changing the overall diffusion process.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we derive Discrete Tilt Matching (DTM), a likelihood-free method that recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting... ρ_{1,A}(x)∝ρ_1(x)e^{A r(x)}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen
PMLR. URL https://proceedings.mlr. press/v235/campbell24a.html. Poster. Chang, H., Zhang, H., Jiang, L., Liu, C., and Freeman, W. T. Maskgit: Masked generative image transformer, 2022. URLhttps://arxiv.org/abs/2202.04200. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Trainin...
-
[2]
URL https://openreview.net/forum? id=KnqiC0znVF. Oral. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, 10 Discrete Tilt Matching J., and Lowe, R. Training language models to ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
URL https://openreview.net/forum? id=tcvMzR2NrP. Oral. Shi, J., Han, K., Wang, Z., Doucet, A., and Titsias, M. K. Simplified and generalized masked diffusion for discrete data, 2024. URL https://arxiv.org/abs/2406. 04329. Tang, X., Dolga, R., Yoon, S., and Bogunovic, I. wd1: Weighted policy optimization for reasoning in diffusion language models, 2025. UR...
-
[4]
URL https://openreview.net/forum? id=wczmXLuLGd. Poster. Zhao, S., Gupta, D., Zheng, Q., and Grover, A. d1: Scaling reasoning in diffusion large language mod- els via reinforcement learning. InAdvances in Neu- ral Information Processing Systems (NeurIPS 2025),
work page 2025
-
[5]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
URL https://openreview.net/forum? id=7ZVRlBFuEv. Spotlight. Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., and Li, C. Llada 1.5: Variance-reduced preference optimiza- tion for large language diffusion models, 2025. URL https://arxiv.org/abs/2505.19223. 11 Discrete Tilt Matching Algorithm 1DTM Training Requ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
+O(h 2), G 1 =µ(x t, i) +hr(x 1) µ(xt, i) +ϕ(x i 1) +O(h 2), where theO(h 2)terms are inL 2 providedrandϕhave finite second moments. Ath= 0, we haveG 0|h=0 =ϕ(x i 1)andG 1|h=0 =µ(x t, i) =E a[ϕ(xi 1)|x t, i]. By the law of total variance, Var(ϕ(xi 1)) = Var Ea[ϕ(xi 1)|x t, i] +E Var(ϕ(xi 1)|x t, i) >Var(µ(x t, i)), so Var(G0)>Var(G 1) holds at h= 0 . Sinc...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.