"What Happens Locally, Leaks Globally": Detecting Privacy Leakage Risks in MCP Servers
Pith reviewed 2026-06-26 14:06 UTC · model grok-4.3
The pith
MCPPrivacyDetector detects privacy leakage in more than 10 percent of 10,655 real-world MCP servers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
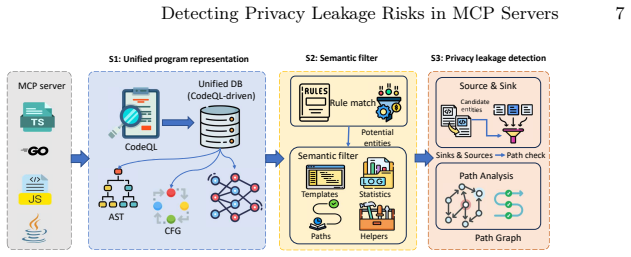
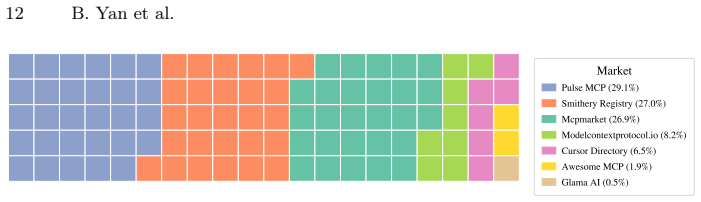
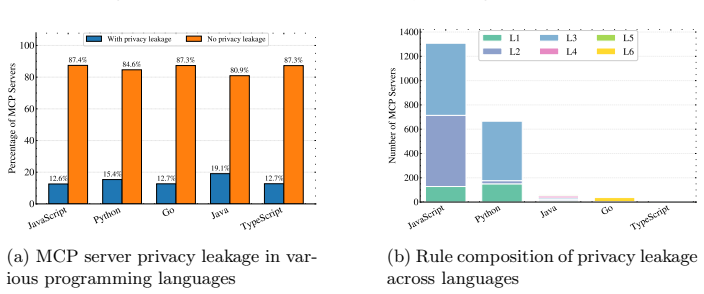
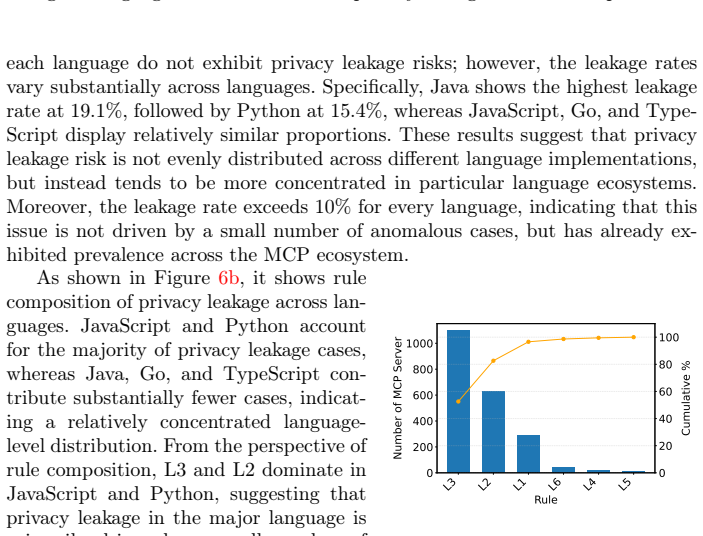
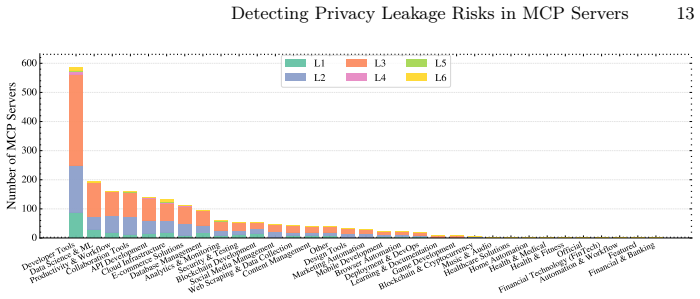
MCPPrivacyDetector lifts heterogeneous code implemented across different programming languages into a unified program representation, applies context-aware semantic filtering to isolate genuinely sensitive values and protocol-specific implicit sinks such as @mcp.tool handlers, and performs taint analysis to enumerate feasible flows. Applied to 10,655 real-world MCP servers, MCPPrivacyDetector finds leakage rates above 10 percent. Case studies confirm concrete exposures including leaked Bearer tokens, propagated API keys, and plaintext authentication credentials.
What carries the argument
MCPPrivacyDetector, the context-aware cross-language static analysis framework that lifts multilingual code, filters sensitive values, and traces taint to implicit MCP sinks.
Load-bearing premise
The context-aware semantic filtering and cross-language lifting step correctly isolate genuinely sensitive values and protocol-specific implicit sinks without introducing substantial false positives or missing real flows in multilingual MCP server code.
What would settle it
Manually auditing a random sample of the servers flagged by the tool to check whether the reported sensitive values actually reach the connected language model during normal operation.
Figures



read the original abstract
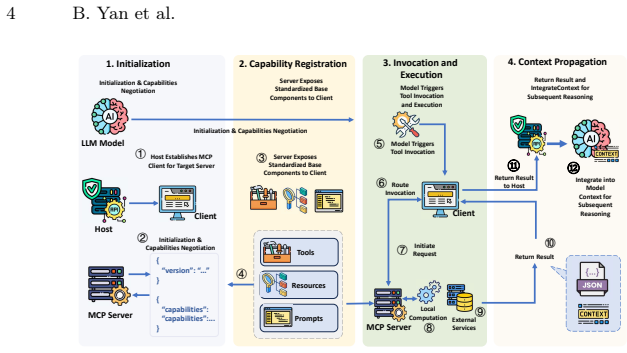
The Model Context Protocol (MCP) has rapidly become the de facto standard for connecting large language models (LLMs) to external resources, but it also introduces a class of privacy risks that existing tools are ill-equipped to detect. Unlike conventional exfiltration bugs, leakage in MCP servers is largely protocol-induced: credentials, API keys, and Personally Identifiable Information (PII) cross the local/LLM boundary simply by being returned, logged, or raised inside a tool handler, with no explicit outbound request in the source code. We present MCPPrivacyDetector, a context-aware cross-language static analysis framework that detects such leakage in multilingual MCP servers. MCPPrivacyDetector lifts heterogeneous code implemented across different programming language (e.g., Python) into a unified program representation, applies context-aware semantic filtering to isolate genuinely sensitive values and protocol-specific implicit sinks (e.g., @mcp.tool handlers), and performs taint analysis to enumerate feasible flows. Applied to 10,655 real-world MCP servers, MCPPrivacyDetector finds leakage rates above 10%. Case studies confirm concrete exposures including leaked Bearer tokens, propagated API keys, and plaintext authentication credentials, arguing for systematic, protocol-aware safeguards in the emerging LLM agent toolchain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MCPPrivacyDetector, a context-aware cross-language static analysis framework for detecting protocol-induced privacy leakages (e.g., credentials and PII crossing the local/LLM boundary) in Model Context Protocol (MCP) servers. It lifts multilingual code to a unified representation, applies semantic filtering for sensitive values and implicit sinks such as @mcp.tool handlers, performs taint analysis, and reports finding leakage rates above 10% when applied to 10,655 real-world MCP servers, supported by case studies of concrete exposures including Bearer tokens and API keys.
Significance. If the detector's accuracy holds, the work identifies an important new class of privacy risks in the emerging LLM-agent toolchain that conventional tools miss, with the large-scale empirical measurement (10k+ servers) providing a useful baseline for the community. The protocol-aware focus and cross-language lifting are novel contributions that could motivate systematic safeguards.
major comments (2)
- [Abstract and §4 (Evaluation)] Abstract and §4 (Evaluation): The central empirical claim of leakage rates above 10% relies on the correctness of context-aware semantic filtering and cross-language lifting, yet no precision, recall, false-positive rate, or validation against a ground-truth set is reported; this directly undermines confidence in the >10% figure and the case-study exposures.
- [§3 (Methodology)] §3 (Methodology): The description of how the unified program representation is constructed and how protocol-specific implicit sinks are identified lacks sufficient detail on handling of language-specific constructs or potential over- or under-approximations, which is load-bearing for the taint-analysis results.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief comparison table contrasting MCPPrivacyDetector with existing static analysis tools for exfiltration or taint tracking.
- [§3 (Methodology)] Figure captions and the description of the lifting step should explicitly note any assumptions about the completeness of the language front-ends used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The two major comments identify important gaps in evaluation and methodological detail that we will address through targeted revisions. Below we respond point-by-point.
read point-by-point responses
-
Referee: [Abstract and §4 (Evaluation)] Abstract and §4 (Evaluation): The central empirical claim of leakage rates above 10% relies on the correctness of context-aware semantic filtering and cross-language lifting, yet no precision, recall, false-positive rate, or validation against a ground-truth set is reported; this directly undermines confidence in the >10% figure and the case-study exposures.
Authors: We agree that the lack of quantitative precision/recall metrics and explicit ground-truth validation is a limitation that weakens confidence in the reported leakage rate. The >10% figure derives from running the detector over 10,655 servers with supporting case studies, but these do not substitute for systematic accuracy assessment. We will revise §4 to include a manual validation study on a statistically meaningful random sample of detections (e.g., 200 instances), reporting estimated precision and discussing sources of false positives. We will also add a threats-to-validity subsection addressing the difficulty of measuring recall at this scale. These additions will be incorporated in the revised manuscript. revision: yes
-
Referee: [§3 (Methodology)] §3 (Methodology): The description of how the unified program representation is constructed and how protocol-specific implicit sinks are identified lacks sufficient detail on handling of language-specific constructs or potential over- or under-approximations, which is load-bearing for the taint-analysis results.
Authors: We concur that §3 would benefit from greater specificity on the lifting process and sink identification. While the section outlines the cross-language IR and protocol-aware filtering, it does not provide concrete examples of language-specific handling (e.g., Python decorators or exception flows) or explicit discussion of over-/under-approximations. In the revision we will expand §3 with (1) pseudocode for the lifting algorithm, (2) worked examples showing how @mcp.tool handlers and return-value sinks are modeled across languages, and (3) a dedicated paragraph analyzing potential sources of imprecision in taint propagation. These changes will make the methodology reproducible and clarify the soundness assumptions. revision: yes
Circularity Check
Empirical measurement; no circular derivation
full rationale
The paper reports an empirical count of leakage instances obtained by running a newly constructed static-analysis tool on an external corpus of 10,655 servers. No equations, fitted parameters, self-citations, or ansatzes are used to derive the reported >10% rate; the result is a direct measurement whose validity rests on the tool's soundness rather than on any reduction to prior fitted values or self-referential premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Taint analysis on a unified program representation can accurately track sensitive data across language boundaries and MCP tool handlers.
invented entities (1)
-
MCPPrivacyDetector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aghili, R., Li, H., Khomh, F.: Protecting privacy in software logs: What should be anonymized? Proceedings of the ACM on Software Engineering2(FSE), 1317–1338 (2025)
2025
-
[2]
Anthropic: Introducing the model context protocol.https://www.anthropic.com/ news/model-context-protocol(2024), accessed: 2026-04-18
2024
-
[3]
In: 2023 ACM/IEEE International Sym- posium on Empirical Software Engineering and Measurement (ESEM)
Basak, S.K., Cox, J., Reaves, B., Williams, L.: A comparative study of software secrets reporting by secret detection tools. In: 2023 ACM/IEEE International Sym- posium on Empirical Software Engineering and Measurement (ESEM). pp. 1–12. IEEE (2023)
2023
-
[4]
arXiv preprint arXiv:2507.19880 (2025) Detecting Privacy Leakage Risks in MCP Servers 17
Croce, N., South, T.: Trivial trojans: How minimal mcp servers enable cross-tool exfiltration of sensitive data. arXiv preprint arXiv:2507.19880 (2025) Detecting Privacy Leakage Risks in MCP Servers 17
arXiv 2025
-
[5]
Advances in Neural Information Processing Systems37, 82895–82920 (2024)
Debenedetti, E., Zhang, J., Balunovic, M., Beurer-Kellner, L., Fischer, M., Tramèr, F.: Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. Advances in Neural Information Processing Systems37, 82895–82920 (2024)
2024
-
[6]
In: Proceedings 2025 Network and Distributed System Security Symposium
Dong, T., Xue, M., Chen, G., Holland, R., Meng, Y., Li, S., Liu, Z., Zhu, H.: The philosopher’s stone: Trojaning plugins of large language models. In: Proceedings 2025 Network and Distributed System Security Symposium. (2025)
2025
-
[7]
In: 2025 IEEE World AI IoT Congress (AIIoT)
Ehtesham, A., Singh, A., Kumar, S.: Enhancing clinical decision support and ehr insights through llms and the model context protocol: An open-source mcp-fhir framework. In: 2025 IEEE World AI IoT Congress (AIIoT). pp. 0205–0211 (2025)
2025
-
[8]
In: 2025 IEEE World AI IoT Congress (AIIoT)
Ehtesham, A., Singh, A., Kumar, S.: Enhancing clinical decision support and ehr insights through llms and the model context protocol: An open-source mcp-fhir framework. In: 2025 IEEE World AI IoT Congress (AIIoT). pp. 0205–0211. IEEE (2025)
2025
-
[9]
arXiv preprint arXiv:2506.13666 (2025)
Fang, J., Yao, Z., Wang, R., Ma, H., Wang, X., Chua, T.S.: We should identify and mitigate third-party safety risks in mcp-powered agent systems. arXiv preprint arXiv:2506.13666 (2025)
arXiv 2025
-
[10]
In: NDSS
Gordon, M.I., Kim, D., Perkins, J.H., Gilham, L., Nguyen, N., Rinard, M.C.: Infor- mation flow analysis of android applications in droidsafe. In: NDSS. vol. 15, p. 110 (2015)
2015
-
[11]
IEEE transactions on software engineering49(2), 902–923 (2022)
Gu, S., Rong, G., Zhang, H., Shen, H.: Logging practices in software engineering: A systematic mapping study. IEEE transactions on software engineering49(2), 902–923 (2022)
2022
-
[12]
arXiv preprint arXiv:2508.12538 (2025)
Guo, Y., Liu, P., Ma, W., Deng, Z., Zhu, X., Di, P., Xiao, X., Wen, S.: Systematic analysis of mcp security. arXiv preprint arXiv:2508.12538 (2025)
Pith/arXiv arXiv 2025
-
[13]
IEEE Transactions on Information Forensics and Security19, 722–734 (2023)
Han, R., Gong, H., Ma, S., Li, J., Xu, C., Bertino, E., Nepal, S., Ma, Z., Ma, J.: A credential usage study: flow-aware leakage detection in open-source projects. IEEE Transactions on Information Forensics and Security19, 722–734 (2023)
2023
-
[14]
arXiv preprint arXiv:2602.14878 (2026)
Hasan, M.M., Li, H., Rajbahadur, G.K., Adams, B., Hassan, A.E.: Model context protocol (mcp) tool descriptions are smelly! towards improving ai agent efficiency with augmented mcp tool descriptions. arXiv preprint arXiv:2602.14878 (2026)
Pith/arXiv arXiv 2026
-
[15]
ACM Transactions on Software Engineering and Methodology (2025)
Hou, X., Zhao, Y., Wang, S., Wang, H.: Model context protocol (mcp): Landscape, security threats, and future research directions. ACM Transactions on Software Engineering and Methodology (2025)
2025
-
[16]
Journal of Computer Science and Digital Technolo- gies1(1), 50–59 (2025)
Karimova, S., Dadashova, U.: The model context protocol: A standardization anal- ysis for application integration. Journal of Computer Science and Digital Technolo- gies1(1), 50–59 (2025)
2025
-
[17]
arXiv preprint arXiv:2504.12757 (2025)
Kumar, S., Girdhar, A., Patil, R., Tripathi, D.: Mcp guardian: A security-first layer for safeguarding mcp-based ai system. arXiv preprint arXiv:2504.12757 (2025)
arXiv 2025
-
[18]
arXiv preprint arXiv:1404.7431 (2014)
Li, L., Bartel, A., Klein, J., Traon, Y.L., Arzt, S., Rasthofer, S., Bodden, E., Octeau, D., Mcdaniel, P.: I know what leaked in your pocket: uncovering privacy leaks on android apps with static taint analysis. arXiv preprint arXiv:1404.7431 (2014)
Pith/arXiv arXiv 2014
-
[19]
arXiv preprint arXiv:2602.03580 (2026)
Li, Z., Ma, B., Dai, X., Xu, M., Zhang, Y., Yan, B., Li, K.: Don’t believe every- thing you read: Understanding and measuring mcp behavior under misleading tool descriptions. arXiv preprint arXiv:2602.03580 (2026)
arXiv 2026
-
[20]
In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security
Liu, T., Deng, Z., Meng, G., Li, Y., Chen, K.: Demystifying rce vulnerabilities in llm-integrated apps. In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. pp. 1716–1730 (2024) 18 B. Yan et al
2024
-
[21]
In: 33rd USENIX Security Symposium (USENIX Security 24)
Liu, Y., Jia, Y., Geng, R., Jia, J., Gong, N.Z.: Formalizing and benchmarking prompt injection attacks and defenses. In: 33rd USENIX Security Symposium (USENIX Security 24). pp. 1831–1847 (2024)
2024
-
[22]
In: 2025 IEEE Symposium on Security and Privacy (SP)
Liu, Y., Jia, Y., Jia, J., Song, D., Gong, N.Z.: Datasentinel: A game-theoretic detection of prompt injection attacks. In: 2025 IEEE Symposium on Security and Privacy (SP). pp. 2190–2208. IEEE (2025)
2025
-
[23]
Model Context Protocol: Model context protocol.https:// modelcontextprotocol.io/specification/2025-03-26(Mar 2025), version 2025-03-26
2025
-
[24]
Accessed: 2026-04-18
Model Context Protocol: What is the model context protocol (mcp)?https: //modelcontextprotocol.io/docs/getting-started/intro(2026), official doc- umentation. Accessed: 2026-04-18
2026
-
[25]
arXiv preprint arXiv:2504.03767 (2025)
Radosevich, B., Halloran, J.: Mcp safety audit: Llms with the model context pro- tocol allow major security exploits. arXiv preprint arXiv:2504.03767 (2025)
arXiv 2025
-
[26]
arXiv preprint arXiv:2510.02325 (2025)
Shehab, M.A.: Agentic-ai healthcare: Multilingual, privacy-first framework with mcp agents. arXiv preprint arXiv:2510.02325 (2025)
arXiv 2025
-
[27]
do anything now
Shen, X., Chen, Z., Backes, M., Shen, Y., Zhang, Y.: "do anything now": Char- acterizing and evaluating in-the-wild jailbreak prompts on large language models. In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Com- munications Security. pp. 1671–1685 (2024)
2024
-
[28]
In: Proceedings of the 24th Workshop on Privacy in the Electronic Society
Sun, Y., Du, L., Su, Z., Wang, Y., Liu, H., Zhao, Q., Niu, X.: Msa: A cross-mcp privacy attack via memory exfiltration of large language models. In: Proceedings of the 24th Workshop on Privacy in the Electronic Society. pp. 177–182 (2025)
2025
-
[29]
In: 2025 3rd International Conference on Inventive Computing and Informatics (ICICI)
T, S., Chandran, A.A., L, G., M, P.: Smart air quality monitoring with model context protocol for environmental safety technology. In: 2025 3rd International Conference on Inventive Computing and Informatics (ICICI). pp. 01–07 (2025)
2025
-
[30]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Wang, B., He, W., Zeng, S., Xiang, Z., Xing, Y., Tang, J., He, P.: Unveiling privacy risks in llm agent memory. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 25241– 25260 (2025)
2025
-
[31]
In: 34rd USENIX Security Symposium (USENIX Security 25) (2025)
Wang, Y., Zou, W., Geng, R., Jia, J., Model, R.: Tracllm: A generic framework for attributing long context llms. In: 34rd USENIX Security Symposium (USENIX Security 25) (2025)
2025
-
[32]
In: First conference on language modeling (2024)
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., et al.: Autogen: Enabling next-gen llm applications via multi- agent conversations. In: First conference on language modeling (2024)
2024
-
[33]
In: 34rd USENIX Security Symposium (USENIX Security 25) (2025)
Yang, Y., Li, C., Li, Q., Ma, O., Wang, H., Wang, Z., Gao, Y., Chen, W., Ji, S., Model, R.: Prsa: Prompt stealing attacks against real-world prompt services. In: 34rd USENIX Security Symposium (USENIX Security 25) (2025)
2025
-
[34]
In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Yi, J., Xie, Y., Zhu, B., Kiciman, E., Sun, G., Xie, X., Wu, F.: Benchmarking and defending against indirect prompt injection attacks on large language models. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. pp. 1809–1820 (2025)
2025
-
[35]
In: Findings of the As- sociation for Computational Linguistics: ACL 2024
Zhan, Q., Liang, Z., Ying, Z., Kang, D.: Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In: Findings of the As- sociation for Computational Linguistics: ACL 2024. pp. 10471–10506 (2024)
2024
-
[36]
arXiv preprint arXiv:2411.01344 (2024) Detecting Privacy Leakage Risks in MCP Servers 19
Zhang, Z., Guo, B., Li, T.: Privacy leakage overshadowed by views of ai: A study on human oversight of privacy in language model agent. arXiv preprint arXiv:2411.01344 (2024) Detecting Privacy Leakage Risks in MCP Servers 19
arXiv 2024
-
[37]
arXiv preprint arXiv:2509.06572 (2025)
Zhao, S., Hou, Q., Zhan, Z., Wang, Y., Xie, Y., Guo, Y., Chen, L., Li, S., Xue, Z.: Mind your server: A systematic study of parasitic toolchain attacks on the mcp ecosystem. arXiv preprint arXiv:2509.06572 (2025)
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.