Action-Gradient Monte Carlo Tree Search for Non-Parametric Continuous (PO)MDPs
Pith reviewed 2026-05-23 00:05 UTC · model grok-4.3
The pith
AGMCTS combines global tree search with local gradient-based action refinement for continuous (PO)MDPs while keeping value estimates consistent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AGMCTS combines global tree search with local gradient-based action refinement while maintaining consistent value estimates, supported by an action score gradient theorem for particle belief states, the Multiple Importance Sampling Tree, and tractable gradients via the Area Formula.
What carries the argument
The Multiple Importance Sampling Tree that supports frequent action-branch updates by reusing prior samples without introducing estimator drift.
If this is right
- Enables frequent action-branch updates in the search tree using reused samples.
- Provides tractable action score gradients for smooth generative models.
- Maintains consistent value estimates across action refinements.
- Outperforms state-of-the-art sample-based solvers on multiple continuous MDP and POMDP benchmarks.
Where Pith is reading between the lines
- The sample-reuse mechanism could apply to other sampling-based planners that face frequent action updates.
- Gradient refinement may lower sample requirements in higher-dimensional continuous spaces than those tested.
- Deployment on physical systems with real sensor noise would test whether the particle-belief gradients remain effective outside simulation.
Load-bearing premise
The Multiple Importance Sampling Tree re-uses prior samples for frequent action-branch updates without introducing estimator drift.
What would settle it
A demonstration of estimator drift when reusing samples under the MIS Tree weighting scheme, or AGMCTS failing to outperform sample-based baselines on the continuous MDP and POMDP benchmarks, would challenge the central claim.
Figures



read the original abstract
Online planning in continuous state, action, and observation spaces remains challenging for autonomous systems. While Monte Carlo Tree Search (MCTS) scales effectively via sampling, most continuous (PO)MDP solvers do not exploit gradient-based action optimization. We propose Action-Gradient MCTS (AGMCTS), a framework that combines global tree search with local gradient-based action refinement, while maintaining consistent value estimates. We provide three key theoretical contributions: (1) an action score gradient theorem for particle belief states; (2) the Multiple Importance Sampling (MIS) Tree that supports frequent action-branch updates by reusing prior samples without introducing estimator drift; and (3) tractable action score gradients for smooth generative models using the Area Formula. Empirical results demonstrate that AGMCTS outperforms state-of-the-art sample-based solvers in multiple challenging continuous MDP and POMDP benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Action-Gradient Monte Carlo Tree Search (AGMCTS) for online planning in continuous-state, continuous-action, continuous-observation (PO)MDPs. It combines global tree search with local gradient-based action refinement while preserving consistent value estimates, via three claimed theoretical results: (1) an action-score gradient theorem for particle belief states, (2) a Multiple Importance Sampling (MIS) Tree that re-uses prior samples for frequent action-branch updates without estimator drift, and (3) tractable gradients obtained from the Area Formula for smooth generative models. Empirical results are reported to show outperformance versus prior sample-based solvers on several continuous MDP and POMDP benchmarks.
Significance. If the central consistency claim holds, the work would provide a principled way to inject gradient information into MCTS without sacrificing the unbiasedness properties required for value estimates in non-parametric continuous settings. The combination of global search and local refinement, together with the sample-reuse mechanism, could improve sample efficiency in high-dimensional planning problems where pure sampling or pure gradient methods each have known limitations.
major comments (2)
- [Multiple Importance Sampling Tree] The Multiple Importance Sampling Tree section: the central claim that prior samples can be re-used for frequent action-branch updates without introducing estimator drift is load-bearing for the consistency guarantee between tree values and action-score gradients. The manuscript must supply the explicit importance-weighting scheme and a derivation showing that the weights exactly compensate for the change in the action-branch sampling distribution after each gradient refinement step; without this, any alteration in the effective proposal (due to particle belief updates or refined actions) risks bias.
- [Action score gradient theorem] Action score gradient theorem section (particle belief states): the theorem is stated to support consistent gradients, yet the manuscript provides no explicit statement of the conditions under which the particle approximation preserves the gradient unbiasedness when the generative model is only approximately known or when the belief support changes.
minor comments (2)
- [Empirical results] The abstract and empirical section omit error-bar reporting, number of independent runs, and precise benchmark descriptions; these details are required to assess whether the reported outperformance is robust.
- [Tractable gradients via Area Formula] Notation for the Area Formula application should be cross-referenced to the precise statement of the generative model smoothness assumptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: [Multiple Importance Sampling Tree] The Multiple Importance Sampling Tree section: the central claim that prior samples can be re-used for frequent action-branch updates without introducing estimator drift is load-bearing for the consistency guarantee between tree values and action-score gradients. The manuscript must supply the explicit importance-weighting scheme and a derivation showing that the weights exactly compensate for the change in the action-branch sampling distribution after each gradient refinement step; without this, any alteration in the effective proposal (due to particle belief updates or refined actions) risks bias.
Authors: We agree that an explicit importance-weighting scheme and derivation are essential to substantiate the unbiasedness claim. The current manuscript describes the MIS Tree mechanism at a high level but does not include the full weighting formulas or the step-by-step proof that the weights compensate for post-refinement distribution shifts. In the revised manuscript we will add a dedicated subsection with the precise importance weights (derived from the ratio of the original and updated action-branch proposals) and the accompanying derivation showing that the combined estimator remains unbiased under the stated assumptions. revision: yes
-
Referee: [Action score gradient theorem] Action score gradient theorem section (particle belief states): the theorem is stated to support consistent gradients, yet the manuscript provides no explicit statement of the conditions under which the particle approximation preserves the gradient unbiasedness when the generative model is only approximately known or when the belief support changes.
Authors: We acknowledge that the theorem statement would benefit from an explicit list of assumptions. The current version assumes an exact generative model and a fixed particle support for the belief; under these conditions the particle-based gradient estimator is unbiased. In the revision we will add a paragraph stating these assumptions clearly, together with a brief discussion of the bias that can arise when the model is only approximate or when particle support changes (e.g., via resampling), including a reference to standard particle-filter convergence results. revision: yes
Circularity Check
No significant circularity; claims rest on stated theorems without reduction to inputs
full rationale
The provided abstract and context present three theoretical contributions—an action score gradient theorem, the MIS Tree for sample reuse without drift, and tractable gradients via the Area Formula—without any equations, fitted parameters, or self-citations that reduce the claimed results to their own inputs by construction. No self-definitional patterns, fitted-input predictions, or load-bearing self-citations appear in the text. The derivation chain is therefore self-contained against external benchmarks, with the central consistency claim depending on the validity of the weighting scheme rather than tautological redefinition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Action-Gradient MCTS (AGMCTS), a framework that combines global tree search with local gradient-based action refinement, while maintaining consistent value estimates. We provide three key theoretical contributions: (1) an action score gradient theorem for particle belief states; (2) the Multiple Importance Sampling (MIS) Tree...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2. If the weighting strategy wi satisfies assumption (MIS-I) and (MIS-II), then the MIS tree yields unbiased estimates...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Continuous upper confidence trees
Adrien Couëtoux, Jean-Baptiste Hoock, Nataliya Sokolovska, Olivier Teytaud, and Nicolas Bonnard. Continuous upper confidence trees. In Learning and Intelligent Optimization: 5th International Conference, LION 5, Rome, Italy, January 17-21, 2011. Selected Papers 5, pages 433–445. Springer, 2011
work page 2011
-
[2]
Online algorithms for pomdps with continuous state, action, and observation spaces
Zachary Sunberg and Mykel Kochenderfer. Online algorithms for pomdps with continuous state, action, and observation spaces. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 28, 2018
work page 2018
-
[3]
Beomjoon Kim, Kyungjae Lee, Sungbin Lim, Leslie Kaelbling, and Tomás Lozano-Pérez. Monte carlo tree search in continuous spaces using voronoi optimistic optimization with regret bounds. In AAAI Conf. on Artificial Intelligence, volume 34, pages 9916–9924, 2020
work page 2020
-
[4]
Michael H Lim, Claire J Tomlin, and Zachary N Sunberg. V oronoi progressive widening: efficient online solvers for continuous state, action, and observation pomdps. In2021 60th IEEE conference on decision and control (CDC), pages 4493–4500. IEEE, 2021
work page 2021
-
[5]
Adaptive discretization using voronoi trees for continuous pomdps
Marcus Hoerger, Hanna Kurniawati, Dirk Kroese, and Nan Ye. Adaptive discretization using voronoi trees for continuous pomdps. The International Journal of Robotics Research, 43(9): 1283–1298, 2024
work page 2024
-
[6]
Monte carlo tree search in continuous action spaces with execution uncertainty
Timothy Yee, Viliam Lis`y, Michael H Bowling, and S Kambhampati. Monte carlo tree search in continuous action spaces with execution uncertainty. In IJCAI, pages 690–697, 2016
work page 2016
-
[7]
Continuous state-action-observation pomdps for trajectory planning with bayesian optimisation
Philippe Morere, Roman Marchant, and Fabio Ramos. Continuous state-action-observation pomdps for trajectory planning with bayesian optimisation. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 8779–8786. IEEE, 2018
work page 2018
-
[8]
Bayesian optimized monte carlo planning
John Mern, Anil Yildiz, Zachary Sunberg, Tapan Mukerji, and Mykel J Kochenderfer. Bayesian optimized monte carlo planning. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 35, pages 11880–11887, 2021
work page 2021
-
[9]
Monte-carlo tree search in continuous action spaces with value gradients
Jongmin Lee, Wonseok Jeon, Geon-Hyeong Kim, and Kee-Eung Kim. Monte-carlo tree search in continuous action spaces with value gradients. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 4561–4568, 2020
work page 2020
-
[10]
Policy gradient meth- ods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient meth- ods for reinforcement learning with function approximation. Advances in neural information processing systems, 12, 1999
work page 1999
-
[11]
Trust region policy optimization of pomdps
Kamyar Azizzadenesheli, Yisong Yue, and Animashree Anandkumar. Policy gradient in partially observable environments: Approximation and convergence. arXiv preprint arXiv:1810.07900, 2018
-
[12]
A policy gradient method for confounded POMDPs
Mao Hong, Zhengling Qi, and Yanxun Xu. A policy gradient method for confounded POMDPs. In The Twelfth International Conference on Learning Representations , 2024. URL https: //openreview.net/forum?id=8BAkNCqpGW. x
work page 2024
-
[13]
Monte-carlo graph search: the value of merging similar states
Edouard Leurent and Odalric-Ambrym Maillard. Monte-carlo graph search: the value of merging similar states. In Sinno Jialin Pan and Masashi Sugiyama, editors, Asian Conference on Machine Learning (ACML 2020), pages 577 – 592, Bangkok, Thailand, November 18-20 2020
work page 2020
-
[14]
Previous knowledge utilization in online anytime belief space planning
Michael Novitsky, Moran Barenboim, and Vadim Indelman. Previous knowledge utilization in online anytime belief space planning. arXiv preprint arXiv:2412.13128, 2024
-
[15]
Optimally combining sampling techniques for monte carlo rendering
Eric Veach and Leonidas J Guibas. Optimally combining sampling techniques for monte carlo rendering. In Proceedings of the 22nd annual conference on Computer graphics and interactive techniques, pages 419–428. ACM, 1995
work page 1995
-
[16]
E. Farhi and V . Indelman. ix-bsp: Incremental belief space planning. arXiv preprint arXiv:2102.09539, 2021
-
[17]
A general reinforcement learning algorithm that masters chess, shogi, and go through self-play
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144, 2018
work page 2018
-
[18]
Moss, Anthony Corso, Jef Caers, and Mykel J
Robert J. Moss, Anthony Corso, Jef Caers, and Mykel J. Kochenderfer. BetaZero: Belief- State Planning for Long-Horizon POMDPs using Learned Approximations. In Reinforcement Learning Conference (RLC), 2024
work page 2024
-
[19]
R.S. Sutton and A.G. Barto. Reinforcement Learning: An Introduction . The MIT press, Cambridge, MA, 1998
work page 1998
-
[20]
L. P. Kaelbling, M. L. Littman, and A. R. Cassandra. Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1):99–134, 1998
work page 1998
- [21]
- [22]
-
[23]
A. Kong, J. S. Liu, and W. H. Wong. Sequential imputations and Bayesian missing data problems. Journal of the American Statistical Association, 89(425):278–288, 1994
work page 1994
-
[24]
A survey of monte carlo tree search methods
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012
work page 2012
-
[25]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. In European conference on machine learning, pages 282–293. Springer, 2006
work page 2006
-
[26]
Real analysis: modern techniques and their applications
Gerald B Folland. Real analysis: modern techniques and their applications . John Wiley & Sons, 1999
work page 1999
-
[27]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Sample distribution theory using coarea formula
Luigi Negro. Sample distribution theory using coarea formula. Communications in Statistics- Theory and Methods, pages 1–26, 2022
work page 2022
-
[29]
Scalable differentiable physics for learning and control
Yi-Ling Qiao, Junbang Liang, Vladlen Koltun, and Ming Lin. Scalable differentiable physics for learning and control. In International Conference on Machine Learning, pages 7847–7856. PMLR, 2020. xi
work page 2020
-
[30]
Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem
C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax - a differentiable physics engine for large scale rigid body simulation. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021. URL https://openreview.net/forum?id=VdvDlnnjzIN
work page 2021
-
[31]
Dojo: A differentiable physics engine for robotics, 2022
Taylor Howell, Simon Le Cleac’h, Jan Bruedigam, Zico Kolter, Mac Schwager, and Zachary Manchester. Dojo: A differentiable physics engine for robotics, 2022. URL https://arxiv. org/abs/2203.00806
-
[32]
Pomdps.jl: A framework for sequential decision making under uncertainty
Maxim Egorov, Zachary N Sunberg, Edward Balaban, Tim A Wheeler, Jayesh K Gupta, and Mykel J Kochenderfer. Pomdps.jl: A framework for sequential decision making under uncertainty. The Journal of Machine Learning Research, 18(1):831–835, 2017
work page 2017
-
[33]
Instead of rewriting foreign code for machine learning, automatically synthesize fast gradients
William Moses and Valentin Churavy. Instead of rewriting foreign code for machine learning, automatically synthesize fast gradients. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 12472–12485. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/...
work page 2020
-
[34]
Forward-Mode Automatic Differentiation in Julia
J. Revels, M. Lubin, and T. Papamarkou. Forward-mode automatic differentiation in Julia, 2016. URL https://arxiv.org/abs/1607.07892
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Universal differential equations for scientific machine learning, 2020
Christopher Rackauckas, Yingbo Ma, Julius Martensen, Collin Warner, Kirill Zubov, Rohit Supekar, Dominic Skinner, and Ali Ramadhan. Universal differential equations for scientific machine learning, 2020
work page 2020
-
[36]
Reinforcement learning with replacing eligibility traces
Satinder P Singh and Richard S Sutton. Reinforcement learning with replacing eligibility traces. Machine learning, 22:123–158, 1996
work page 1996
-
[37]
Tree-based batch mode reinforcement learning
Damien Ernst, Pierre Geurts, and Louis Wehenkel. Tree-based batch mode reinforcement learning. Journal of Machine Learning Research, 6, 2005
work page 2005
-
[38]
Differentiation under the integral sign with weak derivatives, 2006
Steve Cheng. Differentiation under the integral sign with weak derivatives, 2006. URL https://planetmath.org/differentiationundertheintegralsign. [Online]
work page 2006
-
[39]
Optimality guarantees for particle belief approximation of pomdps
Michael H Lim, Tyler J Becker, Mykel J Kochenderfer, Claire J Tomlin, and Zachary N Sunberg. Optimality guarantees for particle belief approximation of pomdps. Journal of Artificial Intelligence Research, 77:1591–1636, 2023
work page 2023
-
[40]
Reuven Y Rubinstein and Dirk P Kroese. The cross-entropy method: a unified approach to combinatorial optimization, Monte-Carlo simulation and machine learning. Springer Science & Business Media, 2004
work page 2004
-
[41]
Zdravko I Botev, Dirk P Kroese, Reuven Y Rubinstein, and Pierre L’ecuyer. The cross-entropy method for optimization. In Handbook of statistics, volume 31, pages 35–59. Elsevier, 2013. xii A Proofs and Derivations A.1 Theorem 1 We first highlight that the required "well-behaved" conditions for the theorem are for changing the order of derivatives and integ...
work page 2013
-
[42]
Suppose that there exists g ∈ L1(µ) such that |f(x, t)| ≤ g(x) for all x, t. If limt→t0 f(x, t) = f(x, t0) for every x, then limt→t0 F (t) = F (t0); in particular, if f(x, ·) is continuous for each x, then F is continuous
-
[43]
Suppose that ∂f /∂t exists and there is a g ∈ L1(µ) such that |∂f /∂t(x, t)| ≤ g(x) for all x, t. Then F is differentiable and F ′ = R (∂f /∂t)(x, t) dµ(x). More general versions of the theorem have been proven [38]. As this is not the focus of our work, we leave the formalization of Theorem 1 general. We note that Lebesgue integrability may hold for a ve...
-
[44]
MDP: n ≜ (n(s′,i)+1)M i=1, (102) PB-MDP: n ≜ (n(¯b′,i)+1)M i=1
Child state visitation counters. MDP: n ≜ (n(s′,i)+1)M i=1, (102) PB-MDP: n ≜ (n(¯b′,i)+1)M i=1. (103)
-
[45]
MDP: p = (pT (s′,i | s, a))M i=1, (104) PB-MDP: p = (pT (¯b−,i | ¯b, a))M i=1
Target transition likelihoods. MDP: p = (pT (s′,i | s, a))M i=1, (104) PB-MDP: p = (pT (¯b−,i | ¯b, a))M i=1. (105)
-
[46]
MDP: q = (pT (s′,i | s, aprop(s′,i)))M i=1, (106) PB-MDP: q = (pT (¯b−,i | ¯b, aprop(¯b−,i)))M i=1
Proposal transition likelihoods. MDP: q = (pT (s′,i | s, aprop(s′,i)))M i=1, (106) PB-MDP: q = (pT (¯b−,i | ¯b, aprop(¯b−,i)))M i=1. (107)
-
[47]
MDP: r = (r(s, a, s′,i))M i=1 (108) PB-MDP: r = (r(¯b, a, ¯b′,i))M i=1
Immediate rewards. MDP: r = (r(s, a, s′,i))M i=1 (108) PB-MDP: r = (r(¯b, a, ¯b′,i))M i=1. (109)
-
[48]
Future value estimates. MDP: v = ( ˆV (s′,i))M i=1 (110) PB-MDP: v = ( ˆV (¯b′,i))M i=1 (111) From here on, the PB-MDP case is the same up to different notations as the MDP case, and we will show only the latter. Using these notations the immediate reward and future value estimates can be compactly written: η(s, a) = 1T (n ⊙ p ⊘ q), (112) ˆr(s, a) = η(s, ...
-
[49]
Log likelihoods l(p) and l(q)
-
[50]
n′ and previous visitation counters n
-
[51]
v′ and previous future value estimates v. The equations for ˆr(s, a) are analogous to ˆVf(s, a), and we will not show their derivation explicitly. xx Action Backpropagation. Let s′,j be an updated node. Hence, we updated nj to n′ j and vj to v′ j. We update n(s, a) by (98) and perform η′(s, a) = η(s, a) + pj qj n′ j − nj , (115) ˆV ′ f(s, a) = 1 η′(s, a) ...
-
[52]
Constant hyperparameters were defined for each algorithm, including simulation budget nsims, particle count J, and rollout policy
-
[53]
A cross-entropy (CE) optimization was performed over the UCB, DPW and step size (where applicable) for each algorithm
-
[54]
For the best performing hyperparameters of each algorithm, we ran 1000 simula- tions of the algorithm with the same seeds between algorithms, at the multiples [10−1, 10−0.75, 10−0.5, 10−0.25, 1.0] of the simulation budget nsims. The simulation jobs were run on a distributed cluster of 8 machines with different cores and con- figurations, using the Julia p...
-
[55]
Ryzen 7 3700X 8-Core (16 threads) Processor
-
[56]
Intel i7-6820HQ 4-Core (8 threads) Processor
-
[57]
Intel i7-8550U 4-Core (8 threads) Processor
-
[58]
Intel E3-1241 v3 4-Core (8 threads) Processor. xxv Table 1: Hyperparameters optimized by CE in the evaluations of each algorithm in the D-Continuous Light-Dark, Mountain Car, Hill Car and Lunar Lander domains. Parameter Notation Explanation Algorithms Tuning c UCT exploration bonus All CE ka Action prog. widening factor All CE αa Action prog. widening pow...
-
[59]
Intel E5-1620 v4 4-Core (8 threads) Processor
-
[60]
Intel i9-7920X 12-Core (24 threads) Processor
-
[61]
Intel i9-11900K 8-Core (16 threads) Processor
-
[62]
Intel i9-12900K 12-Core (24 threads) Processor. C.1.1 Simulation Budget Since POMCPOW is a state-trajectory algorithm, in the POMDP scenarios we measured empirically the runtime of PFT-DPW at nsims and J, and set a larger simulation budget for POMCPOW nsims,POMCPOW to match the runtime of PFT-DPW. C.1.2 Rollout Policy In order to save computation time and...
-
[63]
UCT exploration bonus c
-
[64]
Action progressive widening parameters ka and αa
-
[65]
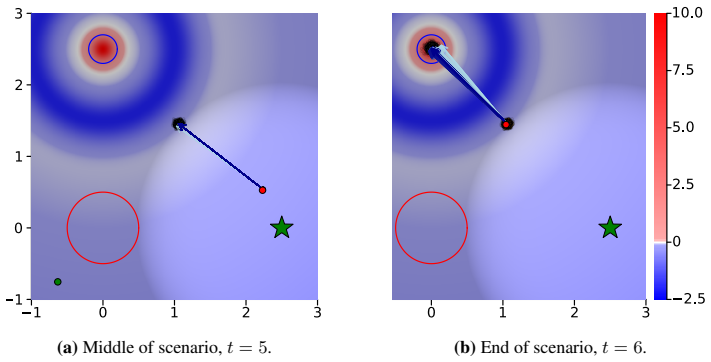
Observation progressive widening parameters ko and αo. For AGMCTS, we also optimized over the Adam learning rate ηAdam, and the action update distance threshold T min da only in the Light-Dark domains. xxvi (a) Middle of scenario, t = 5. (b) End of scenario, t = 6. Figure 4: AGMCTS at 2-Continuous Light-Dark. The agent’s current state is the red dot, the ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.