Self-Harness: Harnesses That Improve Themselves
Pith reviewed 2026-06-27 16:24 UTC · model grok-4.3
The pith
An LLM-based agent can improve its own harness by mining model-specific failures from traces and proposing minimal edits that pass regression tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
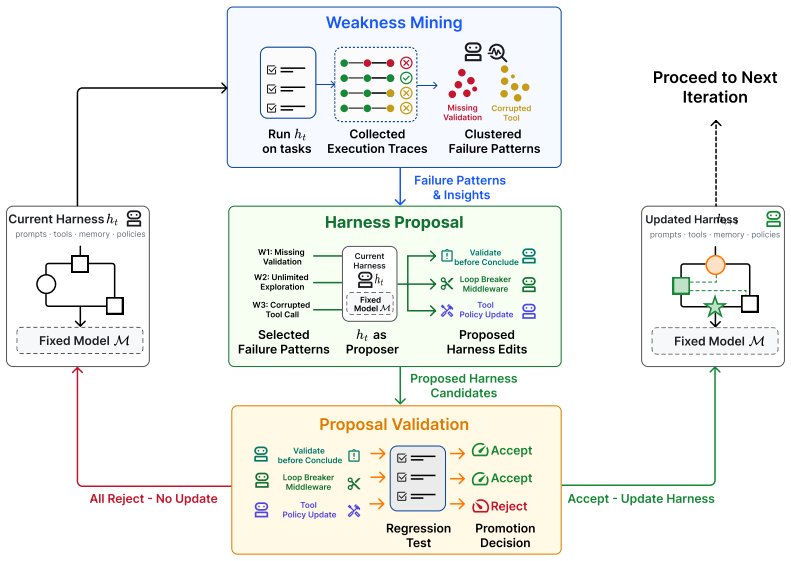
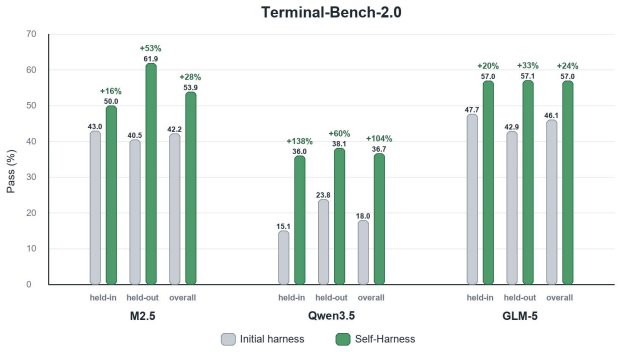
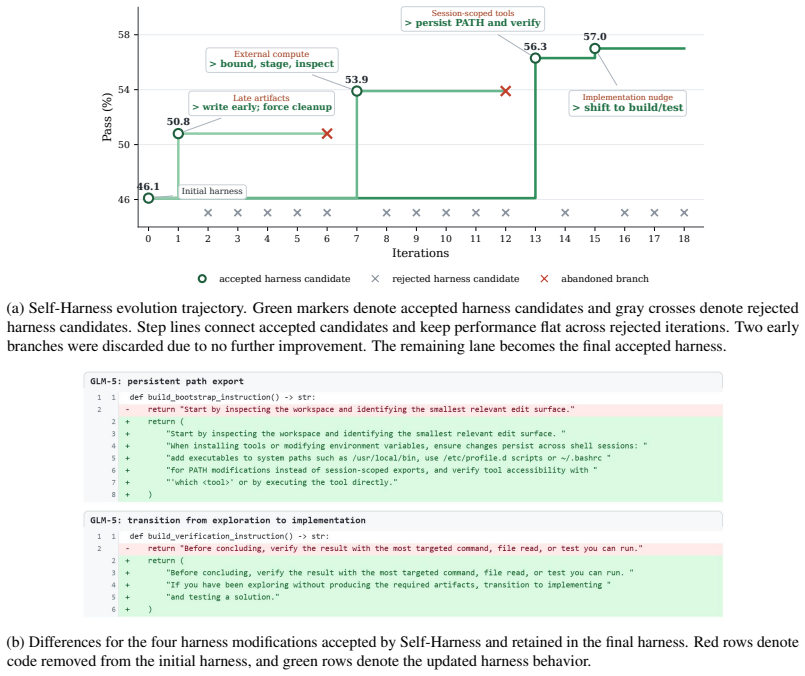
Self-Harness is realized as a three-stage loop—Weakness Mining extracts recurring failure patterns from execution traces, Harness Proposal generates diverse but minimal edits tied to those patterns, and Proposal Validation accepts an edit only after it passes regression testing on held-out tasks. When run on Terminal-Bench-2.0 starting from a minimal harness, the loop raised held-out pass rates from 40.5 % to 61.9 % for MiniMax M2.5, from 23.8 % to 38.1 % for Qwen3.5-35B-A3B, and from 42.9 % to 57.1 % for GLM-5. The resulting harnesses contain concrete, executable changes rather than generic instructions, and the gains are specific to each model’s observed weaknesses.
What carries the argument
The Self-Harness iterative loop of Weakness Mining, Harness Proposal, and Proposal Validation that turns execution traces into model-specific harness edits.
If this is right
- Harness design becomes model-specific and automatic rather than manually engineered once per model family.
- Performance gains appear without access to stronger external agents or human-written instructions beyond the initial minimal harness.
- Qualitative inspection shows edits address concrete failure modes instead of adding blanket rules.
- The same loop can be restarted on any new base model using only its own traces.
Where Pith is reading between the lines
- The approach could let newly released models begin improving their own harnesses within hours of deployment rather than waiting for expert updates.
- If the mining step generalizes, similar loops might be applied to other agent components such as tool-use formats or memory structures.
- Repeated iterations might produce harnesses that become increasingly specialized to a single model’s error distribution.
Load-bearing premise
The LLM can accurately extract model-specific failure patterns from traces and generate minimal, non-regressive harness edits that generalize beyond the traces used for mining.
What would settle it
Applying the final harnesses produced by Self-Harness to a fresh set of tasks drawn from the same benchmark distribution yields no net gain or produces regressions on more than half the tasks.
Figures






read the original abstract
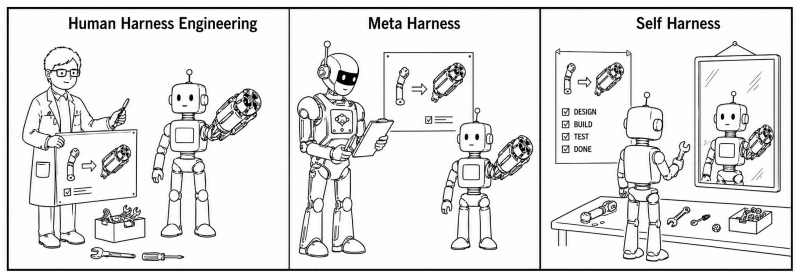
The performance of LLM-based agents is jointly shaped by their base models and the harnesses that mediate their interaction with the environment. Because different models exhibit distinct behaviors, effective harness design is inherently model-specific. Yet agent harnesses are still largely engineered by human experts, a paradigm that scales poorly as modern LLMs become increasingly diverse and rapidly evolving. In this paper, we introduce Self-Harness, a new paradigm in which an LLM-based agent improves its own operating harness, without relying on human engineers or stronger external agents. We operationalize Self-Harness as an iterative loop with three stages: Weakness Mining, which identifies model-specific failure patterns from execution traces; Harness Proposal, which generates diverse yet minimal harness modifications tied to these failures; and Proposal Validation, which accepts candidate edits only after regression testing. We instantiate Self-Harness on Terminal-Bench-2.0 using a minimal initial harness and three base models from diverse families: MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5. Across all three models, Self-Harness consistently improves performance, with held-out pass rates increasing from 40.5% to 61.9%, 23.8% to 38.1%, and 42.9% to 57.1%, respectively. Qualitative analyses further show that Self-Harness does not simply add generic instructions, but effectively turns model-specific weaknesses into concrete, executable harness changes. These results suggest a path toward LLM-based agents that are not merely shaped by their harnesses, but can also participate in reshaping them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Self-Harness, an iterative self-improvement loop for LLM agents consisting of Weakness Mining (extracting model-specific failure patterns from traces), Harness Proposal (generating minimal edits), and Proposal Validation (regression testing). Experiments on Terminal-Bench-2.0 with three base models (MiniMax M2.5, Qwen3.5-35B-A3B, GLM-5) report held-out pass-rate gains from 40.5% to 61.9%, 23.8% to 38.1%, and 42.9% to 57.1%, with qualitative claims that edits are model-specific rather than generic.
Significance. If the generalization mechanism holds, the work offers a concrete path to model-specific harness adaptation without external supervision or human engineers, addressing a scaling bottleneck as LLMs diversify. The use of an external validation stage and held-out evaluation is a positive design choice that reduces obvious circularity risks.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The headline gains are reported without any quantitative details on iteration count, total traces mined, edit diff sizes, or failure-pattern precision/recall. This makes it impossible to assess whether the held-out lift is driven by the claimed mechanism or by incidental effects of the iterative loop.
- [§3.2, §4.3] §3.2 (Harness Proposal) and §4.3 (Qualitative analysis): The claim that edits are 'minimal' and 'non-regressive' and generalize beyond mining traces is central to the contribution, yet no ablation against generic prompt lengthening or random edits is provided, nor is there a breakdown of how many proposals were rejected by Proposal Validation.
- [§4.1] §4.1 (Setup): The construction of the mining set versus the held-out set is not described with sufficient precision to rule out distributional overlap or trace leakage; regression testing alone does not guarantee transfer if the validation slice shares task characteristics with the mining data.
minor comments (2)
- [§3] Notation for the three stages is introduced without a compact diagram or pseudocode listing the exact inputs/outputs of each stage.
- [§4] Table 1 (or equivalent results table) should report per-model iteration counts and number of accepted edits to allow readers to gauge computational cost.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and indicate where revisions to the manuscript are planned.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The headline gains are reported without any quantitative details on iteration count, total traces mined, edit diff sizes, or failure-pattern precision/recall. This makes it impossible to assess whether the held-out lift is driven by the claimed mechanism or by incidental effects of the iterative loop.
Authors: We agree that the current presentation in the abstract and §4 omits these operational details, which limits interpretability of the results. In the revised manuscript we will expand §4 with a dedicated subsection (and corresponding table) that reports iteration counts per model, total traces processed during mining, average token-level edit sizes, and the precision/recall of the weakness-mining stage as measured against human-annotated failure patterns. These additions will make the scale and selectivity of the loop explicit without altering any performance numbers. revision: yes
-
Referee: [§3.2, §4.3] §3.2 (Harness Proposal) and §4.3 (Qualitative analysis): The claim that edits are 'minimal' and 'non-regressive' and generalize beyond mining traces is central to the contribution, yet no ablation against generic prompt lengthening or random edits is provided, nor is there a breakdown of how many proposals were rejected by Proposal Validation.
Authors: The manuscript currently supports minimality and non-regressiveness only through the design of Proposal Validation (regression testing on held-out tasks) and the qualitative examples in §4.3; no quantitative ablation or rejection-rate statistics are reported. We therefore plan a partial revision: we will add (i) a new paragraph in §4.3 reporting the fraction of proposals rejected by validation and (ii) a concise ablation subsection comparing our method against both random edits and generic prompt lengthening on the same held-out set. We maintain that the existing qualitative evidence already indicates model-specific rather than generic changes, but the requested ablation will strengthen that claim. revision: partial
-
Referee: [§4.1] §4.1 (Setup): The construction of the mining set versus the held-out set is not described with sufficient precision to rule out distributional overlap or trace leakage; regression testing alone does not guarantee transfer if the validation slice shares task characteristics with the mining data.
Authors: We acknowledge that §4.1 currently gives only a high-level statement of the split. In the revision we will replace this with an explicit description: tasks were partitioned by category (terminal command families) into a 60 % mining pool and a 40 % strictly held-out pool before any traces were collected; mining traces were generated exclusively on the mining pool; and the validation stage used only the held-out pool. This protocol eliminates trace leakage and reduces distributional overlap by construction. revision: yes
Circularity Check
No circularity; empirical gains rest on held-out validation
full rationale
The paper presents an iterative empirical procedure (Weakness Mining → Harness Proposal → Proposal Validation via regression testing) whose central claims are performance lifts measured on explicitly held-out tasks. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the provided text. The validation stage is described as an external check independent of the mining traces, rendering the reported improvements (40.5%→61.9%, etc.) falsifiable rather than tautological. This is the normal case of a self-contained experimental method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Catarena: Evaluation of llm agents through iterative tournament competitions
Lingyue Fu, Xin Ding, Linyue Pan, Yaoming Zhu, Shao Zhang, Lin Qiu, Weiwen Liu, Weinan Zhang, Xuezhi Cao, Xunliang Cai, Jiaxin Ding, and Yong Yu. Catarena: Evaluation of llm agents through iterative tournament competitions. InInternational Conference on Machine Learning. PMLR, 2026
2026
-
[2]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5 Team. Glm-5: from vibe coding to agentic engineering, 2026. URL https://arxiv. org/abs/2602.15763
Pith/arXiv arXiv 2026
-
[3]
Automated design of agentic systems, 2025
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems, 2025. URL https://arxiv.org/abs/2408.08435
Pith/arXiv arXiv 2025
-
[4]
Deepagents, 2026
LangChain. Deepagents, 2026. URL https://github.com/langchain-ai/deepagents. Software framework
2026
-
[5]
Meta-harness: End-to-end optimization of model harnesses, 2026
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses, 2026. URL https://arxiv.org/ abs/2603.28052
Pith/arXiv arXiv 2026
-
[6]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rocktaschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, 2020. URL https://arxiv.org/abs/2005.11401
Pith/arXiv arXiv 2020
-
[7]
Anticipatory planning for multimodal ai agents
Yongyuan Liang, Shijie Zhou, Yu Gu, Hao Tan, Gang Wu, Franck Dernoncourt, Jihyung Kil, Ryan A Rossi, and Ruiyi Zhang. Anticipatory planning for multimodal ai agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5925–5935, 2026
2026
-
[8]
Jiahang Lin, Shichun Liu, Chengjun Pan, Lizhi Lin, Shihan Dou, Zhiheng Xi, Xuanjing Huang, Hang Yan, Zhenhua Han, Tao Gui, and Yu-Gang Jiang. Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses, 2026. URL https:// arxiv.org/abs/2604.25850
Pith/arXiv arXiv 2026
-
[9]
Dive into claude code: The design space of today’s and future ai agent systems, 2026
Jiacheng Liu, Xiaohan Zhao, Xinyi Shang, and Zhiqiang Shen. Dive into claude code: The design space of today’s and future ai agent systems, 2026. URLhttps://arxiv.org/abs/ 2604.14228
Pith/arXiv arXiv 2026
-
[10]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing, 2021. URLhttps://arxiv.org/abs/2107.13586. 14
arXiv 2021
-
[11]
The ai scientist: Towards fully automated open-ended scientific discovery, 2024
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https: //arxiv.org/abs/2408.06292
Pith/arXiv arXiv 2024
-
[12]
A survey of context engineering for large language models, 2025
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, and Shenghua Liu. A survey of context engineering for large language models, 2025. URL https://arxiv.org/abs/2507.13334
Pith/arXiv arXiv 2025
-
[13]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
Pith/arXiv arXiv 2026
-
[14]
Minimax m2.5: Built for real-world productivity, February 2026
MiniMax. Minimax m2.5: Built for real-world productivity, February 2026. URL https: //www.minimax.io/news/minimax-m25. Official model report
2026
-
[15]
Alexander Novikov, Ngan Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algori...
Pith/arXiv arXiv 2025
-
[16]
Codex, 2026
OpenAI. Codex, 2026. URLhttps://openai.com/codex/. Product page
2026
-
[17]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[18]
Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023. URLhttps://arxiv.org/abs/2307.16789
Pith/arXiv arXiv 2023
-
[19]
Jiahao Qiu, Xuan Qi, Tongcheng Zhang, Xinzhe Juan, Jiacheng Guo, Yifu Lu, Yimin Wang, Zixin Yao, Qihan Ren, Xun Jiang, Xing Zhou, Dongrui Liu, Ling Yang, Yue Wu, Kaixuan Huang, Shilong Liu, Hongru Wang, and Mengdi Wang. Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self-evolution, 2025. URL https://arxi...
arXiv 2025
-
[20]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5. Official model report and model card for Qwen3.5-35B-A3B
2026
-
[21]
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, Pranav Sandeep Dulepet, Saurav Vidyadhara, Dayeon Ki, Sweta Agrawal, Chau Pham, Gerson Kroiz, Feileen Li, Hudson Tao, Ashay Srivastava, Hevander Da Costa, Saloni Gupta, Megan L. Rogers, Inna Goncearenco, G...
Pith/arXiv arXiv 2025
-
[22]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting, 2024. URLhttps://arxiv.org/abs/2310.11324
Pith/arXiv arXiv 2024
-
[23]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[24]
Openhands: An open platform for ai software developers as generalist agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. InInternational Conference on Learning Representations, volume 2025, pages 65882–65919, 2025
2025
-
[25]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022. URL https://arxiv. org/abs/2201.11903
Pith/arXiv arXiv 2022
-
[26]
Siyuan Xu, Shiyang Li, Xin Liu, Tianyi Liu, Yixiao Li, Zhan Shi, Zixuan Zhang, Zilong Wang, Qingyu Yin, Jianshu Chen, et al. Controllable and verifiable tool-use data synthesis for agentic reinforcement learning.arXiv preprint arXiv:2604.09813, 2026
Pith/arXiv arXiv 2026
-
[27]
The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025. URLhttps://arxiv.org/abs/2504.08066
Pith/arXiv arXiv 2025
-
[28]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering, 2024. URLhttps://arxiv.org/abs/2405.15793
Pith/arXiv arXiv 2024
-
[29]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[30]
Gödel agent: A self-referential agent framework for recursively self-improvement
Xunjian Yin, Xinyi Wang, Liangming Pan, Li Lin, Xiaojun Wan, and William Yang Wang. Gödel agent: A self-referential agent framework for recursively self-improvement. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 27890–27913, 2025. doi: 10.18653/v1/2025.acl-long.1354. URL https: //...
-
[31]
Self-taught optimizer (stop): Recursively self-improving code generation, 2024
Eric Zelikman, Eliana Lorch, Lester Mackey, and Adam Tauman Kalai. Self-taught optimizer (stop): Recursively self-improving code generation, 2024. URL https://arxiv.org/abs/ 2310.02304
arXiv 2024
-
[32]
Hangfan Zhang, Siyuan Xu, Zhimeng Guo, Huaisheng Zhu, Shicheng Liu, Xinrun Wang, Qiaosheng Zhang, Yang Chen, Peng Ye, Lei Bai, et al. The path of self-evolving large language models: Achieving data-efficient learning via intrinsic feedback.arXiv preprint arXiv:2510.02752, 2025
arXiv 2025
-
[33]
Darwin gödel machine: Open-ended evolution of self-improving agents, 2025
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. Darwin gödel machine: Open-ended evolution of self-improving agents, 2025. URL https://arxiv.org/abs/2505. 22954
2025
-
[34]
Agentic context engineering: Evolving contexts for self-improving language models, 2026
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models, 2026. URLhttps://arxiv.org/abs/2510.04618. ICLR 2026
Pith/arXiv arXiv 2026
-
[35]
Shao Zhang, Xihuai Wang, Wenhao Zhang, Chaoran Li, Junru Song, Tingyu Li, Lin Qiu, Xuezhi Cao, Xunliang Cai, Wen Yao, Weinan Zhang, Xinbing Wang, and Ying Wen. Leveraging dual process theory in language agent framework for real-time simultaneous human-AI collaboration. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors...
-
[36]
Semaclaw: A step towards general-purpose personal ai agents through harness engineering, 2026
Ningyan Zhu, Huacan Wang, Jie Zhou, Feiyu Chen, Shuo Zhang, Ge Chen, Chen Liu, Jiarou Wu, Wangyi Chen, Xiaofeng Mou, and Yi Xu. Semaclaw: A step towards general-purpose personal ai agents through harness engineering, 2026. URLhttps://arxiv.org/abs/2604.11548
Pith/arXiv arXiv 2026
-
[37]
Language agents as optimizable graphs, 2024
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Juergen Schmidhuber. Language agents as optimizable graphs, 2024. URL https://arxiv. org/abs/2402.16823. 17 A Additional Implementation Details A.1 Experimental details Model inference servicesMiniMax M2.5 and GLM-5 were accessed through hosted inference services, using Mi...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.