HJ-SafeDMP: Hamilton-Jacobi Reachability-Guided Dynamic Movement Primitives for Provably Safe Robot Motion
Pith reviewed 2026-06-30 09:24 UTC · model grok-4.3
The pith
HJ-SafeDMP learns a Control Barrier Value Function offline from demonstrations and uses it to modulate DMP outputs via a closed-form law, delivering formal safety without online optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HJ-SafeDMP integrates DMPs with a learned Control Barrier Value Function obtained via offline model-free finite-difference HJ recursion; the function is deployed as a closed-form safety filter that modulates DMP outputs to render the safe set forward-invariant, yielding formal safety certificates without requiring online quadratic-program solves.
What carries the argument
The Control Barrier Value Function (CBVF), learned from demonstration data and applied through a closed-form modulation law that overrides unsafe DMP commands.
If this is right
- Safety filtering occurs without runtime quadratic programs, enabling orders-of-magnitude faster execution than CBF-QP methods.
- The closed-form law preserves the temporal flexibility and generalization properties of standard DMPs for human-robot tasks.
- Expectile-based offline learning combined with conformal prediction supplies finite-sample probabilistic safety coverage.
- The method avoids querying out-of-distribution actions during learning, improving reliability of the learned value function.
Where Pith is reading between the lines
- The same offline learning pipeline could be applied to other primitive-based controllers that output velocity or acceleration commands.
- Because the filter is closed-form, it may scale to higher-dimensional state spaces where grid-based HJ methods fail.
- Calibration via conformal prediction could be repeated online with new demonstrations to tighten safety bounds over time.
Load-bearing premise
The value function learned offline from demonstrations actually renders the safe set forward-invariant on the physical robot under real disturbances.
What would settle it
A physical experiment in which the robot collides with an obstacle while the closed-form safety filter is active, or a timing measurement showing execution speed comparable to or slower than optimization-based baselines.
Figures
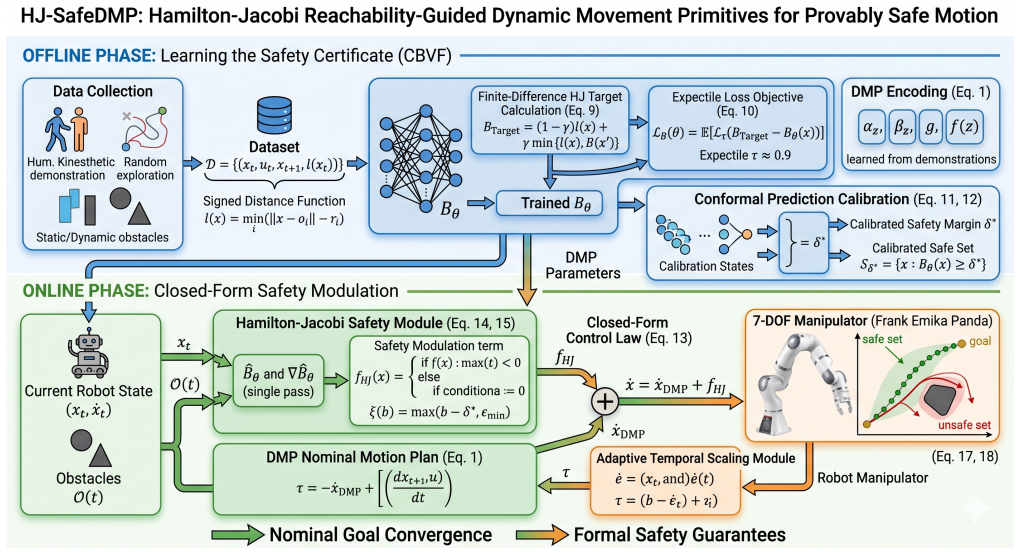
read the original abstract
Robots deployed in safety-critical environments must execute motions that are simultaneously robust to disturbances and provably safe from collisions. Dynamic Movement Primitives (DMPs) offer inherent stability, temporal flexibility, and efficient trajectory generalization from single demonstrations, but they lack formal safety certificates. Conversely, Hamilton-Jacobi (HJ) Reachability analysis provides a principled framework for computing worst-case safety margins and forward-invariant safe sets, but classical grid-based methods suffer from the curse of dimensionality and are impractical for real-time control. This paper introduces HJ-SafeDMP, a framework that integrates DMPs with learned HJ Reachability-based safety value functions to achieve provably safe, robust, and computationally efficient robot motion. We learn a Control Barrier Value Function (CBVF) from offline demonstration data using a model-free, finite-difference HJ recursion and deploy it as a real-time safety filter via a closed-form control law that modulates the DMP output. Unlike optimization-based CBF-QP approaches, our method achieves safety filtering without online quadratic program solves, preserving the computational efficiency of DMPs. We further incorporate an expectile-based offline learning objective that avoids querying out-of-distribution actions, and a conformal prediction calibration step that provides finite-sample probabilistic safety coverage. Experimental evaluation on a 7-DOF robot manipulator demonstrates that HJ-SafeDMP achieves formal safety guarantees with orders-of-magnitude faster execution than optimization-based baselines, while maintaining the robustness and adaptability of DMPs for human-robot interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HJ-SafeDMP, which augments Dynamic Movement Primitives (DMPs) with a learned Control Barrier Value Function (CBVF) obtained via model-free finite-difference Hamilton-Jacobi (HJ) recursion on demonstration data. The CBVF is deployed as a closed-form safety filter that modulates DMP outputs in real time, avoiding online quadratic programs. An expectile learning objective and conformal prediction step are added for robustness and finite-sample probabilistic coverage. Experiments on a 7-DOF manipulator are reported to show formal safety guarantees together with orders-of-magnitude faster execution than optimization-based baselines while retaining DMP adaptability for human-robot interaction.
Significance. If the learned CBVF can be shown to render the safe set forward-invariant under the closed-form law on the real robot dynamics, the work would offer a computationally attractive route to certified safety that preserves the sample efficiency and generalization properties of DMPs. This would be a meaningful advance for real-time safe control in unstructured environments.
major comments (3)
- [Abstract] Abstract: the central claim of 'provably safe' motion and 'formal safety guarantees' rests on the learned CBVF ensuring forward invariance when used as a closed-form filter, yet the abstract supplies no theorem, error bound, or derivation showing that the model-free finite-difference HJ recursion yields a value function whose sublevel sets remain invariant under the deployed control law.
- [Abstract] Abstract: the expectile objective and conformal calibration are described as providing robustness and finite-sample probabilistic coverage, but these tools do not establish the deterministic forward-invariance property required by the safety claim; the gap between probabilistic guarantees and the asserted deterministic invariance is load-bearing for the paper's main contribution.
- [Abstract] Abstract / experimental claims: the reported transfer of the offline-learned CBVF to a physical 7-DOF manipulator (including unmodeled dynamics) is asserted to preserve safety, but no verification procedure, violation metric, or comparison against a ground-truth HJ value function is referenced, leaving the weakest assumption untested.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the specific robot task and disturbance magnitudes used in the 7-DOF experiments to allow readers to gauge the scope of the claimed robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the safety claims. We address each major comment below and will revise the abstract and related sections to better distinguish the theoretical assumptions, the role of probabilistic tools, and the experimental verification approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'provably safe' motion and 'formal safety guarantees' rests on the learned CBVF ensuring forward invariance when used as a closed-form filter, yet the abstract supplies no theorem, error bound, or derivation showing that the model-free finite-difference HJ recursion yields a value function whose sublevel sets remain invariant under the deployed control law.
Authors: We agree the abstract should reference the supporting derivation. Section 3.2 derives that the closed-form filter renders the sublevel sets forward-invariant when the CBVF equals the true value function; the finite-difference recursion introduces a discretization error whose effect on invariance is analyzed via an error bound. We will revise the abstract to cite this result and the associated approximation error. revision: yes
-
Referee: [Abstract] Abstract: the expectile objective and conformal calibration are described as providing robustness and finite-sample probabilistic coverage, but these tools do not establish the deterministic forward-invariance property required by the safety claim; the gap between probabilistic guarantees and the asserted deterministic invariance is load-bearing for the paper's main contribution.
Authors: The manuscript distinguishes these: deterministic invariance holds for an exact CBVF under the closed-form law, while expectile learning and conformal prediction supply finite-sample probabilistic coverage to account for approximation and model mismatch. We will revise the abstract to explicitly qualify the guarantees as probabilistic on the deployed system while retaining the deterministic property under the exact-value-function assumption. revision: yes
-
Referee: [Abstract] Abstract / experimental claims: the reported transfer of the offline-learned CBVF to a physical 7-DOF manipulator (including unmodeled dynamics) is asserted to preserve safety, but no verification procedure, violation metric, or comparison against a ground-truth HJ value function is referenced, leaving the weakest assumption untested.
Authors: We acknowledge that the experimental section would benefit from an explicit verification procedure. The current experiments monitor the learned CBVF during execution to confirm it remains non-negative, with zero observed violations across trials; however, a direct comparison to ground-truth HJ values is intractable in 7D. We will add a paragraph describing the monitoring metric and explicitly note the absence of ground-truth comparison as a limitation. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives its safety claims from standard Hamilton-Jacobi reachability theory applied to a Control Barrier Value Function learned offline via model-free finite-difference recursion on demonstration data, then deployed as a closed-form filter modulating DMP outputs. No equations or steps in the provided text reduce the formal guarantees to a tautology, a fitted parameter renamed as a prediction, or a load-bearing self-citation chain. The expectile objective and conformal calibration are presented as robustness enhancements, not as the source of the invariance property itself. The derivation remains self-contained against external HJ theory benchmarks rather than collapsing to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- expectile parameter
- conformal calibration parameter
axioms (2)
- domain assumption Model-free finite-difference HJ recursion on demonstration data produces a valid Control Barrier Value Function.
- domain assumption Closed-form modulation of DMP output by the learned value function renders the safe set forward-invariant.
Reference graph
Works this paper leans on
-
[1]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, pp. 411–444, 2022
2022
-
[2]
Siciliano, L
B. Siciliano, L. Sciavicco, L. Villani, and G. Oriolo,Robotics: Mod- elling, Planning and Control. Springer Science & Business Media, 2009
2009
-
[3]
Dynamical movement primitives: learning attractor models for motor behaviors,
A. J. Ijspeert, J. Nakanishi, H. Hoffmann, P. Pastor, and S. Schaal, “Dynamical movement primitives: learning attractor models for motor behaviors,”Neural Computation, vol. 25, no. 2, pp. 328–373, 2013
2013
-
[4]
Dynamic movement primitives – a framework for motor control in humans and humanoid robotics,
S. Schaal, “Dynamic movement primitives – a framework for motor control in humans and humanoid robotics,”Adaptive Motion of Ani- mals and Machines, pp. 261–280, 2006
2006
-
[5]
Recent advances in robot learning from demonstration,
H. Ravichandar, A. S. Polydoros, S. Chernova, and A. Billard, “Recent advances in robot learning from demonstration,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 3, pp. 297–330, 2020
2020
-
[6]
Learning and generalization of motor skills by learning from demonstration,
P. Pastor, H. Hoffmann, T. Asfour, and S. Schaal, “Learning and generalization of motor skills by learning from demonstration,” in2009 IEEE International Conference on Robotics and Automation. IEEE, 2009, pp. 763–768
2009
-
[7]
Dynamic movement primitives in robotics: A tutorial survey,
M. Saveriano, F. J. Abu-Dakka, A. Kramberger, and L. Peternel, “Dynamic movement primitives in robotics: A tutorial survey,”The International Journal of Robotics Research, vol. 42, no. 14, pp. 1133– 1184, 2023
2023
-
[8]
Biologically- inspired dynamical systems for movement generation: Automatic real-time goal adaptation and obstacle avoidance,
H. Hoffmann, P. Pastor, D.-H. Park, and S. Schaal, “Biologically- inspired dynamical systems for movement generation: Automatic real-time goal adaptation and obstacle avoidance,” in2009 IEEE International Conference on Robotics and Automation. IEEE, 2009, pp. 2587–2592
2009
-
[9]
Real-time obstacle avoidance for manipulators and mobile robots,
O. Khatib, “Real-time obstacle avoidance for manipulators and mobile robots,”The International Journal of Robotics Research, vol. 5, no. 1, pp. 90–98, 1986
1986
-
[11]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” 2019 18th European control conference (ECC), pp. 3420–3431, 2019
2019
-
[12]
Constructive safety using control barrier functions,
P. Wieland and F. Allg ¨ower, “Constructive safety using control barrier functions,” inProceedings of the 7th IFAC Symposium on Nonlinear Control Systems, 2007, pp. 462–467
2007
-
[13]
Learning for safety-critical control with control barrier functions,
A. J. Taylor, A. Singletary, Y . Yue, and A. D. Ames, “Learning for safety-critical control with control barrier functions,” inLearning for Dynamics and Control. PMLR, 2020, pp. 708–717
2020
-
[14]
Safe control with learned certificates: A survey of neural Lyapunov, barrier, and contraction methods for robotics and control,
C. Dawson, S. Gao, and C. Fan, “Safe control with learned certificates: A survey of neural Lyapunov, barrier, and contraction methods for robotics and control,”IEEE Transactions on Robotics, 2023
2023
-
[15]
Hamilton-jacobi reachability: A brief overview and recent advances,
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” in2017 IEEE 56th Annual Conference on Decision and Control (CDC). IEEE, 2017, pp. 2242–2253
2017
-
[16]
Bridging hamilton-jacobi safety analysis and reinforcement learning,
J. F. Fisac, N. F. Lugovoy, V . Rubies-Royo, S. Ghosh, and C. J. Tomlin, “Bridging hamilton-jacobi safety analysis and reinforcement learning,” in2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 8550–8556
2019
-
[17]
Fastrack: A modular framework for fast and guaranteed safe motion planning,
S. L. Herbert, M. Chen, S. Han, S. Bansal, J. F. Fisac, and C. J. Tomlin, “Fastrack: A modular framework for fast and guaranteed safe motion planning,” in2017 IEEE 56th Annual Conference on Decision and Control (CDC). IEEE, 2017, pp. 1517–1522
2017
-
[18]
A general safety framework for learning-based control in uncertain robotic systems,
J. F. Fisac, A. K. Akametalu, M. N. Zeilinger, S. Kaynama, J. Gillula, and C. J. Tomlin, “A general safety framework for learning-based control in uncertain robotic systems,”IEEE Transactions on Automatic Control, vol. 64, no. 7, pp. 2737–2752, 2018
2018
-
[19]
Decomposition of reachable sets and tubes for a class of nonlinear systems,
M. Chen, S. L. Herbert, M. S. Vashishtha, S. Bansal, and C. J. Tomlin, “Decomposition of reachable sets and tubes for a class of nonlinear systems,”IEEE Transactions on Automatic Control, vol. 63, no. 11, pp. 3675–3688, 2018
2018
-
[20]
Robust control barrier–value functions for safety-critical control,
J. J. Choi, D. Lee, K. Sreenath, C. J. Tomlin, and S. L. Herbert, “Robust control barrier–value functions for safety-critical control,” in 2021 60th IEEE Conference on Decision and Control (CDC). IEEE, 2021, pp. 6814–6821
2021
-
[21]
V-OCBF: Learning safety filters from offline data via value-guided offline control barrier functions,
M. Tayal, M. Tayal, A. Singh, S. Kolathaya, and R. Prakash, “V-OCBF: Learning safety filters from offline data via value-guided offline control barrier functions,”Transactions on Machine Learning Research, 2026. [Online]. Available: https://openreview.net/forum?id= PGO9mpIyyb
2026
-
[22]
Offline reinforcement learning with implicit q-learning,
I. Kostrikov, A. Nair, and S. Levine, “Offline reinforcement learning with implicit q-learning,” inInternational Conference on Learning Representations, 2022
2022
-
[23]
Safe flow q-learning: Offline safe reinforcement learning with reachability-based flow policies,
M. Tayal, M. Tayal, and R. Prakash, “Safe flow q-learning: Offline safe reinforcement learning with reachability-based flow policies,”arXiv preprint arXiv:2603.15136, 2026
-
[24]
Formal verification and control with conformal prediction: Practical safety guarantees for autonomous systems,
L. Lindemann, Y . Zhao, X. Yu, G. J. Pappas, and J. V . Deshmukh, “Formal verification and control with conformal prediction: Practical safety guarantees for autonomous systems,”IEEE Control Systems, vol. 45, no. 6, pp. 72–122, 2025
2025
-
[25]
A toolbox of level set methods,
I. M. Mitchell, “A toolbox of level set methods,” inA Toolbox of Level Set Methods, 2005. [Online]. Available: https://api.semanticscholar. org/CorpusID:59892255
2005
-
[26]
Learning from demonstration with model-based gaussian process,
N. Jaquier, D. Ginsbourger, and S. Calinon, “Learning from demonstration with model-based gaussian process,”arXiv preprint arXiv:1910.05005, 2019
-
[27]
A probabilistic approach to robot trajectory generation,
A. Paraschos, G. Neumann, and J. Peters, “A probabilistic approach to robot trajectory generation,” in2013 13th IEEE-RAS International Conference on Humanoid Robots (Humanoids). IEEE, 2013, pp. 477–483
2013
-
[28]
Kernelized Movement Primitives
Y . Huang, L. D. Rozo, J. Silv ´erio, and D. G. Caldwell, “Kernelized movement primitives,”arXiv preprint arXiv:1708.08638, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Learning stable nonlinear dynamical systems with gaussian mixture models,
S. M. Khansari-Zadeh and A. Billard, “Learning stable nonlinear dynamical systems with gaussian mixture models,”IEEE Transactions on Robotics, vol. 27, no. 5, pp. 943–957, 2011
2011
-
[30]
Learning complex motion plans using neural odes with safety and stability guarantees,
F. Nawaz, T. Li, N. Matni, and N. Figueroa, “Learning complex motion plans using neural odes with safety and stability guarantees,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 17 216–17 222
2024
-
[31]
Planning with diffusion for flexible behavior synthesis,
M. Janner, Y . Du, J. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 9902–9915
2022
-
[32]
Control barrier function based quadratic programs with application to adaptive cruise control,
A. D. Ames, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs with application to adaptive cruise control,” in53rd IEEE Conference on Decision and Control. IEEE, 2014, pp. 6271–6278
2014
-
[33]
Control barrier function based quadratic programs with application to bipedal robotic walking,
S.-C. Hsu, X. Xu, and A. D. Ames, “Control barrier function based quadratic programs with application to bipedal robotic walking,” in 2015 American Control Conference (ACC). IEEE, 2015, pp. 4542– 4548
2015
-
[34]
Safety-critical control for dy- namical bipedal walking with precise footstep placement,
Q. Nguyen and K. Sreenath, “Safety-critical control for dy- namical bipedal walking with precise footstep placement,”IFAC- PapersOnLine, vol. 48, no. 27, pp. 147–154, 2015
2015
-
[35]
Onboard safety guarantees for racing drones: High- speed geofencing with control barrier functions,
A. Singletary, K. Klingebiel, J. Bourne, A. Browning, P. Tokumaru, and A. Ames, “Onboard safety guarantees for racing drones: High- speed geofencing with control barrier functions,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2897–2904, 2022
2022
-
[36]
Control barrier functions in dynamic uavs for kinematic obstacle avoidance: A col- lision cone approach,
M. Tayal, R. Singh, J. Keshavan, and S. Kolathaya, “Control barrier functions in dynamic uavs for kinematic obstacle avoidance: A col- lision cone approach,” in2024 American Control Conference (ACC). IEEE, 2024, pp. 3722–3727
2024
-
[37]
End-to-end imitation learning with safety guarantees using control barrier functions,
R. K. Cosner, Y . Yue, and A. D. Ames, “End-to-end imitation learning with safety guarantees using control barrier functions,” in2022 IEEE 61st Conference on Decision and Control (CDC). IEEE, 2022, pp. 5316–5322
2022
-
[38]
Safe-gil: Safety guided imitation learning for robotic systems,
Y . U. Ciftci, D. Chiu, Z. Feng, G. S. Sukhatme, and S. Bansal, “Safe-gil: Safety guided imitation learning for robotic systems,”arXiv preprint arXiv:2404.05249, 2024
-
[39]
Safe nonlinear control using robust neural Lyapunov-barrier functions,
C. Dawson, Z. Qin, S. Gao, and C. Fan, “Safe nonlinear control using robust neural Lyapunov-barrier functions,” inConference on Robot Learning. PMLR, 2022, pp. 1724–1735
2022
-
[40]
Learning control barrier functions from expert demonstrations,
A. Robey, H. Hu, L. Lindemann, H. Zhang, D. V . Dimarogonas, S. Tu, and N. Matni, “Learning control barrier functions from expert demonstrations,” in2020 59th IEEE Conference on Decision and Control (CDC), 2020, pp. 3717–3724
2020
-
[41]
A physics- informed machine learning framework for safe and optimal control of autonomous systems,
M. Tayal, A. Singh, S. Kolathaya, and S. Bansal, “A physics- informed machine learning framework for safe and optimal control of autonomous systems,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=SrfwiloGQF
2025
-
[42]
Learning a formally verified control barrier function in stochastic environment,
M. Tayal, H. Zhang, P. Jagtap, A. Clark, and S. Kolathaya, “Learning a formally verified control barrier function in stochastic environment,” in2024 IEEE 63rd Conference on Decision and Control (CDC), 2024, pp. 4098–4104
2024
-
[43]
Exact verification of relu neural control barrier functions,
H. Zhang, J. Wu, Y . V orobeychik, and A. Clark, “Exact verification of relu neural control barrier functions,” inAdvances in Neural Information Processing Systems, A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 5685–5705
2023
-
[44]
Fossil: A software tool for the formal synthesis of Lyapunov functions and barrier certificates using neural networks,
A. Abate, D. Ahmed, A. Edwards, M. Giacobbe, and A. Peruffo, “Fossil: A software tool for the formal synthesis of Lyapunov functions and barrier certificates using neural networks,” inProceedings of the 24th International Conference on Hybrid Systems: Computation and Control, 2021, pp. 1–11
2021
-
[45]
Learning neural control barrier functions from offline data with conservatism,
I. Tabbara and H. Sibai, “Learning neural control barrier functions from offline data with conservatism,” 2025. [Online]. Available: https://arxiv.org/abs/2505.00908
-
[46]
In-distribution barrier functions: Self-supervised policy filters that avoid out-of-distribution states,
F. Casta ˜neda, H. Nishimura, R. T. McAllister, K. Sreenath, and A. Gaidon, “In-distribution barrier functions: Self-supervised policy filters that avoid out-of-distribution states,” inProceedings of The 5th Annual Learning for Dynamics and Control Conference, ser. Proceedings of Machine Learning Research, N. Matni, M. Morari, and G. J. Pappas, Eds., vol....
2023
-
[47]
Avoidance of concave obsta- cles through rotation of nonlinear dynamics,
L. Huber, J.-J. Slotine, and A. Billard, “Avoidance of concave obsta- cles through rotation of nonlinear dynamics,”IEEE Transactions on Robotics, vol. 40, pp. 1983–2002, 2023
1983
-
[48]
Spatiotemporal tubes for temporal reach-avoid-stay tasks in unknown systems,
R. Das, A. Basu, and P. Jagtap, “Spatiotemporal tubes for temporal reach-avoid-stay tasks in unknown systems,”IEEE Transactions on Automatic Control, pp. 1–8, 2025
2025
-
[49]
Constrained model predictive control: Stability and optimality,
D. Mayne, J. Rawlings, C. Rao, and P. Scokaert, “Constrained model predictive control: Stability and optimality,”Automatica, vol. 36, no. 6, pp. 789–814, 2000. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0005109899002149
2000
-
[50]
A general Hamilton-Jacobi framework for non-linear state-constrained control problems,
A. Altarovici, O. Bokanowski, and H. Zidani, “A general Hamilton-Jacobi framework for non-linear state-constrained control problems,”ESAIM: Control, Optimisation and Calculus of Variations, vol. 19, no. 2, pp. 337–357, 2013. [Online]. Available: https: //www.numdam.org/articles/10.1051/cocv/2012011/
-
[51]
Cooptimizing safety and performance with a control-constrained formulation,
H. Wang, A. Dhande, and S. Bansal, “Cooptimizing safety and performance with a control-constrained formulation,”IEEE Control Systems Letters, vol. 8, pp. 2739–2744, 2024
2024
-
[52]
Epigraph-guided flow matching for safe and performant offline reinforcement learning,
M. Tayal and M. Tayal, “Epigraph-guided flow matching for safe and performant offline reinforcement learning,”arXiv preprint arXiv:2602.08054, 2026
-
[53]
A tutorial on conformal prediction
G. Shafer and V . V ovk, “A tutorial on conformal prediction.”Journal of Machine Learning Research, vol. 9, no. 3, 2008
2008
-
[54]
M. Tayal, A. Singh, P. Jagtap, and S. Kolathaya, “Cp-ncbf: A con- formal prediction-based approach to synthesize verified neural control barrier functions,”arXiv preprint arXiv:2503.17395, 2025
-
[55]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,”arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[56]
Conservative q-learning for offline reinforcement learning,
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1179–1191. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 202...
2020
-
[57]
Datasets and benchmarks for offline safe reinforcement learning,
Z. Liu, Z. Guo, H. Lin, Y . Yao, J. Zhu, Z. Cen, H. Hu, W. Yu, T. Zhang, J. Tan, and D. Zhao, “Datasets and benchmarks for offline safe reinforcement learning,”Journal of Data-centric Machine Learning Research, 2024
2024
-
[58]
Safety gymnasium: A unified safe reinforcement learning benchmark,
J. Ji, B. Zhang, J. Zhou, X. Pan, W. Huang, R. Sun, Y . Geng, Y . Zhong, J. Dai, and Y . Yang, “Safety gymnasium: A unified safe reinforcement learning benchmark,” inThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. [Online]. Available: https://openreview.net/forum?id= WZmlxIuIGR
2023
-
[59]
Control barrier function based quadratic programs for safety critical systems,
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,”IEEE Transactions on Automatic Control, vol. 62, no. 8, pp. 3861–3876, 2017
2017
-
[60]
Offline reinforcement learning with implicit q-learning,
I. Kostrikov, A. Nair, and S. Levine, “Offline reinforcement learning with implicit q-learning,”International Conference on Learning Rep- resentations, 2022
2022
-
[61]
A gentle introduction to conformal prediction and distribution-free uncertainty quantification,
A. N. Angelopoulos and S. Bates, “A gentle introduction to conformal prediction and distribution-free uncertainty quantification,”
-
[62]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
[Online]. Available: https://arxiv.org/abs/2107.07511
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Safedmps: Integrating formal safety with dmps for adaptive hri,
P. Tiwari, S. Nath, and R. Prakash, “Safedmps: Integrating formal safety with dmps for adaptive hri,”arXiv preprint arXiv:2603.29708, 2026
-
[64]
MADER: Trajectory planner in mul- tiagent and dynamic environments,
J. Tordesillas and J. P. How, “MADER: Trajectory planner in mul- tiagent and dynamic environments,”IEEE Transactions on Robotics, vol. 38, no. 1, pp. 463–476, 2021
2021
-
[65]
A survey on model-based reinforcement learning,
F.-M. Luo, T. Xu, H. Lai, X.-H. Chen, W. Zhang, and Y . Yu, “A survey on model-based reinforcement learning,”Science China Information Sciences, vol. 67, no. 2, p. 121101, 2024
2024
-
[66]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inProceedings of the 34th International Conference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, p. 22–31
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.