Disentangled Fine-Grained Prototype Learning for Incomplete Image-Tabular Classification
Pith reviewed 2026-06-28 06:31 UTC · model grok-4.3
The pith
DFPL disentangles shared and specific prototypes to align fine-grained semantics and distributions in missing-modality image-tabular tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DFPL preserves both fine-grained distributional and semantic consistency across modalities through prototype-level disentanglement and alignment, thereby enabling superior performance compared to previous approaches under various missing-modality settings on three image-tabular benchmarks.
What carries the argument
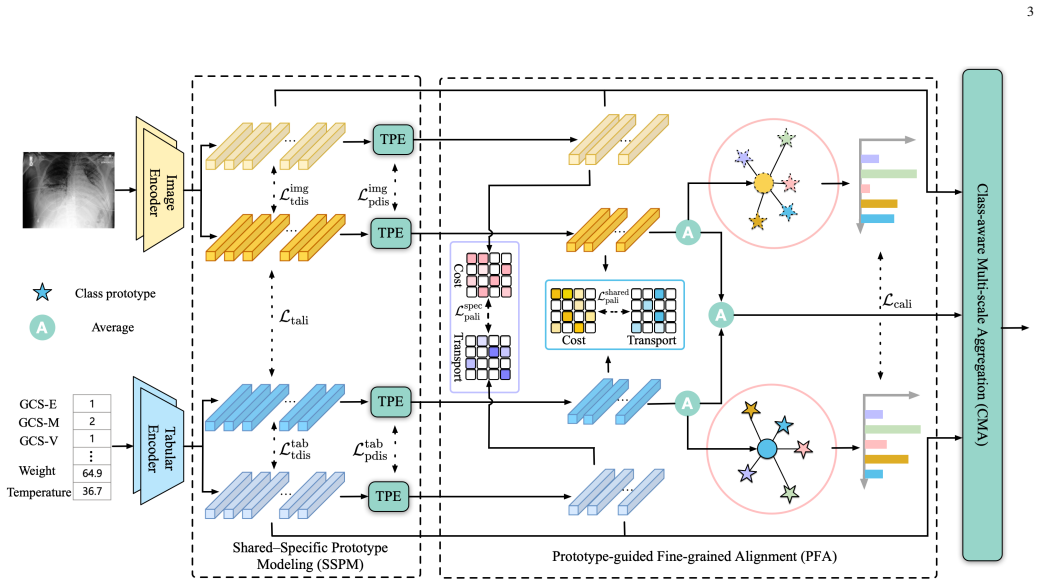
Shared-Specific Prototype Modeling (SSPM) extracts compact shared and specific prototypes for disentanglement, while Prototype-guided Fine-grained Alignment (PFA) matches distributions and aligns semantics in a unified prototype space, supported by Class-aware Multi-scale Aggregation (CMA).
If this is right
- Superior performance on three diverse image-tabular benchmarks under missing-modality conditions.
- Preservation of fine-grained distributional consistency between heterogeneous modalities.
- Joint enforcement of distribution matching and class semantic alignment at prototype level.
- Robust predictions by adaptively aggregating shared and specific characteristics from global and prototype levels.
Where Pith is reading between the lines
- Applying similar prototype disentanglement could improve other multimodal tasks with high heterogeneity.
- Testing on larger or real-world medical datasets would check if the consistency holds beyond the three benchmarks.
- The approach might generalize to more than two modalities if prototypes can be extended accordingly.
Load-bearing premise
That shared and specific prototypes can be extracted in a way that their disentanglement removes redundant correlations while their alignment captures both distribution and semantic details for very different image and tabular data.
What would settle it
A controlled experiment where removing the prototype disentanglement or alignment steps causes performance to match or fall below prior global-feature methods on the same missing-modality benchmarks.
Figures


read the original abstract
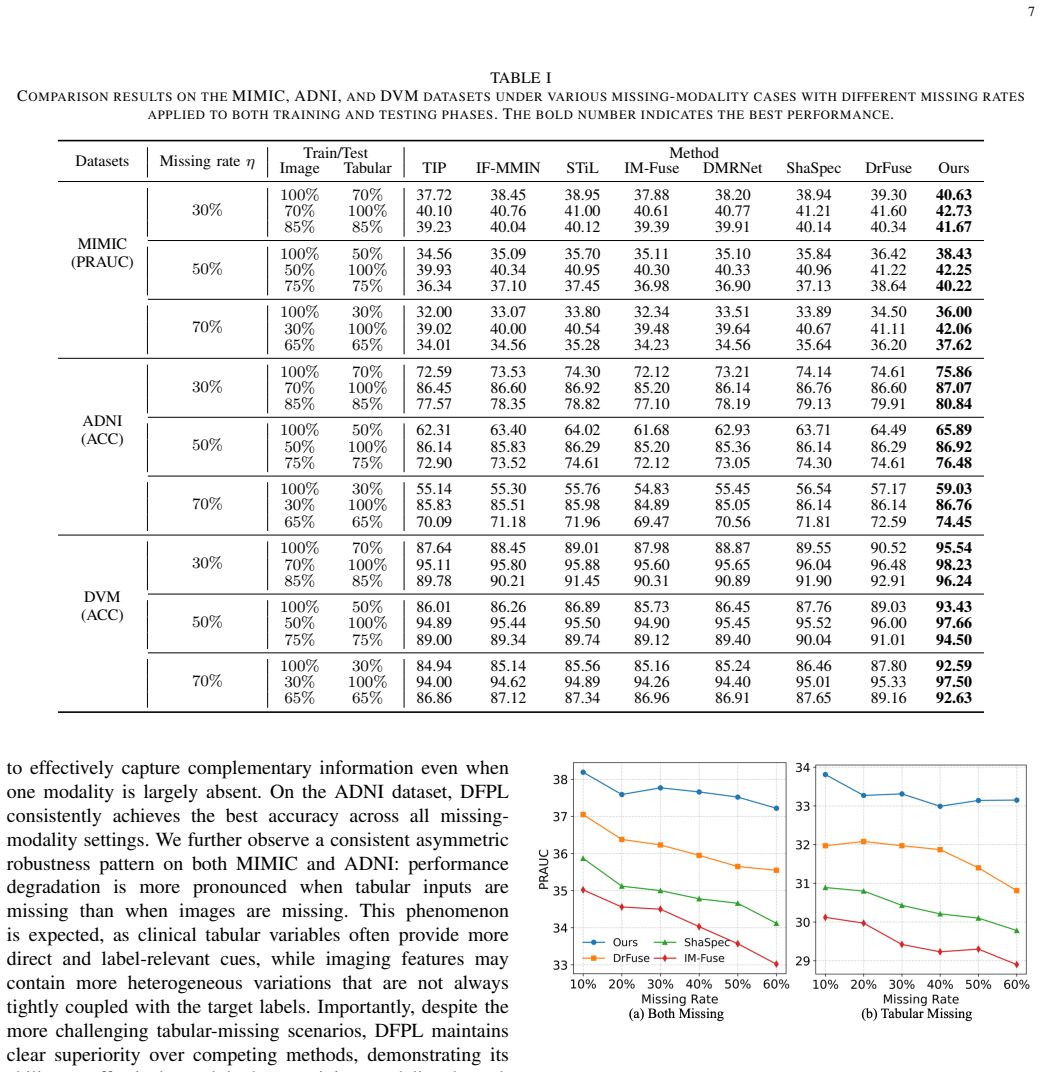
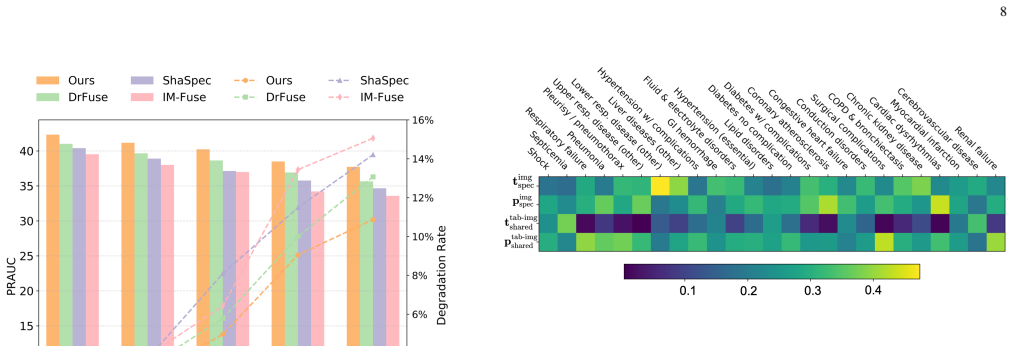
The missing-modality problem poses a significant challenge in image-tabular multimodal learning across a wide range of multimedia applications, including product understanding, recommendation systems, and medical diagnosis. This challenge is particularly pronounced when the two modalities are highly heterogeneous, as images and tabular attributes differ substantially in their semantic granularity and data distributions. Existing methods learn modality-invariant representations through disentanglement and alignment over global token-averaged features, capturing only coarse cross-modal consistency and overlooking fine-grained semantic and distributional misalignment, which hampers the exploitation of complementary cues under missing modalities. To address this, we propose DFPL, a novel framework for fine-grained prototype learning. Specifically, Shared-Specific Prototype Modeling (SSPM) extracts compact and diverse shared and modality-specific prototypes, and further performs prototype-level disentanglement to suppress redundant intra-modality correlations. Additionally, we propose a Prototype-guided Fine-grained Alignment (PFA) module that jointly enforces prototype-level distribution matching and prototype-to-class semantic alignment within a unified prototype space, thereby preserving both fine-grained distributional and semantic consistency across modalities. We further introduce a Class-aware Multi-scale Aggregation (CMA) module to adaptively aggregate shared semantics and modality-specific characteristics from global and prototype levels for robust predictions. Extensive experiments on three diverse image-tabular benchmarks demonstrate the superiority of our method compared to the previous approaches under various missing-modality settings. Code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DFPL for incomplete image-tabular classification under missing modalities. It introduces Shared-Specific Prototype Modeling (SSPM) to extract compact shared and modality-specific prototypes with prototype-level disentanglement to suppress intra-modality correlations, Prototype-guided Fine-grained Alignment (PFA) to jointly enforce distribution matching and class semantic alignment in a unified space, and Class-aware Multi-scale Aggregation (CMA) to combine global and prototype-level features. The central claim is that this yields fine-grained cross-modal consistency and superior performance versus prior methods on three image-tabular benchmarks.
Significance. If validated by detailed experiments, the framework could advance handling of highly heterogeneous modalities with missing data by moving beyond coarse global-feature alignment to prototype-level disentanglement and joint alignment, with potential utility in medical diagnosis and recommendation systems.
major comments (2)
- [Abstract] Abstract: the claim of experimental superiority on three benchmarks under missing-modality settings supplies no metrics, baselines, ablation results, error bars, or implementation details, so it is impossible to determine whether SSPM, PFA, or CMA support the central claim.
- [Framework] Framework description: the modeling constructs (Shared-Specific Prototypes, Prototype-guided Fine-grained Alignment) are presented without equations or derivations, preventing verification that the disentanglement suppresses redundant correlations independently of prior work or that the alignment is not circular with the claimed consistency.
minor comments (1)
- [Abstract] The abstract could more explicitly distinguish the contribution of prototype-level operations from global token-averaged baselines used in prior disentanglement methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of experimental superiority on three benchmarks under missing-modality settings supplies no metrics, baselines, ablation results, error bars, or implementation details, so it is impossible to determine whether SSPM, PFA, or CMA support the central claim.
Authors: We agree the abstract is high-level and omits quantitative details. The full experimental results, including metrics on the three benchmarks, baseline comparisons, ablation studies, error bars, and implementation details, appear in Sections 4 and 5. To strengthen the abstract, we will revise it to report key performance improvements under missing-modality settings. revision: yes
-
Referee: [Framework] Framework description: the modeling constructs (Shared-Specific Prototypes, Prototype-guided Fine-grained Alignment) are presented without equations or derivations, preventing verification that the disentanglement suppresses redundant correlations independently of prior work or that the alignment is not circular with the claimed consistency.
Authors: The current manuscript describes SSPM and PFA at a conceptual level without explicit equations. To enable verification of the disentanglement mechanism and alignment objective, we will add the mathematical formulations, loss terms, and derivations in Section 3 of the revised manuscript. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces DFPL as a new framework consisting of SSPM for prototype extraction and disentanglement, PFA for alignment, and CMA for aggregation. These are presented as novel modeling choices without any equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations to uniqueness theorems. No step reduces by construction to its inputs; the central claims rest on the independent design of the modules for handling heterogeneous modalities, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Shared-Specific Prototypes
no independent evidence
-
Prototype-guided Fine-grained Alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stil: Semi-supervised tabular-image learning for comprehensive task-relevant information ex- ploration in multimodal classification,
S. Du, X. Luo, D. P. O’Regan, and C. Qin, “Stil: Semi-supervised tabular-image learning for comprehensive task-relevant information ex- ploration in multimodal classification,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15 549–15 559. 1, 4, 5, 6
2025
-
[2]
Drfuse: Learning disentangled representation for clinical multi-modal fusion with missing modality and modal inconsistency,
W. Yao, K. Yin, W. K. Cheung, J. Liu, and J. Qin, “Drfuse: Learning disentangled representation for clinical multi-modal fusion with missing modality and modal inconsistency,” inProceedings of the AAAI confer- ence on artificial intelligence, vol. 38, no. 15, 2024, pp. 16 416–16 424. 1, 3, 4, 5, 6
2024
-
[3]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 46, no. 8, pp. 5625–5644, 2024. 1
2024
-
[4]
Multi-grained vision- and-language model for medical image and text alignment,
H. Yan, X. Yang, L. Bai, J. Li, and J. Liang, “Multi-grained vision- and-language model for medical image and text alignment,”IEEE Transactions on Multimedia, 2025. 1
2025
-
[5]
Intra-sample and intra- modal enhancement for multimodal sentiment analysis with missing modalities,
Y . Zhuang, Y . Zhang, J. Deng, and F. Ren, “Intra-sample and intra- modal enhancement for multimodal sentiment analysis with missing modalities,”IEEE Transactions on Multimedia, 2025. 1
2025
-
[6]
Boosting modal-specific representations for sentiment analysis with incomplete modalities,
X. Jiang, L. He, F. Gao, K. Zhang, J. Li, and X. Gao, “Boosting modal-specific representations for sentiment analysis with incomplete modalities,”IEEE Transactions on Multimedia, 2025. 1
2025
-
[7]
Multimodal multi-graph fusion learning for alzheimer’s disease diagnosis,
A. Dong, Y . Cai, L. Wang, J. Xu, G. Lv, and G. Zhao, “Multimodal multi-graph fusion learning for alzheimer’s disease diagnosis,”IEEE Transactions on Multimedia, 2025. 1
2025
-
[8]
3d multimodal fusion network with disease-induced joint learning for early alzheimer’s disease diagnosis,
Z. Qiu, P. Yang, C. Xiao, S. Wang, X. Xiao, J. Qin, C.-M. Liu, T. Wang, and B. Lei, “3d multimodal fusion network with disease-induced joint learning for early alzheimer’s disease diagnosis,”IEEE Transactions on Medical Imaging, vol. 43, no. 9, pp. 3161–3175, 2024. 1
2024
-
[9]
Predicting stroke outcome: a case for multimodal deep learning methods with tabular and ct perfusion data,
B. Borsos, C. G. Allaart, and A. van Halteren, “Predicting stroke outcome: a case for multimodal deep learning methods with tabular and ct perfusion data,”Artificial Intelligence in Medicine, vol. 147, p. 102719, 2024. 1
2024
-
[10]
A population-based phenome- wide association study of cardiac and aortic structure and function,
W. Bai, H. Suzuki, J. Huang, C. Francis, S. Wang, G. Tarroni, F. Guitton, N. Aung, K. Fung, S. E. Petersenet al., “A population-based phenome- wide association study of cardiac and aortic structure and function,” Nature Medicine, 2020. 1
2020
-
[11]
DVM-CAR: A large-scale automotive dataset for visual marketing research and applications,
J. Huang, B. Chen, L. Luoet al., “DVM-CAR: A large-scale automotive dataset for visual marketing research and applications,” in2022 IEEE International Conference on Big Data (Big Data). IEEE, 2022. 1, 6
2022
-
[12]
TIP: Tabular-image pre-training for multimodal classification with incomplete data,
S. Du, S. Zheng, Y . Wang, W. Bai, D. P. O’Regan, and C. Qin, “TIP: Tabular-image pre-training for multimodal classification with incomplete data,” inECCV, 2024. 1, 2, 6
2024
-
[13]
DAFT: a universal module to interweave tabular data and 3d images in CNNs,
T. N. Wolf, S. Pölsterl, C. Wachinger, A. D. N. Initiativeet al., “DAFT: a universal module to interweave tabular data and 3d images in CNNs,” NeuroImage, 2022. 1, 2
2022
-
[14]
Best of both worlds: Multimodal contrastive learning with tabular and imaging data,
P. Hager, M. J. Menten, and D. Rueckert, “Best of both worlds: Multimodal contrastive learning with tabular and imaging data,” in CVPR, 2023. 1, 2
2023
-
[15]
Hyperfusion: A hypernetwork approach to multimodal integration of tabular and medical imaging data for predictive modeling,
D. Duenias, B. Nichyporuk, T. Arbel, T. R. Ravivet al., “Hyperfusion: A hypernetwork approach to multimodal integration of tabular and medical imaging data for predictive modeling,”Medical Image Analysis, vol. 102, p. 103503, 2025. 1 10
2025
-
[16]
Predicting stroke through retinal graphs and multimodal self-supervised learning,
Y . Huang, B. Wittmann, O. Demler, B. Menze, and N. Davoudi, “Predicting stroke through retinal graphs and multimodal self-supervised learning,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 223–234. 1, 2
2024
-
[17]
Multi-modal learning with missing modality via shared-specific feature modelling,
H. Wang, Y . Chen, C. Ma, J. Avery, L. Hull, and G. Carneiro, “Multi-modal learning with missing modality via shared-specific feature modelling,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 878–15 887. 2, 3, 4, 5, 6
2023
-
[18]
Exploiting modality- invariant feature for robust multimodal emotion recognition with missing modalities,
H. Zuo, R. Liu, J. Zhao, G. Gao, and H. Li, “Exploiting modality- invariant feature for robust multimodal emotion recognition with missing modalities,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5. 2, 3, 6
2023
-
[19]
Disentangle first, then distill: A unified framework for missing modality imputation and alzheimer’s disease diagnosis,
Y . Chen, Y . Pan, Y . Xia, and Y . Yuan, “Disentangle first, then distill: A unified framework for missing modality imputation and alzheimer’s disease diagnosis,”IEEE Transactions on Medical Imaging, 2023. 2, 3
2023
-
[20]
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
C. Qian, S. Xing, S. Li, Y . Zhao, and Z. Tu, “Decalign: Hierarchical cross-modal alignment for decoupled multimodal representation learn- ing,”arXiv preprint arXiv:2503.11892, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Learnable cross-modal knowledge distillation for multi-modal learning with missing modality,
H. Wang, C. Ma, J. Zhang, Y . Zhang, J. Avery, L. Hull, and G. Carneiro, “Learnable cross-modal knowledge distillation for multi-modal learning with missing modality,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 216–226. 2, 3
2023
-
[22]
Correlation-decoupled knowledge distillation for multimodal sentiment analysis with incomplete modalities,
M. Li, D. Yang, X. Zhao, S. Wang, Y . Wang, K. Yang, M. Sun, D. Kou, Z. Qian, and L. Zhang, “Correlation-decoupled knowledge distillation for multimodal sentiment analysis with incomplete modalities,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 458–12 468. 2, 3, 5
2024
-
[23]
Maskmentor: Unlock- ing the potential of masked self-teaching for missing modality rgb-d semantic segmentation,
Z. Zhao, J. Li, L. Wang, Y . Wang, and H. Lu, “Maskmentor: Unlock- ing the potential of masked self-teaching for missing modality rgb-d semantic segmentation,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1915–1923. 2, 3
2024
-
[24]
Deep correlated prompting for visual recognition with missing modalities,
T. Shi, W. Feng, F. Shang, L. Wanet al., “Deep correlated prompting for visual recognition with missing modalities,”Advances in Neural Information Processing Systems, vol. 37, pp. 67 446–67 466, 2024. 2, 3
2024
-
[25]
Multimodal prompt- ing with missing modalities for visual recognition,
Y .-L. Lee, Y .-H. Tsai, W.-C. Chiu, and C.-Y . Lee, “Multimodal prompt- ing with missing modalities for visual recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14 943–14 952. 2, 3
2023
-
[26]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763. 2
2021
-
[27]
Query2label: A simple transformer way to multi-label classification,
S. Liu, L. Zhang, X. Yang, H. Su, and J. Zhu, “Query2label: A simple transformer way to multi-label classification,”arXiv preprint arXiv:2107.10834, 2021. 2
-
[28]
Combining 3D image and tabular data via the dynamic affine feature map transform,
S. Pölsterl, T. N. Wolf, and C. Wachinger, “Combining 3D image and tabular data via the dynamic affine feature map transform,” inMICCAI. Springer, 2021. 2
2021
-
[29]
AI- based differential diagnosis of dementia etiologies on multimodal data,
C. Xue, S. S. Kowshik, D. Lteif, S. Puducheri, V . H. Jasodanand, O. T. Zhou, A. S. Walia, O. B. Guney, J. D. Zhang, S. T. Phamet al., “AI- based differential diagnosis of dementia etiologies on multimodal data,” Nature Medicine, 2024. 2
2024
-
[30]
Glcp: Global-to-local connectivity preservation for tubular structure segmentation,
F. Zhou, Z. Gao, H. Zhao, J. Xie, Y . Meng, Y . Zhao, G. Y . Lip, and Y . Zheng, “Glcp: Global-to-local connectivity preservation for tubular structure segmentation,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2025, pp. 237–247. 2
2025
-
[31]
Unleashing the power of image-tabular self-supervised learning via breaking cross-tabular barriers,
Y . Fu, Y . Zhao, Z. Zeng, C. Chen, and Y . Jin, “Unleashing the power of image-tabular self-supervised learning via breaking cross-tabular barriers,”arXiv preprint arXiv:2512.14026, 2025. 2, 6
-
[32]
A self-supervised model for multi-modal stroke risk prediction,
C. Delgrange, O. V . Demler, S. Mora, bjoern menze, E. D. la Rosa, and N. Davoudi, “A self-supervised model for multi-modal stroke risk prediction,” inAdvancements In Medical Foundation Models: Explainability, Robustness, Security, and Beyond, 2024. [Online]. Available: https://openreview.net/forum?id=ST72dbOvwx 2
2024
-
[33]
Time: Tabpfn-integrated multimodal engine for robust tabular-image learning,
J. Luo, Y . Yuan, and S. Xu, “Time: Tabpfn-integrated multimodal engine for robust tabular-image learning,”arXiv preprint arXiv:2506.00813,
-
[34]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
N. Hollmann, S. Müller, K. Eggensperger, and F. Hutter, “Tabpfn: A transformer that solves small tabular classification problems in a second,”arXiv preprint arXiv:2207.01848, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
MultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning
W. Kim, C. Song, and H. Kim, “Multimodalpfn: Extending prior- data fitted networks for multimodal tabular learning,”arXiv preprint arXiv:2602.20223, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Mmcformer: Missing modality compensation transformer for brain tumor segmentation,
S. Karimijafarbigloo, R. Azad, A. Kazerouni, S. Ebadollahi, and D. Mer- hof, “Mmcformer: Missing modality compensation transformer for brain tumor segmentation,” inMedical imaging with deep learning. PMLR, 2024, pp. 1144–1162. 2
2024
-
[37]
Rosa: A robust self- adaptive model for multimodal emotion recognition with uncertain missing modalities,
Z. Li, Y . Liu, C. Yang, Y . Zhou, and S. Hu, “Rosa: A robust self- adaptive model for multimodal emotion recognition with uncertain missing modalities,”IEEE Transactions on Multimedia, 2025. 2
2025
-
[38]
Unified multi-modal image synthesis for missing modality imputation,
Y . Zhang, C. Peng, Q. Wang, D. Song, K. Li, and S. K. Zhou, “Unified multi-modal image synthesis for missing modality imputation,”IEEE Transactions on Medical Imaging, vol. 44, no. 1, pp. 4–18, 2024. 2
2024
-
[39]
Missing as masking: arbitrary cross-modal feature reconstruction for incomplete multimodal brain tumor segmentation,
Z. Zeng, Z. Peng, X. Yang, and W. Shen, “Missing as masking: arbitrary cross-modal feature reconstruction for incomplete multimodal brain tumor segmentation,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 424–433. 2
2024
-
[40]
Epe-p: Evidence-based parameter- efficient prompting for multimodal learning with missing modalities,
Z. Chen, X. Lin, Y . Cui, and Z. Yu, “Epe-p: Evidence-based parameter- efficient prompting for multimodal learning with missing modalities,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5. 3
2025
-
[41]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,”Advances in neural information processing systems, vol. 30,
-
[42]
Exploring intrinsic normal prototypes within a single image for universal anomaly detection,
W. Luo, Y . Cao, H. Yao, X. Zhang, J. Lou, Y . Cheng, W. Shen, and W. Yu, “Exploring intrinsic normal prototypes within a single image for universal anomaly detection,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9974–9983. 4
2025
-
[43]
Fg-clip: Fine-grained visual and textual alignment,
C. Xie, B. Wang, F. Kong, J. Li, D. Liang, G. Zhang, D. Leng, and Y . Yin, “Fg-clip: Fine-grained visual and textual alignment,” inForty- second International Conference on Machine Learning, 2025. 4, 5
2025
-
[44]
Large-scale and fine-grained vision-language pre-training for enhanced ct image understanding,
Z. Shui, J. Zhang, W. Cao, S. Wang, R. Guo, L. Lu, L. Yang, X. Ye, T. Liang, Q. Zhanget al., “Large-scale and fine-grained vision-language pre-training for enhanced ct image understanding,” inThe Thirteenth International Conference on Learning Representations, 2025. 4, 5
2025
-
[45]
Sinkhorn distances: Lightspeed computation of optimal transport,
M. Cuturi, “Sinkhorn distances: Lightspeed computation of optimal transport,”Advances in neural information processing systems, vol. 26,
-
[46]
Faster wasserstein distance estimation with the sinkhorn divergence,
L. Chizat, P. Roussillon, F. Léger, F.-X. Vialard, and G. Peyré, “Faster wasserstein distance estimation with the sinkhorn divergence,”Advances in neural information processing systems, vol. 33, pp. 2257–2269, 2020. 5
2020
-
[47]
Improving neural cross-lingual abstractive summarization via employing optimal transport distance for knowledge distillation,
T. T. Nguyen and A. T. Luu, “Improving neural cross-lingual abstractive summarization via employing optimal transport distance for knowledge distillation,” inProceedings of the AAAI Conference on Artificial Intel- ligence, vol. 36, no. 10, 2022, pp. 11 103–11 111. 5
2022
-
[48]
Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports,
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, and S. Horng, “Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports,”Scientific data, vol. 6, no. 1, p. 317, 2019. 6
2019
-
[49]
The alzheimer’s disease neuroimaging initiative (adni): Mri methods,
C. R. Jack Jr, M. A. Bernstein, N. C. Fox, P. Thompson, G. Alexander, D. Harvey, B. Borowski, P. J. Britson, J. L. Whitwell, C. Wardet al., “The alzheimer’s disease neuroimaging initiative (adni): Mri methods,” Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine, vol. 27, no. 4, pp. 68...
2008
-
[50]
A modality- flexible framework for alzheimer’s disease diagnosis following clinical routine,
Y . Zhang, K. Sun, Y . Liu, F. Xie, Q. Guo, and D. Shen, “A modality- flexible framework for alzheimer’s disease diagnosis following clinical routine,”IEEE Journal of Biomedical and Health Informatics, vol. 29, no. 1, pp. 535–546, 2024. 6
2024
-
[51]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, 2016. 6
2016
-
[52]
Im-fuse: A mamba-based fusion block for brain tumor segmen- tation with incomplete modalities,
V . Pipoli, A. Saporita, K. Marchesini, C. Grana, E. Ficarra, F. Bolelli et al., “Im-fuse: A mamba-based fusion block for brain tumor segmen- tation with incomplete modalities,” inMedical Image Computing and Computer Assisted Intervention–MICCAI 2025, 2025. 6
2025
-
[53]
Robust multimodal learning via representation decoupling,
S. Wei, Y . Luo, Y . Wang, and C. Luo, “Robust multimodal learning via representation decoupling,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 38–54. 6
2024
-
[54]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.