NegAS: Negative Label Guided Attention and Scoring for Out-of-Distribution Object Detection with Vision-Language Models
Pith reviewed 2026-06-26 10:27 UTC · model grok-4.3
The pith
Negative labels guide vision-language detectors to better identify out-of-distribution objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
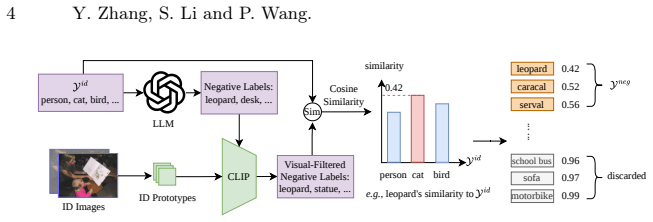
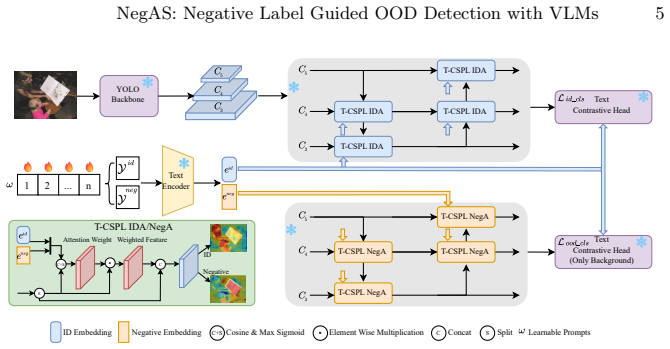
The central claim is that the NegAS framework, built from a negative label guided attention module (NegA) and a sigmoid-based OOD scoring function (NegS), solves two VLM-specific problems: uniform background treatment that ignores OOD cues and incompatibility between sigmoid outputs and standard OOD scores. By feeding LLM-produced negative labels into the attention module, the detector focuses on background regions likely to contain out-of-distribution instances; the scoring function then combines responses from both ID and negative labels to separate the two categories reliably.
What carries the argument
The NegA module, which routes attention using LLM-generated visually-similar but semantically-different negative labels, together with the NegS scoring function that leverages both ID and negative label responses.
If this is right
- FPR95 drops by 11.4 percent on COCO and 25.5 percent on OpenImages relative to the baseline VLM detector.
- In-distribution detection accuracy remains unchanged.
- The same modules transfer to both dense detectors such as YOLO-World and query-based transformers such as Grounding DINO.
Where Pith is reading between the lines
- The technique could be tested on video streams or 3D scenes where background regions evolve over time.
- Replacing the LLM label generator with a smaller model or rule-based method might preserve gains at lower cost.
- The same negative-label principle might improve uncertainty estimation in other multi-label vision tasks.
Load-bearing premise
LLM-generated negative labels will steer attention to genuine OOD background regions without creating new biases or errors.
What would settle it
Attention maps or OOD scores showing no separation between ID and OOD instances when the negative labels are applied to the same VLM detector on COCO or OpenImages.
Figures

read the original abstract
Out-of-Distribution (OOD) detection is essential for ensuring the robustness and reliability of object detection systems deployed in safety-critical applications. While prior research has mainly focused on uni-modal detectors or vision-language model (VLM) based classifiers, the potential of VLM-based object detectors in OOD scenarios remains underexplored. In this work, we take the first step toward building OOD object detection methods upon VLMs. We identify two challenges specific to VLM detectors: (i) their text-guided attention enhances foreground with ID labels but treats background uniformly, leaving potential OOD regions unexploited for separating in-distribution (ID) from OOD instances; and (ii) their sigmoid-based multi-label outputs are incompatible with softmax-based OOD scores, calling for scoring functions consistent with VLM probabilistic outputs. Hence, we introduce Negative Label Guided Attention and Scoring (NegAS). To address (i), we propose a negative label guided attention module (NegA), where LLM-generated, visually-similar but semantically-different negative labels are used to guide attention toward potential OOD background regions. To address (ii), we introduce a novel sigmoid-based OOD scoring function (NegS) that leverages both ID and negative labels, producing strong responses for ID instances and suppressed responses for OOD ones. Extensive experiments demonstrate that our approach improves OOD detection performance by a large margin while maintaining ID accuracy, e.g., reducing the FPR95 by 11.4% on the COCO dataset and 25.5% on the OpenImages dataset compared to the baseline model. While initially designed for dense VLM detectors like YOLO-World, we successfully adapt NegAS to Grounding DINO, a query-based VLM transformer and achieve significant improvements, demonstrating the generalizability of our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NegAS for out-of-distribution (OOD) object detection in vision-language model (VLM) detectors such as YOLO-World and Grounding DINO. It identifies two VLM-specific challenges—uniform background treatment by text-guided attention and incompatibility of sigmoid outputs with standard OOD scores—and introduces the NegA module (LLM-generated visually-similar but semantically-different negative labels to steer attention toward potential OOD regions) together with the NegS sigmoid-based scoring function. Experiments report substantial OOD gains (e.g., FPR95 reductions of 11.4% on COCO and 25.5% on OpenImages) while preserving in-distribution accuracy, with successful adaptation across detector architectures.
Significance. If the empirical claims are substantiated, the work is significant because it targets underexplored challenges specific to dense VLM detectors rather than uni-modal or classification-only settings. The reported margins are large, the framework demonstrates cross-architecture applicability, and the emphasis on producing scoring functions consistent with VLM probabilistic outputs is a constructive contribution. The absence of supporting ablations for the core mechanism, however, limits the strength of the significance assessment at present.
major comments (2)
- [Abstract / NegA module description] Abstract and method description of NegA: the headline FPR95 improvements are attributed to LLM-generated negative labels guiding attention to OOD background regions, yet no ablation isolating label quality (LLM-generated vs. random vs. human-curated negatives) or measuring attention-map overlap with ground-truth OOD masks is reported. This directly bears on whether the observed margins arise from the claimed mechanism or from dataset-specific label statistics.
- [Experiments] Experiments section: the assumption that the generated negatives reliably direct attention without introducing new false positives or degrading ID foreground detection is load-bearing for the central claim, but no quantitative verification (e.g., attention correlation metrics or per-class error breakdown) is provided to confirm the two conditions stated in the skeptic note hold across the evaluated datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of validating the proposed mechanism. We address each major comment below and commit to revisions that strengthen the empirical support without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / NegA module description] Abstract and method description of NegA: the headline FPR95 improvements are attributed to LLM-generated negative labels guiding attention to OOD background regions, yet no ablation isolating label quality (LLM-generated vs. random vs. human-curated negatives) or measuring attention-map overlap with ground-truth OOD masks is reported. This directly bears on whether the observed margins arise from the claimed mechanism or from dataset-specific label statistics.
Authors: We agree that isolating the contribution of LLM-generated negative label quality via explicit ablations (against random or human-curated alternatives) and providing attention-map overlap metrics with OOD ground truth would more directly substantiate the mechanism. The current manuscript relies on end-to-end performance gains and cross-architecture consistency to support the claim, but these do not fully rule out alternative explanations. We will add the requested ablations and attention correlation analysis in the revised version. revision: yes
-
Referee: [Experiments] Experiments section: the assumption that the generated negatives reliably direct attention without introducing new false positives or degrading ID foreground detection is load-bearing for the central claim, but no quantitative verification (e.g., attention correlation metrics or per-class error breakdown) is provided to confirm the two conditions stated in the skeptic note hold across the evaluated datasets.
Authors: The manuscript does not include the suggested quantitative checks such as attention correlation metrics or per-class ID error breakdowns to verify that negative labels steer attention without new false positives or ID degradation. While the reported preservation of ID mAP and large OOD gains are consistent with the assumption, direct verification is absent. We will incorporate these metrics and breakdowns in the revision to address this point. revision: yes
Circularity Check
No circularity; empirical method addition with no derivations or self-referential reductions
full rationale
The paper introduces NegAS as an empirical framework consisting of the NegA attention module (using LLM-generated negative labels) and NegS scoring function. No equations, derivations, or parameter-fitting steps are described that reduce to inputs by construction. Claims rest on experimental results (FPR95 reductions on COCO/OpenImages) rather than tautological definitions or self-citation chains. The approach is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bai, Y., Han, Z., Cao, B., Jiang, X., Hu, Q., Zhang, C.: Id-like prompt learn- ing for few-shot out-of-distribution detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17480–17489 (2024)
2024
-
[2]
arXiv preprint arXiv:2406.00806 (2024)
Cao, C., Zhong, Z., Zhou, Z., Liu, Y., Liu, T., Han, B.: Envisioning outlier ex- posure by large language models for out-of-distribution detection. arXiv preprint arXiv:2406.00806 (2024)
arXiv 2024
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, T., Song, L., Ge, Y., Liu, W., Wang, X., Shan, Y.: Yolo-world: Real-time open-vocabulary object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16901–16911 (2024)
2024
-
[4]
Advances in neural information processing systems35, 20434–20449 (2022)
Du, X., Gozum, G., Ming, Y., Li, Y.: Siren: Shaping representations for detecting out-of-distribution objects. Advances in neural information processing systems35, 20434–20449 (2022)
2022
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Du, X., Wang, X., Gozum, G., Li, Y.: Unknown-aware object detection: Learning what you don’t know from videos in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13678–13688 (2022)
2022
-
[6]
arXiv preprint arXiv:2202.01197 (2022)
Du, X., Wang, Z., Cai, M., Li, Y.: Vos: Learning what you don’t know by virtual outlier synthesis. arXiv preprint arXiv:2202.01197 (2022)
arXiv 2022
-
[7]
Everingham,M.,VanGool,L.,Williams,C.K.,Winn,J.,Zisserman,A.:Thepascal visualobjectclasses(voc)challenge.Internationaljournalofcomputervision88(2), 303–338 (2010)
2010
-
[8]
In: European conference on computer vision
Feng, C., Zhong, Y., Jie, Z., Chu, X., Ren, H., Wei, X., Xie, W., Ma, L.: Prompt- det: Towards open-vocabulary detection using uncurated images. In: European conference on computer vision. pp. 701–717. Springer (2022)
2022
-
[9]
arXiv preprint arXiv:2104.13921 (2021)
Gu, X., Lin, T.Y., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 (2021)
Pith/arXiv arXiv 2021
-
[10]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Hsu, Y.C., Shen, Y., Jin, H., Kira, Z.: Generalized odin: Detecting out-of- distribution image without learning from out-of-distribution data. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10951–10960 (2020)
2020
-
[11]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[12]
arXiv preprint arXiv:2403.20078 (2024)
Jiang, X., Liu, F., Fang, Z., Chen, H., Liu, T., Zheng, F., Han, B.: Negative la- bel guided ood detection with pretrained vision-language models. arXiv preprint arXiv:2403.20078 (2024)
arXiv 2024
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19113–19122 (2023)
2023
-
[14]
International journal of computer vision128(7), 1956–1981 (2020)
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Ka- mali, S., Popov, S., Malloci, M., Kolesnikov, A., et al.: The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision128(7), 1956–1981 (2020)
1956
-
[15]
In: European Conference on Computer Vision
Lafon, M., Ramzi, E., Rambour, C., Audebert, N., Thome, N.: Gallop: Learning global and local prompts for vision-language models. In: European Conference on Computer Vision. pp. 264–282. Springer (2024)
2024
-
[16]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., et al.: Grounded language-image pre-training. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10965–10975 (2022) NegAS: Negative Label Guided OOD Detection with VLMs 19
2022
-
[17]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Li, T., Pang, G., Bai, X., Miao, W., Zheng, J.: Learning transferable negative prompts for out-of-distribution detection. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 17584–17594 (2024)
2024
-
[18]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[19]
Liu, J., Wen, X., Zhao, S., Chen, Y., Qi, X.: Can ood object detectors learn from foundation models? In: European Conference on Computer Vision. pp. 213–231. Springer (2024)
2024
-
[20]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[21]
Advances in neural information processing systems33, 21464–21475 (2020)
Liu, W., Wang, X., Owens, J., Li, Y.: Energy-based out-of-distribution detection. Advances in neural information processing systems33, 21464–21475 (2020)
2020
-
[22]
Advances in neural information processing systems35, 35087–35102 (2022)
Ming, Y., Cai, Z., Gu, J., Sun, Y., Li, W., Li, Y.: Delving into out-of-distribution detection with vision-language representations. Advances in neural information processing systems35, 35087–35102 (2022)
2022
-
[23]
Advances in Neural Information Processing Systems 36, 76298–76310 (2023)
Miyai, A., Yu, Q., Irie, G., Aizawa, K.: Locoop: Few-shot out-of-distribution de- tection via prompt learning. Advances in Neural Information Processing Systems 36, 76298–76310 (2023)
2023
-
[24]
arXiv preprint arXiv:2304.04521 (2023)
Miyai, A., Yu, Q., Irie, G., Aizawa, K.: Zero-shot in-distribution detection in multi-object settings using vision-language foundation models. arXiv preprint arXiv:2304.04521 (2023)
arXiv 2023
-
[25]
In: The twelfth international conference on learning representations (2024)
Nie, J., Zhang, Y., Fang, Z., Liu, T., Han, B., Tian, X.: Out-of-distribution detec- tion with negative prompts. In: The twelfth international conference on learning representations (2024)
2024
-
[26]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[27]
IEEE transactions on pattern analysis and machine intelligence39(6), 1137–1149 (2016)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object de- tection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence39(6), 1137–1149 (2016)
2016
-
[28]
In: International conference on machine learning
Sastry, C.S., Oore, S.: Detecting out-of-distribution examples with gram matrices. In: International conference on machine learning. pp. 8491–8501. PMLR (2020)
2020
-
[29]
Advances in neural information processing systems33, 11839–11852 (2020)
Tack, J., Mo, S., Jeong, J., Shin, J.: Csi: Novelty detection via contrastive learning on distributionally shifted instances. Advances in neural information processing systems33, 11839–11852 (2020)
2020
-
[30]
University, P.: About wordnet.https://wordnet.princeton.edu/(2010), ac- cessed: 2025-11-09
2010
-
[31]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[32]
In: Proceedings of the ieee/cvf international conference on computer vision
Wilson, S., Fischer, T., Dayoub, F., Miller, D., Sünderhauf, N.: Safe: Sensitivity- aware features for out-of-distribution object detection. In: Proceedings of the ieee/cvf international conference on computer vision. pp. 23565–23576 (2023)
2023
-
[33]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wu, A., Chen, D., Deng, C.: Deep feature deblurring diffusion for detecting out- of-distribution objects. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13381–13391 (2023) 20 Y. Zhang, S. Li and P. Wang
2023
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, A., Deng, C.: Discriminating known from unknown objects via structure- enhanced recurrent variational autoencoder. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23956–23965 (2023)
2023
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, A., Deng, C.: Percept, memory, and imagine: World feature simulating for open-domain unknown object detection. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4682–4691 (2025)
2025
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 2636–2645 (2020)
2020
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision- language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16816–16825 (2022)
2022
-
[38]
International Journal of Computer Vision130(9), 2337–2348 (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International Journal of Computer Vision130(9), 2337–2348 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.