MASS: Deep Research for Social Sciences with Memory-Augmented Social Simulation
Pith reviewed 2026-06-27 16:53 UTC · model grok-4.3
The pith
Memory-augmented social simulations let LLMs generate social science papers with greater insight and empirical grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
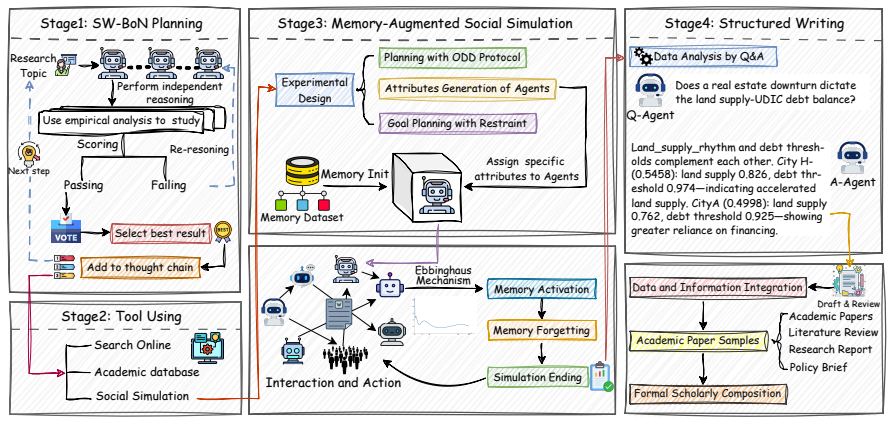
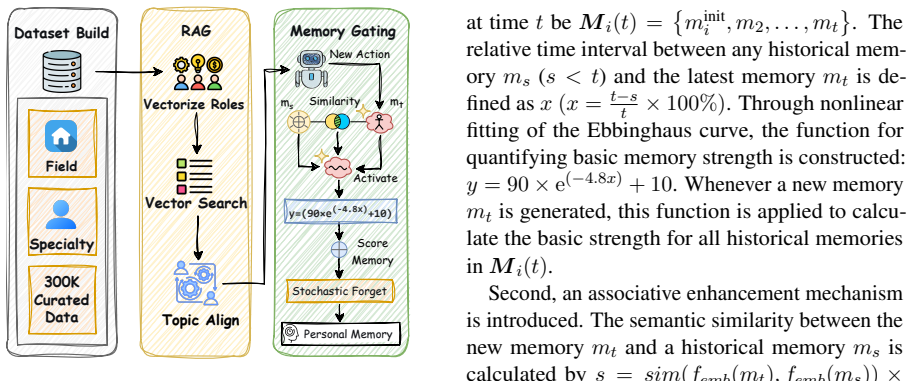
MASS integrates dynamic goal-path planning with multi-level social norm restraint, a multi-disciplinary behavior dataset for agent memory cold-start, and a structured forgetting mechanism inspired by the Ebbinghaus curve. Together these produce highly realistic, research-oriented social simulations that give LLMs an empirical foundation for generating innovative scholarly papers in the social sciences.
What carries the argument
Memory-Augmented Social Simulation (MASS) with its three components that turn multi-agent interactions into source material for LLM research writing.
If this is right
- LLM-generated papers achieve higher overall quality when grounded in simulated social data.
- Insight scores rise substantially compared with retrieval-only baselines.
- Social simulation supplies a distinct source of novelty beyond literature synthesis.
- The three-component architecture can be reused for other automated research tasks in the social sciences.
- Structured forgetting keeps long simulations stable enough to support sustained empirical claims.
Where Pith is reading between the lines
- The same simulation approach could be tested in adjacent fields such as behavioral economics where rich interaction datasets already exist.
- Adding a human-in-the-loop validation step on the simulated behaviors would directly test whether the generated insights survive external scrutiny.
- Merging MASS outputs with conventional retrieval might produce hybrid systems that combine simulation novelty with documented evidence.
- The forgetting schedule could be adapted for memory management in other long-horizon LLM agent tasks outside research writing.
Load-bearing premise
The social simulations must be realistic enough to generate genuinely new and empirically valid research insights rather than artifacts of the simulation rules.
What would settle it
An experiment in which expert social scientists rate papers produced with and without the MASS simulation components and find no reliable difference in insight or novelty scores.
Figures
read the original abstract
Deep Research agents powered by Large Language Models (LLMs) have exhibited extraordinary potential in automated paper writing tasks. However, existing systems rely heavily on literature retrieval and synthesis through internet and local knowledge bases, often resulting research in lacking insight and creativity in social science. To address this issue, we propose "Memory-Augmented Social Simulation (MASS)", an innovative paradigm that leverages highly realistic and research-oriented social simulations to enhance the creativity and empirical founding of LLMs-generated research. Specifically, MASS integrates three core components: dynamic goal-path planning with multi-level social norm restraint to guide the simulation, a multi-disciplinary behavior dataset for agent memory cold-start, and a structured forgetting mechanism inspired by the Ebbinghaus curve. Together, these ensure simulation authenticity and provide a robust empirical foundation for generating innovative scholarly papers. Experimental results demonstrate the effectiveness of our method, showing a 6.81\% improvement in generation overall quality over foundation LLMs and 17.19\% gain in Insight over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
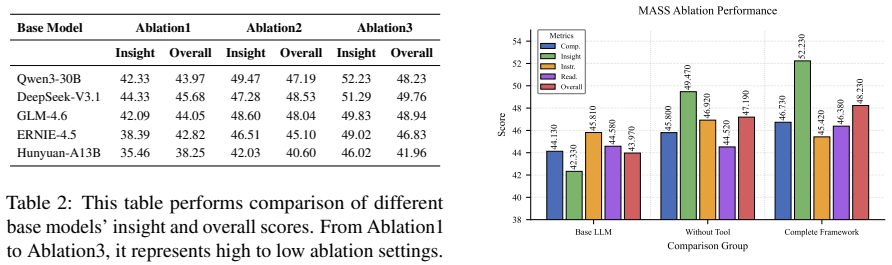
Summary. The paper proposes Memory-Augmented Social Simulation (MASS) as a new paradigm for LLM-based deep research in social sciences. MASS combines three components—dynamic goal-path planning with multi-level social norm restraint, a multi-disciplinary behavior dataset for agent memory cold-start, and an Ebbinghaus-inspired structured forgetting mechanism—to produce realistic social simulations that supply an empirical foundation for generating more creative and insightful scholarly papers. The central claim is that this yields measurable gains: 6.81% improvement in overall generation quality over foundation LLMs and 17.19% gain in Insight over strong baselines.
Significance. If the simulation fidelity and evaluation protocol can be rigorously validated, the approach could address a recognized limitation of retrieval-only LLM research agents by supplying grounded behavioral data for social-science hypothesis generation. The explicit use of norm restraint, cold-start memory, and forgetting curves is a concrete attempt to operationalize realism, which would be a useful contribution if the resulting outputs demonstrably improve downstream paper quality beyond prompt engineering.
major comments (3)
- [Abstract] Abstract: The headline results (6.81% quality, 17.19% Insight) are asserted without any description of experimental design, baselines, metrics, sample size, statistical tests, or evaluation protocol. This absence makes it impossible to determine whether the deltas are attributable to the three MASS components rather than evaluator bias or prompt differences.
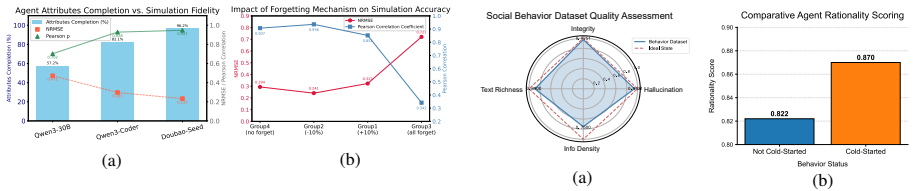
- [Abstract] Abstract / §4 (assumed experimental section): No ablation results are reported that isolate the contribution of dynamic goal-path planning, the multi-disciplinary dataset, or the forgetting mechanism to the reported gains. Without these, the claim that the three components together “ensure simulation authenticity” remains untested.
- [Abstract] Abstract: The “Insight” metric is introduced without definition or validation protocol (human raters? LLM-as-judge? inter-rater reliability? alignment with real behavioral datasets). This raises a circularity concern: if Insight is scored by the same LLM pipeline that implements MASS, the 17.19% gain cannot be interpreted as evidence of improved empirical grounding.
minor comments (1)
- [Abstract] Abstract contains a grammatical error: “often resulting research in lacking insight” should read “often resulting in research lacking insight.”
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline results (6.81% quality, 17.19% Insight) are asserted without any description of experimental design, baselines, metrics, sample size, statistical tests, or evaluation protocol. This absence makes it impossible to determine whether the deltas are attributable to the three MASS components rather than evaluator bias or prompt differences.
Authors: We agree that the abstract is too concise and omits key experimental details. In the revised version we will expand the abstract to briefly describe the experimental design, baselines, metrics, sample sizes, evaluation protocol, and any statistical tests used. revision: yes
-
Referee: [Abstract] Abstract / §4 (assumed experimental section): No ablation results are reported that isolate the contribution of dynamic goal-path planning, the multi-disciplinary dataset, or the forgetting mechanism to the reported gains. Without these, the claim that the three components together “ensure simulation authenticity” remains untested.
Authors: We acknowledge that dedicated ablations are needed to isolate each component. The current manuscript contains some component-wise analysis, but we will add explicit ablation experiments in the revised experimental section to quantify the individual contributions of dynamic goal-path planning, the multi-disciplinary dataset, and the forgetting mechanism. revision: yes
-
Referee: [Abstract] Abstract: The “Insight” metric is introduced without definition or validation protocol (human raters? LLM-as-judge? inter-rater reliability? alignment with real behavioral datasets). This raises a circularity concern: if Insight is scored by the same LLM pipeline that implements MASS, the 17.19% gain cannot be interpreted as evidence of improved empirical grounding.
Authors: We will revise both the abstract and the methods section to define the Insight metric explicitly, specify the evaluation protocol (including whether human raters or LLM judges are used), report inter-rater reliability, and describe alignment with behavioral datasets. We will also clarify that evaluation is performed by independent judges separate from the MASS simulation agents to mitigate circularity concerns. revision: yes
Circularity Check
No significant circularity; empirical claims rest on reported experiments.
full rationale
The paper proposes the MASS paradigm with three components and reports experimental percentage gains (6.81% quality, 17.19% Insight) over baselines. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described structure. The central claim is an empirical demonstration of effectiveness rather than a mathematical reduction to inputs by construction. While simulation realism is asserted as an assumption, this does not trigger any of the enumerated circularity patterns (self-definitional, fitted-input prediction, etc.). The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Highly realistic and research-oriented social simulations can enhance the creativity and empirical grounding of LLM-generated research in social sciences.
invented entities (1)
-
Memory-Augmented Social Simulation (MASS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2024 Joint International Conference on Computational Linguis- tics, Language Resources and Evaluation (LREC- COLING 2024), pages 10476–10487, Torino, Italia
LHMKE: A Large-scale Holistic Multi-subject Knowledge Evaluation Benchmark for Chinese Large Language Models. InProceedings of the 2024 Joint International Conference on Computational Linguis- tics, Language Resources and Evaluation (LREC- COLING 2024), pages 10476–10487, Torino, Italia. ELRA and ICCL. Yusong Ma, Hongxuan Nie, Chao Chen, Jiujie Zhang, Jia...
2024
-
[2]
Technical report, National Bureau of Economic Research
Automated Social Science: Language Models as Scientist and Subjects. Technical report, National Bureau of Economic Research. Scott Merrill and Shashank Srivastava. 2025. Point of Order: Action-Aware LLM Persona Modeling for Realistic Civic Simulation.arXiv preprint arXiv:2511.17813. Jaap MJ Murre and Joeri Dros. 2015. Replication and Analysis of Ebbinghau...
arXiv 2025
-
[3]
Agentsociety: Large-scale Simulation of Llm- driven Generative Agents Advances Understanding of Human Behaviors and Society.arXiv preprint arXiv:2502.08691. Riwa Saied. 2025. How to Use Perplexity AI (2025): Screenshots, Citations & Setup. Online Technical Guide. Jiabin Tang, Tianyu Fan, and Chao Huang. 2025. Autoa- gent: A Fully-Automated and Zero-Code F...
Pith/arXiv arXiv 2025
-
[4]
From Agent Simulation to Social Simulator: A Comprehensive Review (Part 1).arXiv preprint arXiv:2510.18271. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, volume 36, pages 1...
arXiv 2023
-
[5]
The result should generally be within 100 characters
thinkingContent: string type, representing the initial thoughts on the writing plan for a social science research paper based on requirements and various prompts. The result should generally be within 100 characters
-
[6]
Return True if needed, and False if not
ISInternet: boolean type, indicating whether an internet search for relevant content is needed before the next thinking session. Return True if needed, and False if not
-
[7]
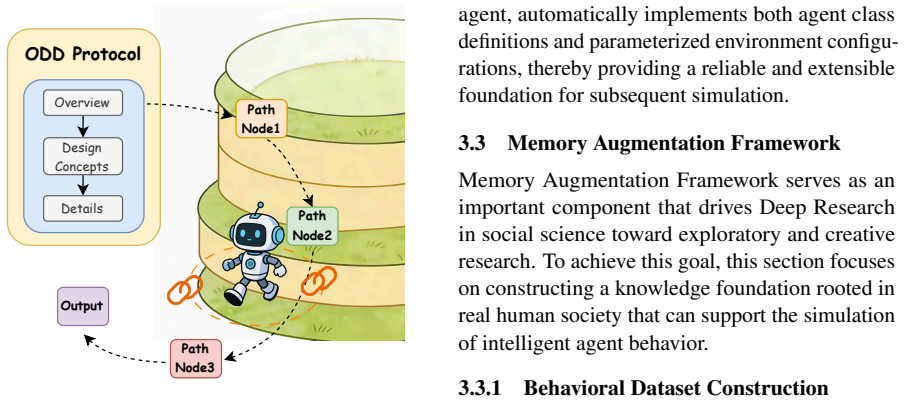
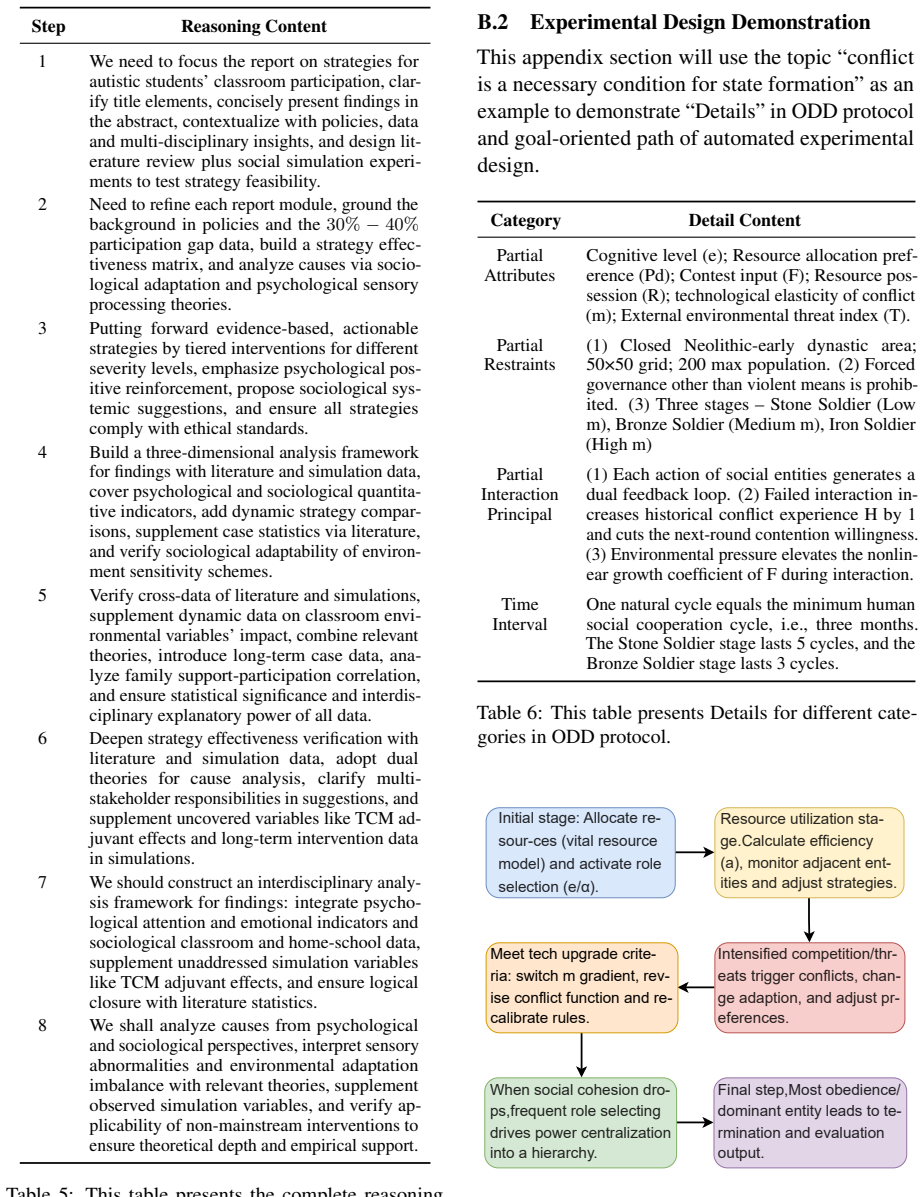
scope and boundaries,
keyword: string type, representing the keywords to be searched online before the next session. If no online search is required, return an empty string. Automated Experimental Design Prompt System Prompt:You are a research assistant specializing in automated academic research and thesis writing in the social sciences, assisting researchers in this field wi...
-
[8]
Based on the overview and design concepts of the ODD protocol described above, output the attribute names and descriptions required for each social entity
attribute: Type List[str], representing the attributes of a social entity. Based on the overview and design concepts of the ODD protocol described above, output the attribute names and descriptions required for each social entity
-
[9]
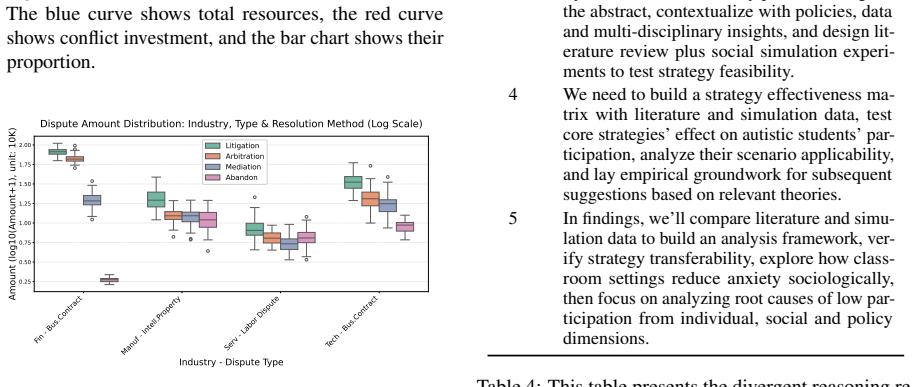
envRestraint: of type str, representing specific environmental constraints within the simulator. Based on the overview and design concepts of the ODD protocol described above, as well as the topics and Q&A content from the dialogue history, output a general summary describing the specific constraints of the social environment in the social simulator
-
[10]
It summarizes how the entity’s behavior feeds back to influence its own attributes
entityFeedback: str type, representing a description of how a social entity’s behavior affects its attributes. It summarizes how the entity’s behavior feeds back to influence its own attributes
-
[11]
It outputs a specific social time to provide a basis for action
timeInterval: str type, representing the interval between two actions of a social entity. It outputs a specific social time to provide a basis for action. Social Simulation Prompt System Prompt:[2pt] You are a social entity (i.e., a person in society) within the Social Simulator. Your social attributes, personality traits, physical characteristics, social...
-
[12]
Every action you take must strictly adhere to your behavioral characteristics, physiological traits, social attributes, and other relevant features; you must not act arbitrarily without regard to your actual circumstances
-
[13]
All your previous actions are recorded in the ‘Action‘ attribute; you must refer to these records when planning your next action
You may base your decision for the next action on your network of relationships with other social entities and the sequence of actions preceding this one. All your previous actions are recorded in the ‘Action‘ attribute; you must refer to these records when planning your next action
-
[14]
Your actions may include major life events and decisions, engaging in social interactions with other social entities, or making significant decisions or initiating events through such interactions
-
[15]
You must act in accordance with this plan
Since your behavior must align with the theme of the social simulation experiment, we will provide you with a general action path plan. You must act in accordance with this plan
-
[16]
By default, all social entities already exist, so there is no need to start path planning from scratch
The initialization of social entities has been completed. By default, all social entities already exist, so there is no need to start path planning from scratch. Instead, begin by planning the general direction in which the social entities should move in their first step. The general action path planning is shown below: {pathPlanning} User Prompt Template...
-
[17]
isSocialize: boolean type; can only be True or False, indicating whether this social entity needs to interact with other social entities
-
[18]
This field describes the purpose of the social entity’s interaction with its target and specific details of the interaction
socializeContent: string type. This field describes the purpose of the social entity’s interaction with its target and specific details of the interaction. The description should be as detailed as possible, with a minimum length of approximately 150 characters
-
[19]
This field describes the specific details of the social entity’s current action
actionContent: string type. This field describes the specific details of the social entity’s current action. The description should be as detailed as possible, with a minimum length of approximately 200 characters. D Algorithm Pseudocode This appendix section presents the algorithmic pseudocode for agents interaction processes in so- cial simulation exper...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.