ProDG: Prototypes for Data-Free Generative Post-Hoc Explainability
Pith reviewed 2026-05-21 09:01 UTC · model grok-4.3
The pith
ProDG generates high-fidelity visual prototypes for model explanations directly from frozen network weights without any external data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
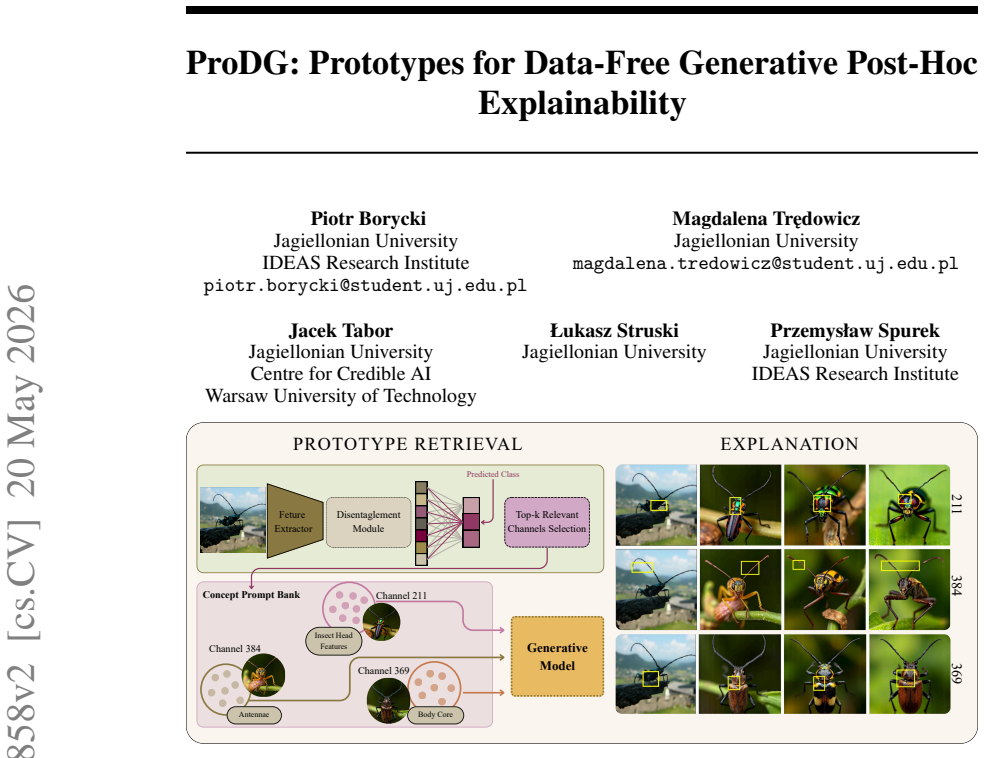
ProDG leverages generative models to synthesize pure, high-fidelity prototypes directly from the frozen model's weights, completely eliminating the dependency on any external data. By establishing this new frontier in Data-Free XAI, ProDG unlocks robust visual interpretability for privacy-sensitive domains, where original data is strictly restricted or fundamentally inaccessible.
What carries the argument
Generative synthesis of prototypes from model weights alone, which replaces the data-driven search step used in earlier post-hoc prototype methods.
If this is right
- Post-hoc prototype explanations become available for any input image even when no dataset can be released.
- The original classifier requires no retraining or architectural changes.
- The same generative procedure can be applied to any frozen image classifier regardless of its training history.
- Privacy-sensitive applications such as medical imaging or proprietary models gain access to visual prototype explanations.
Where Pith is reading between the lines
- The approach could be adapted to generate prototypes for other explanation styles beyond class prototypes.
- If the generative step proves stable, it may allow on-device interpretability without ever storing user data.
- The method implicitly assumes that the generative model can be trained or conditioned solely on weight statistics rather than image statistics.
Load-bearing premise
Generative models can produce prototypes that faithfully reflect the frozen model's learned features and decision boundaries without any data to guide or validate the synthesis process.
What would settle it
Compare classification accuracy and explanation fidelity when using generated prototypes versus prototypes extracted from an actual held-out dataset on the same frozen model.
Figures
















read the original abstract
Ante-hoc interpretability methods based on prototypes provide highly accurate explanations by utilizing the intuitive "this looks like that" reasoning paradigm. On the other hand, post-hoc models can explain predictions for a single image without relying on an underlying dataset or requiring costly neural network retraining. Recent approaches successfully solve the retraining problem for prototype-based networks. However, they still face a fundamental limitation: they require access to a subset of data (e.g., a test or validation set) to search for and extract the visual prototypes. In this paper, we address this issue and introduce ProDG: Generative Prototypes for Data-Free Post-Hoc Explainability, a novel framework that leverages generative models to synthesize pure, high-fidelity prototypes directly from the frozen model's weights, completely eliminating the dependency on any external data. By establishing this new frontier in Data-Free XAI, ProDG unlocks robust visual interpretability for privacy-sensitive domains, where original data is strictly restricted or fundamentally inaccessible. Project page: https://github.com/piotr310100/ProDG
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProDG, a framework for data-free post-hoc prototype-based explainability. It claims to synthesize high-fidelity visual prototypes directly from the weights of a frozen classifier by conditioning a generative model on those weights, thereby removing any requirement for training, validation, or test data while preserving the 'this looks like that' interpretability paradigm.
Significance. If the central claim holds, the result would enable prototype explanations in privacy-restricted domains where data access is prohibited. The approach correctly identifies the data-dependency limitation in prior post-hoc prototype methods and attempts to close it via generative synthesis rather than retraining or data search.
major comments (2)
- [§3] §3 (Method): The conditioning mechanism that maps frozen-model weights to the generative process is described at a high level but lacks an explicit statement of the surrogate objective and any manifold-regularization term. Without such a term, the optimization that maximizes prototype similarity or class logits can converge to high-activation inputs that lie outside the training manifold, violating the faithfulness requirement for interpretability.
- [§4] §4 (Experiments): No quantitative metric is reported that measures how closely the generated prototypes reproduce the model's internal activations or decision boundaries on held-out data. Qualitative image grids alone cannot establish that the synthesized samples correspond to the visual concepts actually learned by the frozen network rather than artifacts of the generative prior.
minor comments (2)
- [§3.2] Notation for the prototype extraction loss and the generative conditioning function should be introduced once and used consistently; current usage mixes descriptive phrases with ad-hoc symbols.
- [Abstract] The abstract states that prototypes are 'pure' and 'high-fidelity' without defining these terms or linking them to any measurable quantity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and the recommendation for a major revision. We have carefully addressed each of the major comments in our point-by-point response below. Revisions have been made to the manuscript to improve clarity and provide additional quantitative support where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Method): The conditioning mechanism that maps frozen-model weights to the generative process is described at a high level but lacks an explicit statement of the surrogate objective and any manifold-regularization term. Without such a term, the optimization that maximizes prototype similarity or class logits can converge to high-activation inputs that lie outside the training manifold, violating the faithfulness requirement for interpretability.
Authors: We are grateful for this detailed comment on the method section. We agree that making the surrogate objective explicit would enhance the manuscript. In the revised version, we now provide a formal definition of the objective in §3: the generative model is optimized to maximize the target class logit from the frozen classifier, subject to the conditioning on the extracted prototype weights. Furthermore, to prevent out-of-manifold samples, we have added a manifold regularization term that encourages the generated prototypes to have high likelihood under the generative model's prior distribution. This term is implemented via a penalty on the latent code deviation. These changes directly address the concern about faithfulness and we believe they strengthen the technical presentation of the approach. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative metric is reported that measures how closely the generated prototypes reproduce the model's internal activations or decision boundaries on held-out data. Qualitative image grids alone cannot establish that the synthesized samples correspond to the visual concepts actually learned by the frozen network rather than artifacts of the generative prior.
Authors: We thank the referee for raising this important point about the experimental validation. We must note that, by design, ProDG operates without any access to data, including held-out sets, to enable applications in data-restricted environments. Therefore, metrics requiring held-out data cannot be computed. To provide quantitative assessment, we have included in the revised experiments section metrics that evaluate the prototypes using the frozen model itself, such as the mean activation strength for the correct class and the consistency of predictions when using the prototypes for classification. These internal metrics help confirm that the generated samples align with the model's learned decision boundaries rather than being mere artifacts. We have also added comparisons showing improved fidelity over baselines. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents ProDG as a framework that applies pre-existing generative models to synthesize prototypes from a frozen classifier's weights, explicitly eliminating any need for external data during the explanation phase. The abstract frames the contribution as an engineering integration of independent generative components rather than a closed derivation that redefines or refits its own outputs. No equations, optimization loops, or self-citation chains are shown that would reduce a claimed prediction to a fitted parameter or prior result by construction. The approach therefore remains self-contained against external generative-model benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[2]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144, 2016
work page 2016
-
[3]
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PLoS One, 10(7):e0130140, 2015
work page 2015
-
[4]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization.International Journal of Computer Vision, 128:336–359, 2020
work page 2020
-
[5]
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition.Advances in neural information processing systems, 32, 2019
work page 2019
-
[6]
Interpretable image classification with differentiable prototypes assignment
Dawid Rymarczyk, Łukasz Struski, Michał Górszczak, Koryna Lewandowska, Jacek Tabor, and Bartosz Zieli´nski. Interpretable image classification with differentiable prototypes assignment. InEuropean Conference on Computer Vision, pages 351–368. Springer, 2022
work page 2022
-
[7]
Dawid Rymarczyk, Łukasz Struski, Jacek Tabor, and Bartosz Zieli´nski. Protopshare: Prototypi- cal parts sharing for similarity discovery in interpretable image classification. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 1420–1430, 2021
work page 2021
-
[8]
Neural prototype trees for interpretable fine-grained image recognition
Meike Nauta, Ron Van Bree, and Christin Seifert. Neural prototype trees for interpretable fine-grained image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14933–14943, 2021
work page 2021
-
[9]
This looks like it rather than that: Protoknn for similarity-based classifiers
Yuki Ukai, Tsubasa Hirakawa, Takayoshi Yamashita, and Hironobu Fujiyoshi. This looks like it rather than that: Protoknn for similarity-based classifiers. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[10]
Pip-net: Patch-based intuitive prototypes for interpretable image classification
Meike Nauta, Jörg Schlötterer, Maurice Van Keulen, and Christin Seifert. Pip-net: Patch-based intuitive prototypes for interpretable image classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2744–2753, 2023
work page 2023
-
[11]
Łukasz Struski, Dawid Rymarczyk, and Jacek Tabor. Infodisent: Explainability of image classification models by information disentanglement.arXiv preprint arXiv:2409.10329, 2024
-
[12]
Viktar Dubovik, Łukasz Struski, Jacek Tabor, and Dawid Rymarczyk. Side: Sparse information disentanglement for explainable artificial intelligence.arXiv preprint arXiv:2507.19321, 2025
-
[13]
Epic: Explanation of pretrained image classification networks via prototypes
Piotr Borycki, Magdalena Tr˛ edowicz, Szymon Janusz, Jacek Tabor, Przemysław Spurek, Arka- diusz Lewicki, and Łukasz Struski. Epic: Explanation of pretrained image classification networks via prototypes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17366–17373, 2026
work page 2026
-
[14]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 10 l o o k s l i k e z o o m r e g i o n l o o k s l i k e l o o k s l i k e l o o k s l i k e prototype no. 1 prototype no. 2 prototype no. 3 prototype no. 4 Figure 7:User study instructions and guide.Illustrative guide presented prior to the user-study questionnaire, demonstrating ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.