ContextShift: A Controlled Benchmark for Context Dependence in Object Detection
Pith reviewed 2026-06-27 17:04 UTC · model grok-4.3
The pith
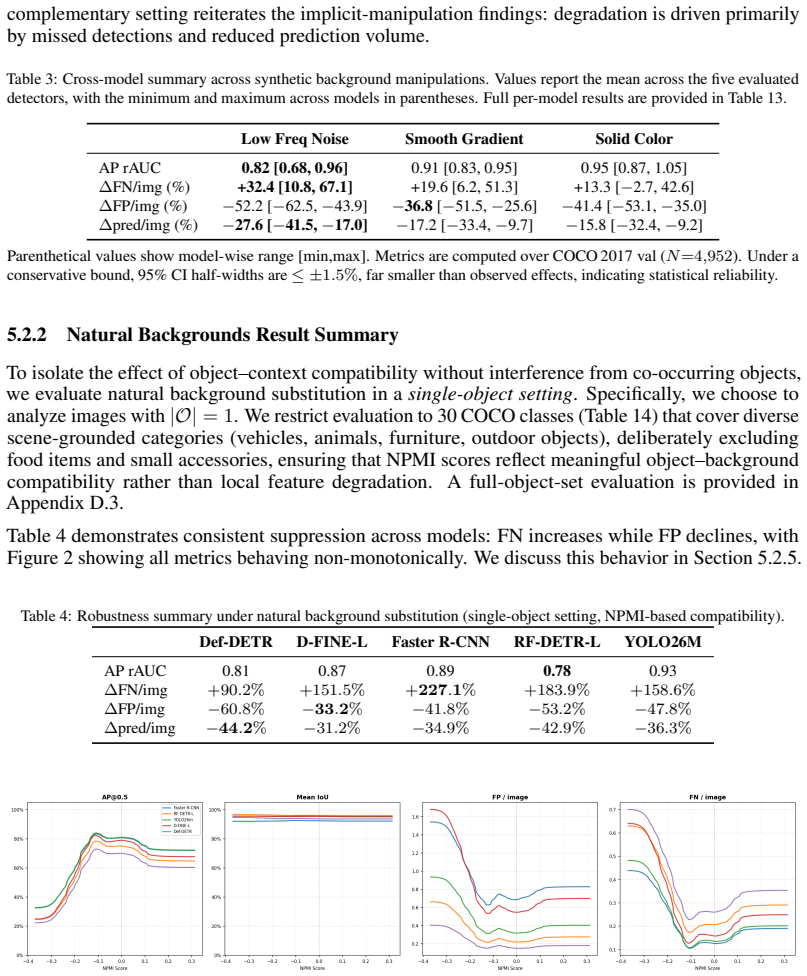
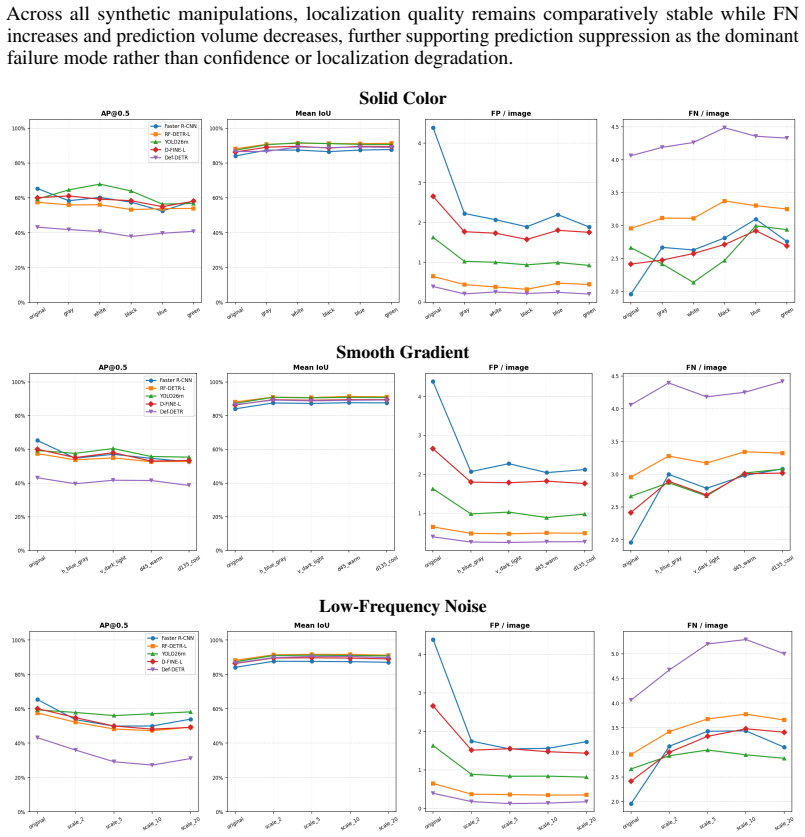
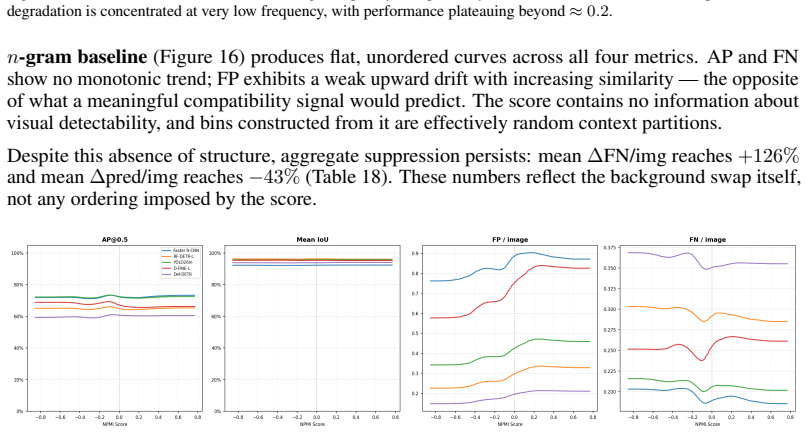
Object detectors miss more objects and produce fewer predictions when context is altered while objects stay identical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
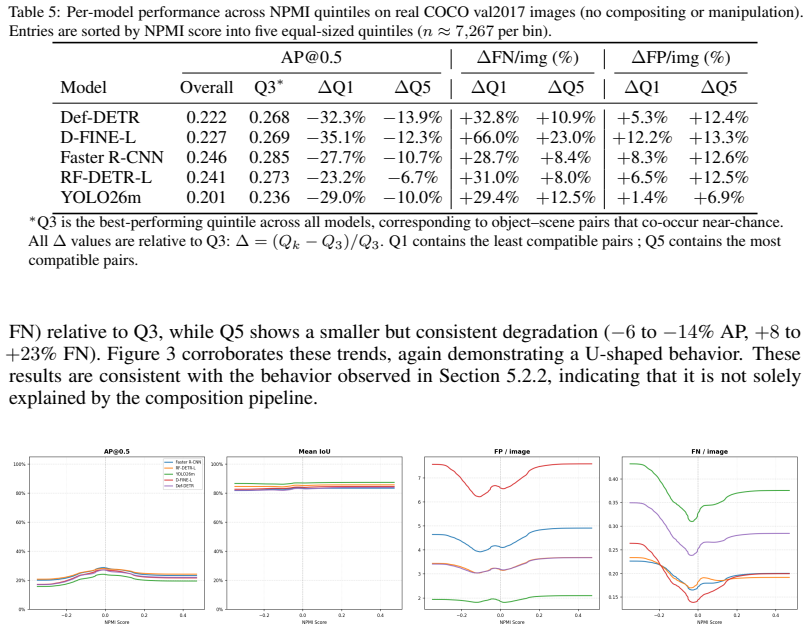
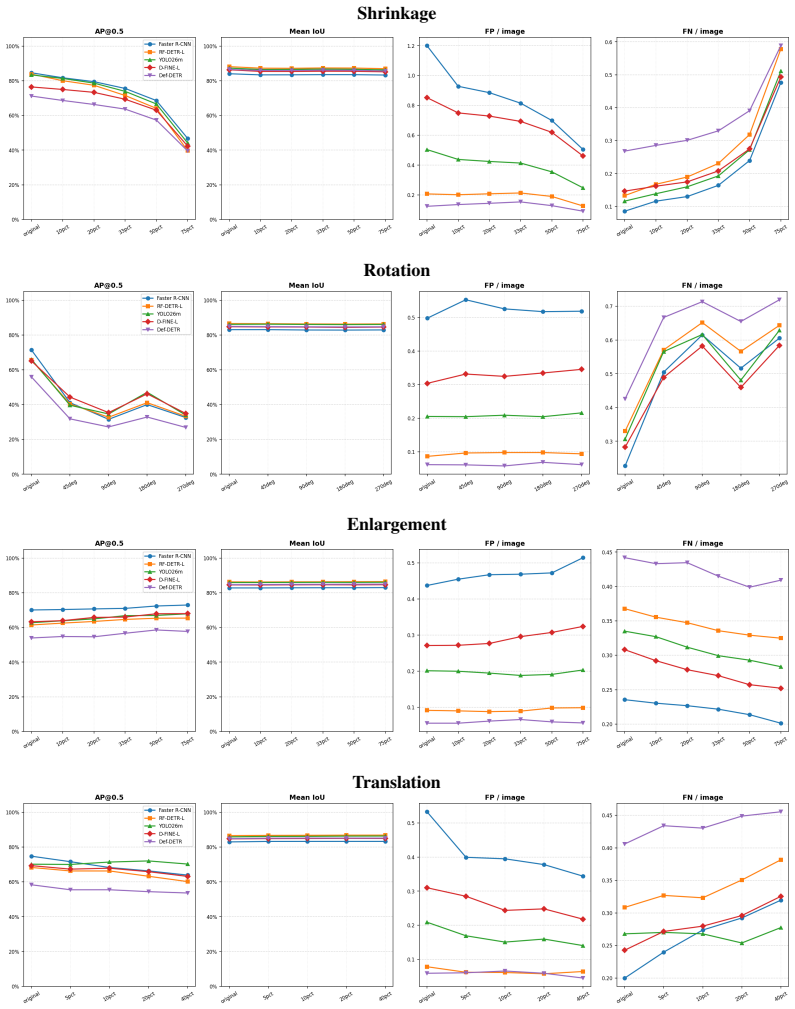
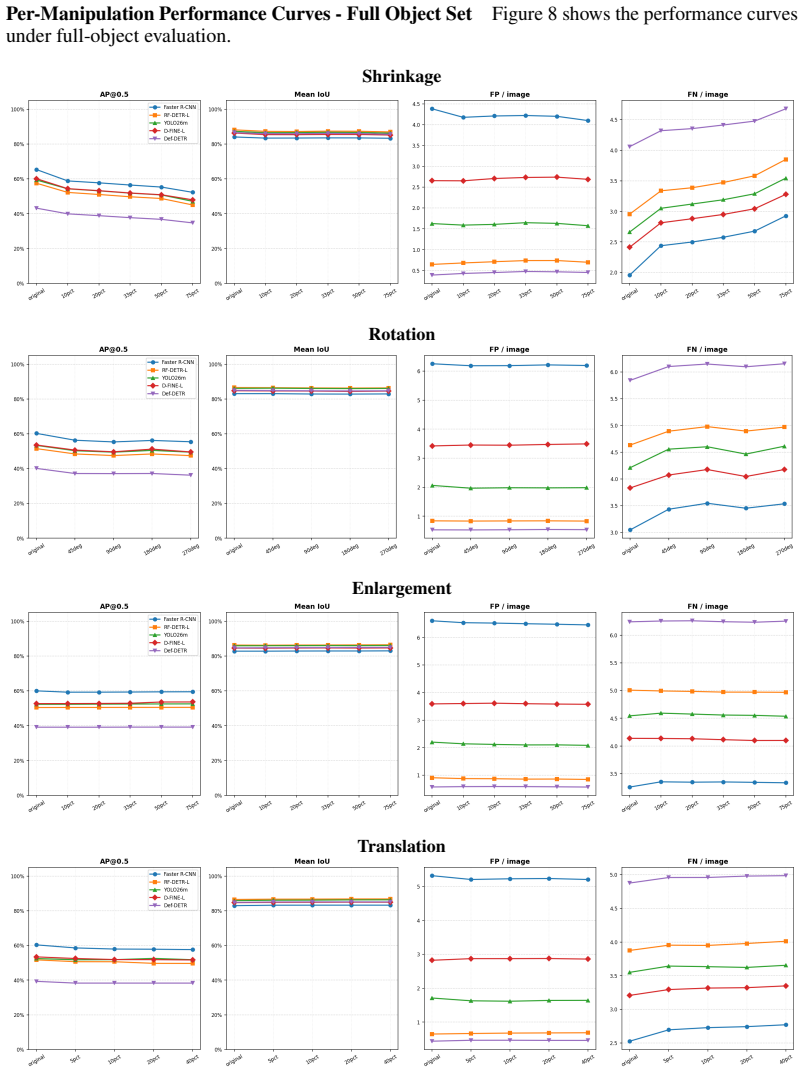
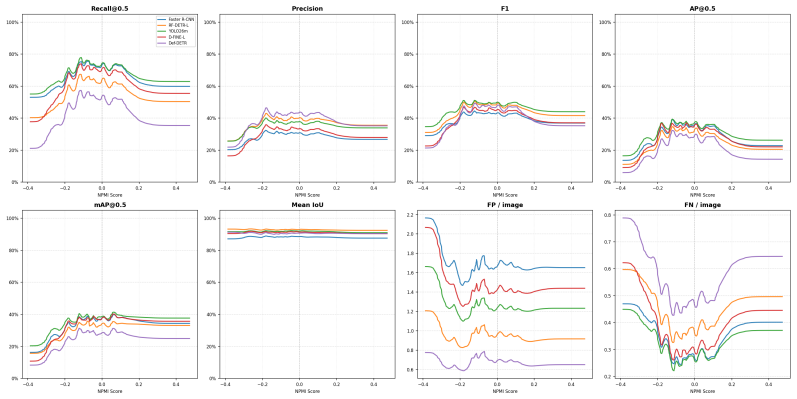
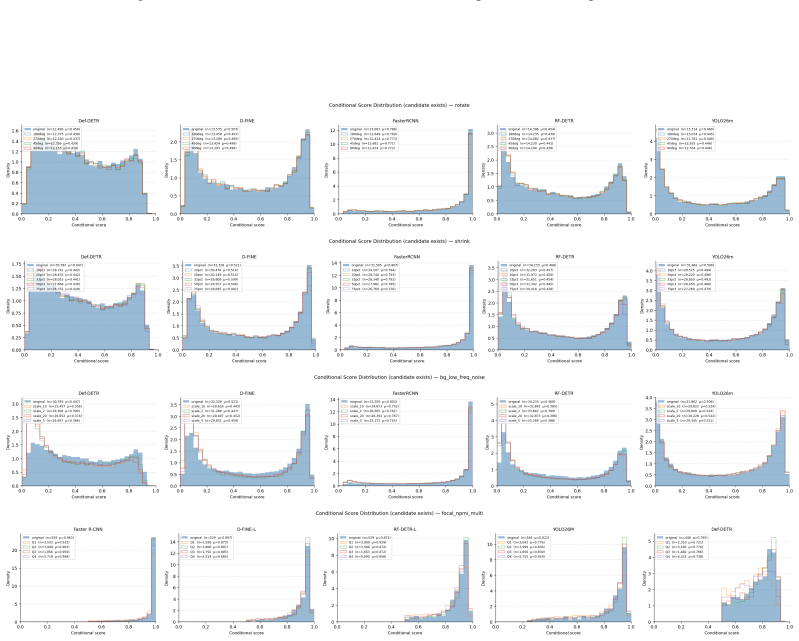
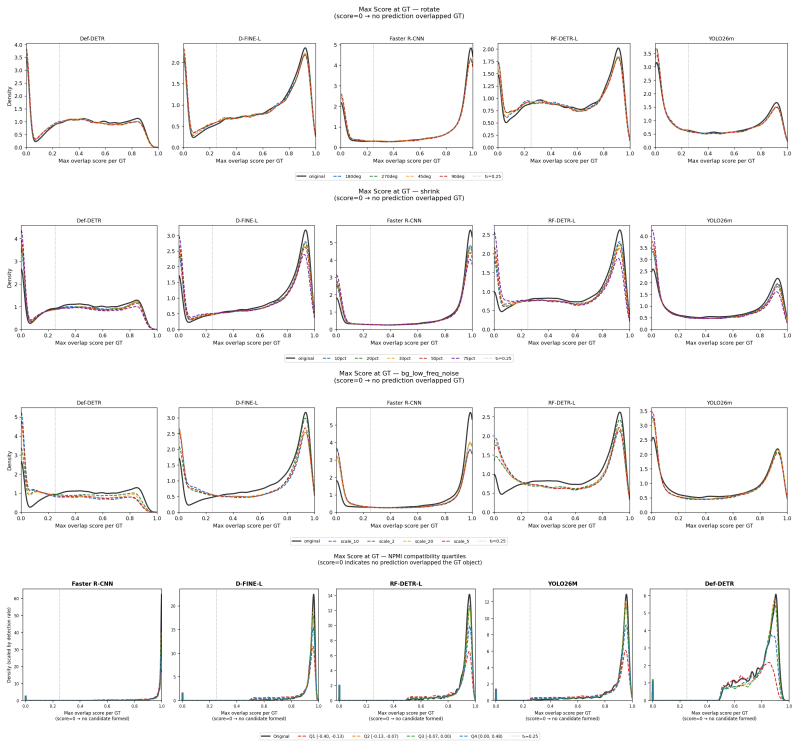
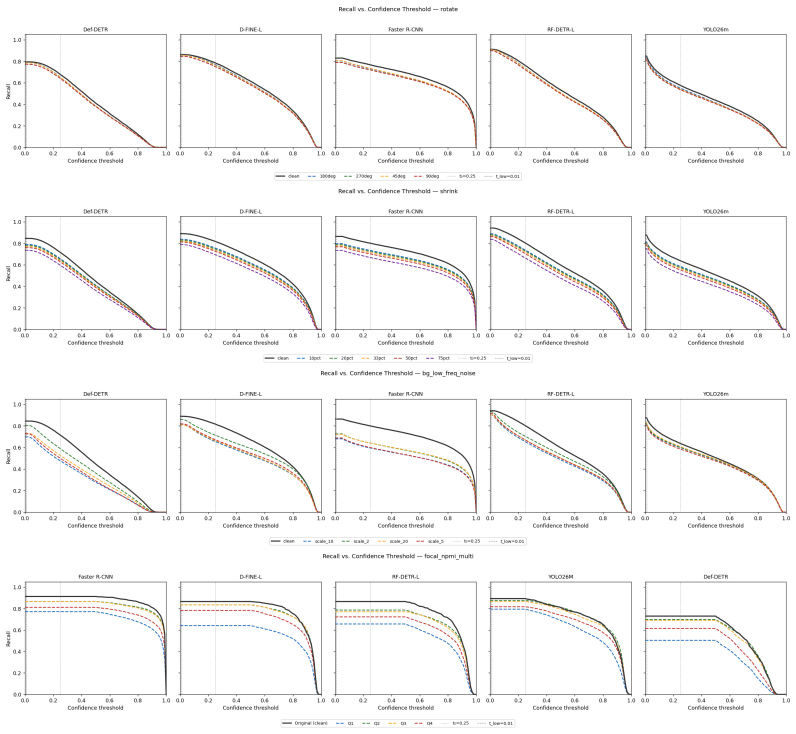
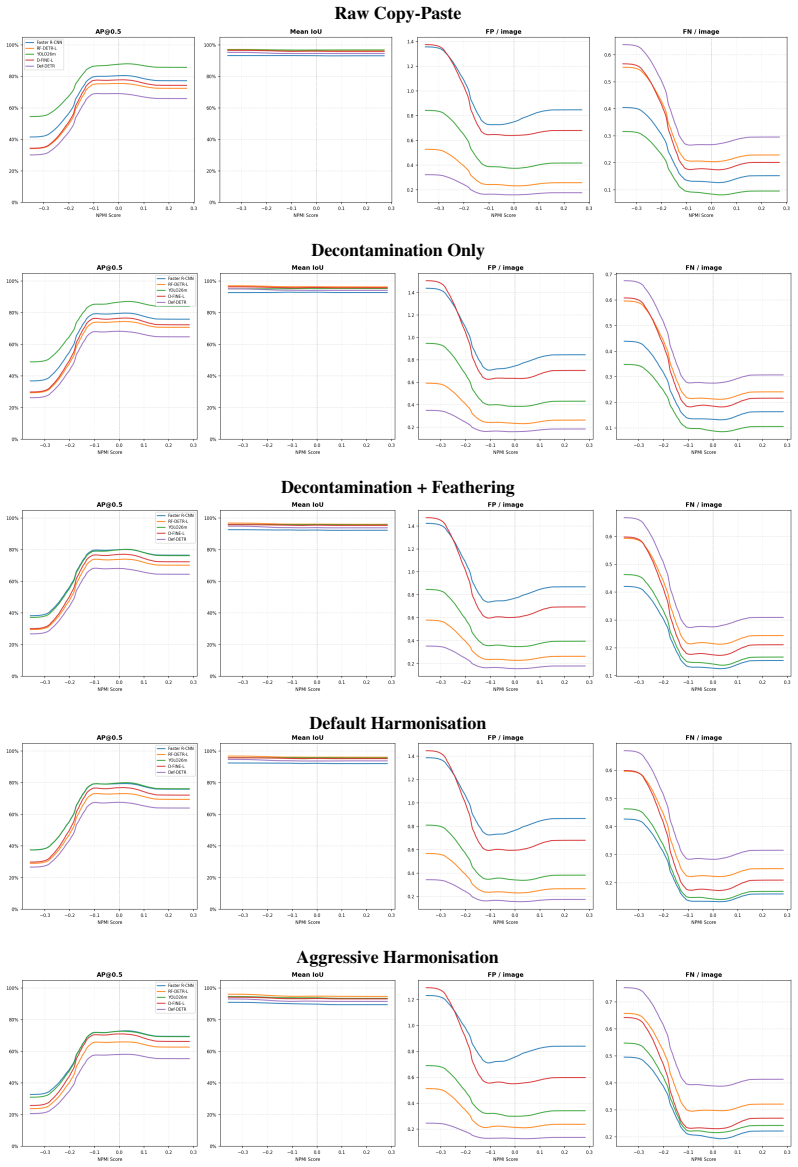
Across detectors, controlled context manipulations produce up to 227% more false negatives and up to 44% fewer predictions while false positives remain stable or decline; this suppression is driven by reduced formation of valid candidates, is masked by AP, shows non-monotonic dependence on normalized pointwise mutual information, and can be partially recovered by context-aware training augmentations.
What carries the argument
ContextShift benchmark that isolates context via geometric transformations and synthetic/natural background substitutions on COCO images, with a continuous compatibility axis based on normalized pointwise mutual information.
If this is right
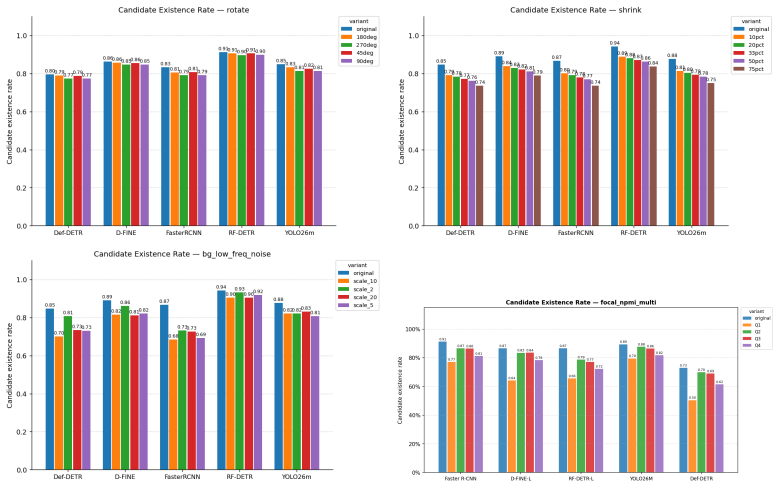
- Detectors form fewer valid candidates once object-context pairings are broken.
- AP scores can remain stable while recall losses grow large under context change.
- Exposing models to object-context decoupling during training raises performance on both original and altered test images.
Where Pith is reading between the lines
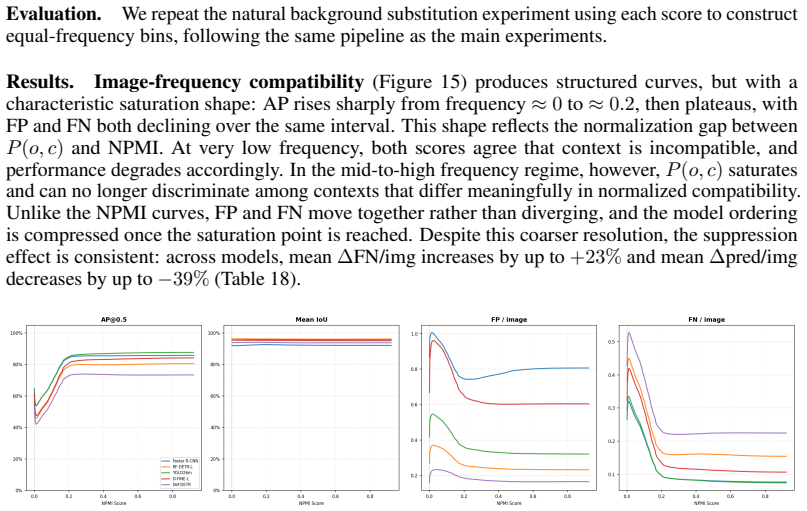
- The non-monotonic pattern with statistical compatibility suggests detectors may over-rely on typical co-occurrences rather than learning robust visual features.
- The same controlled manipulation approach could be extended to measure context sensitivity in segmentation or pose estimation.
Load-bearing premise
The manipulations keep object appearance exactly the same and change nothing else visually besides the intended context shift.
What would settle it
Run the same detectors on paired images that differ only by background replacement or object repositioning and check whether false-negative counts rise and total predictions fall without corresponding rises in false positives.
Figures



read the original abstract
Modern object detectors achieve strong performance on standard benchmarks, yet their robustness to contextual variation remains insufficiently understood. Prior evaluations largely rely on aggregate metrics such as AP on uncontrolled distribution shifts, which can obscure how performance degrades under context change. We introduce ContextShift, a controlled benchmark that systematically manipulates object--context relationships while preserving object appearance. Built on COCO 2017, it isolates context as an independent variable through geometric transformations and synthetic and natural background substitutions, including a continuous compatibility axis based on normalized pointwise mutual information (NPMI). Across diverse detector architectures, we observe a consistent degradation pattern: false negatives increase by up to 227% and prediction volume decreases by up to 44%, while false positives remain stable or decline. This suppression behavior is not captured by aggregate metrics such as AP, which can mask substantial recall loss and changes in prediction dynamics. Further analysis suggests that degradation is driven less by reduced confidence than by a reduced formation of valid detection candidates. Moreover, performance along the statistical compatibility axis is non-monotonic, peaking at intermediate NPMI and degrading toward both extremes, indicating that statistical co-occurrence does not correlate linearly with effective visual context. Finally, we show that context-aware augmentation improves robustness: every augmented variant outperforms the dataset-only baseline on both original and manipulated test images, partially recovering performance lost to prediction-suppression failures by exposing models to object--context decoupling during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContextShift, a controlled benchmark on COCO 2017 that manipulates object-context relationships via geometric transformations and synthetic/natural background substitutions while claiming to preserve object appearance exactly. It defines a continuous compatibility axis using normalized pointwise mutual information (NPMI). Across multiple detector architectures, it reports consistent degradation: false negatives rise by up to 227%, prediction volume falls by up to 44%, false positives remain stable or decline; these effects are not captured by aggregate AP. Degradation is attributed to reduced candidate formation rather than confidence drop. NPMI performance is non-monotonic (peaks at intermediate values). Context-aware augmentation during training partially recovers performance on both original and manipulated images.
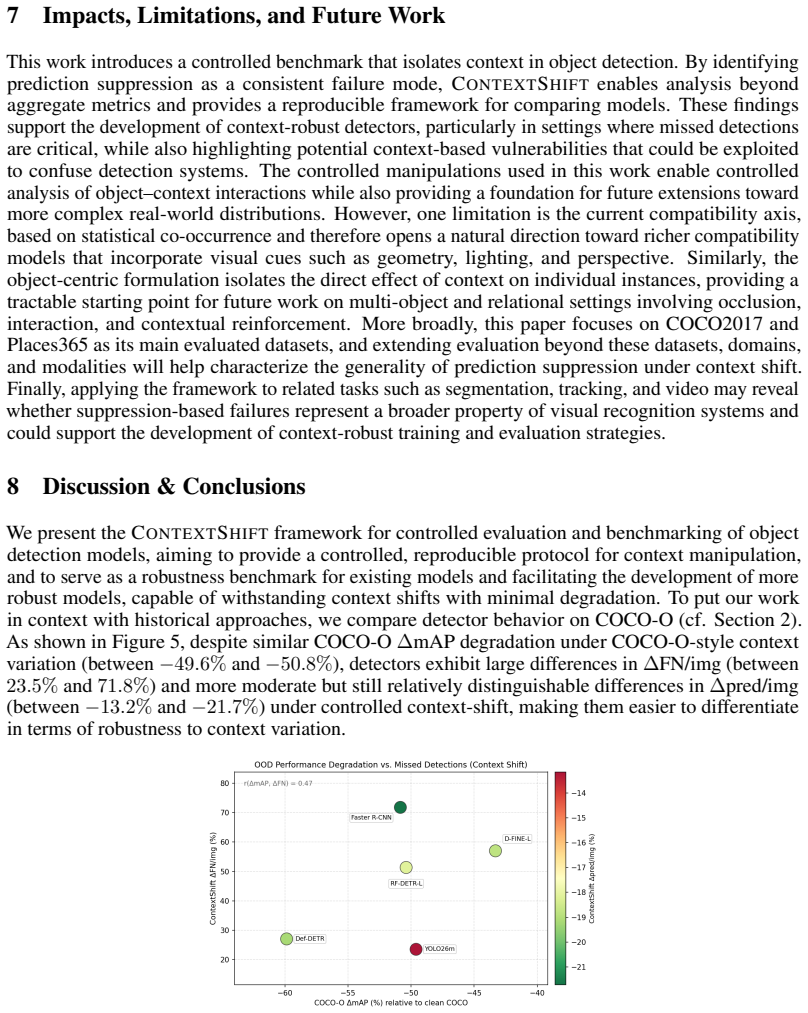
Significance. If the benchmark successfully isolates context, the work demonstrates that standard aggregate metrics like AP can mask substantial recall loss and prediction suppression under context shifts, that statistical co-occurrence (NPMI) does not linearly predict effective context, and that targeted augmentation can mitigate suppression failures. This would offer a reproducible empirical tool for studying context dependence and a concrete training intervention, strengthening robustness evaluation practices in object detection.
major comments (2)
- [Methods / Benchmark Construction] Benchmark construction (methods section): The central claim that detectors exhibit context-driven suppression (FN +227%, candidate volume -44%) requires that geometric transformations and background substitutions preserve object appearance exactly and introduce no confounding low-level artifacts. The manuscript provides no quantitative validation (e.g., mask-aligned pixel statistics, edge continuity metrics, or perceptual studies) confirming absence of illumination mismatches, boundary discontinuities, or resampling artifacts outside the object mask. This directly undermines causal attribution of the observed candidate-formation drop and non-monotonic NPMI curve to semantic context rather than synthesis artifacts.
- [Results] Results on candidate formation (results section): The claim that degradation is driven by reduced formation of valid detection candidates rather than reduced confidence is load-bearing for the interpretation that AP masks the effect. The manuscript does not report the precise operational definition of 'valid detection candidates' (e.g., IoU threshold, score threshold, or region-proposal count) nor provide per-image breakdowns or ablation on proposal generation stages, making it impossible to verify that the 44% volume reduction is not an artifact of post-processing or thresholding choices.
minor comments (2)
- [Abstract / Results] The abstract and results report 'up to 227%' and 'up to 44%' without specifying the exact detector, split, or manipulation condition achieving the maximum; add a table row or footnote linking each extreme value to its source experiment.
- [Figures] Figure captions for the NPMI plots should explicitly state the number of images per NPMI bin and whether error bars represent standard deviation across architectures or across images.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our benchmark construction and analysis. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Methods / Benchmark Construction] Benchmark construction (methods section): The central claim that detectors exhibit context-driven suppression (FN +227%, candidate volume -44%) requires that geometric transformations and background substitutions preserve object appearance exactly and introduce no confounding low-level artifacts. The manuscript provides no quantitative validation (e.g., mask-aligned pixel statistics, edge continuity metrics, or perceptual studies) confirming absence of illumination mismatches, boundary discontinuities, or resampling artifacts outside the object mask. This directly undermines causal attribution of the observed candidate-formation drop and non-monotonic NPMI curve to semantic context rather than synthesis artifacts.
Authors: We agree that explicit quantitative validation of object preservation would strengthen causal attribution to semantic context. The transformations are constructed to leave object pixels unchanged (affine transforms applied only within instance masks, followed by seamless background compositing), but the manuscript does not report supporting statistics. In revision we will add mask-aligned L2 pixel difference statistics, gradient continuity metrics at mask boundaries, and a small perceptual study on a subset of images, all placed in an expanded Methods section and supplementary material. These additions directly address the concern while preserving the existing experimental results. revision: yes
-
Referee: [Results] Results on candidate formation (results section): The claim that degradation is driven by reduced formation of valid detection candidates rather than reduced confidence is load-bearing for the interpretation that AP masks the effect. The manuscript does not report the precise operational definition of 'valid detection candidates' (e.g., IoU threshold, score threshold, or region-proposal count) nor provide per-image breakdowns or ablation on proposal generation stages, making it impossible to verify that the 44% volume reduction is not an artifact of post-processing or thresholding choices.
Authors: We acknowledge the need for a precise operational definition. Valid detection candidates are defined as initial region proposals (or equivalent early-stage outputs) that achieve IoU > 0.5 with a ground-truth object before final classification and NMS thresholding. We will insert this definition, together with the exact score threshold used for counting, into the Results section. In addition, the revised manuscript will include per-image histograms of candidate counts and a brief ablation isolating the proposal-generation stage (e.g., RPN output before ROI head) in supplementary material. These clarifications will allow readers to verify that the reported 44% reduction is not an artifact of post-processing. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper introduces ContextShift as a data manipulation benchmark on COCO and reports observed detector behaviors (FN increases, prediction volume drops, non-monotonic NPMI effects) via direct comparisons. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All central claims reduce to experimental outputs on manipulated images rather than any self-referential construction. This is the expected outcome for an empirical benchmark study with no theoretical derivation component.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption COCO 2017 images can be manipulated to change context while exactly preserving object appearance
- domain assumption Normalized pointwise mutual information computed on the dataset provides a meaningful continuous axis for context compatibility
Reference graph
Works this paper leans on
-
[1]
Detecting out-of-context objects using graph contextual reasoning network
Manoj Acharya, Anirban Roy, Kaushik Koneripalli, Susmit Jha, Christopher Kanan, and Ajay Divakaran. Detecting out-of-context objects using graph contextual reasoning network. In International Joint Conference on Artificial Intelligence, 2022
2022
-
[2]
Impact of data duplication on deep neural network-based image classifiers: Robust vs
Alireza Aghabagherloo, Aydin Abadi, Sumanta Sarkar, Vishnu Asutosh Dasu, and Bart Preneel. Impact of data duplication on deep neural network-based image classifiers: Robust vs. standard models, 2025
2025
-
[3]
End to End Learning for Self-Driving Cars
Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D Jackel, Mathew Monfort, Urs Muller, Jiawei Zhang, et al. End to end learning for self-driving cars.arXiv preprint arXiv:1604.07316, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Normalized (pointwise) mutual information in collocation extraction
Gerlof Bouma. Normalized (pointwise) mutual information in collocation extraction. In Proceedings of the Biennial GSCL Conference, pages 31–40, Tübingen, Germany, 2009
2009
-
[5]
Yolo- world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo- world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
2024
-
[6]
Modeling visual context is key to augmenting object detection datasets
Nikita Dvornik, Julien Mairal, and Cordelia Schmid. Modeling visual context is key to augmenting object detection datasets. InProceedings of the European Conference on Computer Vision (ECCV), pages 375–391, 2018
2018
-
[7]
A survey on bias in visual datasets.Computer Vision and Image Understanding, 223:103552, 2022
Simone Fabbrizzi, Symeon Papadopoulos, Eirini Ntoutsi, and Ioannis Kompatsiaris. A survey on bias in visual datasets.Computer Vision and Image Understanding, 223:103552, 2022
2022
-
[8]
Cubuk, Quoc V
Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D. Cubuk, Quoc V . Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2664–2674, 2021
2021
-
[9]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[10]
Ultralytics yolo
Glenn Jocher, Ayush Chaurasia, Jing Qiu, et al. Ultralytics yolo. https://github.com/ ultralytics/ultralytics, 2023. Accessed: 2026-04-15
2023
-
[11]
WILDS: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton Earnshaw, Imran Haque, Sara Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang. WILDS: A be...
2021
-
[12]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[13]
Aengus Lynch, Gbètondji J-S Dovonon, Jean Kaddour, and Ricardo Silva. Spawrious: A benchmark for fine control of spurious correlation biases.arXiv preprint arXiv:2303.05470, 2023
-
[14]
Coco- o: A benchmark for object detectors under natural distribution shifts
Xiaofeng Mao, Yuefeng Chen, Yao Zhu, Da Chen, Hang Su, Rong Zhang, and Hui Xue. Coco- o: A benchmark for object detectors under natural distribution shifts. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6339–6350, 2023
2023
-
[15]
Ecker, Matthias Bethge, and Wieland Brendel
Claudio Michaelis, Benjamin Mitzkus, Robert Geirhos, Evgenia Rusak, Oliver Bringmann, Alexander S. Ecker, Matthias Bethge, and Wieland Brendel. Benchmarking robustness in object detection: Autonomous driving when winter is coming. InNeurIPS Workshop on Machine Learning for Autonomous Driving, 2019. 10
2019
-
[16]
The role of context for object detection and semantic segmentation in the wild
Roozbeh Mottaghi, Xianjie Chen, Xiaobai Liu, Nam-Gyu Cho, Seong-Whan Lee, Sanja Fidler, Raquel Urtasun, and Alan Yuille. The role of context for object detection and semantic segmentation in the wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014
2014
-
[17]
Decompose-and-compose: A compositional approach to mitigating spurious correlation
Fahimeh Hosseini Noohdani, Parsa Hosseini, Aryan Yazdan Parast, Hamidreza Yaghoubi Araghi, and Mahdieh Soleymani Baghshah. Decompose-and-compose: A compositional approach to mitigating spurious correlation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[18]
arXiv preprint arXiv:2410.13842 (2024) 4, 10
Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. D-fine: Redefine regression task in detrs as fine-grained distribution refinement.arXiv preprint arXiv:2410.13842, 2024
-
[19]
Black-box explanation of object detectors via saliency maps
Vitali Petsiuk, Rajiv Jain, Bhavan Bhotika, and Kate Saenko. Black-box explanation of object detectors via saliency maps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11443–11452, 2021
2021
-
[20]
You only look once: Unified, real-time object detection
Joseph Redmon et al. You only look once: Unified, real-time object detection. InCVPR, 2016
2016
-
[21]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[22]
Rf-detr: Real-time detection transformer
Roboflow. Rf-detr: Real-time detection transformer. https://github.com/roboflow/ rf-detr, 2023. Accessed: 2026-04-15
2023
-
[23]
Role of spatial context in adversarial robustness for object detection
Aniruddha Saha, Akshayvarun Subramanya, Koninika Patil, and Hamed Pirsiavash. Role of spatial context in adversarial robustness for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 784–785, 2020
2020
-
[24]
Don’t judge an object by its context: Learning to overcome contextual bias
Krishna Kumar Singh, Dhruv Mahajan, Kristen Grauman, Yong Jae Lee, Matt Feiszli, and Deepti Ghadiyaram. Don’t judge an object by its context: Learning to overcome contextual bias. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11070–11078, 2020
2020
-
[25]
Benchmarking object detectors with COCO: A new path forward, 2024
Shweta Singh, Aayan Yadav, Jitesh Jain, Humphrey Shi, Justin Johnson, and Karan Desai. Benchmarking object detectors with COCO: A new path forward, 2024
2024
-
[26]
Hojun Son, Asma Almutairi, and Arpan Kusari. Quantifying context bias in domain adaptation for object detection.arXiv preprint arXiv:2409.14679, 2024
-
[27]
Real-world anomaly detection in surveillance videos
Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6479–6488, 2018
2018
-
[28]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2149–2159, January 2022
2022
-
[29]
Robust real-time face detection.International Journal of Computer Vision, 57(2):137–154, 2004
Paul Viola and Michael J Jones. Robust real-time face detection.International Journal of Computer Vision, 57(2):137–154, 2004
2004
-
[30]
Ke Wang, Harshitha Machiraju, Oh-Hyeon Choung, Michael Herzog, and Pascal Frossard. Clad: A contrastive learning based approach for background debiasing.arXiv preprint arXiv:2210.02748, 2022
-
[31]
Noise or signal: The role of image backgrounds in object recognition
Kai Xiao, Logan Engstrom, Andrew Ilyas, and Aleksander Madry. Noise or signal: The role of image backgrounds in object recognition. InInternational Conference on Learning Representations (ICLR), 2021. 11
2021
-
[32]
Wild-time: A benchmark of in-the-wild distribution shift over time
Huaxiu Yao, Caroline Choi, Bochuan Cao, Yoonho Lee, Pang Wei Koh, and Chelsea Finn. Wild-time: A benchmark of in-the-wild distribution shift over time. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, volume 35, pages 10309–10324, 2022
2022
-
[33]
Places: A 10 million image database for scene recognition
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. InIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2017
2017
-
[34]
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. InInternational Conference on Learning Representations (ICLR), 2021. 12 A Manipulation Framework A.1 Object-Background Compatibility Modeling A.1.1 Compatibility Metric We construct an |O| × |P| compatibility ma...
-
[35]
All data used consists of existing publicly available datasets; no new data collection involving human participants took place
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.