ViTexQA: A Multi-Frame Temporal Perception Dataset for Video Text Question Answering
Pith reviewed 2026-06-26 00:22 UTC · model grok-4.3
The pith
ViTexQA is a video-text QA dataset where every question requires fusing text across multiple frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present ViTexQA, a large-scale video-text QA dataset, and FrameThinker for robust multi-frame temporal reasoning. We build ViTexQA via a quality-controlled Chain-of-Thought annotation pipeline boosted with temporal constraints; all its QA pairs demand cross-frame text fusion to solve, enforcing true temporal reliance. FrameThinker adopts two-stage training for explicit temporal modeling: CoT-Guided Supervised Fine-Tuning generates frame-aware reasoning chains, followed by Temporally-grounded Reinforcement Learning optimized with multi-frame coherence rewards.
What carries the argument
The quality-controlled Chain-of-Thought annotation pipeline with temporal constraints that forces every QA pair to require cross-frame text fusion.
If this is right
- Video text understanding models must integrate textual cues that are distributed across time rather than present in one image.
- Two-stage training that first produces frame-aware chains and then optimizes for multi-frame coherence yields measurable gains on temporal tasks.
- Datasets that enforce cross-frame reliance expose the gap between current MLLM performance and real-world video text demands.
Where Pith is reading between the lines
- Similar temporal-constraint pipelines could be applied to other video tasks such as action recognition or event localization to reduce single-frame shortcuts.
- The performance lift from the RL stage suggests that coherence rewards may transfer to longer videos where text appears even more sparsely.
- If single-frame shortcuts remain in other datasets, retraining on ViTexQA-style data might improve generalization to uncurated video streams.
Load-bearing premise
The annotation pipeline with temporal constraints actually creates questions that cannot be answered from any single frame.
What would settle it
Human or model tests on isolated frames showing that a substantial share of ViTexQA questions can still be answered without seeing other frames.
Figures
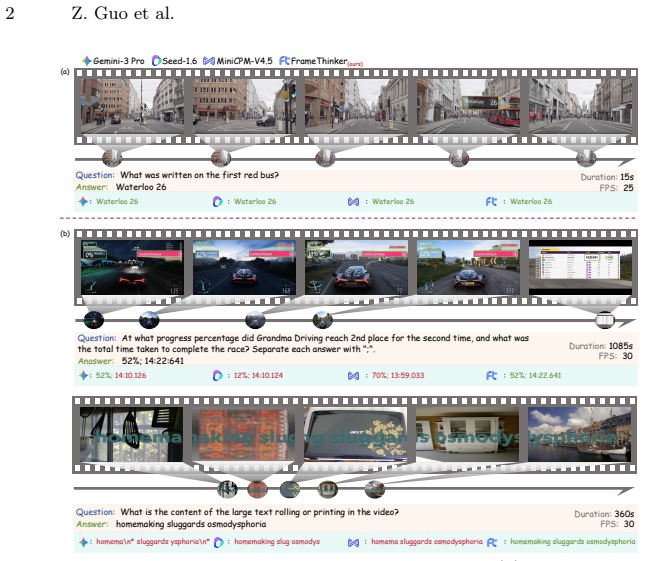
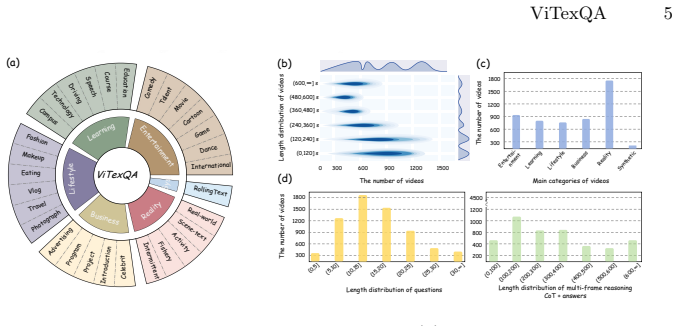
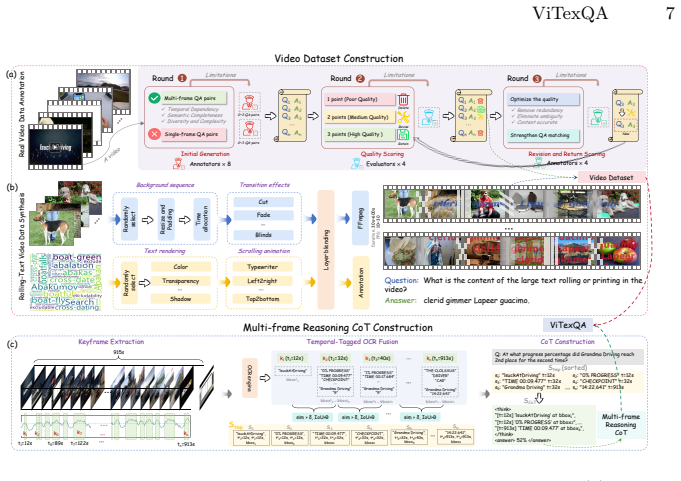
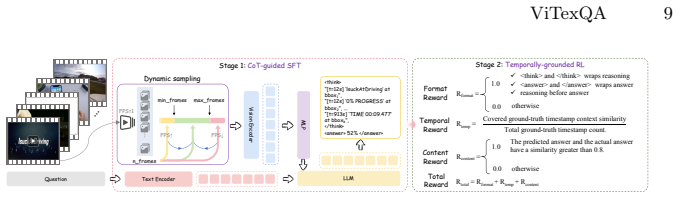






read the original abstract
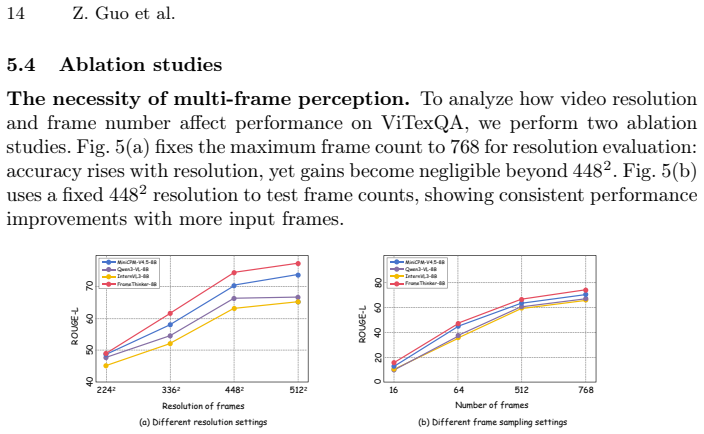
Despite remarkable progress in multimodal understanding, current MLLMs still exhibit limitations in video text understanding, particularly when semantics emerge through the integration of temporally distributed textual cues across multiple frames. This perception challenge fundamentally differs from static image text understanding, yet existing datasets fail to capture: the vast majority of questions remain answerable from single frames, inadequately reflecting real-world video text comprehension demands. To address this, we present ViTexQA, a large-scale video-text QA dataset, and FrameThinker for robust multi-frame temporal reasoning. We build ViTexQA via a quality-controlled Chain-of-Thought (CoT) annotation pipeline boosted with temporal constraints; all its QA pairs demand cross-frame text fusion to solve, enforcing true temporal reliance. FrameThinker adopts two-stage training for explicit temporal modeling: CoT-Guided Supervised Fine-Tuning (SFT) generates frame-aware reasoning chains, followed by Temporally-grounded Reinforcement Learning (RL) optimized with multi-frame coherence rewards. Evaluations show our method outperforms SOTA baselines on ViTexQA, lifting ROUGE-L by 6.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViTexQA, a large-scale video-text QA dataset constructed via a quality-controlled CoT annotation pipeline with temporal constraints, claiming that all QA pairs require cross-frame text fusion and cannot be solved from single frames. It also presents FrameThinker, a two-stage model using CoT-Guided SFT followed by Temporally-grounded RL with multi-frame coherence rewards, which outperforms SOTA baselines on ViTexQA with a 6.3% ROUGE-L improvement.
Significance. If the temporal requirement claim holds and is verified, ViTexQA would address a clear gap in existing video QA datasets by enforcing multi-frame reasoning, providing a more realistic benchmark for MLLM temporal perception. The explicit two-stage training approach with coherence rewards offers a concrete method for improving temporal modeling, which could influence future work on video understanding if the gains are reproducible.
major comments (3)
- [§3] §3 (Dataset Construction), specifically the CoT pipeline description: the central claim that 'all its QA pairs demand cross-frame text fusion to solve' is load-bearing for both dataset novelty and the reported performance gains, yet no quantitative statistics (e.g., single-frame answerability rates, failure cases of single-frame models, or audit results on temporal constraint enforcement) are provided to verify this property.
- [§4] §4 (Experiments), Table reporting baseline comparisons: the 6.3% ROUGE-L lift is presented without error bars, multiple random seeds, or detailed baseline implementation specifics (e.g., exact prompting or fine-tuning protocols for SOTA models), making it difficult to assess whether the gain is robust or attributable to the temporal modeling.
- [§3.2] §3.2 (Temporal Constraints): the exact rules for the temporal constraints in the annotation pipeline and their enforcement mechanism are described at a high level without examples of rejected single-frame questions or verification that the resulting QA pairs are indeed unsolvable from any individual frame.
minor comments (2)
- [Abstract] Abstract and §1: the phrasing 'lifting ROUGE-L by 6.3%' should specify the exact baseline model and metric variant for clarity.
- Figure 1 or dataset examples: including at least one concrete QA pair with frame annotations would help illustrate the cross-frame requirement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ViTexQA and FrameThinker. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction), specifically the CoT pipeline description: the central claim that 'all its QA pairs demand cross-frame text fusion to solve' is load-bearing for both dataset novelty and the reported performance gains, yet no quantitative statistics (e.g., single-frame answerability rates, failure cases of single-frame models, or audit results on temporal constraint enforcement) are provided to verify this property.
Authors: We agree that explicit quantitative verification would better substantiate the central claim. The CoT pipeline with temporal constraints was designed to enforce cross-frame fusion, but we did not report single-frame answerability rates or audit statistics. We will add these analyses, including single-frame model failure rates and constraint enforcement results, to the revised §3. revision: yes
-
Referee: [§4] §4 (Experiments), Table reporting baseline comparisons: the 6.3% ROUGE-L lift is presented without error bars, multiple random seeds, or detailed baseline implementation specifics (e.g., exact prompting or fine-tuning protocols for SOTA models), making it difficult to assess whether the gain is robust or attributable to the temporal modeling.
Authors: The 6.3% ROUGE-L improvement reflects our reported experimental setup. To address concerns about robustness, we will include error bars computed over multiple random seeds and expand the baseline implementation details (prompting and fine-tuning protocols) in the revised §4 and appendix. revision: yes
-
Referee: [§3.2] §3.2 (Temporal Constraints): the exact rules for the temporal constraints in the annotation pipeline and their enforcement mechanism are described at a high level without examples of rejected single-frame questions or verification that the resulting QA pairs are indeed unsolvable from any individual frame.
Authors: We will revise §3.2 to provide the precise temporal constraint rules, concrete examples of rejected single-frame questions, and the verification steps confirming that QA pairs require multi-frame fusion. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper asserts that its CoT annotation pipeline with temporal constraints produces QA pairs requiring cross-frame fusion, and reports a 6.3% ROUGE-L gain for FrameThinker on this dataset. This is a stated design outcome of the construction process rather than any derivation, equation, or prediction that reduces to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no parameters are fitted then renamed as predictions, and no ansatzes or renamings of known results appear. The two-stage training (CoT-Guided SFT followed by RL) is described independently of the dataset property. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature computa- tional science5(10), 952–961 (2025)
Alampara, N., Schilling-Wilhelmi, M., Ríos-García, M., Mandal, I., Khetarpal, P., Grover, H.S., Krishnan, N.A., Jablonka, K.M.: Probing the limitations of multi- modal language models for chemistry and materials research. Nature computa- tional science5(10), 952–961 (2025)
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the IEEE/CVF international conference on computer vision
Biten, A.F., Tito, R., Mafla, A., Gomez, L., Rusinol, M., Valveny, E., Jawahar, C., Karatzas, D.: Scene text visual question answering. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4291–4301 (2019)
2019
-
[4]
arXiv preprint arXiv:2101.09465 (2021)
Chen, X., Zhao, Z., Chen, L., Zhang, D., Ji, J., Luo, A., Xiong, Y., Yu, K.: Web- src: A dataset for web-based structural reading comprehension. arXiv preprint arXiv:2101.09465 (2021)
arXiv 2021
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[6]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., Marris, L., Petulla, S., Gaffney, C., Asaf: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities (2025),https://arxiv.org/ abs/2507.06261
Pith/arXiv arXiv 2025
-
[7]
Dao, T.: Flashattention-2: Faster attention with better parallelism and work par- titioning (2023),https://arxiv.org/abs/2307.08691
Pith/arXiv arXiv 2023
-
[8]
In: Proceedings of the Nineteenth ACM Conference on Recommender Systems
De Nadai, M., Damianou, A., Lalmas, M.: Describe what you see with multimodal large language models to enhance video recommendations. In: Proceedings of the Nineteenth ACM Conference on Recommender Systems. pp. 1159–1163 (2025)
2025
-
[9]
arXiv preprint arXiv:2009.09941 (2020)
Du, Y., Li, C., Guo, R., Yin, X., Liu, W., Zhou, J., Bai, Y., Yu, Z., Yang, Y., Dang, Q., et al.: Pp-ocr: A practical ultra lightweight ocr system. arXiv preprint arXiv:2009.09941 (2020)
arXiv 2009
-
[10]
In: Proceedings of the 31st International Conference on Computational Linguistics
Fei, Y., Gao, Y., Xian, X., Zhang, X., Wu, T., Chen, W.: Do current video llms have strong ocr abilities? a preliminary study. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 9860–9876 (2025)
2025
-
[11]
arXiv preprint arXiv:2501.00321 (2024)
Fu, L., Kuang, Z., Song, J., Huang, M., Yang, B., Li, Y., Zhu, L., Luo, Q., Wang, X., Lu, H., et al.: Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning. arXiv preprint arXiv:2501.00321 (2024)
Pith/arXiv arXiv 2024
-
[12]
Guan,T.,Lin,C.,Shen,W.,Yang,X.:Posformer:recognizingcomplexhandwritten mathematicalexpressionwithpositionforesttransformer.In:EuropeanConference on Computer Vision. pp. 130–147. Springer (2024)
2024
-
[13]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Guan, T., Shen, W., Yang, X.: Ccdplus: Towards accurate character to charac- ter distillation for text recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[14]
In: European Conference on Computer Vision
Guan, T., Shen, W., Yang, X., Wang, X., Yang, X.: Bridging synthetic and real worlds for pre-training scene text detectors. In: European Conference on Computer Vision. pp. 428–446. Springer (2024)
2024
-
[15]
Guo et al
Guan, T., Wang, Z., Fu, P., Guo, Z., Shen, W., Zhou, K., Yue, T., Duan, C., Sun, H., Jiang, Q., et al.: A token-level text image foundation model for docu- 16 Z. Guo et al. ment understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23210–23220 (2025)
2025
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guan, T., Yang, Z., Wan, J., Yang, M., Guo, Z., Hu, Z., Luo, R., Chen, R., Jiang, S., Wang, P., et al.: Codepercept: Code-grounded visual stem perception for mllms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 33542–33552 (2026)
2026
-
[17]
Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., et al.: Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062 (2025)
Pith/arXiv arXiv 2025
-
[18]
The Visual Computer42(5), 221 (2026)
Guo, Z., Ma, H.: Enhanced point cloud registration for workpieces using triangular constraint sampling consistency in complex industrial environment. The Visual Computer42(5), 221 (2026)
2026
-
[19]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Hu, A., Xu, H., Zhang, L., Ye, J., Yan, M., Zhang, J., Jin, Q., Huang, F., Zhou, J.: mplug-docowl2: High-resolution compressing for ocr-free multi-page document understanding. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 5817–5834 (2025)
2025
-
[20]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Jahagirdar, S., Mathew, M., Karatzas, D., Jawahar, C.: Watching the news: To- wards videoqa models that can read. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 4441–4450 (2023)
2023
-
[21]
In: 2013 12th international conference on document analysis and recognition
Karatzas, D., Shafait, F., Uchida, S., Iwamura, M., i Bigorda, L.G., Mestre, S.R., Mas, J., Mota, D.F., Almazan, J.A., De Las Heras, L.P.: Icdar 2013 robust read- ing competition. In: 2013 12th international conference on document analysis and recognition. pp. 1484–1493. IEEE (2013)
2013
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lee, M.J., Gong, D., Cho, M.: Video summarization with large language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18981–18991 (2025)
2025
-
[23]
arXiv preprint arXiv:2404.16790 (2024)
Li, B., Ge, Y., Chen, Y., Ge, Y., Zhang, R., Shan, Y.: Seed-bench-2-plus: Bench- marking multimodal large language models with text-rich visual comprehension. arXiv preprint arXiv:2404.16790 (2024)
arXiv 2024
-
[24]
Advances in Neural Information Processing Systems37, 5697–5738 (2024)
Li, W., Fan, H., Wong, Y., Kankanhalli, M., Yang, Y.: Topa: Extending large language models for video understanding via text-only pre-alignment. Advances in Neural Information Processing Systems37, 5697–5738 (2024)
2024
-
[25]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Z., Yang, B., Liu, Q., Ma, Z., Zhang, S., Yang, J., Sun, Y., Liu, Y., Bai, X.: Monkey: Image resolution and text label are important things for large multi- modal models. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26763–26773 (2024)
2024
-
[26]
arXiv preprint arXiv:2309.17444 (2023)
Lian, L., Shi, B., Yala, A., Darrell, T., Li, B.: Llm-grounded video diffusion models. arXiv preprint arXiv:2309.17444 (2023)
arXiv 2023
-
[27]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971– 5984 (2024)
2024
-
[28]
arXiv preprint arXiv:2412.19437 (2024)
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
Pith/arXiv arXiv 2024
-
[29]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[30]
Science China Information Sciences67(12), 220102 (2024) ViTexQA 17
Liu, Y., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.C., Liu, C.L., Jin, L., Bai, X.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences67(12), 220102 (2024) ViTexQA 17
2024
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y., Yang, S., Xi, H., Cao, S., Gu, Y., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4122– 4134 (2025)
2025
-
[32]
arXiv preprint arXiv:2203.10244 (2022)
Masry, A., Long, D.X., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244 (2022)
Pith/arXiv arXiv 2022
-
[33]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Mathew, M., Bagal, V., Tito, R., Karatzas, D., Valveny, E., Jawahar, C.: Info- graphicvqa. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1697–1706 (2022)
2022
-
[34]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Mathew, M., Karatzas, D., Jawahar, C.: Docvqa: A dataset for vqa on document images. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2200–2209 (2021)
2021
-
[35]
In: 2019 international conference on document analysis and recognition (ICDAR)
Mishra, A., Shekhar, S., Singh, A.K., Chakraborty, A.: Ocr-vqa: Visual question answering by reading text in images. In: 2019 international conference on document analysis and recognition (ICDAR). pp. 947–952. IEEE (2019)
2019
-
[36]
In: IEEE winter conference on applications of computer vision
Nguyen, P.X., Wang, K., Belongie, S.: Video text detection and recognition: Dataset and benchmark. In: IEEE winter conference on applications of computer vision. pp. 776–783. IEEE (2014)
2014
-
[37]
In: International Conference on Multimedia Modeling
Nguyen, T., Anh, V.N.M., Pham, D.D., Vinh, T.Q., Quynh, N.D.T., Tien, L.A., Le, T.D., Nguyen, B.T.: Horus: multimodal large language models framework for video retrieval at vbs 2025. In: International Conference on Multimedia Modeling. pp. 286–293. Springer (2025)
2025
-
[38]
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., and, I.B.: Gpt-4 technical report (2024),https://arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2024
-
[39]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Ozaki, S., Hayashi, K., Oba, M., Sakai, Y., Kamigaito, H., Watanabe, T.: Bqa: Body language question answering dataset for video large language models. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). pp. 110–123 (2025)
2025
-
[40]
In: Proceed- ings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Rasley, J., Rajbhandari, S., Ruwase, O., He, Y.: Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In: Proceed- ings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 3505–3506 (2020)
2020
-
[41]
Sadowski, C., Levin, G.: Simhash: Hash-based similarity detection. Tech. rep., Technical report, Google (2007)
2007
-
[42]
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., Liu, Z., Xu, H., Kim, H.J., Soran, B., Krishnamoorthi, R., Elhoseiny, M., Chandra, V.: Longvu: Spatiotemporal adaptive compression for long video-language understanding (2024),https://arxiv.org/abs/2410.17434
Pith/arXiv arXiv 2024
-
[43]
arXiv preprint arXiv:2502.05177 (2025)
Shen,Y.,Fu,C.,Dong,S.,Wang,X.,Zhang,Y.F.,Chen,P.,Zhang,M.,Cao,H.,Li, K., Lin, S., et al.: Long-vita: Scaling large multi-modal models to 1 million tokens with leading short-context accuracy. arXiv preprint arXiv:2502.05177 (2025)
arXiv 2025
-
[44]
arXiv preprint arXiv:2505.21333 (2025)
Shi, Y., Wang, H., Xie, W., Zhang, H., Zhao, L., Zhang, Y.F., Li, X., Fu, C., Wen, Z., Liu, W., et al.: Mme-videoocr: Evaluating ocr-based capabilities of multimodal llms in video scenarios. arXiv preprint arXiv:2505.21333 (2025)
arXiv 2025
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8317–8326 (2019) 18 Z. Guo et al
2019
-
[46]
arXiv preprint arXiv:2511.19529 (2025)
Team, V., Liu, C., Kuo, C.W., Huang, C., Du, D., Chen, F., Chen, G., Zhang, H., Zhao,H.,Zhang,L.,etal.:Vidi2:Largemultimodalmodelsforvideounderstanding and creation. arXiv preprint arXiv:2511.19529 (2025)
arXiv 2025
-
[47]
In: International Conference on Doc- ument Analysis and Recognition
Tom, G., Mathew, M., Garcia-Bordils, S., Karatzas, D., Jawahar, C.: Reading between the lanes: Text videoqa on the road. In: International Conference on Doc- ument Analysis and Recognition. pp. 137–154. Springer (2023)
2023
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, X., Liu, Y., Shen, C., Ng, C.C., Luo, C., Jin, L., Chan, C.S., Hengel, A.v.d., Wang, L.: On the general value of evidence, and bilingual scene-text visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10126–10135 (2020)
2020
-
[49]
In: European conference on computer vision
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Chen, G., Pei, B., Zheng, R., Wang, Z., Shi, Y., et al.: Internvideo2: Scaling foundation models for multimodal video understanding. In: European conference on computer vision. pp. 396–416. Springer (2024)
2024
-
[50]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang,Z.,Guan,T.,Fu,P.,Duan,C.,Jiang,Q.,Guo,Z.,Guo,S.,Luo,J.,Shen,W., Yang, X.: Marten: Visual question answering with mask generation for multi-modal document understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14460–14471 (2025)
2025
-
[51]
In: International Conference on Document Analysis and Recognition
Wu, W., Zhao, Y., Li, Z., Li, J., Shou, M.Z., Pal, U., Karatzas, D., Bai, X.: Icdar 2023 competition on video text reading for dense and small text. In: International Conference on Document Analysis and Recognition. pp. 405–419. Springer (2023)
2023
-
[52]
In: ACM Multimedia (2017)
Xu, D., Zhao, Z., Xiao, J., Wu, F., Zhang, H., He, X., Zhuang, Y.: Video question answering via gradually refined attention over appearance and motion. In: ACM Multimedia (2017)
2017
-
[53]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., and, C.Z.: Qwen3 technical report (2025),https://arxiv.org/abs/ 2505.09388
Pith/arXiv arXiv 2025
-
[54]
Yang, B., Wen, B., Ding, B., Liu, C., Chu, C., Song, C., Rao, C., Yi, C., Li, D., Zang, D., Yang, F., Zhou, G.: Kwai keye-vl 1.5 technical report (2025),https: //arxiv.org/abs/2509.01563
arXiv 2025
-
[55]
arXiv preprint arXiv:2505.22810 (2025)
Yang, Z., Shu, Y., Yang, Z., Zhang, Y., Li, Y., Lu, K., Zeng, G., Liu, S., Zhou, Y., Sebe, N.: Vidtext: Towards comprehensive evaluation for video text understanding. arXiv preprint arXiv:2505.22810 (2025)
arXiv 2025
-
[56]
Nature Communications16(1), 5509 (2025)
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Chen, C., Li, H., Zhao, W., et al.: Efficient gpt-4v level multimodal large language model for deployment on edge devices. Nature Communications16(1), 5509 (2025)
2025
-
[57]
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., Chen, Q., Zhou, H., Zou, Z., Zhang, H., Hu, S., Zheng, Z., Zhou, J., Cai, J., Han, X., Zeng, G., Li, D., Liu, Z., Sun, M.: Minicpm-v: A gpt-4v level mllm on your phone (2024),https://arxiv.org/abs/2408.01800
Pith/arXiv arXiv 2024
-
[58]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[59]
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., Jin, P., Zhang, W., Wang, F., Bing, L., Zhao, D.: Videollama 3: Frontier multimodal foundation models for image and video understanding (2025), https://arxiv.org/abs/2501.13106
Pith/arXiv arXiv 2025
-
[60]
02713 ViTexQA 19
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data (2025),https://arxiv.org/abs/2410. 02713 ViTexQA 19
2025
-
[61]
Advances in Neural Information Processing Systems35, 35549–35562 (2022)
Zhao, M., Li, B., Wang, J., Li, W., Zhou, W., Zhang, L., Xuyang, S., Yu, Z., Yu, X., Li, G., et al.: Towards video text visual question answering: Benchmark and baseline. Advances in Neural Information Processing Systems35, 35549–35562 (2022)
2022
-
[62]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhou, S., Xiao, J., Li, Q., Li, Y., Yang, X., Guo, D., Wang, M., Chua, T.S., Yao, A.: Egotextvqa: Towards egocentric scene-text aware video question answering. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3363–3373 (2025)
2025
-
[63]
Education_Text
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models (2025),https://arxiv.org/abs/2504. 10479 ViTexQA 1 A Overview of Appendix –Collecting Details of ViTexQA. –Details of Annotation. –Representative Exampl...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.