Evolutionary Rule Extraction from Corporate Default Prediction Models
Pith reviewed 2026-06-29 00:03 UTC · model grok-4.3
The pith
ML models outperform logistic regression for SME default prediction and evolutionary rules reveal key financial distress patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
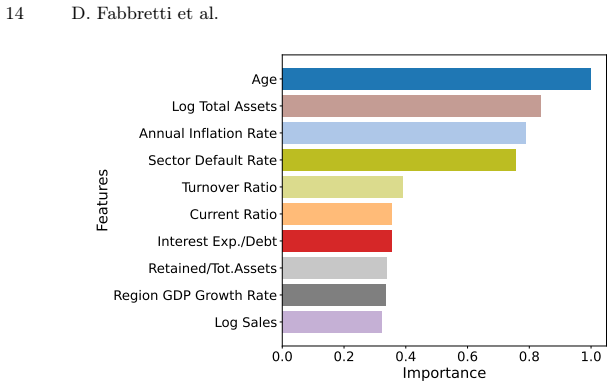
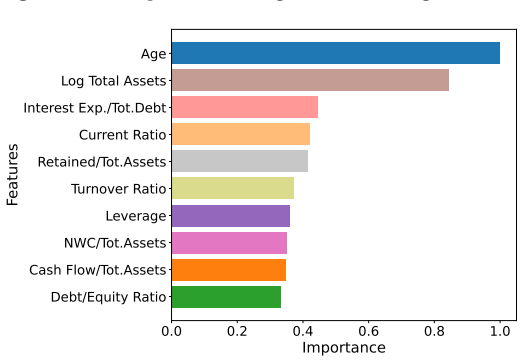
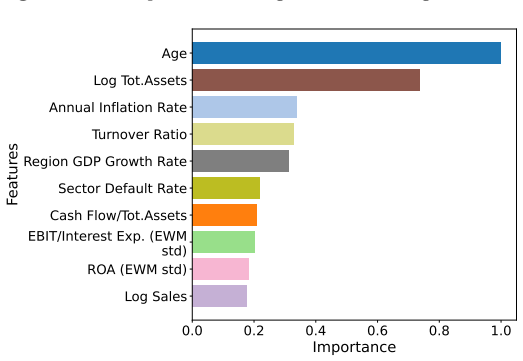
Using data from over 50,000 Italian SMEs from 2015 to 2024, ML models achieve better balanced accuracy and PR-AUC than logistic regression. The DEXiRE-EVO framework applies multi-objective optimization guided by Contextual Importance and Utility to derive rules that identify economically meaningful predictors of distress, including weak liquidity generation, internal capital erosion, high leverage, operational inefficiency, macroeconomic conditions, and persistence of instability.
What carries the argument
DEXiRE-EVO, an evolutionary rule extraction framework that integrates multi-objective optimization with the Contextual Importance and Utility (CIU) method to generate interpretable rules from ML models.
If this is right
- ML classifiers deliver higher predictive performance than the logistic regression benchmark.
- Extracted rules associate SME distress with weak liquidity, capital erosion, leverage, and inefficiency.
- Contextual macroeconomic conditions and financial instability persistence help flag high-risk firms.
- The approach supports more transparent decision-making in credit risk.
Where Pith is reading between the lines
- Such rules could be directly used by lenders to explain decisions to borrowers or regulators.
- The method might generalize to default prediction in other sectors or countries if the evolutionary search remains stable.
- Testing the rules on out-of-sample data from post-2024 periods would confirm their robustness beyond the training panel.
Load-bearing premise
The extracted rules reflect genuine economic drivers of default rather than spurious correlations specific to the Italian SME panel or the CIU-guided search process.
What would settle it
If the rules fail to identify high-risk firms in a held-out test set from a later period or different jurisdiction at rates better than chance or simple benchmarks.
Figures

read the original abstract
Small and medium-sized enterprises (SMEs) represent the majority of firms in most economies and often face financial constraints and higher vulnerability to financial distress. Predicting SME default is therefore crucial for financial institutions, policymakers, and researchers. Recent advances in machine learning (ML) have improved predictive performance in credit risk modeling. Yet, the limited interpretability of complex models raises concerns regarding transparency and regulatory compliance. This study investigates SME's default predictors and applies explainable artificial intelligence (XAI) techniques to them. Using a panel of 50,718 Italian SME over the period 2015-2024, we compare traditional econometric approaches with several ML classifiers. The empirical results show that ML models significantly outperform the traditional logistic regression benchmark in terms of Balanced Accuracy and PR-AUC. To address the interpretability challenge, we introduce DEXiRE-EVO, a novel evolutionary rule extraction framework that combines multi-objective optimization with the Contextual Importance and Utility (CIU) explainability method. The extracted rules reveal economically meaningful patterns associated with SME financial distress, highlighting the roles of weak internal liquidity generation, internal capital erosion, high leverage, and operational inefficiency. Additionally, contextual macroeconomic conditions and the persistence of financial instability contribute to identifying high-risk firms. In general, the results show that combining ML with evolutionary rule extraction can improve both predictive performance and interpretability in credit risk modeling, thus supporting more transparent, data-driven decision-making in financial environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares ML classifiers to logistic regression for SME default prediction on a 50,718-firm Italian panel (2015-2024), reporting superior Balanced Accuracy and PR-AUC for ML models. It introduces DEXiRE-EVO, a multi-objective evolutionary rule-extraction framework that integrates CIU to produce rules claimed to be economically meaningful (weak liquidity, capital erosion, high leverage, operational inefficiency, plus macro and persistence effects).
Significance. If the extracted rules can be shown to be faithful approximations of the black-box models with stability across time folds and not post-hoc artifacts, the work would strengthen the case for interpretable ML in credit-risk applications where regulatory transparency is required.
major comments (2)
- [Abstract, §4] Abstract and §4 (results): the central claim that DEXiRE-EVO rules are 'economically meaningful' rests on qualitative interpretation alone; no fidelity metric (e.g., agreement with black-box predictions on held-out data), no stability across temporal folds or subsamples, and no comparison to simpler rule baselines are reported, leaving open the possibility that the liquidity/leverage patterns are search artifacts or panel-specific correlations.
- [§3.2] §3.2 (DEXiRE-EVO description): the multi-objective evolutionary search is presented without quantitative details on how CIU is embedded in the fitness function or how rule complexity is penalized; without these, it is impossible to assess whether the reported rules are the result of genuine optimization or post-selection interpretation.
minor comments (1)
- [Table 1] Table 1 (dataset description): the panel construction (firm-year observations, handling of missing values, default definition) is only sketched; explicit counts of defaults per year and any macroeconomic covariate sources would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional quantitative validation can strengthen the interpretability claims. We address each major comment below and will incorporate the suggested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results): the central claim that DEXiRE-EVO rules are 'economically meaningful' rests on qualitative interpretation alone; no fidelity metric (e.g., agreement with black-box predictions on held-out data), no stability across temporal folds or subsamples, and no comparison to simpler rule baselines are reported, leaving open the possibility that the liquidity/leverage patterns are search artifacts or panel-specific correlations.
Authors: We agree that the current manuscript relies primarily on qualitative economic interpretation of the extracted rules. To address this, the revised version will report fidelity metrics (e.g., rule-model agreement on held-out data), stability of rules across temporal cross-validation folds, and comparisons against simpler baselines such as standard decision-tree rule extraction and single-objective genetic algorithms. These additions will provide quantitative support that the reported patterns reflect genuine model behavior rather than artifacts. revision: yes
-
Referee: [§3.2] §3.2 (DEXiRE-EVO description): the multi-objective evolutionary search is presented without quantitative details on how CIU is embedded in the fitness function or how rule complexity is penalized; without these, it is impossible to assess whether the reported rules are the result of genuine optimization or post-selection interpretation.
Authors: We acknowledge that the current description of DEXiRE-EVO lacks explicit quantitative specifications. The revised manuscript will include the precise formulation of the multi-objective fitness function, detailing how CIU importance and utility scores are incorporated (including any weighting scheme), the exact penalty term applied to rule complexity (e.g., number of antecedents or total length), and the Pareto-front selection criteria. This will allow readers to evaluate the optimization process directly. revision: yes
Circularity Check
No circularity; derivation chain is self-contained against external benchmarks
full rationale
The abstract and summary present a comparison of ML classifiers against a logistic regression benchmark on an external 50k-firm panel, followed by introduction of DEXiRE-EVO (multi-objective evolutionary search + CIU) whose outputs are interpreted post-hoc. No equations, parameter-fitting steps, or self-citation chains are shown that would reduce any claimed prediction or rule to its own inputs by construction. The outperformance metrics and rule patterns are reported as empirical results rather than tautologies, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Journal of Finance23(4), 589–609 (1968)
Altman,E.I.:Financialratios,discriminantanalysisandthepredictionofcorporate bankruptcy. The Journal of Finance23(4), 589–609 (1968)
1968
-
[2]
In: Proceed- ings (2020)
Anjomshoae, S., Kampik, T., Främling, K.: Py-ciu: A python library for explaining machine learning predictions using contextual importance and utility. In: Proceed- ings (2020)
2020
-
[3]
In: The 40th Conference on Uncertainty in Artificial Intelligence (2024)
Balcan, M.F., Sharma, D.: Learning accurate and interpretable decision trees. In: The 40th Conference on Uncertainty in Artificial Intelligence (2024)
2024
-
[4]
Risk Management26(2024)
Bazzana, F., Bee, M., Khatir, A.A.H.A.: Machine learning techniques for default prediction: An application to small italian companies. Risk Management26(2024)
2024
-
[5]
Journal of Machine Learning Research13, 281–305 (2012)
Bergstra, J., Bengio, Y.: Random search for hyper-parameter optimization. Journal of Machine Learning Research13, 281–305 (2012)
2012
-
[6]
Socio- Economic Planning Sciences90, 101746 (2023)
Bitetto, A., Cerchiello, P., Filomeni, S., Tanda, A., Tarantino, B.: Machine learning and credit risk: Empirical evidence from small- and mid-sized businesses. Socio- Economic Planning Sciences90, 101746 (2023)
2023
-
[7]
Bitetto, A., Cerchiello, P., Filomeni, S., Tanda, A., Tarantino, B.: Can we trust ma- chine learning to predict the credit risk of small businesses? Review of Quantitative Finance and Accounting63(3), 925–954 (2024)
2024
-
[8]
Machine Learning45(1), 5–32 (2001)
Breiman, L.: Random forests. Machine Learning45(1), 5–32 (2001)
2001
-
[9]
Journal of Small Business Management (2018)
Brighi, P., Lucarelli, C., Venturelli, V.: Predictive strength of lending technologies in funding smes. Journal of Small Business Management (2018)
2018
-
[10]
Annals of Operations Research354, 247–271 (2025) 18 D
Chang, V., Xu, Q.A., Akinloye, S.H., Benson, V., Hall, K.: Prediction of bank credit worthiness through credit risk analysis: An explainable machine learning study. Annals of Operations Research354, 247–271 (2025) 18 D. Fabbretti et al
2025
-
[11]
In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 785–794 (2016)
2016
-
[12]
Journal of Small Business Management62(6), 2847–2905 (2024)
Cheraghali, H., Molnár, P.: Sme default prediction: A systematic methodology- focused review. Journal of Small Business Management62(6), 2847–2905 (2024)
2024
-
[13]
Scientometrics126, 2141–2188 (2021)
Ciampi, F., Giannozzi, A., Marzi, G., Altman, E.I.: Rethinking sme default predic- tion: A systematic literature review and future perspectives. Scientometrics126, 2141–2188 (2021)
2021
-
[14]
Electronics11(24) (2022).https://doi.org/10 .3390/electronics11244171,https://www.mdpi.com/2079-9292/11/24/4171
Contreras, V., Marini, N., Fanda, L., Manzo, G., Mualla, Y., Calbimonte, J.P., Schumacher, M., Calvaresi, D.: A dexire for extracting propositional rules from neural networks via binarization. Electronics11(24) (2022).https://doi.org/10 .3390/electronics11244171,https://www.mdpi.com/2079-9292/11/24/4171
2022
-
[15]
Applied Stochastic Models in Business and Industry39(6), 829–846 (2023)
Crosato, L., Liberati, C., Repetto, M.: Lost in a black-box? interpretable machine learning for assessing italian smes default. Applied Stochastic Models in Business and Industry39(6), 829–846 (2023)
2023
-
[16]
Towards A Rigorous Science of Interpretable Machine Learning
Doshi-Velez,F.,Kim,B.:Towardsarigorousscienceofinterpretablemachinelearn- ing. arXiv preprint arXiv:1702.08608 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Official Journal of the European Union, L 124, 20 May 2003, pp
European Commission: Commission recommendation 2003/361/ec of 6 may 2003 concerning the definition of micro, small and medium-sized enterprises. Official Journal of the European Union, L 124, 20 May 2003, pp. 36–41 (2003)
2003
-
[18]
European Commission: Ethics guidelines for trustworthy ai (April 2019)
2019
-
[19]
Journal of Computer and System Sciences55(1), 119–139 (1997)
Freund, Y., Schapire, R.E.: A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences55(1), 119–139 (1997)
1997
-
[20]
Annals of Statistics29(5), 1189–1232 (2001)
Friedman, J.H.: Greedy function approximation: A gradient boosting machine. Annals of Statistics29(5), 1189–1232 (2001)
2001
-
[21]
Heliyon10, e27096 (2024)
Gu, Z., Lv, J., Wu, B., Hu, Z., Yu, X.: Credit risk assessment of small and micro enterprise based on machine learning. Heliyon10, e27096 (2024)
2024
-
[22]
ACM Queue16(3), 30–57 (2018)
Lipton, Z.C.: The mythos of model interpretability. ACM Queue16(3), 30–57 (2018)
2018
-
[23]
Advances in neural information processing systems30(2017)
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. Advances in neural information processing systems30(2017)
2017
-
[24]
European jour- nal of operational research183(3), 1466–1476 (2007)
Martens, D., Baesens, B., Van Gestel, T., Vanthienen, J.: Comprehensible credit scoring models using rule extraction from support vector machines. European jour- nal of operational research183(3), 1466–1476 (2007)
2007
-
[25]
Digital Signal Processing73, 1–15 (2018)
Montavon, G., Samek, W., Müller, K.R.: Methods for interpreting and understand- ing deep neural networks. Digital Signal Processing73, 1–15 (2018)
2018
-
[26]
Expert Systems with Applications161, 113567 (2020)
Moscatelli, M., Parlapiano, F., Narizzano, S., Viggiano, G.: Corporate default fore- casting with machine learning. Expert Systems with Applications161, 113567 (2020)
2020
-
[27]
nguyen et al
Nguyen, H.H., Viviani, J.L., Ben Jabeur, S.: Bankruptcy prediction using machine learning and shapley additive explanations: H.-h. nguyen et al. Review of Quanti- tative Finance and Accounting65(1), 107–148 (2025)
2025
-
[28]
Jour- nal of Accounting Research18(1), 109–131 (1980)
Ohlson, J.A.: Financial ratios and the probabilistic prediction of bankruptcy. Jour- nal of Accounting Research18(1), 109–131 (1980)
1980
-
[29]
why should i trust you?
Ribeiro, M.T., Singh, S., Guestrin, C.: " why should i trust you?" explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD interna- tional conference on knowledge discovery and data mining. pp. 1135–1144 (2016)
2016
-
[30]
Psychological Review65(6), 386–408 (1958) Evolutionary Rule Extraction from Corporate Default Prediction Models 19
Rosenblatt, F.: The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review65(6), 386–408 (1958) Evolutionary Rule Extraction from Corporate Default Prediction Models 19
1958
-
[31]
Nature323, 533–536 (1986)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back- propagating errors. Nature323, 533–536 (1986)
1986
- [32]
-
[33]
Research in International Business and Finance70, 102397 (2024)
Zedda, S.: Credit scoring: Does xgboost outperform logistic regression? a test on italian smes. Research in International Business and Finance70, 102397 (2024)
2024
-
[34]
International Review of Financial Analysis89, 102755 (2023)
Zhou, Y., Shen, L., Ballester, L.: A two-stage credit scoring model based on ran- dom forest: Evidence from chinese small firms. International Review of Financial Analysis89, 102755 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.