SAGE: Stochastic Prompt Optimization via Agent-Guided Exploration
Pith reviewed 2026-06-26 20:50 UTC · model grok-4.3
The pith
Coupling qualitative diagnosis with quantitative validation via multi-agent stochastic search makes prompt optimization effective for open-ended dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAGE performs stochastic prompt optimization through a multi-agent pipeline that executes diagnostic code; this couples error diagnosis with quantitative A/B validation, enabling the system to compound individually noisy test cycles into statistically robust retention gains when applied continuously to an open-ended mental-health dialogue task.
What carries the argument
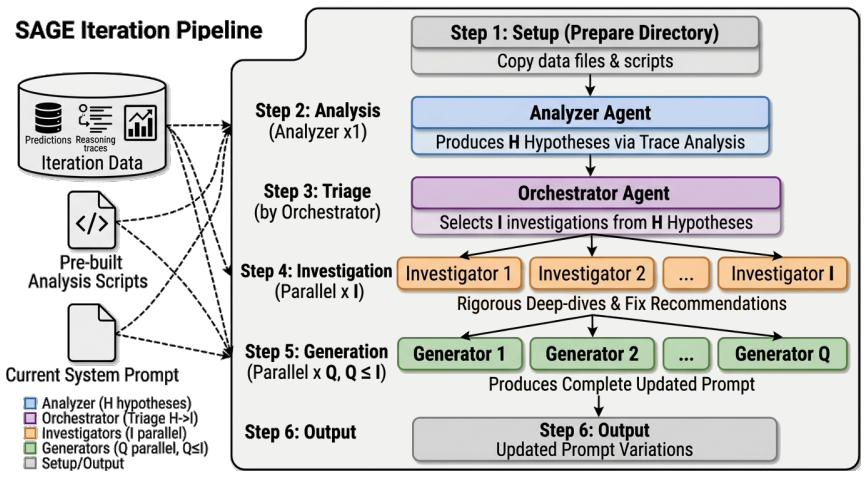
SAGE multi-agent pipeline with diagnostic code execution, which conducts agent-guided exploration over prompt space while generating and testing qualitative diagnoses.
If this is right
- Effectiveness of any prompt-search strategy depends on the interaction between the task landscape structure and the dominant error types.
- Running optimization as a continuous sequence of A/B tests allows noisy individual results to compound into reliable performance lifts.
- Agentic methods that generate and act on qualitative diagnoses outperform purely quantitative search on open-ended dialogue tasks.
- Black-box stochastic search can improve deployed dialogue systems without any parameter updates.
Where Pith is reading between the lines
- The same diagnosis-plus-validation loop could be applied to prompt optimization in other open-ended domains such as customer support or tutoring.
- Production systems might adopt automated cycles of prompt search and live A/B testing to reduce reliance on manual engineering.
- Future deployments could test whether the approach remains effective when the underlying model or user population changes.
- The method points toward hybrid human-AI loops where agents surface interpretable reasons for prompt changes that humans can review.
Load-bearing premise
The A/B-test retention gains observed in the mental-health chatbot deployment are produced by the prompt changes rather than by external time trends or selective choice of which cycles to report.
What would settle it
A controlled replication of the deployment in which next-day retention shows no net improvement once external calendar effects are removed and all cycles are included without post-hoc selection.
Figures

read the original abstract
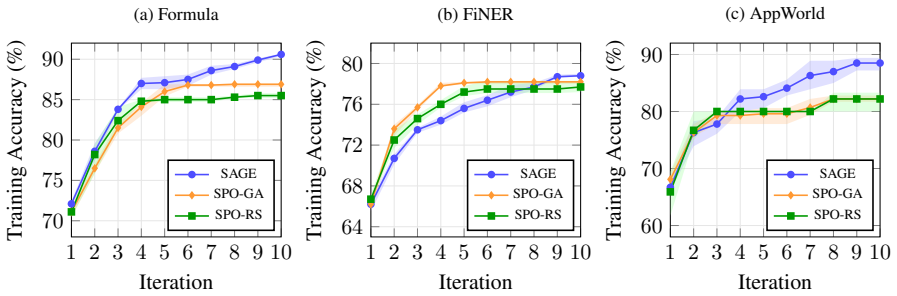
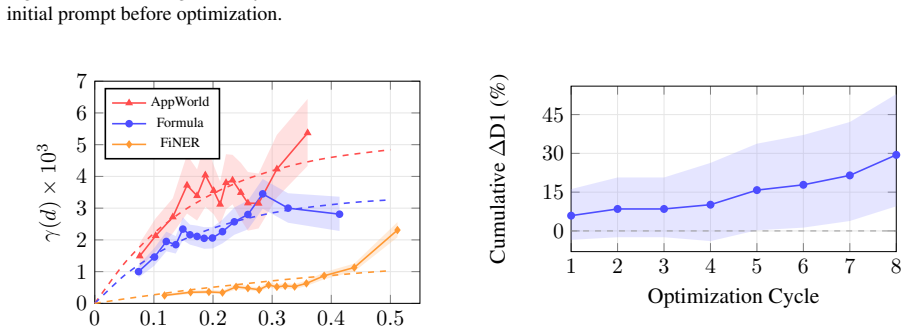
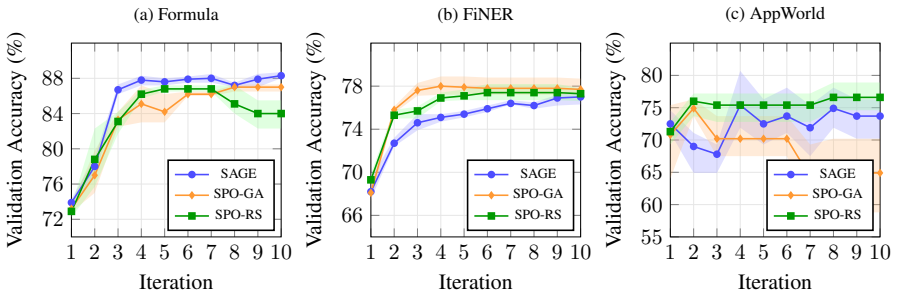
Context engineering has emerged as a primary lever for improving AI systems without parameter updates. Recent work showing that textual gradients do not function as real gradients motivates treating automatic prompt optimization (APO) as black-box search. We introduce SPO (Stochastic Prompt Optimization), a framework for stochastic search over prompt space, and compare three strategies of increasing sophistication: error-informed random search, a genetic algorithm with evolutionary operators, and SAGE (SPO via Agent-Guided Exploration), a multi-agent pipeline with diagnostic code execution. Across three benchmarks, no single strategy dominates; effectiveness depends on the interaction of landscape structure with error type. We further deploy SAGE on a mental-health chatbot under a continuous optimization paradigm, where it compounds eight cycles of individually-noisy A/B tests into a statistically robust gain in next-day retention. We argue that coupling qualitative diagnosis with quantitative validation is what makes agentic optimization effective for open-ended task-oriented dialogue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Stochastic Prompt Optimization (SPO) as a black-box search framework for automatic prompt optimization (APO), motivated by limitations of textual gradients. It compares three strategies of increasing complexity—error-informed random search, a genetic algorithm with evolutionary operators, and SAGE (a multi-agent pipeline incorporating diagnostic code execution)—across three benchmarks. No single strategy dominates; performance depends on interactions between landscape structure and error type. The paper further deploys SAGE in a continuous-optimization setting on a mental-health chatbot, where eight cycles of noisy A/B tests compound into a reported statistically robust gain in next-day retention, arguing that coupling qualitative diagnosis with quantitative validation is key to effective agentic optimization for open-ended task-oriented dialogue.
Significance. If the benchmark interactions and deployment results hold under rigorous statistical controls, the work would usefully demonstrate that agent-guided exploration can compound noisy signals in open-ended dialogue settings where simpler search methods fall short. The explicit finding that effectiveness is landscape- and error-dependent is a strength, as is the shift from single-shot optimization to continuous deployment.
major comments (2)
- [Deployment section] Deployment section: the claim that eight A/B cycles compound into a 'statistically robust' next-day retention gain is load-bearing for the central argument that qualitative diagnosis (rather than repeated A/B testing alone) drives the result. The manuscript provides no per-cycle sample sizes, exact hypothesis test, multiple-comparison correction, pre-specification of cycles, or controls for external retention drivers; without these, the observed gain cannot be isolated from post-hoc selection or unmodeled confounders.
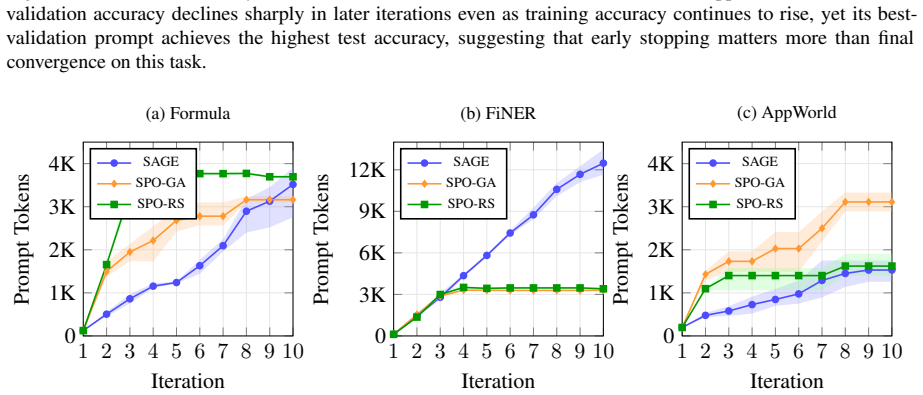
- [Benchmark experiments] Benchmark results (across the three tasks): the statement that 'no single strategy dominates' and that effectiveness depends on landscape/error-type interactions is presented as a key empirical takeaway, yet the manuscript does not report quantitative measures of landscape structure (e.g., modality, noise level, or basin geometry) that would allow readers to reproduce or generalize the interaction claim.
minor comments (2)
- [Method] Notation for the three SPO variants is introduced in the abstract but not consistently carried through the method section; a single table mapping names to algorithmic components would improve clarity.
- [Introduction] The abstract states that 'textual gradients do not function as real gradients' but cites no specific prior result or section where this is demonstrated or referenced.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Deployment section] Deployment section: the claim that eight A/B cycles compound into a 'statistically robust' next-day retention gain is load-bearing for the central argument that qualitative diagnosis (rather than repeated A/B testing alone) drives the result. The manuscript provides no per-cycle sample sizes, exact hypothesis test, multiple-comparison correction, pre-specification of cycles, or controls for external retention drivers; without these, the observed gain cannot be isolated from post-hoc selection or unmodeled confounders.
Authors: We agree that the deployment section requires additional statistical detail to support the claim. In the revised manuscript we will report per-cycle sample sizes, the exact hypothesis test and any multiple-comparison corrections applied, confirmation that the eight cycles were pre-specified, and a discussion of potential external retention drivers. These additions will clarify how the compounding effect is isolated from the agent-guided process. revision: yes
-
Referee: [Benchmark experiments] Benchmark results (across the three tasks): the statement that 'no single strategy dominates' and that effectiveness depends on landscape/error-type interactions is presented as a key empirical takeaway, yet the manuscript does not report quantitative measures of landscape structure (e.g., modality, noise level, or basin geometry) that would allow readers to reproduce or generalize the interaction claim.
Authors: The claim that no single strategy dominates is grounded in the empirical performance patterns observed across the three benchmarks, where relative effectiveness varied systematically with task and error characteristics. We maintain that these results suffice to demonstrate the interaction without explicit quantitative landscape descriptors; adding such metrics would require new experiments outside the current scope. We therefore do not intend to revise this section. revision: no
Circularity Check
No derivations or fitted quantities; empirical results are independent of method definition
full rationale
The paper introduces SPO/SAGE as black-box search strategies and reports benchmark comparisons plus an A/B deployment outcome. No equations, parameters, or predictions appear that reduce to inputs by construction. The central argument rests on observed retention gains from external A/B tests rather than any self-referential fit or self-citation chain. The work is therefore self-contained against its stated empirical benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Informa- tion Processing Systems (NeurIPS)
Practical Bayesian optimization of machine learning algorithms. InAdvances in Neural Informa- tion Processing Systems (NeurIPS). James C. Spall. 2003.Introduction to Stochastic Search and Optimization: Estimation, Simulation, and Con- trol. Wiley. Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. 2026. Dynamic cheat- sheet: Te...
Pith/arXiv arXiv 2003
-
[2]
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). Xingchen Wan, Ruoxi Sun, Hootan Nakhost, and Ser- can O. Arik. 2024. Teach better or show smarter? on instructions and exemplars in automatic promp...
Pith/arXiv arXiv 2024
-
[3]
Large language models as optimizers. InIn- ternational Conference on Learning Representations (ICLR). 8 Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR). Haoran Ye, Xuning He, Vincent Ar...
arXiv 2023
-
[4]
Agentic context engineering: Evolving con- texts for self-improving language models.Preprint, arXiv:2510.04618. ICLR 2026. Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. Large language models are human-level prompt engineers. InInternational Conference on Learning Representations (ICLR). Ziyi ...
Pith/arXiv arXiv 2026
-
[5]
Automated overview: Run analysis scripts with --prompt all for structured error breakdowns across all prompts
-
[6]
Which prompts have this error ? What instruction in the better prompt prevented it?
Cross-prompt comparison: For each error category, check how each prompt performs. Which prompts have this error ? What instruction in the better prompt prevented it?
-
[7]
Count exact occurrences
Deep-dive: Examine 5-10 specific error cases, focusing on the model's reasoning trace. Count exact occurrences
-
[8]
Hypothesis formation: Each hypothesis must be distinct and include: observation (with sample indices and counts), cross-prompt comparison, mechanism, predicted fix, suggested parent prompt, and estimated impact. ## Output A numbered list of exactly { num_max_hypotheses} hypotheses ordered by estimated impact, each with: observation, cross-prompt note, hyp...
-
[9]
Quantify precisely: Count exactly how many error cases match this pattern using scripts or targeted one- liners
-
[10]
Quote the exact reasoning showing where the model went wrong
Examine reasoning traces: Read 5-10 specific error cases. Quote the exact reasoning showing where the model went wrong
-
[11]
Check correct cases: Do correctly- answered samples of the same type avoid this pattern?
-
[12]
If so, what instruction helped?
Compare across prompts: Check if other prompts handle this error better. If so, what instruction helped?
-
[13]
if X then Y
Assess the fix: Would the proposed change actually help? Are there edge cases where it might hurt? ## Output Verdict (Supported/Partially supported/ Not supported), evidence with concrete examples, cross-prompt comparison, exact prevalence count, confidence level, implementation-ready recommended fix, and suggested parent prompt. 11 Generator.Produces a c...
-
[14]
Deploy the current best prompt to real users and collect production conversations
-
[15]
Run SAGE on the collected conversations to identify failure patterns and generate Q im- proved prompt candidates
-
[16]
A/B test all candidates alongside the current best prompt simultaneously, running for ∼48 hours to capture full D1 retention results
-
[17]
why do I keep doing this?
Promote the best-performing prompt as the new main; repeat. A/B test analysis.Within a cycle, every arm a is assigned a disjoint, randomly-sampled slice of incoming users, and we record its mean D1 reten- tion µa (a rate in [0,1] ) together with the standard error σa of that mean over its na enrolled users. We report each test arm relative to the incumben...
1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.