Efficient Regularized Piecewise-Linear Regression Trees
Pith reviewed 2026-05-25 12:30 UTC · model grok-4.3
The pith
Regularized piecewise-linear regression trees with linear models at the leaves have new high-probability generalization bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The class of regression decision tree algorithms which employ a regularized piecewise-linear node-splitting criterion and have regularized linear models at the leaves admits new high-probability upper bounds for the generalization error based on the Rademacher complexity framework, including LASSO-type and ℓ2 regularization for the leaf models; the same class is shown to be numerically stable and tractable via a concrete algorithmic implementation and modern GPU technology.
What carries the argument
Rademacher complexity bounds applied to the class of regularized piecewise-linear regression trees that place regularized linear models at the leaves.
If this is right
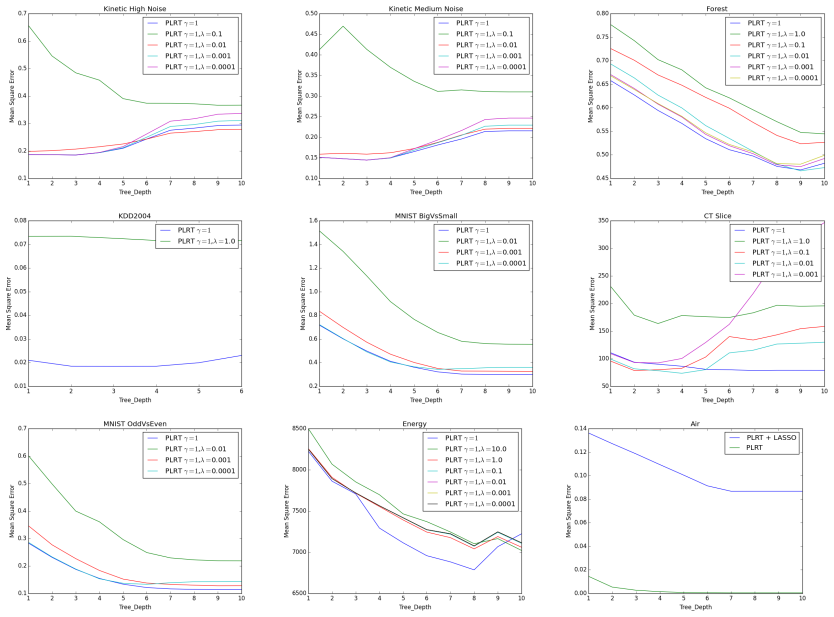
- High-probability generalization bounds hold for both LASSO-type and ℓ2 regularization of the leaf linear models.
- The same bounds extend when a general variable selection procedure is added to the tree construction.
- The proposed algorithmic implementation together with GPU acceleration renders the trees numerically stable and computationally practical.
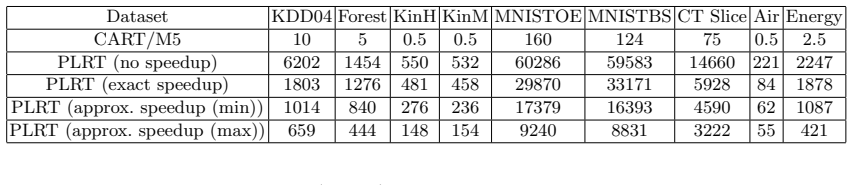
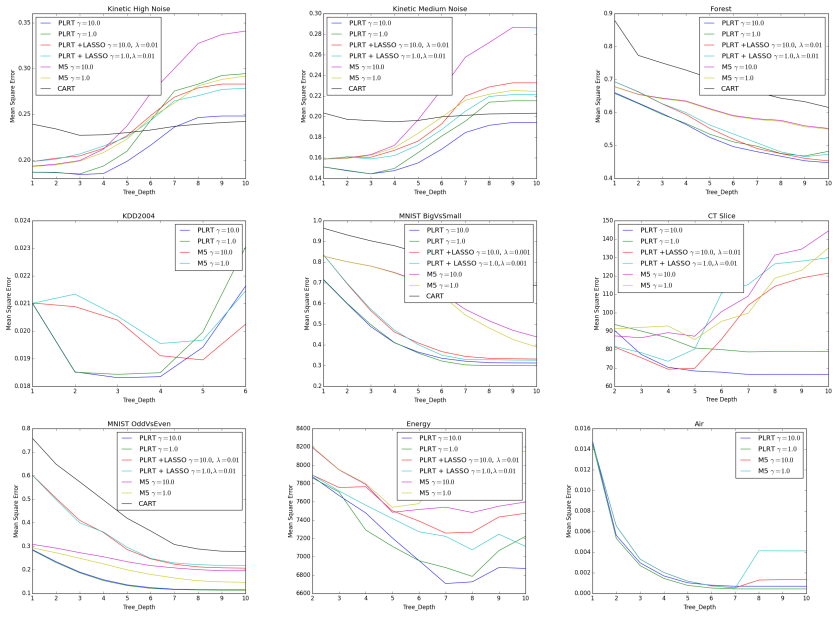
- Empirical performance on real datasets can be directly compared against piecewise-constant regression trees.
Where Pith is reading between the lines
- The bounds offer a theoretical basis for choosing between different leaf regularizers when data exhibit local linear structure.
- The GPU-oriented implementation suggests the method scales to data volumes where standard tree growing becomes prohibitive.
- Variable selection inside the same framework may allow automatic feature pruning while preserving the generalization guarantee.
Load-bearing premise
The Rademacher complexity framework applies directly to yield valid high-probability generalization bounds for the specific class of regularized piecewise-linear regression trees with linear models at the leaves.
What would settle it
A concrete dataset, regularization strength, and sample size for which the observed test error exceeds the derived upper bound with frequency higher than the probability guarantee permits.
Figures
read the original abstract
We present a detailed analysis of the class of regression decision tree algorithms which employ a regulized piecewise-linear node-splitting criterion and have regularized linear models at the leaves. From a theoretic standpoint, based on Rademacher complexity framework, we present new high-probability upper bounds for the generalization error for the proposed classes of regularized regression decision tree algorithms, including LASSO-type, and $\ell_{2}$ regularization for linear models at the leaves. Theoretical result are further extended by considering a general type of variable selection procedure. Furthermore, in our work we demonstrate that the class of piecewise-linear regression trees is not only numerically stable but can be made tractable via an algorithmic implementation, presented herein, as well as with the help of modern GPU technology. Empirically, we present results on multiple datasets which highlight the strengths and potential pitfalls, of the proposed tree algorithms compared to baselines which grow trees based on piecewise constant models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a class of regression decision trees that use regularized piecewise-linear splitting criteria and regularized linear models (LASSO-type or ℓ₂) at the leaves. It derives new high-probability generalization bounds via the Rademacher complexity framework for these classes, extends the analysis to a general variable-selection procedure, describes a GPU-accelerated algorithmic implementation for tractability, and reports empirical comparisons against piecewise-constant tree baselines on multiple datasets.
Significance. If the generalization bounds are shown to be valid, the work would provide a useful theoretical characterization of regularized regression trees with linear leaves, complementing existing results on piecewise-constant trees. The algorithmic implementation and GPU scaling constitute a practical contribution, and the empirical section illustrates both strengths and limitations relative to standard baselines.
major comments (2)
- [theoretical analysis section] Theoretical analysis section: The high-probability bounds are obtained by applying the standard Rademacher complexity framework to the final hypothesis class of regularized piecewise-linear trees. Because the tree topology, partition, and variable selection are produced by a data-dependent regularized splitting rule, the derivation must include an explicit term (union bound, covering number over admissible trees, or structural-risk penalty) to account for this dependence; the provided description gives no indication that such a term is present.
- [theoretical analysis section] Theoretical analysis section, extension to general variable selection: The extension of the bounds to an arbitrary variable-selection procedure inherits the same issue; without a concrete argument showing that the selection mechanism can be absorbed into the fixed function class for Rademacher purposes, the claimed high-probability guarantee does not follow from the standard framework.
minor comments (2)
- [abstract] Abstract: the phrase 'theoretic standpoint' should read 'theoretical standpoint'.
- [empirical results] Empirical section: no information is supplied on the number of random seeds, error-bar computation, or data-exclusion rules used when reporting performance; this makes it difficult to assess the stability of the reported comparisons.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting an important subtlety in the theoretical analysis. We address the two major comments below.
read point-by-point responses
-
Referee: [theoretical analysis section] Theoretical analysis section: The high-probability bounds are obtained by applying the standard Rademacher complexity framework to the final hypothesis class of regularized piecewise-linear trees. Because the tree topology, partition, and variable selection are produced by a data-dependent regularized splitting rule, the derivation must include an explicit term (union bound, covering number over admissible trees, or structural-risk penalty) to account for this dependence; the provided description gives no indication that such a term is present.
Authors: We agree that the data-dependent selection of tree topology and partitions via the regularized splitting rule requires an explicit accounting that is not currently shown. Our derivation treated the hypothesis class as the collection of all admissible regularized piecewise-linear trees and bounded its Rademacher complexity directly, but this does not automatically control the complexity of the selection process itself. We will revise the theoretical analysis section to incorporate either a union bound over admissible tree structures or an additional structural-risk term that accounts for the dependence introduced by the splitting criterion. revision: yes
-
Referee: [theoretical analysis section] Theoretical analysis section, extension to general variable selection: The extension of the bounds to an arbitrary variable-selection procedure inherits the same issue; without a concrete argument showing that the selection mechanism can be absorbed into the fixed function class for Rademacher purposes, the claimed high-probability guarantee does not follow from the standard framework.
Authors: The same limitation applies to the extension. The current argument does not supply a concrete reduction showing that an arbitrary variable-selection procedure can be absorbed into a fixed function class without an additional complexity term. In the revised manuscript we will add an explicit argument (for example, by bounding the number of admissible selections or by treating the selection as part of a larger hypothesis class whose Rademacher complexity is controlled) so that the high-probability guarantee follows from the standard framework. revision: yes
Circularity Check
No circularity; bounds derived from external Rademacher framework on the stated hypothesis class.
full rationale
The paper's central claim is new high-probability generalization bounds obtained by applying the Rademacher complexity framework to the class of regularized piecewise-linear regression trees. The abstract explicitly frames the result as an application of this external framework rather than any reduction to fitted quantities, self-defined parameters, or prior self-citations. No equations or steps in the provided text exhibit self-definitional, fitted-input, or self-citation load-bearing patterns. The derivation is therefore self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rademacher complexity framework yields valid high-probability generalization bounds for regularized piecewise-linear regression trees with linear leaves
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
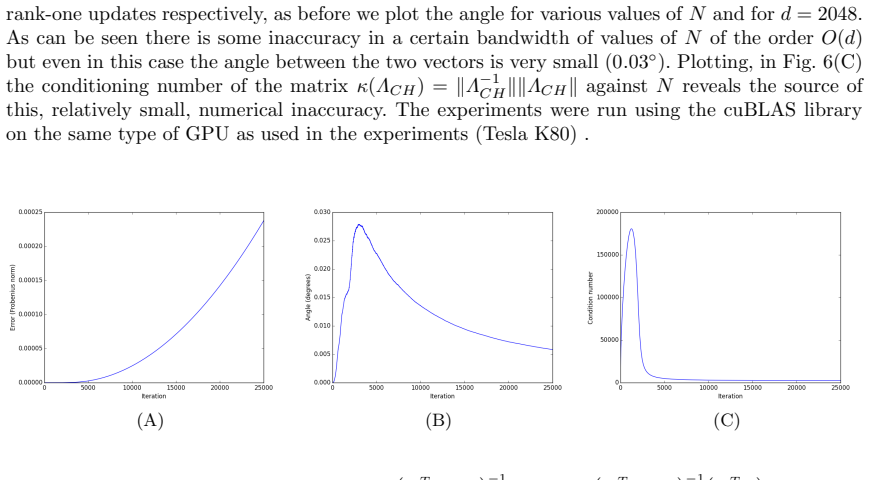
high-probability upper bounds … based on Rademacher complexity framework … LASSO-type and ℓ2 regularization … variable selection procedure
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
class F … union over Tℓ … Catalan number … log(enD) term
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bartlett, P., Bousquet, O., Mendelson, S.: Local rademacher complexities. Annals of Statistics pp. 1497–1537 (2005)
work page 2005
-
[2]
Journal of Machine Learning Research pp
Bartlett, P., Mendelson, S.: Rademacher and gaussian complexities: Risk bounds and results. Journal of Machine Learning Research pp. 463–482 (2002)
work page 2002
-
[3]
Computing Science and Statistics (1994)
Benett, K.: Global tree optimization. Computing Science and Statistics (1994)
work page 1994
-
[4]
Breiman, L., Friedman, J., Olshen, A., Stone, C.: Classification and regression trees. Chapman and Hall (1984)
work page 1984
-
[5]
Breinman, L., Friedman, J., Olshen, R., Stone, C.: Classification and regression trees. CRC (1984)
work page 1984
-
[6]
Statistica Sinica 4(1), 143–167 (1994)
Chaudhuri, P., Huang, M.C., Loh, W.Y., Yao, R.: Piecewise-polynomial regression trees. Statistica Sinica 4(1), 143–167 (1994)
work page 1994
-
[7]
Chipman, H.A., George, E.I., McCulloch, R.E.: Bart: Bayesian additive regression trees. Ann. Appl. Stat. 4(1), 266–298 (03 2010). https://doi.org/10.1214/09-AOAS285
-
[8]
Jour- nal of Machine Learning Research 1, 143–160 (2001)
Collobert, R., Bengio, S.: Svmtorch: Support vector machines for large-scale regression problems. Jour- nal of Machine Learning Research 1, 143–160 (2001)
work page 2001
-
[9]
DeSalvo, G., Mohri, M.: Random composite forests. In: AAAI 2016 (2016)
work page 2016
-
[10]
Dobra, A., Gehrke, J.: Secret: a scalable linear regression tree algorithm. In: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 481–487 (2002)
work page 2002
-
[11]
Annals of Statistics 25(5), 1870–1911 (1997)
Donoho, D.: Cart and best ortho-basis: A connection. Annals of Statistics 25(5), 1870–1911 (1997)
work page 1911
-
[12]
In: Lecture Notes in Statistics, pp
Gey, S., Nedelec, E.: Risk bounds for cart regression trees. In: Lecture Notes in Statistics, pp. 369–379 (2003)
work page 2003
-
[13]
Karalic, A.: Employing linear regression in regression tree leaves. In: Proceeding of ECAI’92. pp. 440– 441 (1992)
work page 1992
-
[14]
IEEE Transactions on Infor- mation Theory 47(5), 1902–1914 (2001)
Koltchinskii, V.: Rademacher penalties and structural risk minimization. IEEE Transactions on Infor- mation Theory 47(5), 1902–1914 (2001)
work page 1902
-
[15]
In: The IEEE International Conference on Computer Vision (ICCV) (December 2015) 17
Kontschieder, P., Fiterau, M., Criminisi, A., Rota Bulo, S.: Deep neural decision forests. In: The IEEE International Conference on Computer Vision (ICCV) (December 2015) 17
work page 2015
-
[16]
Landwehr, N., Hall, M., Eibe, F.: Logit model trees. ECML PKDD (2003)
work page 2003
-
[17]
Lauer, P.: Error bounds for piecewise smooth and switching regression (2019), https://arxiv.org/abs/1707.07938
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Statistica Sinica 12(2), 361–386 (2002)
Loh, W.Y.: Regression tress with unbiased variable selection and interaction detection. Statistica Sinica 12(2), 361–386 (2002)
work page 2002
-
[19]
Mansour, Y., Mcallster, D.: Generalization bounds of decision trees. In: COLT 2000 (2000)
work page 2000
-
[20]
Maurer, A., Pontil, M.: Structured sparsity and generalization. JLMR 13, 671–690 (2012)
work page 2012
-
[21]
Journal of Machine Learning Research:Workshop and Conference Proceedings 35, 1–21 (2014)
Maurer, A., Pontil, M., Romera-Paredes, B.: An inequality with applications to structured sparsity and multitask dictionary learning. Journal of Machine Learning Research:Workshop and Conference Proceedings 35, 1–21 (2014)
work page 2014
-
[22]
Natarajan, R., Pednault, E.: Segmented Regression Estimators for Massive Data Sets, pp. 566–582
-
[23]
Norouzi, M., Collins, M., Johnson, M., Fleet, D., Kohli, P.: Efficient non-greedy optimization of decision trees. In: NIPS’15 Proceedings of the 28th International Conference on Neural Information Processing Systems. pp. 1729–1737 (2015)
work page 2015
-
[24]
Machine Learning61(1), 5–48 (2005)
Potts, D., Sammut, C.: Incremental learning of linear model trees. Machine Learning61(1), 5–48 (2005). https://doi.org/10.1007/s10994-005-1121-8
- [25]
-
[26]
Springer Science & Business Media (2008)
Steinwart, I., Christmann, A.: Support Vector Machines. Springer Science & Business Media (2008)
work page 2008
-
[27]
Torgo, L.: Functional models for regression tree leaves. In: ICML-97. pp. 385–393 (1997)
work page 1997
-
[28]
Torgo, L.: Computationally Efficient Linear Regression Trees, chap. I, pp. 409–417. Springer (2002)
work page 2002
-
[29]
Foundations and Trends in Machine Learning 8, 1–230 (2015)
Tropp, J.: An introduction to matrix concentration inequalities. Foundations and Trends in Machine Learning 8, 1–230 (2015)
work page 2015
-
[30]
Vogel, D., Asparouhov, O., Scheffer, T.: Scalable look-ahead linear regression trees. In: Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 757–764 (2007)
work page 2007
-
[31]
Wang, Y., Witten, I.: Inducing model trees for continuos classes. In: Proc. of Poster Papers, European Conf. in Machine Learning (1997) 18 A Appendix. Proofs of the main results A.1 Generalization error bounds of the class of Piecewise Linear Regression tree models We remind the formal definition used for the class of piecewise-linear regression trees F. F...
work page 1997
-
[32]
If for a given k , Lλ i,m≥ Lλ iT ,kT , we forgo calculating lλ j,m, rλ j,N−m,∀m, k≤ m≤ N− k
∀m, k≤ m≤ N− k we approximate Lλ i,m≈ lλ j,k + rλ j,N−k + (N− 2∗ k) ( min(lλ j,k− λ∥wj,k− w0∥2 Q, rλ j,N−k− λ∥wc j,N−k− wc 0∥2 Q) ) . If for a given k , Lλ i,m≥ Lλ iT ,kT , we forgo calculating lλ j,m, rλ j,N−m,∀m, k≤ m≤ N− k
-
[33]
If for a given i , Lλ i,m≥ Lλ iT ,kT , we forego calculating lλ j,m, rλ j,N−m,∀m, k≤ m≤ N− k
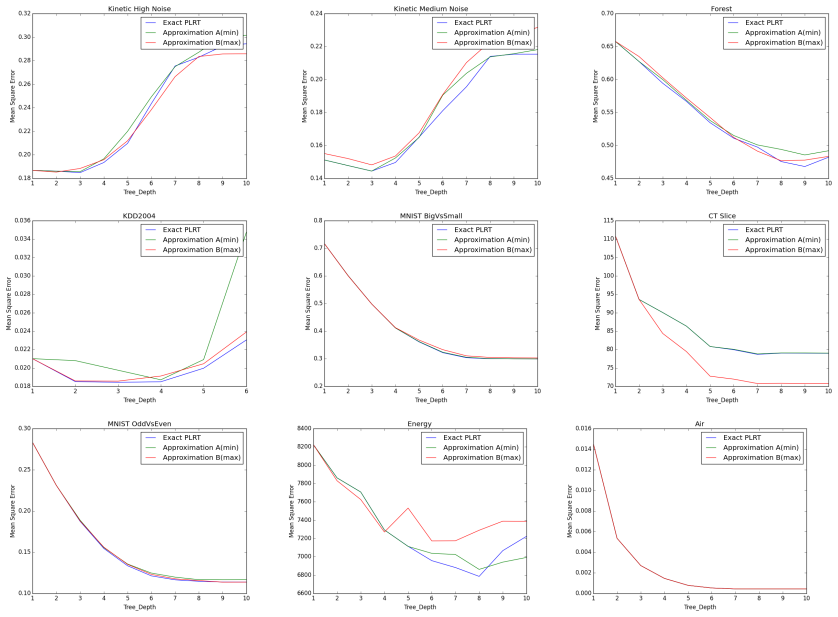
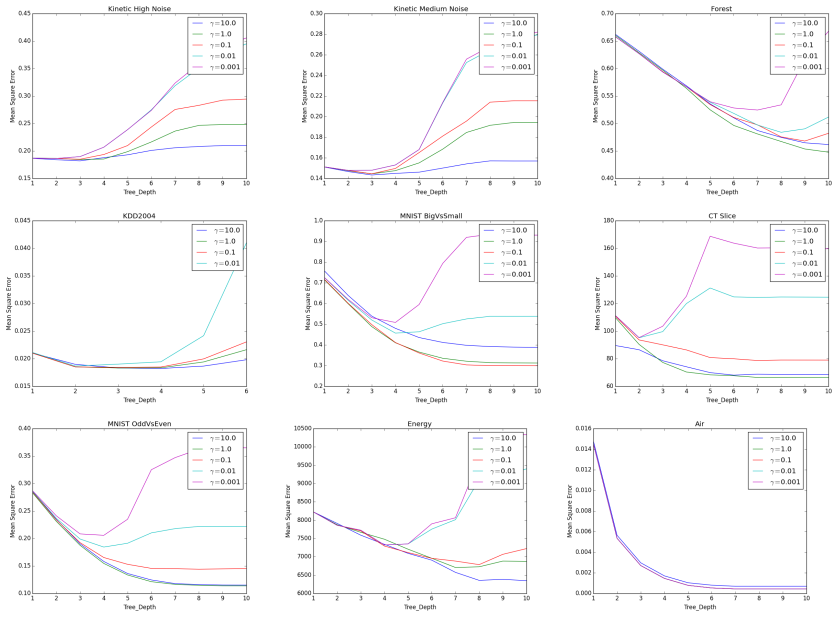
∀m, k≤ m≤ N− k we approximate Lλ i,m≈ lλ j,k + rλ j,N−k + (N− 2∗ k) ( max(lλ j,k− λ∥wj,k− w0∥2 Q, rλ j,N−k− λ∥wc j,N−k− wc 0∥2 Q) ) . If for a given i , Lλ i,m≥ Lλ iT ,kT , we forego calculating lλ j,m, rλ j,N−m,∀m, k≤ m≤ N− k. We set regularization parameterγ = 1 throughout these experiments and plot the loss for various tree depths on the various datase...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.