Gate the Filter, Not the Message: Node-Channel Mixtures for Pre-Propagation GNNs
Pith reviewed 2026-06-28 15:34 UTC · model grok-4.3
The pith
A 3D-gated mixture of Chebyshev filter experts enables joint node- and channel-adaptive filtering in pre-propagation GNNs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
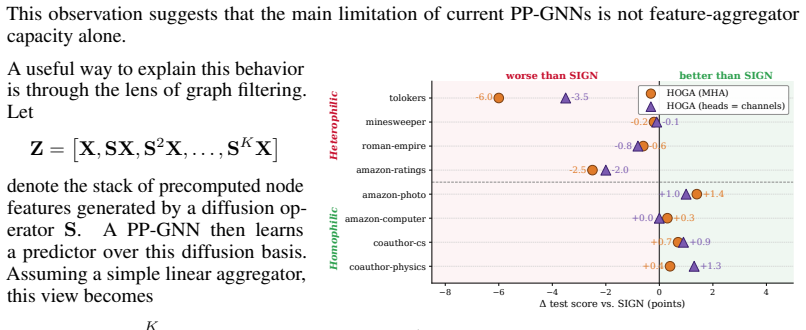
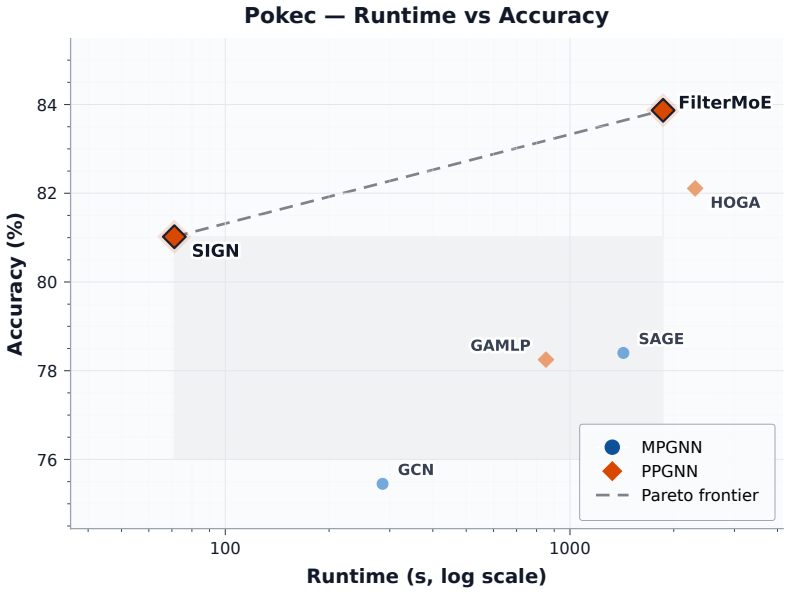
Existing PPGNNs differ primarily in filter coefficient sharing patterns: channel-dependent but node-shared for MLPs, node-dependent but channel-shared for hop-attention. The missing joint node-channel regime can be realized by routing a bank of learnable Chebyshev filters through a 3D gating tensor, producing a single model that outperforms prior PPGNNs on nine of eleven benchmarks and leads on all large-scale ones with a 1.53-point average gain.
What carries the argument
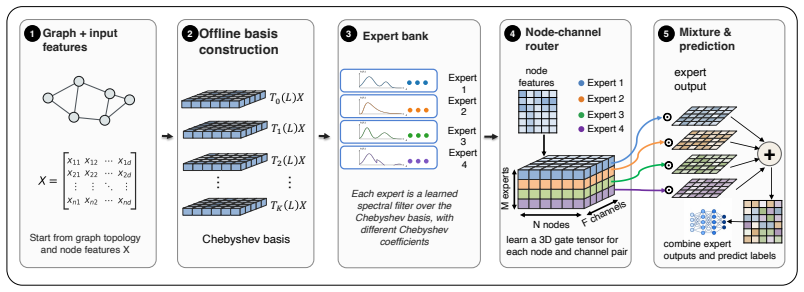
A 3D gating tensor that routes a small bank of learnable Chebyshev filter experts jointly over nodes and feature channels.
If this is right
- Outperforms strong PPGNN baselines on nine of eleven homophilic and heterophilic benchmarks.
- Ranks first on all three large-scale benchmarks tested.
- Delivers a 1.53-point average test-score improvement over prior designs.
- Supplies a single architecture that serves as a robust alternative to dataset-specific hop-aggregator selection.
Where Pith is reading between the lines
- The routing mechanism could be applied to other polynomial bases such as Bernstein or monomial filters while preserving the pre-propagation property.
- Joint node-channel adaptation may reduce the engineering effort spent on per-dataset hyperparameter searches over aggregator families.
- The same 3D gating idea might transfer to other scalable GNN families that separate propagation from learned parameters.
Load-bearing premise
Performance gaps among existing PPGNNs are explained mainly by differences in how filter coefficients are shared across nodes and channels rather than by differences in raw aggregator capacity.
What would settle it
A controlled test showing that a PPGNN variant with higher raw aggregator capacity but the same node-channel sharing pattern as an MLP or hop-attention model consistently beats FilterMoE on the large-scale benchmarks would falsify the central claim.
Figures
read the original abstract
Pre-propagation graph neural networks (PPGNNs) push all graph-dependent computation into a preprocessing step and train only on the resulting dense hop features, which makes them highly scalable. A puzzle in this regime is that more complex hop aggregators do not reliably outperform simpler ones: on many benchmarks, a plain MLP-based aggregator matches or beats hop-attention variants. We revisit this behavior from a graph-filter perspective. Over a precomputed diffusion basis, existing PPGNNs differ mainly in how filter coefficients are shared across nodes and feature channels, rather than simply in raw aggregator capacity. MLP-based architectures learn channel-dependent filters that are largely shared across nodes, while hop-attention-based architectures learn node-dependent mixtures that are largely shared across channels. This reveals a missing regime in standard PPGNN designs: joint node- and channel-adaptive filtering under the pre-propagation computational contract. We propose FilterMoE, a mixture-of-experts PPGNN in which a small bank of learnable Chebyshev filter experts is routed jointly over nodes and channels by a 3D gating tensor. Across eleven homophilic and heterophilic benchmarks, FilterMoE outperforms strong PPGNN baselines on nine datasets and ranks first on all three large-scale benchmarks, improving the average test score by 1.53 points. These results establish joint node-channel filter routing as a robust alternative to dataset-specific hop-aggregator selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FilterMoE, a pre-propagation GNN architecture that routes a small bank of learnable Chebyshev filter experts via a 3D gating tensor to realize joint node- and channel-adaptive filtering. It argues from a graph-filter perspective that prior PPGNNs differ mainly in how they share filter coefficients across nodes versus channels (MLP-style channel-dependent but node-shared; hop-attention-style node-dependent but channel-shared), identifies the joint regime as missing, and reports that FilterMoE outperforms strong PPGNN baselines on nine of eleven homophilic and heterophilic benchmarks while ranking first on all three large-scale ones with a 1.53-point average test-score gain.
Significance. If the performance advantage can be isolated to the joint node-channel routing mechanism, the work would supply a scalable, dataset-agnostic PPGNN design that replaces per-dataset aggregator selection with a single flexible filter-mixture regime. The multi-benchmark evaluation spanning homophilic and heterophilic graphs, together with emphasis on the three largest datasets, constitutes a concrete empirical contribution; the graph-filter unification of existing PPGNN designs is a useful organizing lens.
major comments (1)
- [Abstract and experimental evaluation] Abstract and experimental evaluation: the claim that PPGNN performance gaps are explained primarily by differences in node/channel filter sharing (rather than raw aggregator capacity) is load-bearing for motivating the 3D-gated MoE, yet the reported comparisons supply neither parameter counts nor FLOPs for the baselines, nor capacity-matched ablations that hold total expert parameters or routing overhead fixed. Consequently the 1.53-point average improvement and first-place large-scale results do not yet isolate the joint-sharing regime from the simple effect of increased effective capacity introduced by multiple learnable experts plus the 3D gating tensor.
minor comments (2)
- [Abstract] The abstract and results tables do not report per-run variance, standard errors, or statistical significance tests for the claimed improvements.
- [Method] Notation for the 3D gating tensor and its routing over nodes, channels, and experts should be introduced with an explicit equation or diagram in the method section to clarify the pre-propagation contract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the experimental controls. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] Abstract and experimental evaluation: the claim that PPGNN performance gaps are explained primarily by differences in node/channel filter sharing (rather than raw aggregator capacity) is load-bearing for motivating the 3D-gated MoE, yet the reported comparisons supply neither parameter counts nor FLOPs for the baselines, nor capacity-matched ablations that hold total expert parameters or routing overhead fixed. Consequently the 1.53-point average improvement and first-place large-scale results do not yet isolate the joint-sharing regime from the simple effect of increased effective capacity introduced by multiple learnable experts plus the 3D gating tensor.
Authors: We agree that parameter counts and FLOPs are necessary to better isolate the contribution of joint node-channel routing. In the revised manuscript we will add a table reporting parameter counts and estimated FLOPs for FilterMoE and all baselines. We will also include a capacity-controlled ablation that scales a single-expert Chebyshev baseline to match the total parameter budget of the mixture model, allowing direct comparison of the routing mechanism versus raw capacity. These additions will address the concern without altering the core claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an architectural proposal (FilterMoE with 3D-gated Chebyshev experts) plus empirical validation on eleven benchmarks. The motivating graph-filter perspective on node vs. channel sharing in PPGNNs is presented as an interpretive lens rather than a derived equation. No load-bearing mathematical steps, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. Performance gains are reported as experimental outcomes, not quantities forced by construction from the inputs. The contribution remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of filter experts
- Chebyshev polynomial degree
axioms (1)
- domain assumption Precomputed diffusion bases capture sufficient graph structure for downstream filter learning.
invented entities (1)
-
3D gating tensor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xuanze Chen, Jiajun Zhou, Shanqing Yu, and Qi Xuan. Mixture of experts meets decoupled message passing: Towards general and adaptive node classification.CoRR, abs/2412.08193,
-
[3]
URLhttps://jmlr.org/papers/v23/21-0998.html. Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael Bronstein, and Federico Monti. SIGN: Scalable Inception Graph Neural Networks.arXiv preprint arXiv:2004.11198,
arXiv 2004
-
[4]
Fernando Gama, Brendon G. Anderson, and Somayeh Sojoudi. Node-variant graph filters in graph neural networks.arXiv preprint arXiv:2106.00089,
-
[5]
URL https://arxiv.org/abs/2106.00089
doi: 10.48550/arXiv.2106.00089. URL https://arxiv.org/abs/2106.00089. Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict Then Propagate: Graph Neural Networks Meet Personalized PageRank.International Conference on Learning Representations (ICLR),
-
[6]
Schoenholz, Patrick F
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, Proceedings of Machine Learning Research, pages 1263–1272. PMLR,
2017
-
[7]
Jingwei Guo, Kaizhu Huang, Xinping Yi, and Rui Zhang
URLhttp://proceedings.mlr.press/v70/gilmer17a.html. Jingwei Guo, Kaizhu Huang, Xinping Yi, and Rui Zhang. Graph neural networks with diverse spectral filtering. InProceedings of the ACM web conference 2023, pages 306–316,
2023
-
[8]
Node-wise filtering in graph neural networks: A mixture of experts approach.CoRR, abs/2406.03464,
Haoyu Han, Juanhui Li, Wei Huang, Xianfeng Tang, Hanqing Lu, Chen Luo, Hui Liu, and Jiliang Tang. Node-wise filtering in graph neural networks: A mixture of experts approach.CoRR, abs/2406.03464,
-
[9]
Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba
doi: 10.48550/ARXIV .2406.03464. URL https://doi.org/10.48550/ arXiv.2406.03464. 10 Mingguo He, Zhewei Wei, and Ji-Rong Wen. Convolutional neural networks on graphs with chebyshev approximation, revisited. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Con...
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[10]
Graphdive: Graph classification by mixture of diverse experts
Fenyu Hu, Liping Wang, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. Graphdive: Graph classification by mixture of diverse experts. In Luc De Raedt, editor,Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pages 2080–2086. ijcai.org,
2022
-
[11]
doi: 10.24963/IJCAI.2022/289. Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open Graph Benchmark: Datasets for Machine Learning on Graphs.Conf. on Neural Information Processing Systems (NeurIPS),
-
[12]
doi: 10.1162/NECO.1991.3.1.79. URL https://doi.org/10.1162/neco.1991.3.1.79. Thomas N Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks.International Conference on Learning Representations (ICLR),
-
[13]
URLhttps://arxiv.org/abs/2006.16668. Sitao Luan, Chenqing Hua, Qincheng Lu, Jiaqi Zhu, Mingde Zhao, Shuyuan Zhang, Xiao-Wen Chang, and Doina Precup. Revisiting heterophily for graph neural networks.Advances in neural information processing systems, 35:1362–1375,
Pith/arXiv arXiv 2006
-
[14]
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. A critical look at the evaluation of gnns under heterophily: Are we really making progress?arXiv preprint arXiv:2302.11640,
-
[15]
Recipe for a general, powerful, scalable graph transformer
Ladislav Rampásek, Michael Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a general, powerful, scalable graph transformer. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Ad- vances in Neural Information Processing Systems 35: Annual Conference on Neural Infor- mation Processi...
2022
-
[16]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V
URL http://papers.nips.cc/paper_files/paper/2022/hash/ 5d4834a159f1547b267a05a4e2b7cf5e-Abstract-Conference.html. Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In5th International Conference on Learning Represe...
2022
-
[17]
URLhttps://openreview. net/forum?id=B1ckMDqlg. Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868,
-
[18]
Adaptive graph diffusion networks.arXiv preprint arXiv:2012.15024,
Chuxiong Sun, Jie Hu, Hongming Gu, Jinpeng Chen, and Mingchuan Yang. Adaptive graph diffusion networks.arXiv preprint arXiv:2012.15024,
arXiv 2012
-
[19]
Fastestimationoftr(𝑓(𝑎))viastochasticLanczosquadrature
doi: 10.1137/16M1104974. Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph Attention Networks.International Conference on Learning Representations (ICLR),
-
[20]
Graph mixture of experts: Learning on large-scale graphs with explicit diversity modeling
Haotao Wang, Ziyu Jiang, Yuning You, Yan Han, Gaowen Liu, Jayanth Srinivasa, Ramana Kompella, and Zhangyang Wang. Graph mixture of experts: Learning on large-scale graphs with explicit diversity modeling. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36...
2023
-
[21]
Xiyuan Wang and Muhan Zhang
URL http://papers.nips.cc/paper_files/paper/ 2023/hash/9f4064d145bad5e361206c3303bda7b8-Abstract-Conference.html. Xiyuan Wang and Muhan Zhang. How powerful are spectral graph neural networks. InInternational conference on machine learning, pages 23341–23362. PMLR,
2023
-
[22]
Mixture of weak and strong experts on graphs
Hanqing Zeng, Hanjia Lyu, Diyi Hu, Yinglong Xia, and Jiebo Luo. Mixture of weak and strong experts on graphs. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[23]
St-moe: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906,
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906,
-
[24]
It is intended for readers less familiar with pre-propagation GNNs (PP-GNNs). The key distinction is where graph-dependent computation occurs: message-passing GNNs (MP-GNNs) repeatedly aggregate over the graph during training, whereas PP-GNNs amortize graph propagation into a preprocessing stage and train a dense predictor over cached graph-diffused featu...
2017
-
[25]
fixed” denotes the standard public split; “random
Split protocol.We follow the standard split protocol for each dataset. For the four homophily datasets amazon-computer, amazon-photo, coauthor-cs, and coauthor-physics, we report mean±standard deviation over random splits. All other datasets use their fixed public splits. C Hardware settings For the training efficiency study, we use a Linux server with a ...
2025
-
[26]
Shared spectral preprocessing.All datasets use the same SLQ setup for the spectral response sketches in Sec
Each configuration is selected by Optuna TPE and then evaluated over 10 random seeds. Shared spectral preprocessing.All datasets use the same SLQ setup for the spectral response sketches in Sec. 3.2: 20 random-vector probes, 50 Lanczos iterations per probe, and a P= 64 point weighted spectral grid {(θp, wp)}64 p=1 on the rescaled graph Laplacian. This gri...
2023
-
[27]
–” means no projection.routeris either the Direct joint MLP router or the Response-aware two-stage router from Sec. 3.3. k is the sparse-routing top- k value, with “dense
For each tuned baseline, we run an Optuna TPE search on the validation split, select the best validation configuration, and report the mean and standard deviation over 10 random seeds. Unless otherwise specified, each search uses 50 trials per dataset. The same protocol is used for the Chebyshev-operator variants of SIGN, HOGA, and GAMLP in Appendix G: th...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.