Detecting Hidden ML Training With Zero-Overhead Telemetry
Pith reviewed 2026-06-26 21:01 UTC · model grok-4.3
The pith
Zero-overhead GPU telemetry identifies training workloads at 98.2 percent accuracy even after adversarial evasion attempts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A classifier built on content-agnostic NVML telemetry signals achieves 98.2 percent binary accuracy at identifying training workloads across the corpus and retains 43 to 87 percent accuracy against the hardest adversarially disguised unexpected workloads after evaluation of 20 evasion strategy families across 5 monitor-evader iterations on 9 GPU models spanning 4 architecture generations.
What carries the argument
The NVML telemetry classifier that maps zero-overhead, privacy-preserving hardware signals to workload labels without inspecting model weights, data, or hyperparameters.
If this is right
- Governance systems can monitor large GPU fleets using only existing hardware interfaces without added cost or privacy risk.
- Detection performance degrades but remains above random against repeated adversarial adaptation.
- The same signals work across four generations of GPU architectures.
- Unexpected workloads remain detectable even when operators attempt to disguise them as non-training tasks.
Where Pith is reading between the lines
- Similar telemetry on other accelerators could support comparable detection if equivalent low-level counters exist.
- Combining these signals with network or power data might raise accuracy further without changing the zero-overhead property.
- Mandating telemetry access on shared clusters could shift the cost of evasion onto operators who want to hide activity.
Load-bearing premise
The 20 evasion strategy families evaluated across 5 monitor-evader iterations are assumed to cover the strongest practical attacks that could be mounted against the telemetry-based detector in real deployments.
What would settle it
A workload using an evasion technique outside the 20 families that drops the classifier accuracy below 43 percent on the most challenging test cases would falsify the robustness claim.
Figures

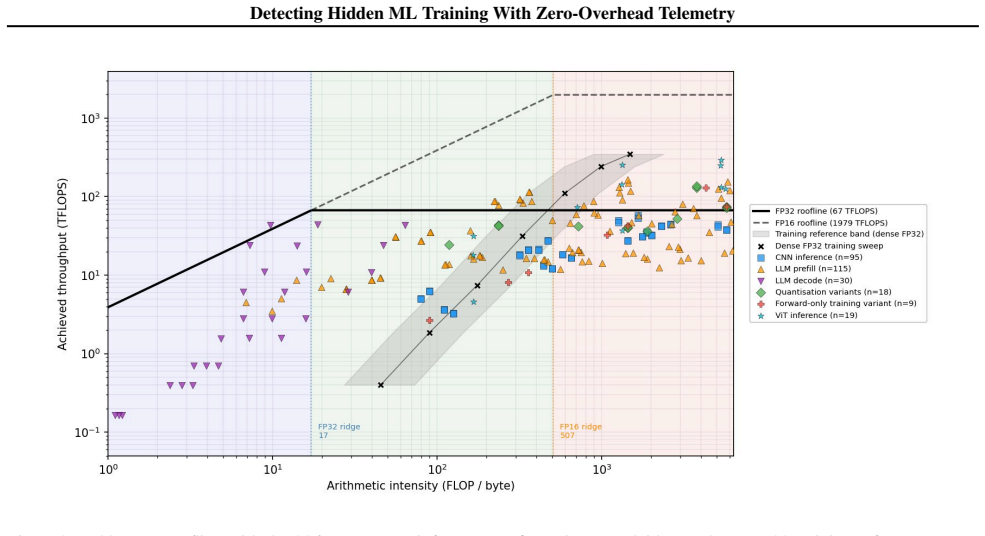
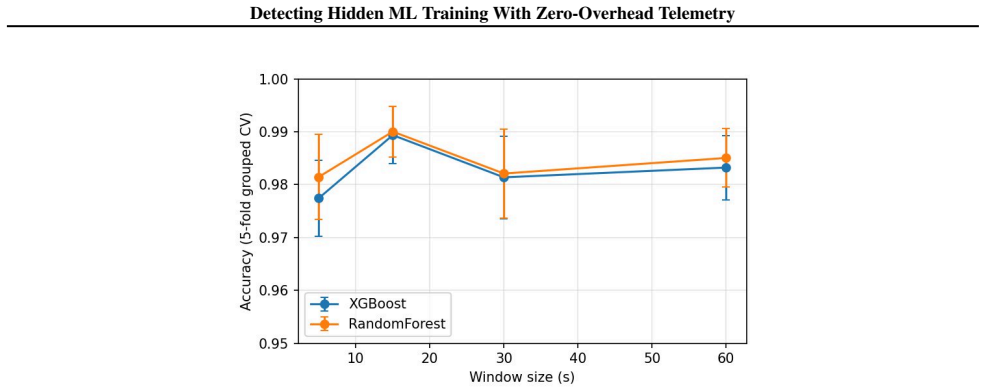
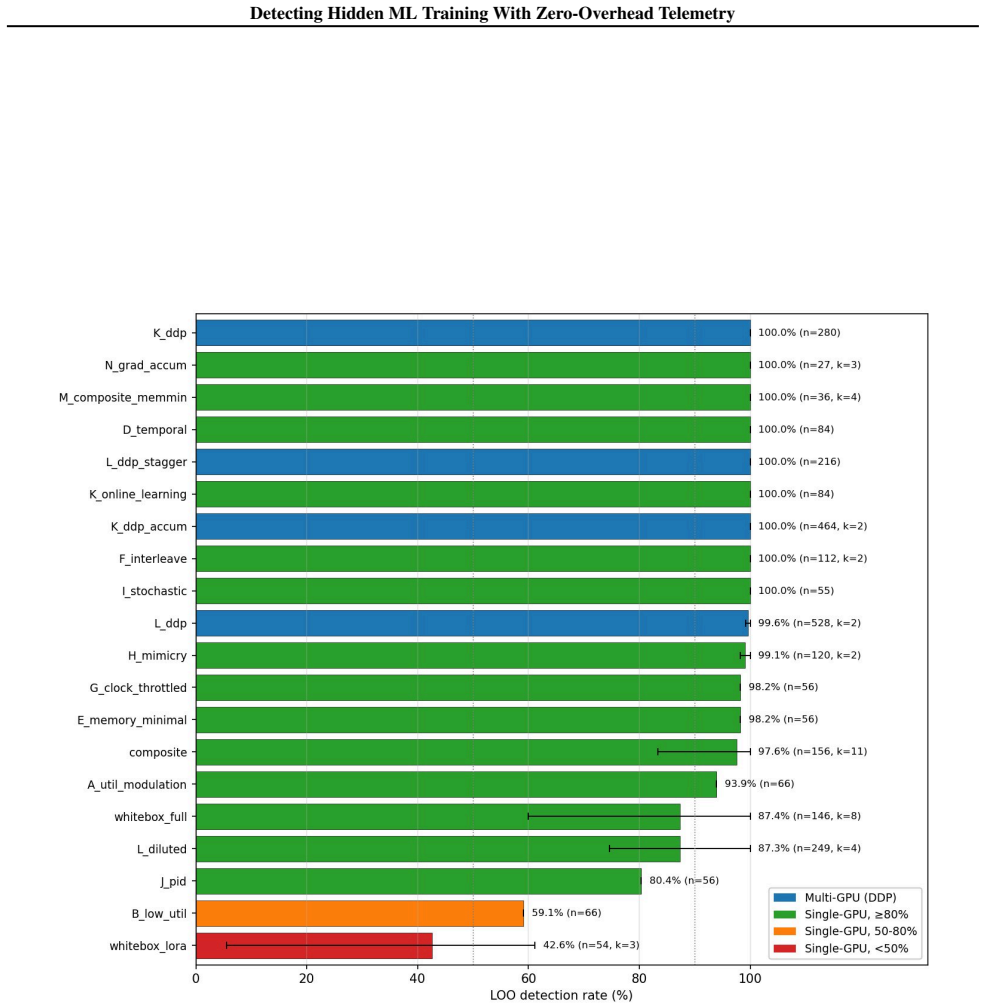
read the original abstract
Hardware-enabled monitoring of GPU workloads underpins many proposals for AI compute governance, but if developers can defeat monitoring mechanisms, such schemes are unworkable. We evaluate the adversarial robustness of GPU workload classification using only zero-overhead, privacy-preserving NVML telemetry: content-agnostic signals that observe physical effects of computation without accessing model weights, training data, or hyperparameters. Across 5 rounds of monitor-evader iteration, we evaluate 20 evasion strategy families on 9 GPU models spanning 4 architecture generations. We develop a classifier that achieves 98.2% binary accuracy at identifying training workloads across the whole corpus, and 43-87% accuracy against the most challenging unexpected workloads even when they are adversarially disguised.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates the adversarial robustness of a GPU workload classifier that uses only zero-overhead, content-agnostic NVML telemetry (power, utilization, temperature, clock rates) to detect ML training workloads. It reports 98.2% binary accuracy on a corpus of workloads and 43-87% accuracy on the most challenging unexpected workloads after 5 rounds of monitor-evader iteration over 20 evasion strategy families evaluated on 9 GPU models across 4 architecture generations.
Significance. If the robustness results hold under stronger scrutiny of the evaluation methodology, the work would provide concrete evidence that privacy-preserving hardware telemetry can support AI compute governance proposals by resisting practical evasion attempts without requiring access to model weights or data.
major comments (2)
- [Abstract] Abstract: the headline performance claims (98.2% binary accuracy; 43-87% on adversarially disguised workloads) are presented without any description of dataset construction, cross-validation, statistical tests, or how the accuracy ranges were aggregated, rendering the central empirical result unverifiable from the provided text.
- [Abstract] Abstract: the robustness claim rests on the untested assumption that the 20 evaluated evasion strategy families (iterated 5 times) adequately sample the space of strongest practical attacks against NVML signals; no theoretical coverage argument, exhaustive enumeration, or architecture-specific analysis is supplied to bound the possibility of stronger untested attacks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance claims (98.2% binary accuracy; 43-87% on adversarially disguised workloads) are presented without any description of dataset construction, cross-validation, statistical tests, or how the accuracy ranges were aggregated, rendering the central empirical result unverifiable from the provided text.
Authors: We agree the abstract omits these details for brevity. Dataset construction, cross-validation, and aggregation of the 43-87% range (derived from the final round of the 5-iteration process across 9 GPUs) are fully described in Sections 3 and 4. We will revise the abstract to add one sentence summarizing the corpus size, evaluation protocol, and range aggregation method. revision: yes
-
Referee: [Abstract] Abstract: the robustness claim rests on the untested assumption that the 20 evaluated evasion strategy families (iterated 5 times) adequately sample the space of strongest practical attacks against NVML signals; no theoretical coverage argument, exhaustive enumeration, or architecture-specific analysis is supplied to bound the possibility of stronger untested attacks.
Authors: The 20 families were selected to span the main practical categories observable in NVML (power, clock, thermal, utilization, and scheduling manipulations) and were stress-tested via 5 rounds of adaptive iteration. No theoretical coverage bound or exhaustive enumeration is provided, as the space of possible evasions is open-ended. We will add an explicit limitations paragraph acknowledging this and noting that stronger untested attacks remain possible. revision: partial
Circularity Check
No circularity: purely empirical evaluation
full rationale
The paper reports measured classifier accuracies (98.2% binary, 43-87% on evasive workloads) obtained by training and testing on collected NVML telemetry traces across 9 GPUs and 20 explicitly enumerated evasion families. No equations, fitted parameters, or self-citations appear in the provided text that would reduce these reported numbers to definitions or inputs internal to the paper itself. The evaluation is self-contained against the concrete corpus and attack families that were actually run; any concern about whether those 20 families exhaust the space of possible attacks is a question of experimental coverage rather than circular reduction of the claimed results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[7]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
O'Gara, Aidan and Kulp, Gabriel and Hodgkins, Will and Petrie, James and Immler, Vincent and Aysu, Aydin and Basu, Kanad and Bhasin, Shivam and Picek, Stjepan and Srivastava, Ankur , title =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[8]
2025 , url =
Aarne, Onni and Fist, Tim and Withers, Caleb , title =. 2025 , url =
2025
-
[9]
2025 , url =
Kulp, Gabriel and Siu, Daniel and Heim, Lennart , title =. 2025 , url =
2025
-
[10]
2025 , note =
Petrie, James , title =. 2025 , note =
2025
-
[12]
2025 , url =
Brass, Asher and Aarne, Onni , title =. 2025 , url =
2025
-
[13]
2023 , url =
Fist, Tim and Grunewald, Erich , title =. 2023 , url =
2023
-
[14]
Working paper , year =
Seferis, Emmanouil and Fist, Tim , title =. Working paper , year =
-
[16]
Proceedings of the Cray User Group (CUG) , year =
Weakley, Le Mai and Michael, Scott and Thota, Abhinav and Huber, Laura and Fulton, Ben and Kusz, Matthew , title =. Proceedings of the Cray User Group (CUG) , year =
-
[17]
Proceedings of the ACM , year =
Xu, Haoxuan and Gong, Chen and Liu, Beijie and Zheng, Haizhong and Chen, Beidi and Li, Mengyuan , title =. Proceedings of the ACM , year =
-
[23]
Working paper , year =
Esposito, Giuseppe and Guerrero-Balaguera, Juan-David and Condia, Josie Esteban Rodriguez and Reorda, Matteo Sonza and Barbiero, Marco and Fortuna, Rossella , title =. Working paper , year =
-
[24]
31st USENIX Security Symposium (USENIX Security 22) , year =
Maia, Henrique Teles and Xiao, Chang and Li, Dingzeyu and Grinspun, Eitan and Zheng, Changxi , title =. 31st USENIX Security Symposium (USENIX Security 22) , year =
-
[25]
Proceedings of the 15th ACM Conference on Data and Application Security and Privacy (CODASPY) , year =
Arefin, Sayed Erfan and Serwadda, Abdul , title =. Proceedings of the 15th ACM Conference on Data and Application Security and Privacy (CODASPY) , year =
-
[26]
and Carbone, Matthew R
Latif, Imran and Newkirk, Alex C. and Carbone, Matthew R. and Munir, Arslan and Lin, Yuewei and Koomey, Jonathan and Yu, Xi and Dong, Zhihua , title =. 2025 , url =
2025
-
[28]
Proceedings of the 53rd International Symposium on Computer Architecture (ISCA) , year =
Anonymous , title =. Proceedings of the 53rd International Symposium on Computer Architecture (ISCA) , year =
-
[29]
Machine Learning , volume =
Breiman, Leo , title =. Machine Learning , volume =
-
[30]
Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , pages =
Chen, Tianqi and Guestrin, Carlos , title =. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , pages =
-
[31]
Communications of the ACM , volume =
Williams, Samuel and Waterman, Andrew and Patterson, David , title =. Communications of the ACM , volume =
-
[33]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[34]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT) , pages =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , title =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT) , pages =
2019
-
[35]
Executive Order 14110: Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence , year =
-
[36]
2025 , url =
You, Josh and Owen, David , title =. 2025 , url =
2025
-
[37]
2025 , url =
Data on. 2025 , url =
2025
-
[38]
Secure, governable chips: Using on-chip mechanisms to manage national security risks from AI and advanced computing
Aarne, O., Fist, T., and Withers, C. Secure, governable chips: Using on-chip mechanisms to manage national security risks from AI and advanced computing. Technical report, Center for a New American Security, 2025. URL https://www.cnas.org/publications/reports/secure-governable-chips
2025
-
[39]
D., Ponomarev, D., and Abu-Ghazaleh, N
Almusaddar, G., Zhang, Y., Ganjisaffar, S., Williams, B., Liu, Y. D., Ponomarev, D., and Abu-Ghazaleh, N. ShadowScope : Composable performance-counter monitoring for GPU computation integrity. arXiv preprint arXiv:2509.00300, 2025. URL https://arxiv.org/abs/2509.00300
arXiv 2025
-
[40]
Differential architecture: Hardware mechanisms to limit the performance of targeted applications
Anonymous. Differential architecture: Hardware mechanisms to limit the performance of targeted applications. In Proceedings of the 53rd International Symposium on Computer Architecture (ISCA), 2026. Forthcoming
2026
-
[41]
Arefin, S. E. and Serwadda, A. Exploiting HDMI and USB ports for GPU side-channel insights. In Proceedings of the 15th ACM Conference on Data and Application Security and Privacy (CODASPY), 2025. arXiv:2410.02539
arXiv 2025
-
[42]
Baker, M., Kulp, G., Marks, O., Brundage, M., and Heim, L. Verifying international agreements on AI : Six layers of verification for rules on large-scale AI development and deployment. arXiv preprint arXiv:2507.15916, 2025. URL https://arxiv.org/abs/2507.15916
arXiv 2025
-
[43]
and Aarne, O
Brass, A. and Aarne, O. Location verification for AI chips. Technical report, Institute for AI Policy and Strategy, 2025. URL https://www.iaps.ai/research/location-verification-for-ai-chips
2025
-
[44]
Random forests
Breiman, L. Random forests. Machine Learning, 45 0 (1): 0 5--32, 2001
2001
-
[45]
and Guestrin, C
Chen, T. and Guestrin, C. XGBoost : A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pp.\ 785--794, 2016
2016
-
[46]
Electricity demand and grid impacts of AI data centers: Challenges and prospects
Chen, X., Wang, X., Colacelli, A., Lee, M., and Xie, L. Electricity demand and grid impacts of AI data centers: Challenges and prospects. arXiv preprint arXiv:2509.07218, 2025 a . URL https://arxiv.org/abs/2509.07218
arXiv 2025
-
[47]
Chen, Z., Chien, S. W. D., Qian, P., and Zilberman, N. Hardware-centric, workload-agnostic anomaly detection for GPU computing. arXiv preprint arXiv:2510.26008, 2025 b . URL https://arxiv.org/abs/2510.26008
arXiv 2025
-
[48]
BERT : Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), pp.\ 4171--4186, 2019
2019
-
[49]
Data on AI chip sales, 2025
Epoch AI . Data on AI chip sales, 2025. URL https://epoch.ai/data/ai-chip-sales
2025
-
[50]
Esposito, G., Guerrero-Balaguera, J.-D., Condia, J. E. R., Reorda, M. S., Barbiero, M., and Fortuna, R. Estimating GPU stress and reliability across workloads from telemetry and performance counters. Working paper, 2025
2025
-
[51]
and Grunewald, E
Fist, T. and Grunewald, E. Preventing AI chip smuggling to C hina: A working paper. Technical report, Center for a New American Security, 2023. URL https://www.cnas.org/publications/reports/preventing-ai-chip-smuggling-to-china
2023
-
[52]
Gangwal, A., Piazzetta, S. G., Lain, G., and Conti, M. Detecting covert cryptomining using HPC . arXiv preprint arXiv:1909.00268, 2019. URL https://arxiv.org/abs/1909.00268
arXiv 1909
-
[53]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 770--778, 2016
2016
-
[54]
Heim, L. and Koessler, L. Training compute thresholds: Features and functions in AI regulation. arXiv preprint arXiv:2405.10799, 2024. URL https://arxiv.org/abs/2405.10799
arXiv 2024
-
[55]
Heim, L., Fist, T., Egan, J., Huang, S., Zekany, S., Trager, R., Osborne, M. A., and Zilberman, N. Governing through the cloud: The intermediary role of compute providers in AI regulation. arXiv preprint arXiv:2403.08501, 2024. URL https://arxiv.org/abs/2403.08501
arXiv 2024
-
[56]
B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020. URL https://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2001
-
[57]
Hardware-enabled governance mechanisms: Developing technical solutions to exempt items otherwise classified under export control classification numbers 3A090 and 4A090
Kulp, G., Siu, D., and Heim, L. Hardware-enabled governance mechanisms: Developing technical solutions to exempt items otherwise classified under export control classification numbers 3A090 and 4A090 . Technical report, RAND Corporation, 2025. URL https://www.rand.org/pubs/working_papers/WRA3056-1.html
2025
-
[58]
Latif, I., Newkirk, A. C., Carbone, M. R., Munir, A., Lin, Y., Koomey, J., Yu, X., and Dong, Z. Empirical power signatures of large-scale training on 8- GPU H100 nodes. Technical report, Office of Scientific and Technical Information (OSTI), 2025. URL https://www.osti.gov/biblio/2555926
arXiv 2025
-
[59]
T., Xiao, C., Li, D., Grinspun, E., and Zheng, C
Maia, H. T., Xiao, C., Li, D., Grinspun, E., and Zheng, C. Can one hear the shape of a neural network? S nooping the GPU via magnetic side channel. In 31st USENIX Security Symposium (USENIX Security 22), pp.\ 4383--4400. USENIX Association, 2022
2022
-
[60]
K., Ganji, F., Holcomb, D., and Tajik, S
Monfared, S. K., Ganji, F., Holcomb, D., and Tajik, S. Detecting ML training under untrusted host and device via timing and memory observables. arXiv preprint arXiv:2602.09369, 2026. URL https://arxiv.org/abs/2602.09369
arXiv 2026
-
[61]
Hardware-enabled mechanisms for verifying responsible AI development
O'Gara, A., Kulp, G., Hodgkins, W., Petrie, J., Immler, V., Aysu, A., Basu, K., Bhasin, S., Picek, S., and Srivastava, A. Hardware-enabled mechanisms for verifying responsible AI development. In Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025. URL https://arxiv.org/abs/2505.03742. arXiv:2505.03742
arXiv 2025
-
[62]
POLCA : Power oversubscription in LLM cloud providers
Patel, P., Choukse, E., Zhang, C., Goiri, \'I ., Warrier, B., Mahalingam, N., and Bianchini, R. POLCA : Power oversubscription in LLM cloud providers. arXiv preprint arXiv:2308.12908, 2023. URL https://arxiv.org/abs/2308.12908
arXiv 2023
-
[63]
Offline licensing: A proposal for authorizing AI chip operation
Petrie, J. Offline licensing: A proposal for authorizing AI chip operation. Technical report, Institute for AI Policy and Strategy, 2025. Working paper
2025
-
[64]
Flexible hardware-enabled guarantees for AI compute
Petrie, J., Aarne, O., Ammann, N., and Dalrymple, D. Flexible hardware-enabled guarantees for AI compute. arXiv preprint arXiv:2506.03409, 2025. URL https://arxiv.org/abs/2506.03409
arXiv 2025
-
[65]
K., Ngo, R., Pilz, K., Gor, G., Bluemke, E., Shoker, S., Egan, J., Trager, R
Sastry, G., Heim, L., Belfield, H., Anderljung, M., Brundage, M., Hazell, J., O'Keefe, C., Hadfield, G. K., Ngo, R., Pilz, K., Gor, G., Bluemke, E., Shoker, S., Egan, J., Trager, R. F., Avin, S., Weller, A., Bengio, Y., and Coyle, D. Computing power and the governance of artificial intelligence. arXiv preprint arXiv:2402.08797, 2024. URL https://arxiv.org...
arXiv 2024
-
[66]
An international agreement to prevent the premature creation of artificial superintelligence
Scher, A., Abecassis, D., Barnett, P., and Abeyta, B. An international agreement to prevent the premature creation of artificial superintelligence. arXiv preprint arXiv:2511.10783, 2025. URL https://arxiv.org/abs/2511.10783
Pith/arXiv arXiv 2025
-
[67]
and Fist, T
Seferis, E. and Fist, T. Detecting compute structuring: Distributing training runs across providers. Working paper, 2025. URL https://openreview.net/forum?id=qseqw1sWzz
2025
-
[68]
Shavit, Y. What does it take to catch a C hinchilla? V erifying rules on large-scale neural network training via compute monitoring. arXiv preprint arXiv:2303.11341, 2023. URL https://arxiv.org/abs/2303.11341
arXiv 2023
-
[69]
Tang, B. J., Chen, Q., Weiss, M. L., Frey, N., McDonald, J., Bestor, D., Yee, C., Arcand, W., Byun, C., Edelman, D., Hubbell, M., Jones, M., Kepner, J., Klein, A., Michaleas, A., Michaleas, P., Milechin, L., Mullen, J., Prout, A., Reuther, A., Rosa, A., Bowne, A., McEvoy, L., Li, B., Tiwari, D., Gadepally, V., and Samsi, S. The MIT S upercloud workload cl...
arXiv 2022
-
[70]
Executive order 14110: Safe, secure, and trustworthy development and use of artificial intelligence, 2023
The White House . Executive order 14110: Safe, secure, and trustworthy development and use of artificial intelligence, 2023. URL https://www.federalregister.gov/documents/2023/11/01/2023-24283/. Federal Register 88 FR 75191
2023
-
[71]
M., Michael, S., Thota, A., Huber, L., Fulton, B., and Kusz, M
Weakley, L. M., Michael, S., Thota, A., Huber, L., Fulton, B., and Kusz, M. Classifying HPC and machine learning workloads from system telemetry. In Proceedings of the Cray User Group (CUG), 2025. URL https://cug.org/proceedings/cug2023_proceedings/cug2023_doi/papers_pages/pap139.html
2025
-
[72]
Roofline: An insightful visual performance model for multicore architectures
Williams, S., Waterman, A., and Patterson, D. Roofline: An insightful visual performance model for multicore architectures. Communications of the ACM, 52 0 (4): 0 65--76, 2009
2009
-
[73]
WAVE : Workload-aware verification via performance-counter evidence for GPU inference
Xu, H., Gong, C., Liu, B., Zheng, H., Chen, B., and Li, M. WAVE : Workload-aware verification via performance-counter evidence for GPU inference. In Proceedings of the ACM, 2026. URL https://dl.acm.org/doi/10.1145/3779212.3790247. doi:10.1145/3779212.3790247
-
[74]
You, J. and Owen, D. Scaling intelligence: The exponential growth of AI 's power needs. Technical report, EPRI, 2025. URL https://www.epri.com/research/products/000000003002033669
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.