Predict, Reuse, and Repair: Accelerating Dynamic Sparse Attention for Long-Context LLM Decoding
Pith reviewed 2026-06-30 07:00 UTC · model grok-4.3
The pith
PRR overlaps DSA block selection with attention computation by predicting likely KV blocks, speculating on them, and repairing misses to cut per-token latency up to 40 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
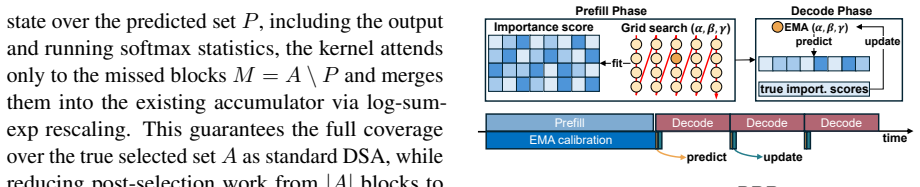
PRR is a runtime that exploits temporal locality in DSA block selections to predict likely blocks with an EMA predictor, speculate attention over them during selection, and repair the partial attention state with a FlashAttention-based kernel once the true top-K set arrives, thereby removing the serialized selection-to-attention dependency.
What carries the argument
The PRR speculate-reuse-repair runtime that combines an EMA-based predictor, a profiling-guided speculation budget, and an incremental FlashAttention repair kernel that updates online-softmax statistics for missed blocks.
If this is right
- Per-token decoding latency drops by as much as 40 percent on representative long-context benchmarks.
- Downstream task accuracy remains the same as the underlying DSA method.
- The technique applies across multiple existing DSA selection algorithms without changing their selection logic.
- Speculation work stays off the critical path through the use of a profiling-determined budget.
Where Pith is reading between the lines
- The repair kernel could be reused in other settings where partial attention results must be updated after a delayed decision.
- Higher temporal locality in future DSA methods would increase the fraction of work that can be overlapped.
- The same predict-repair pattern might reduce latency in other serialized stages of LLM inference such as dynamic KV cache eviction.
- If predictor accuracy improves, the same framework could support larger speculation budgets and greater speedups.
Load-bearing premise
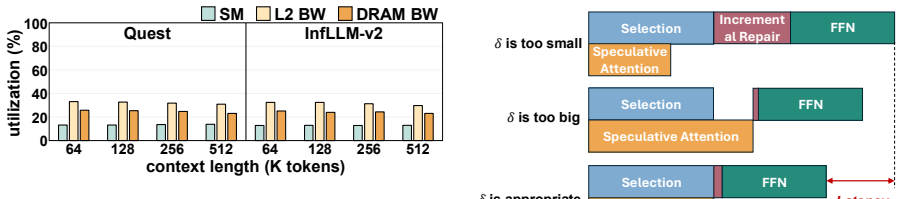
Block selections in DSA exhibit enough temporal locality that a simple EMA predictor can guess most blocks correctly and the cost of repairing the rest stays below the time saved by overlapping computation.
What would settle it
A measurement on a held-out long-context workload showing that the EMA predictor's hit rate is low enough for total PRR latency to exceed the latency of the original DSA baseline.
Figures



read the original abstract
Dynamic sparse attention (DSA) accelerates long-context LLM decoding by attending to only the top-K KV blocks relevant to each query, but it introduces a serialized selection-to-attention dependency that emerges as a new latency bottleneck. We present PRR, a speculate-reuse-repair runtime that exploits temporal locality in DSA selections to predict likely blocks, speculate the attention over them while selection is in flight, and incrementally repair missed blocks once the true selected set is known. PRR uses a lightweight EMA-based predictor, a profiling-guided speculation budget that keeps speculative work off the critical path, and a FlashAttention-based repair kernel that folds missed blocks into the partial attention state using online-softmax statistics. Across long-context benchmarks and representative DSA methods, PRR reduces per-token decoding latency by up to 40% while preserving downstream task accuracy. Github: https://github.com/Tianyu9748/Incremental_FlashAttention
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRR, a speculate-reuse-repair runtime for dynamic sparse attention (DSA) during long-context LLM decoding. It exploits temporal locality via a lightweight EMA-based predictor to speculate attention over likely KV blocks while selection is in flight, reuses correct speculations, and repairs misses with an incremental FlashAttention kernel that folds missed blocks into partial online-softmax states. A profiling-guided speculation budget keeps extra work off the critical path. The central empirical claim is that PRR reduces per-token decoding latency by up to 40% across long-context benchmarks and representative DSA methods while preserving downstream task accuracy. Code is released at https://github.com/Tianyu9748/Incremental_FlashAttention.
Significance. If the latency results hold under detailed scrutiny, the work addresses a practical serialization bottleneck in DSA and could improve inference efficiency for long-context models. The combination of prediction, reuse, and incremental repair is a pragmatic runtime technique. Explicit credit is due for the public code release, which supports reproducibility and allows independent verification of the empirical claims.
major comments (2)
- [Abstract] Abstract: the headline claim of 'up to 40% latency reduction' is presented without any description of the experimental protocol (chosen baselines, number of runs or variance reporting, hardware, context lengths, or whether measurements exclude warmup). This information is load-bearing for assessing whether the speedup is robust or benchmark-specific.
- [Evaluation] The central claim rests on the assumption that DSA block selections exhibit sufficient temporal locality for an EMA predictor plus bounded speculation budget to produce net savings after repair. No quantitative characterization is supplied (e.g., autocorrelation of selected block indices across tokens, hit-rate curves versus context length or layer, or sensitivity to model scale). Without this, the 40% figure cannot be separated from the particular locality present in the evaluated workloads.
minor comments (1)
- [Method] The description of the FlashAttention-based repair kernel would benefit from a short pseudocode or equation showing how the online-softmax statistics are updated when a missed block is folded in.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating where revisions will be made to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 'up to 40% latency reduction' is presented without any description of the experimental protocol (chosen baselines, number of runs or variance reporting, hardware, context lengths, or whether measurements exclude warmup). This information is load-bearing for assessing whether the speedup is robust or benchmark-specific.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol. In the revised manuscript, we will expand the abstract to include brief details on the evaluated DSA methods and baselines, hardware platform, context length ranges, averaging over multiple runs, and confirmation that reported latencies exclude warmup phases. revision: yes
-
Referee: [Evaluation] The central claim rests on the assumption that DSA block selections exhibit sufficient temporal locality for an EMA predictor plus bounded speculation budget to produce net savings after repair. No quantitative characterization is supplied (e.g., autocorrelation of selected block indices across tokens, hit-rate curves versus context length or layer, or sensitivity to model scale). Without this, the 40% figure cannot be separated from the particular locality present in the evaluated workloads.
Authors: We acknowledge the value of explicit quantitative characterization of temporal locality to better substantiate the core assumption. While the manuscript reports consistent end-to-end gains across multiple long-context benchmarks and DSA methods, it does not include autocorrelation analysis, hit-rate curves, or scale sensitivity. In the revision, we will add such analysis (e.g., predictor hit rates versus context length and layer) in a new subsection or appendix to separate the locality properties from the reported speedups. revision: yes
Circularity Check
No significant circularity; performance claims are empirical
full rationale
The paper introduces PRR as a runtime optimization exploiting temporal locality via an EMA predictor and FlashAttention repair, with the central result being measured latency reductions (up to 40%) on long-context benchmarks. No equations or derivations are presented that reduce a claimed prediction or first-principles result to its own inputs by construction. The method's effectiveness is validated externally via benchmarks rather than presupposed through self-definition, fitted inputs renamed as predictions, or self-citation chains. The assumption of sufficient locality is stated explicitly but does not create circularity in the reported outcomes.
Axiom & Free-Parameter Ledger
free parameters (2)
- EMA smoothing factor
- speculation budget
axioms (1)
- domain assumption DSA selections exhibit temporal locality across tokens
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Tang, Jiaming and Zhao, Yilong and Zhu, Kan and Xiao, Guangxuan and Kasikci, Baris and Han, Song , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[2]
Proceedings of Machine Learning and Systems , series =
FlexiCache: Leveraging Temporal Stability of Attention Heads for Efficient KV Cache Management , author =. Proceedings of Machine Learning and Systems , series =. 2026 , url =
2026
-
[3]
Advances in neural information processing systems , volume=
Infllm: Training-free long-context extrapolation for llms with an efficient context memory , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2509.24663 , year=
Infllm-v2: Dense-sparse switchable attention for seamless short-to-long adaptation , author=. arXiv preprint arXiv:2509.24663 , year=
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Native sparse attention: Hardware-aligned and natively trainable sparse attention , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[7]
B ench: Extending Long Context Evaluation Beyond 100 K Tokens
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong. B ench: Extending Long Context Evaluation Beyond 100 K Tokens. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi...
-
[8]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the real context size of your long-context language models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2024 , publisher =
AIME 2024 , author =. 2024 , publisher =
2024
-
[10]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions , author =
-
[12]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[13]
and Barrett, Clark and Sheng, Ying , title =
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[14]
Dao, Tri , booktitle=. Flash
-
[15]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving , author =. arXiv preprint arXiv:2501.01005 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
\ InfiniGen \ : Efficient generative inference of large language models with dynamic \ KV \ cache management , author=. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
-
[17]
Less Is More: Fast and Accurate Reasoning with Cross-Head Unified Sparse Attention
Less is more: Training-free sparse attention with global locality for efficient reasoning , author=. arXiv preprint arXiv:2508.07101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
AsyncTLS: Efficient Generative LLM Inference with Asynchronous Two-level Sparse Attention
AsyncTLS: Efficient Generative LLM Inference with Asynchronous Two-level Sparse Attention , author=. arXiv preprint arXiv:2604.07815 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
arXiv preprint arXiv:2506.15704 , year=
Learn from the Past: Fast Sparse Indexing for Large Language Model Decoding , author=. arXiv preprint arXiv:2506.15704 , year=
-
[20]
arXiv preprint arXiv:2510.07486 , year=
AsyncSpade: Efficient Test-Time Scaling with Asynchronous Sparse Decoding , author=. arXiv preprint arXiv:2510.07486 , year=
-
[21]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot , author=. arXiv preprint arXiv:2412.02612 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools , year=. 2406.12793 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[24]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[25]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[26]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Deepresearcher: Scaling deep research via reinforcement learning in real-world environments , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[27]
Advances in Neural Information Processing Systems , volume=
Webthinker: Empowering large reasoning models with deep research capability , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Rethinking the bounds of llm reasoning: Are multi-agent discussions the key? , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
International Conference on Learning Representations , volume=
Advancing llm reasoning generalists with preference trees , author=. International Conference on Learning Representations , volume=
-
[30]
ACM Transactions on Software Engineering and Methodology , volume=
Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2025 , publisher=
2025
-
[31]
Advances in Neural Information Processing Systems , volume=
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
International Conference on Learning Representations , volume=
Efficient streaming language models with attention sinks , author=. International Conference on Learning Representations , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2402.09398 , year=
Get more with less: Synthesizing recurrence with kv cache compression for efficient llm inference , author=. arXiv preprint arXiv:2402.09398 , year=
-
[35]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Scope: Optimizing key-value cache compression in long-context generation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
arXiv preprint arXiv:2410.21465 , year=
Shadowkv: Kv cache in shadows for high-throughput long-context llm inference , author=. arXiv preprint arXiv:2410.21465 , year=
-
[37]
arXiv preprint arXiv:2510.11292 , year=
LouisKV: Efficient KV Cache Retrieval for Long Input-Output Sequences , author=. arXiv preprint arXiv:2510.11292 , year=
-
[38]
Proceedings of the ACM SIGOPS 31st symposium on operating systems principles , pages=
Hedrarag: Co-optimizing generation and retrieval for heterogeneous rag workflows , author=. Proceedings of the ACM SIGOPS 31st symposium on operating systems principles , pages=
-
[39]
2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=
Dynamollm: Designing llm inference clusters for performance and energy efficiency , author=. 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=. 2025 , organization=
2025
-
[40]
Wang, Zibo and Zhang, Yijia and Wei, Fuchun and Wang, Bingqiang and Liu, Yanlin and Hu, Zhiheng and Zhang, Jingyi and Xu, Xiaoxin and He, Jian and Wang, Xiaoliang and Dou, Wanchun and Chen, Guihai and Tian, Chen , title =. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume ...
-
[41]
arXiv preprint arXiv:2603.13430 , year=
Dynamic Sparse Attention: Access Patterns and Architecture , author=. arXiv preprint arXiv:2603.13430 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.