MixerSENet: A Lightweight Framework for Efficient Hyperspectral Image Classification
Pith reviewed 2026-06-28 15:05 UTC · model grok-4.3
The pith
MixerSENet decouples spatial and channel mixing in a constant-resolution patch network plus squeeze-excitation to classify hyperspectral images with 53k parameters and higher accuracy than heavier baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
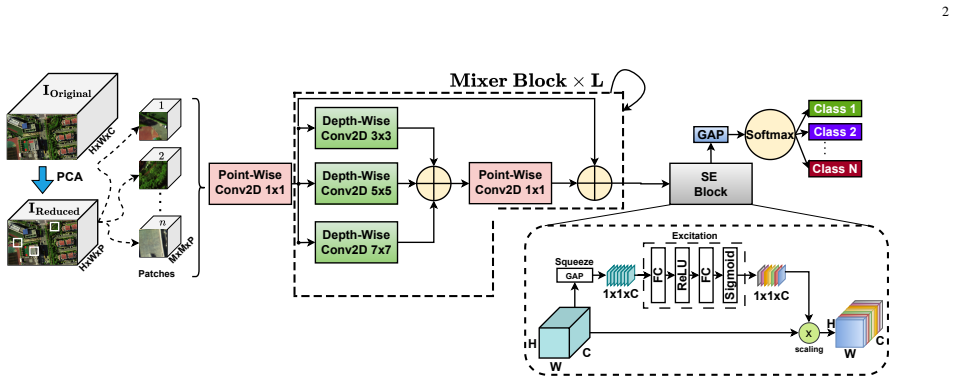
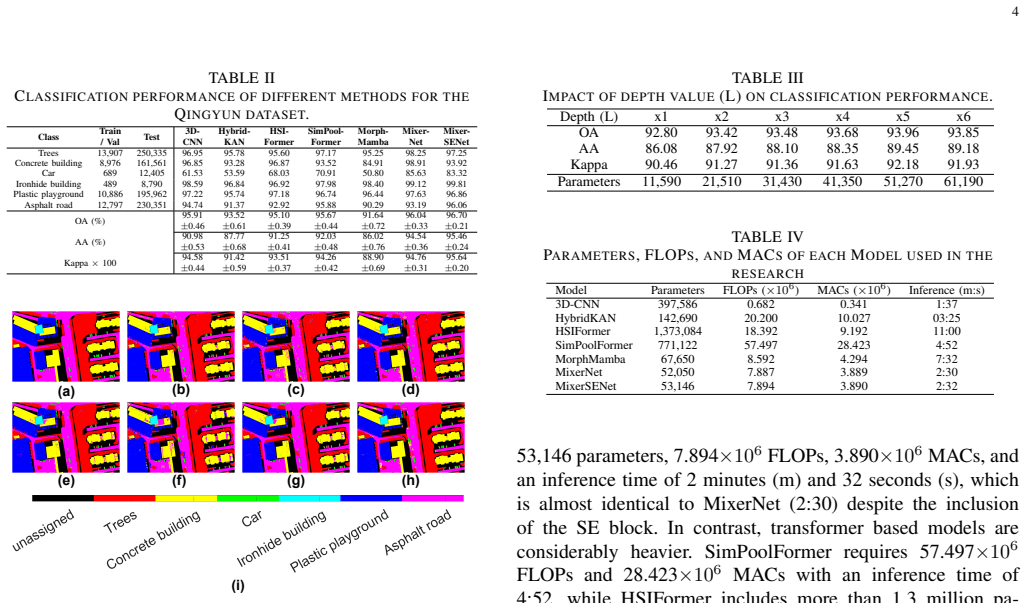
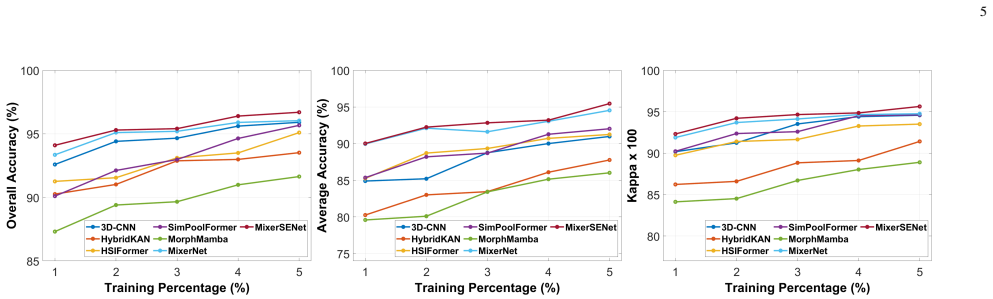
MixerSENet processes hyperspectral image patches while maintaining consistent size and resolution throughout the network, effectively decoupling the mixing of spatial and channel dimensions, incorporates a squeeze and excitation block to refine feature extraction, and reaches overall accuracies of 82.47 percent on the Houston13 dataset and 96.70 percent on the Qingyun dataset with only 53,146 parameters, outperforming 3D-CNN, HybridKAN, HSIFormer, SimPoolFormer, and MorphMamba while keeping inference time low.
What carries the argument
The spatial-channel decoupling mixer that keeps patch size and resolution fixed across layers, augmented by a squeeze-and-excitation block for feature refinement.
If this is right
- The model requires far fewer parameters than traditional deep networks, enabling use in resource-constrained settings such as satellite or drone platforms.
- It delivers a better accuracy-efficiency balance than the compared state-of-the-art methods on the two benchmark datasets.
- The constant-resolution patch processing avoids the need for upsampling or resizing operations inside the network.
- Low inference time combined with high accuracy supports real-world deployment where both speed and precision matter.
Where Pith is reading between the lines
- The same decoupling pattern could be tested on other multi-band remote-sensing tasks such as semantic segmentation or change detection to check whether parameter savings generalize.
- If the squeeze-excitation block is the main contributor, ablating it while keeping the mixer fixed would quantify its isolated contribution on the same datasets.
- Public release of the code allows direct measurement of whether the architecture transfers to new sensors or larger spatial resolutions without retraining from scratch.
Load-bearing premise
The accuracy gains arise from the architectural decoupling and squeeze-excitation design rather than from dataset-specific tuning, training protocol details, or non-identical evaluation conditions for the baseline methods.
What would settle it
Re-training or re-evaluating the listed baseline methods (3D-CNN, HybridKAN, HSIFormer, SimPoolFormer, MorphMamba) on the same Houston13 and Qingyun splits using identical data augmentation, optimizer, epochs, and random seeds as MixerSENet, then finding that any baseline matches or exceeds the reported overall accuracies.
Figures

read the original abstract
In this paper, a novel framework, MixerSENet, is introduced for hyperspectral image (HSI) classification, designed to address the challenges of computational efficiency and limited labeled data. The proposed model processes hyperspectral image patches while maintaining consistent size and resolution throughout the network, effectively decoupling the mixing of spatial and channel dimensions. Notably, MixerSENet is lightweight and computationally efficient, requiring fewer parameters compared to traditional models, making it suitable for resource-constrained environments. A squeeze and excitation block is incorporated into the model to refine feature extraction, enhancing the network's ability to capture more informative features. Experimental results on two benchmark datasets demonstrate that MixerSENet achieves superior performance, reaching an overall accuracy (OA) of 82.47% on Houston13 dataset and 96.70% on the Qingyun dataset, outperforming state-of-the-art methods including 3D-CNN, HybridKAN, HSIFormer, SimPoolFormer, and MorphMamba. Furthermore, a detailed analysis of computational efficiency shows that MixerSENet achieves a favorable balance between accuracy and efficiency, with only 53,146 parameters and an low inference time, confirming its practicality for real-world applications. At publication, source code will be publicly available at https://github.com/mqalkhatib/MixerSENet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MixerSENet, a lightweight architecture for hyperspectral image classification that decouples spatial and channel mixing via mixer layers and adds a squeeze-and-excitation block for feature refinement. It claims superior overall accuracy (82.47% on Houston13, 96.70% on Qingyun) over baselines including 3D-CNN, HybridKAN, HSIFormer, SimPoolFormer, and MorphMamba, while using only 53,146 parameters and low inference time, with code promised at publication.
Significance. If the performance deltas can be shown to arise from the architectural choices rather than evaluation mismatches, the work would provide a useful efficiency-focused baseline for HSI classification under limited labeled data and compute constraints.
major comments (2)
- [Abstract] Abstract: The headline claims (OA 82.47% Houston13, 96.70% Qingyun, outperforming listed SOTA methods) rest on the unverified assumption that all baselines were trained and evaluated under identical conditions (shared train/val/test splits, patch sizes, optimizer schedules, augmentation, early stopping). No such protocol details or re-implementation statements appear, rendering the attribution of gains to the spatial-channel decoupling or SE block unverifiable.
- [Experimental Results] Experimental section (implied by results): No information is supplied on training hyperparameters (epochs, batch size, learning rate, loss), number of runs, statistical significance testing, or confirmation that baseline numbers were reproduced rather than taken from original papers under potentially different settings; this directly undermines the central empirical claim.
minor comments (2)
- [Abstract] Abstract: 'an low inference time' is grammatically incorrect and should read 'a low inference time'.
- [Abstract] The GitHub link is noted as future work; until code and exact reproduction scripts are released, the numerical results cannot be independently verified.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of experimental reproducibility. The concerns about baseline training conditions and hyperparameter details are valid, and we will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (OA 82.47% Houston13, 96.70% Qingyun, outperforming listed SOTA methods) rest on the unverified assumption that all baselines were trained and evaluated under identical conditions (shared train/val/test splits, patch sizes, optimizer schedules, augmentation, early stopping). No such protocol details or re-implementation statements appear, rendering the attribution of gains to the spatial-channel decoupling or SE block unverifiable.
Authors: We agree that the manuscript does not currently include explicit statements confirming identical training conditions across all models or details on re-implementation. In the revised version, we will expand the abstract and add a new 'Experimental Setup' subsection that explicitly states the shared train/val/test splits, patch sizes, optimizer schedules, augmentation strategies, and early stopping criteria used for MixerSENet and all baselines. We will also add a sentence confirming that all listed models were re-implemented and trained under these identical conditions using a unified codebase. revision: yes
-
Referee: [Experimental Results] Experimental section (implied by results): No information is supplied on training hyperparameters (epochs, batch size, learning rate, loss), number of runs, statistical significance testing, or confirmation that baseline numbers were reproduced rather than taken from original papers under potentially different settings; this directly undermines the central empirical claim.
Authors: We acknowledge the absence of these details in the current manuscript. The revision will include a comprehensive description of all training hyperparameters (epochs, batch size, learning rate schedule, loss function), report mean and standard deviation over multiple independent runs (e.g., 5 runs), and include statistical significance testing (e.g., paired t-tests) against baselines. We will also explicitly state that baseline results were obtained via re-implementation under the same protocol rather than copied from original publications. The promised public code release will further support full reproducibility. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The manuscript presents an empirical neural architecture (MixerSENet) together with reported accuracies on two fixed benchmark datasets. No first-principles derivation, uniqueness theorem, or predictive equation is claimed; the performance numbers are direct outcomes of training and evaluation rather than quantities derived from the model definition by algebraic reduction. No self-citations, ansatzes, or fitted parameters are invoked as load-bearing steps in any derivation. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (3)
- number of mixer layers and channel dimensions
- squeeze ratio and excitation parameters in SE block
- optimizer settings and training schedule
axioms (2)
- domain assumption Houston13 and Qingyun datasets are appropriate and representative benchmarks for evaluating HSI classification methods
- domain assumption Maintaining constant patch size and resolution throughout the network is feasible and beneficial
invented entities (1)
-
MixerSENet architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Review of Hyperspectral Image Classifi- cation Based on Joint Spatial-spectral Features,
S. Qu, X. Li, and Z. Gan, “A Review of Hyperspectral Image Classifi- cation Based on Joint Spatial-spectral Features,” inJournal of Physics: Conference Series, vol. 2203. IOP Publishing, 2022, p. 012040
2022
-
[2]
Tri-CNN: a three branch model for hyperspectral image classification,
M. Q. Alkhatib, M. Al-Saad, N. Aburaed, S. Almansoori, J. Zabalza, S. Marshall, and H. Al-Ahmad, “Tri-CNN: a three branch model for hyperspectral image classification,”Remote Sensing, vol. 15, no. 2, p. 316, 2023
2023
-
[3]
HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification,
S. K. Roy, G. Krishna, S. R. Dubey, and B. B. Chaudhuri, “HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification,”IEEE Geoscience and Remote Sensing Letters, vol. 17, no. 2, pp. 277–281, 2019
2019
-
[4]
Deep convolutional neural networks for hyperspectral image classification,
W. Hu, Y . Huang, L. Wei, F. Zhang, and H. Li, “Deep convolutional neural networks for hyperspectral image classification,”Journal of Sensors, vol. 2015, pp. 1–12, 2015
2015
-
[5]
Deep supervised learning for hyperspectral data classification through convo- lutional neural networks,
K. Makantasis, K. Karantzalos, A. Doulamis, and N. Doulamis, “Deep supervised learning for hyperspectral data classification through convo- lutional neural networks,” in2015 IEEE international geoscience and remote sensing symposium (IGARSS). IEEE, 2015, pp. 4959–4962
2015
-
[6]
3-D deep learning approach for remote sensing image classification,
A. B. Hamida, A. Benoit, P. Lambert, and C. B. Amar, “3-D deep learning approach for remote sensing image classification,”IEEE Trans- actions on geoscience and remote sensing, vol. 56, no. 8, pp. 4420–4434, 2018
2018
-
[7]
A simplified 2D- 3D CNN architecture for hyperspectral image classification based on spatial–spectral fusion,
C. Yu, R. Han, M. Song, C. Liu, and C.-I. Chang, “A simplified 2D- 3D CNN architecture for hyperspectral image classification based on spatial–spectral fusion,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 13, pp. 2485–2501, 2020
2020
-
[8]
SCViT: A spatial-channel feature preserving vision transformer for remote sensing image scene classification,
P. Lv, W. Wu, Y . Zhong, F. Du, and L. Zhang, “SCViT: A spatial-channel feature preserving vision transformer for remote sensing image scene classification,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–12, 2022
2022
-
[9]
T 3SR: Texture Transfer Transformer for Remote Sensing Image Superresolution,
D. Cai and P. Zhang, “T 3SR: Texture Transfer Transformer for Remote Sensing Image Superresolution,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 7346– 7358, 2022
2022
-
[10]
Multimodal fusion transformer for remote sensing image classification,
S. K. Roy, A. Deria, D. Hong, B. Rasti, A. Plaza, and J. Chanussot, “Multimodal fusion transformer for remote sensing image classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1– 20, 2023
2023
-
[11]
HSIFormer: An Efficient Vision Trans- former Framework for Enhanced Hyperspectral Image Classification Using Local Window Attention,
M. Q. Alkhatib and A. Jamali, “HSIFormer: An Efficient Vision Trans- former Framework for Enhanced Hyperspectral Image Classification Using Local Window Attention,” in2024 14th Workshop on Hyper- spectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS). IEEE, 2024, pp. 1–5
2024
-
[12]
MLP-mixer: An all-MLP architecture for vision,
I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai, T. Unterthiner, J. Yung, A. Steiner, D. Keysers, J. Uszkoreitet al., “MLP-mixer: An all-MLP architecture for vision,”Advances in neural information processing systems, vol. 34, pp. 24 261–24 272, 2021
2021
-
[13]
PolSAR- ConvMixer: A Channel and Spatial Mixing Convolutional Algorithm for PolSAR Data Classification,
A. Jamali, S. K. Roy, B. Lu, A. Bhattacharya, and P. Ghamisi, “PolSAR- ConvMixer: A Channel and Spatial Mixing Convolutional Algorithm for PolSAR Data Classification,” inIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2024, pp. 11 248– 11 251
2024
-
[14]
SEM-RCNN: a squeeze-and- excitation-based mask region convolutional neural network for multi- class environmental microorganism detection,
J. Zhang, P. Ma, T. Jiang, X. Zhao, W. Tan, J. Zhang, S. Zou, X. Huang, M. Grzegorzek, and C. Li, “SEM-RCNN: a squeeze-and- excitation-based mask region convolutional neural network for multi- class environmental microorganism detection,”Applied Sciences, vol. 12, no. 19, p. 9902, 2022
2022
-
[15]
How to learn more? Exploring Kolmogorov–Arnold networks for hyperspectral image classification,
A. Jamali, S. K. Roy, D. Hong, B. Lu, and P. Ghamisi, “How to learn more? Exploring Kolmogorov–Arnold networks for hyperspectral image classification,”Remote Sensing, vol. 16, no. 21, p. 4015, 2024
2024
-
[16]
SimPoolFormer: A two-stream vision transformer for hy- perspectral image classification,
S. K. Roy, A. Jamali, J. Chanussot, P. Ghamisi, E. Ghaderpour, and H. Shahabi, “SimPoolFormer: A two-stream vision transformer for hy- perspectral image classification,”Remote Sensing Applications: Society and Environment, p. 101478, 2025
2025
-
[17]
Spatial–spectral morphological mamba for hyperspectral image classification,
M. Ahmad, M. H. F. Butt, A. M. Khan, M. Mazzara, S. Distefano, M. Usama, S. K. Roy, J. Chanussot, and D. Hong, “Spatial–spectral morphological mamba for hyperspectral image classification,”Neuro- computing, vol. 636, p. 129995, 2025
2025
-
[18]
Hyperspectral and lidar data fusion: Outcome of the 2013 grss data fusion contest,
C. Debes, A. Merentitis, R. Heremans, J. Hahn, N. Frangiadakis, T. Van Kasteren, W. Liao, R. Bellens, A. Pi ˇzurica, S. Gautamaet al., “Hyperspectral and lidar data fusion: Outcome of the 2013 grss data fusion contest,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 7, no. 6, pp. 2405–2418, 2014
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.