NaLA: A 3D Native LLM Layout Agent for High-quality 3D Scene Generation
Pith reviewed 2026-06-30 08:09 UTC · model grok-4.3
The pith
Encoding 3D assets directly into LLMs reduces information loss and improves scene layout quality over text conversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
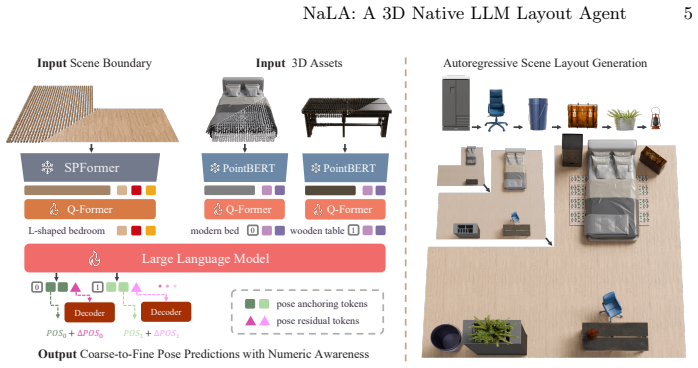
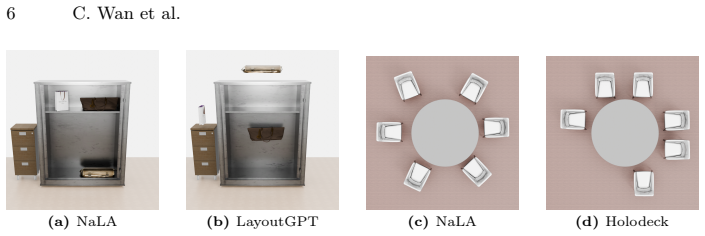
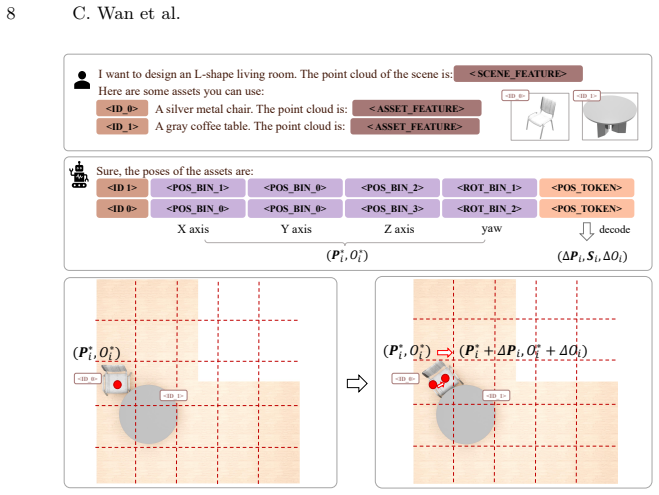
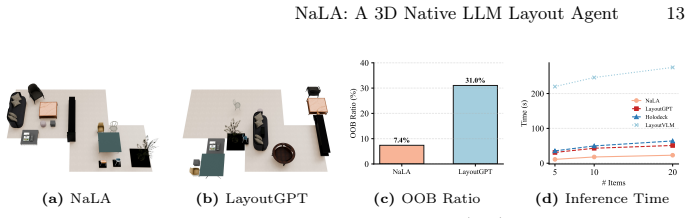
NaLA encodes 3D scene boundaries and 3D assets directly into the LLM, preserving fine-grained geometry and enabling explicit reasoning over relationships like collisions, surface supporting, and containment. It adopts a coarse-to-fine prediction mechanism that first predicts discrete poses in an autoregressive manner and then refines the discrete poses with a continuous regression. Trained on diverse layout datasets, NaLA attains strong geometric perception and layout coherence and outperforms prior layout agents in both generation quality and inference efficiency.
What carries the argument
Direct native 3D encoding of assets and boundaries into the LLM together with a coarse-to-fine autoregressive-then-regression pose predictor.
If this is right
- Higher geometric perception from avoiding text-based information loss.
- Explicit handling of spatial constraints such as collisions and containment.
- Faster inference than agents that rely on textual descriptions.
- Improved layout coherence when trained across multiple layout datasets.
- Each added component contributes measurably to overall performance as shown by ablations.
Where Pith is reading between the lines
- The same direct-encoding approach could reduce errors in other LLM tasks that involve 3D spatial planning.
- Integration with 3D vision encoders might allow end-to-end generation from images without intermediate text.
- Scaling the method to larger scenes could test whether native 3D input continues to prevent quality drop-off.
Load-bearing premise
Directly encoding 3D assets and boundaries into the LLM preserves fine-grained geometry and enables explicit reasoning over spatial relationships without introducing new modality-specific errors or training instabilities.
What would settle it
Running NaLA and a text-conversion baseline on identical scene inputs and checking whether NaLA produces fewer object collisions or unsupported placements while using less inference time.
Figures





read the original abstract
Recently, Large Language Models (LLMs) have emerged as promising layout agents for 3D scene generation. Existing layout agents still suffer from implausible layout generation because most of them convert 3D assets and 3D layouts into textual descriptions as inputs and outputs, which involves severe information loss due to the modality gap between texts and 3D assets and 3D layouts. We propose NaLA, a native 3D LLM layout Agent for high-quality 3D scene generation by placing 3D assets in the scene. For the inputs, NaLA encodes 3D scene boundaries and 3D assets directly into the LLM, preserving fine-grained geometry and enabling explicit reasoning over relationships like collisions, surface supporting, and containment. To accurately output the positions and orientations of assets, NaLA adopts a coarse-to-fine prediction mechanism that first predicts discrete poses in an autoregressive manner and then refines the discrete poses with a continuous regression. Trained on diverse layout datasets, NaLA attains strong geometric perception and layout coherence. Experiments demonstrate that NaLA outperforms prior layout agents in both generation quality and inference efficiency, with comprehensive ablation studies to verify each component's effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NaLA, a native 3D LLM layout agent for 3D scene generation. It encodes 3D scene boundaries and assets directly into the LLM (avoiding text-based modality gaps) to enable reasoning over collisions, support, and containment; uses a coarse-to-fine autoregressive discrete pose prediction followed by continuous regression; and claims, based on training on diverse layout datasets plus experiments and ablations, to outperform prior layout agents in generation quality and inference efficiency while attaining strong geometric perception and layout coherence.
Significance. If the claimed outperformance and component effectiveness hold under rigorous evaluation, the work could advance LLM-based 3D scene synthesis by reducing information loss in spatial reasoning, with potential downstream impact on applications requiring coherent 3D layouts. The explicit mention of comprehensive ablation studies to verify each component is a positive aspect of the experimental design.
major comments (2)
- [Abstract] Abstract: The central claim that 'NaLA outperforms prior layout agents in both generation quality and inference efficiency' is stated without any quantitative metrics, baselines, dataset sizes, error bars, or experimental protocol details. This absence makes the strength of the result impossible to assess from the provided text and is load-bearing for the paper's primary contribution.
- [Abstract] Abstract: The key assumption that directly encoding 3D assets and boundaries 'preserves fine-grained geometry' and enables explicit reasoning 'without introducing new modality-specific errors or training instabilities' is load-bearing for attributing gains to the native approach. No mechanism details (e.g., tokenization or embedding of continuous 3D geometry) or quantitative fidelity checks (e.g., reconstruction error of encoded assets) are supplied, leaving open the possibility that discretization losses are comparable to or larger than those in text-based methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] The central claim that 'NaLA outperforms prior layout agents in both generation quality and inference efficiency' is stated without any quantitative metrics, baselines, dataset sizes, error bars, or experimental protocol details. This absence makes the strength of the result impossible to assess from the provided text and is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights. The full manuscript reports these details in the Experiments section (including specific baselines, dataset sizes, and metrics with standard deviations). We will revise the abstract to concisely incorporate summary results (e.g., relative improvements on generation quality metrics and inference speed) while preserving length constraints. revision: yes
-
Referee: [Abstract] The key assumption that directly encoding 3D assets and boundaries 'preserves fine-grained geometry' and enables explicit reasoning 'without introducing new modality-specific errors or training instabilities' is load-bearing for attributing gains to the native approach. No mechanism details (e.g., tokenization or embedding of continuous 3D geometry) or quantitative fidelity checks (e.g., reconstruction error of encoded assets) are supplied, leaving open the possibility that discretization losses are comparable to or larger than those in text-based methods.
Authors: Mechanism details for 3D encoding, tokenization, and embedding are provided in Section 3 (Method) of the manuscript. We acknowledge that the abstract does not include quantitative fidelity metrics. We will add a brief reference to these details in the abstract and include a new quantitative analysis (reconstruction error and stability metrics) in the revised Experiments or Ablation section to directly address potential discretization concerns. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external experiments
full rationale
The provided abstract and description contain no equations, derivations, or self-referential steps. The method is described as encoding 3D boundaries/assets directly into an LLM with a coarse-to-fine pose mechanism, trained on diverse datasets, and evaluated via experiments and ablations. No self-definitional reductions (e.g., a quantity defined in terms of itself), fitted inputs renamed as predictions, load-bearing self-citations, imported uniqueness theorems, or ansatzes smuggled via prior work appear. Central claims of outperformance and geometric preservation are asserted via experimental results rather than reducing to inputs by construction. This is the expected non-finding for an empirical systems paper without a mathematical derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[2]
217–234 (2024)
Çelen, A., Han, G., Schindler, K., Van Gool, L., Armeni, I., Obukhov, A., Wang, X.: I-design: Personalized llm interior designer, pp. 217–234 (2024)
2024
-
[3]
ACM Transactions on Graphics (TOG)36(4), 1–12 (2017)
Cordonnier, G., Galin, E., Gain, J., Benes, B., Guérin, E., Peytavie, A., Cani, M.P.: Authoring landscapes by combining ecosystem and terrain erosion simula- tion. ACM Transactions on Graphics (TOG)36(4), 1–12 (2017)
2017
-
[4]
569–593 (1992)
Efron, B.: Bootstrap methods: another look at the jackknife pp. 569–593 (1992)
1992
-
[5]
Feng, W., Zhu, W., Fu, T.j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X.E., Wang, W.Y.: Layoutgpt: Compositional visual planning and generation with large language models (2023)
2023
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fu, H., Cai, B., Gao, L., Zhang, L.X., Wang, J., Li, C., Zeng, Q., Sun, C., Jia, R., Zhao, B., et al.: 3d-front: 3d furnished rooms with layouts and semantics. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10933–10942 (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, G., Liu, W., Chen, A., Geiger, A., Schölkopf, B.: Graphdreamer: Composi- tional 3d scene synthesis from scene graphs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21295–21304 (2024) 16 C. Wan et al
2024
-
[8]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kim, S.W., Brown, B., Yin, K., Kreis, K., Schwarz, K., Li, D., Rombach, R., Torralba, A., Fidler, S.: Neuralfield-ldm: Scene generation with hierarchical latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8496–8506 (2023)
2023
-
[10]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment
Kumaran, V., Rowe, J., Mott, B., Lester, J.: Scenecraft: automating interactive narrative scene generation in digital games with large language models. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment. vol. 19, pp. 86–96 (2023)
2023
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning seg- mentation via large language model. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9579–9589 (2024)
2024
-
[12]
Neurocomputing566, 127052 (2024)
Li, H., Zhu, G., Zhang, L., Jiang, Y., Dang, Y., Hou, H., Shen, P., Zhao, X., Shah, S.A.A., Bennamoun, M.: Scene graph generation: A comprehensive survey. Neurocomputing566, 127052 (2024)
2024
-
[13]
In: International confer- ence on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International confer- ence on machine learning. pp. 12888–12900. PMLR (2022)
2022
-
[14]
In: SIGGRAPH Asia 2024 Conference Papers
Li, X.L., Li, H., Chen, H.X., Mu, T.J., Hu, S.M.: Discene: Object decoupling and interaction modeling for complex scene generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–12 (2024)
2024
-
[15]
Li, X., Lai, Z., Xu, L., Qu, Y., Cao, L., Zhang, S., Dai, B., Ji, R.: Director3d: Real-world camera trajectory and 3d scene generation from text (2024)
2024
-
[16]
Archives of psychology (1932)
Likert, R.: A technique for the measurement of attitudes. Archives of psychology (1932)
1932
-
[17]
arXiv preprint arXiv:2505.02836 (2025)
Ling, L., Lin, C.H., Lin, T.Y., Ding, Y., Zeng, Y., Sheng, Y., Ge, Y., Liu, M.Y., Bera, A., Li, Z.: Scenethesis: A language and vision agentic framework for 3d scene generation. arXiv preprint arXiv:2505.02836 (2025)
-
[18]
In: Ad- vances in Neural Information Processing Systems (2025)
Mao, Y., Zhong, J., Fang, C., Zheng, J., Tang, R., Zhu, H., Tan, P., Zhou, Z.: Spatiallm: Training large language models for structured indoor modeling. In: Ad- vances in Neural Information Processing Systems (2025)
2025
-
[19]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[20]
In: European Conference on Computer Vision
Öcal, B.M., Tatarchenko, M., Karaoğlu, S., Gevers, T.: Sceneteller: Language-to- 3d scene generation. In: European Conference on Computer Vision. pp. 362–378. Springer (2024)
2024
-
[21]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[22]
Advances in Neural Information Processing Systems38, 125055–125081 (2026)
Ran, X., Li, Y., Xu, L., Yu, M., Dai, B.: Direct numerical layout generation for 3d indoor scene synthesis via spatial reasoning. Advances in Neural Information Processing Systems38, 125055–125081 (2026)
2026
-
[23]
Sun, F.Y., Liu, W., Gu, S., Lim, D., Bhat, G., Tombari, F., Li, M., Haber, N., Wu, J.: Layoutvlm: Differentiable optimization of 3d layout via vision-language models (2025)
2025
-
[24]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Sun, J., Qing, C., Tan, J., Xu, X.: Superpoint transformer for 3d scene instance segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 2393–2401 (2023) NaLA: A 3D Native LLM Layout Agent 17
2023
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tang, J., Nie, Y., Markhasin, L., Dai, A., Thies, J., Nießner, M.: Diffuscene: De- noising diffusion models for generative indoor scene synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20507– 20518 (2024)
2024
-
[26]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Team, Q.: Qwen2.5: A party of foundation models (September 2024),https:// qwenlm.github.io/blog/qwen2.5/
2024
-
[28]
arXiv preprint arXiv:2505.05474 (2025)
Wen, B., Xie, H., Chen, Z., Hong, F., Liu, Z.: 3d scene generation: A survey. arXiv preprint arXiv:2505.05474 (2025)
-
[29]
Wu, W., Fan, L., Liu, L., Wonka, P.: Miqp-based layout design for building interiors 37(2), 511–521 (2018)
2018
-
[30]
Yang, Y., Lu, J., Zhao, Z., Luo, Z., Yu, J.J., Sanchez, V., Zheng, F.: Llplace: The 3d indoor scene layout generation and editing via large language model (2024)
2024
-
[31]
Yang, Y., Sun, F.Y., Weihs, L., VanderBilt, E., Herrasti, A., Han, W., Wu, J., Haber, N., Krishna, R., Liu, L., et al.: Holodeck: Language guided generation of 3d embodied ai environments (2024)
2024
-
[32]
Yu, H., Wang, C., Zhuang, P., Menapace, W., Siarohin, A., Cao, J., Jeni, L., Tulyakov, S., Lee, H.Y.: 4real: Towards photorealistic 4d scene generation via video diffusion models. vol. 37, pp. 45256–45280 (2024)
2024
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, H.X., Duan, H., Hur, J., Sargent, K., Rubinstein, M., Freeman, W.T., Cole, F., Sun, D., Snavely, N., Wu, J., et al.: Wonderjourney: Going from anywhere to everywhere. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6658–6667 (2024)
2024
-
[34]
ACM Trans
Yu, L.F., Yeung, S.K., Tang, C.K., Terzopoulos, D., Chan, T.F., Osher, S.J.: Make it home: Automatic optimization of furniture arrangement. ACM Trans. Graph. 30(4), 86 (2011)
2011
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu, X., Tang, L., Rao, Y., Huang, T., Zhou, J., Lu, J.: Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19313– 19322 (2022)
2022
-
[36]
Zausinger, J., Pennig, L., Kozina, A., Sdahl, S., Sikora, J., Dendorfer, A., Kuznetsov, T., Hagog, M., Wiedemann, N., Chlodny, K., et al.: Regress, don’t guess–a regression-like loss on number tokens for language models (2024)
2024
-
[37]
Zhang, Y., Cai, Z., Wang, M., Guo, M., Li, T., Lin, L., Wang, Y.: M3dlayout: A multi-source dataset of 3d indoor layouts and structured descriptions for 3d generation (2026)
2026
-
[38]
Zhong, W., Cao, P., Jin, Y., Li, L., Cai, W., Lin, J., Wang, H., Lyu, Z., Wang, T., XU, X., et al.: Internscenes: A large-scale simulatable indoor scene dataset with realistic layouts (2026)
2026
-
[39]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhou,M.,Wang,Y.,Hou,J.,Zhang,S.,Li,Y.,Luo,C.,Peng,J.,Zhang,Z.:Scenex: Procedural controllable large-scale scene generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 10806–10814 (2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, C., Wang, T., Zhang, W., Pang, J., Liu, X.: Llava-3d: A simple yet effec- tive pathway to empowering lmms with 3d capabilities. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4295–4305 (2025)
2025
-
[41]
Dining_chair
Zhu, X., Huang, X., Xie, Q., Deng, Z., Yu, J., Guan, Y., Liu, Z., Zhu, L., Zhao, Q., Liu, L., et al.: Imaginarium: Vision-guided high-quality 3d scene layout generation. ACM Transactions on Graphics (TOG)44(6), 1–24 (2025) 18 C. Wan et al. A Supplementary Experiments A.1 Additional Quantitative Results Fig.8:Qualitative results of NaLA’s layout generation...
2025
-
[42]
Select items that naturally belong in a {target_scene_type}
-
[43]
The total count must be 20
-
[44]
str1", "str2
Output strictly a JSON list of strings [ "str1", "str2" ... ]. Your JSON List: """ Here,{target_scene_type}specifies the room type, and{style_description} is filled with a randomly sampled room style (out of “minimalist”, “cozy and warm”, “messy and cluttered”, “vintage and retro”, “industrial”, “luxurious and expensive”, “Modern and clean”) to increase t...
-
[45]
Physical Plausibility
-
[46]
Semantic Plausibility
-
[47]
Visual Aesthetics **SCORING METHODOLOGY (CRITICAL):** For each main dimension, you must evaluate specific **Sub-criteria**
-
[48]
Assign a score from 1 to 5 (Integer) for EACH sub-criterion
-
[49]
Calculate the average of these sub-scores to get the Final Dimension Score
-
[50]
""Here are the rendered images of a generated room layout. **Target Room Type:**
Round the Final Dimension Score to the nearest integer for the JSON output. Scoring Rubric: - 1: Very Poor (Critical failure, completely unusable) - 2: Poor (Major flaws, breaks immersion) - 3: Fair (Acceptable logic, but unrefined) - 4: Good (Functional and pleasing, minor issues) - 5: Excellent (Professional quality, flawless) Output strictly in JSON fo...
-
[51]
**Gravity & Support:** Are objects floating in the air? Are heavy objects naturally supported by the floor or other surfaces?
-
[52]
**Collision:** Do objects intersect or clip into each other or walls significantly? (Ignore very minor mesh overlaps)
-
[53]
**Stability:** Are objects placed in a way that implies they would fall over in real life? --- ### Dimension 2: Semantic Plausibility **Is the layout practical and functional for human use?** *(Sub-criteria)*
-
[54]
{room_type}
**Scene Identity (Layout-based):** Given the fixed set of assets, does this specific **arrangement** successfully convey the function of a "{room_type}"? (e.g., A bathroom layout should look like a bathroom, not a bedroom, based on how items are grouped)
-
[55]
**Accessibility / Flow:** Can a human physically walk through the space? Are pathways clear? Are doors, drawers, or critical zones blocked by other objects?
-
[56]
* *Examples:* A sofa must face the TV; A toilet must have legroom; A desk chair must face the desk
**Usability Logic:** **Definition:** The strict functional relationship between interacting objects. * *Examples:* A sofa must face the TV; A toilet must have legroom; A desk chair must face the desk. Is the primary function of the furniture enabled by its orientation and position?
-
[57]
natural
**Everyday Habits:** **Definition:** The "soft" constraints of human behavior and comfort, distinct from strict logic. * *Examples:* Is the nightstand practically placed within reach of the bedhead? Is the coffee table at a comfortable reach distance from the sofa (not too far, not too close)? Does the layout feel "natural " to live in? --- ### Dimension ...
-
[58]
visual weight
**Composition & Spatial Balance:** * *Explanation:* Evaluate the distribution of "visual weight". Does the room feel lopsided? Is there an appropriate use of negative space (empty floor), or is it overcrowded/too sparse?
-
[59]
Are objects aligned to implied architectural lines (walls, rugs)? Are rotations clean or chaotically random without purpose? Do edges align pleasingly?
**Alignment & Grid Logic:** * *Explanation:* Evaluate the geometric order. Are objects aligned to implied architectural lines (walls, rugs)? Are rotations clean or chaotically random without purpose? Do edges align pleasingly?
-
[60]
reasoning
**Arrangement Harmony:** * *Explanation:* Do the objects feel like they belong together in this specific cluster? Is the grouping aesthetically coherent, or does it look like a random pile of assets dumped on the floor? --- 26 C. Wan et al. ### Output Format Output ONLY valid JSON. **Important:** Inside the "reasoning" text, you must explicitly list the s...
-
[61]
Adjacent points in the list must share either the exact same X or the same Y coordinate
Orthogonal Only: All corners must be right angles. Adjacent points in the list must share either the exact same X or the same Y coordinate. No diagonal lines
-
[62]
- 1 cutout requires exactly 6 points (e.g., L-shape)
Form: Treat the room as a main rectangular Bounding Box with 1 or 2 rectangular "cutouts" missing from its edges or corners. - 1 cutout requires exactly 6 points (e.g., L-shape). - 2 cutouts require exactly 8 points (e.g., Z-shape, T-shape). NaLA: A 3D Native LLM Layout Agent 27
-
[63]
The area of each individual cutout must be $\le 0.25 \times S$
Area Limit: Let the area of the main Bounding Box be $S$. The area of each individual cutout must be $\le 0.25 \times S$
-
[64]
Scale is in meters
Tracing: The coordinates must trace the perimeter of the room in a continuous, non-intersecting closed loop (clockwise or counter- clockwise), starting at [0.0, 0.0]. Scale is in meters. Output Format: For each room, briefly state the Bounding Box dimensions, cutout dimensions, and prove the area constraint ($Cutout Area \le 0.25 \ times S$). Then output ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.