MR-IQA: A Unified Margin View of Regression and Ranking for Blind Image Quality Assessment
Pith reviewed 2026-06-30 06:33 UTC · model grok-4.3
The pith
Regression and ranking in blind image quality assessment both fit quality margins at the objective-optimization level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
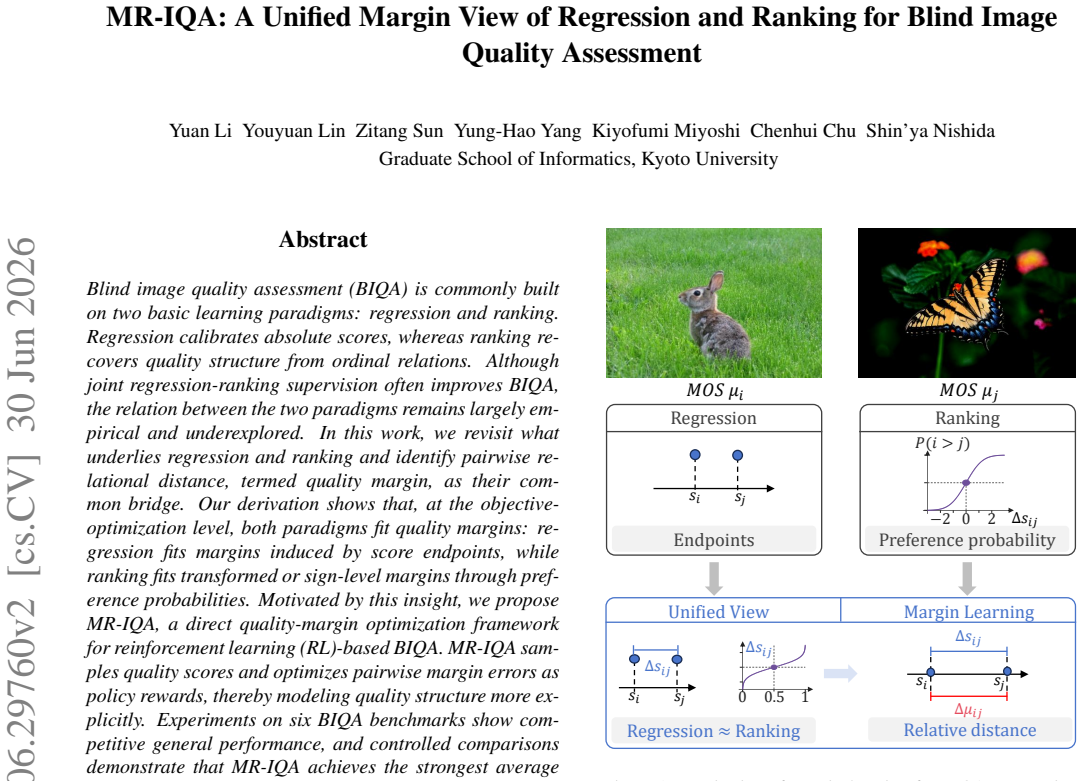
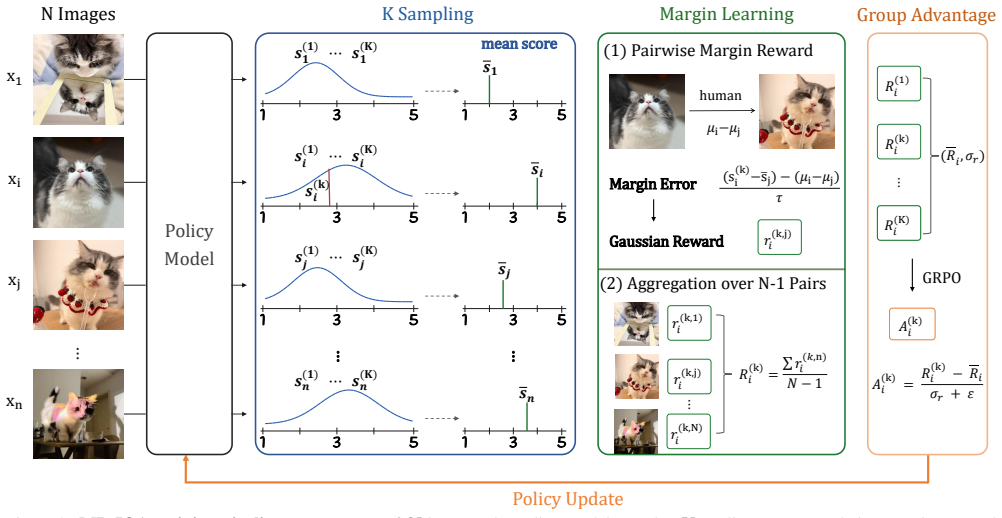
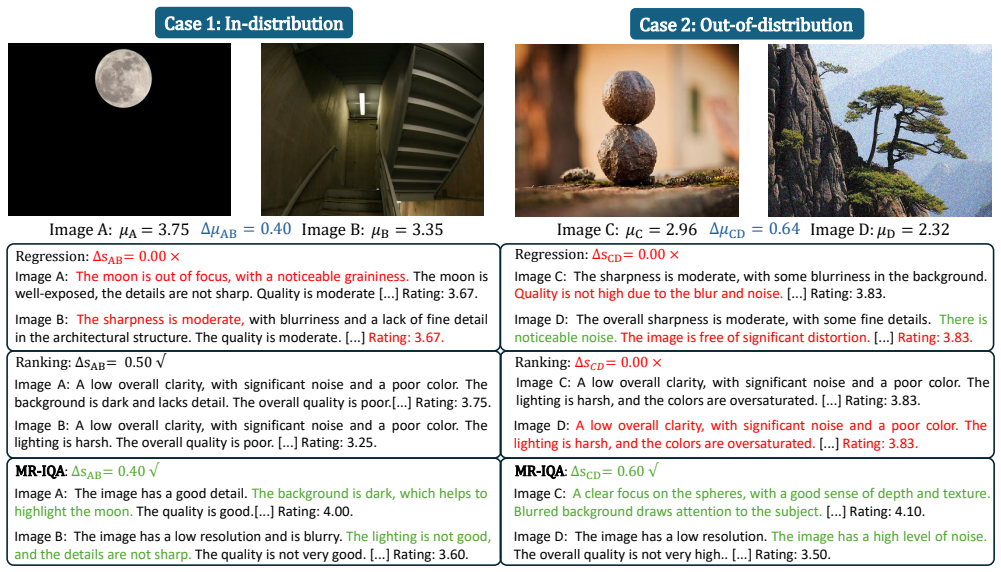
At the objective-optimization level, both regression and ranking paradigms fit quality margins: regression fits margins induced by score endpoints, while ranking fits transformed or sign-level margins through preference probabilities. Motivated by this insight, MR-IQA samples quality scores and optimizes pairwise margin errors as policy rewards, modeling quality structure more explicitly.
What carries the argument
The quality margin, defined as pairwise relational distance, which acts as the common bridge allowing both paradigms to be viewed as fitting the same type of quantity at the optimization level.
If this is right
- MR-IQA provides a direct quality-margin optimization framework for RL-based BIQA.
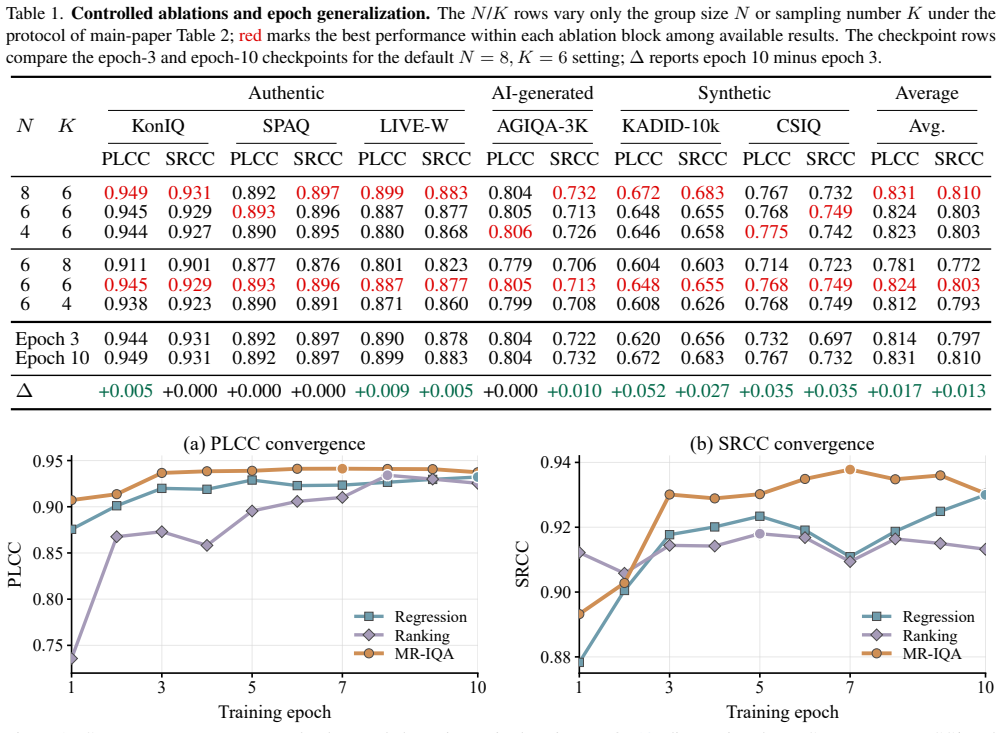
- Controlled comparisons show MR-IQA achieves the strongest average PLCC/SRCC over regression- or ranking-based RL methods.
- Experiments on six BIQA benchmarks demonstrate competitive general performance.
- The findings offer a theoretical basis for understanding quality-structure modeling in BIQA and beyond.
Where Pith is reading between the lines
- Applying the margin view could simplify the design of hybrid supervision in other ranking-regression tasks.
- New optimization algorithms that explicitly target margin errors might be developed for quality assessment problems.
- Testing the framework on non-image quality tasks involving ordinal and cardinal data could reveal broader applicability.
Load-bearing premise
Pairwise relational distance serves as the common bridge between regression and ranking at the optimization level without additional constraints on how margins are induced or transformed.
What would settle it
A demonstration that models trained with standard regression or ranking losses cannot be equivalently expressed as direct margin optimization on the same data would falsify the unification claim.
Figures
read the original abstract
Blind image quality assessment (BIQA) is commonly built on two basic learning paradigms: regression and ranking. Regression calibrates absolute scores, whereas ranking recovers quality structure from ordinal relations. Although joint regression-ranking supervision often improves BIQA, the relation between the two paradigms remains largely empirical and underexplored. In this work, we revisit what underlies regression and ranking and identify pairwise relational distance, termed quality margin, as their common bridge. Our derivation shows that, at the objective-optimization level, both paradigms fit quality margins: regression fits margins induced by score endpoints, while ranking fits transformed or sign-level margins through preference probabilities. Motivated by this insight, we propose MR-IQA, a direct quality-margin optimization framework for reinforcement learning (RL)-based BIQA. MR-IQA samples quality scores and optimizes pairwise margin errors as policy rewards, thereby modeling quality structure more explicitly. Experiments on six BIQA benchmarks show competitive general performance, and controlled comparisons demonstrate that MR-IQA achieves the strongest average PLCC/SRCC over regression- or ranking-based RL methods. Our findings provide a new insight into unifying regression and ranking, offering a theoretical basis for understanding quality-structure modeling in BIQA and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to unify regression and ranking for blind image quality assessment (BIQA) by identifying pairwise relational distance ('quality margin') as their common bridge at the objective-optimization level: regression fits margins induced by score endpoints while ranking fits transformed or sign-level margins through preference probabilities. Motivated by this, it proposes MR-IQA, an RL-based framework that samples quality scores and optimizes pairwise margin errors as policy rewards. Experiments on six BIQA benchmarks report competitive general performance and the strongest average PLCC/SRCC among regression- or ranking-based RL methods.
Significance. If the margin-based unification derivation holds without unstated constraints on induction or transformation rules, the work supplies a theoretical basis for quality-structure modeling in BIQA and could guide more explicit margin optimization in related ranking/regression tasks. The RL formulation and benchmark results would then constitute a practical demonstration of the insight.
major comments (2)
- [Abstract / derivation] Abstract (and derivation section): the central claim that both paradigms fit the same quality-margin quantity at the objective-optimization level requires the explicit mapping from score endpoints (regression) and from preference probabilities (ranking) to be derived step-by-step; without these equations it is impossible to verify that the unification avoids case-specific adjustments not justified by the shared margin concept.
- [Experiments] Experiments section: the claim that MR-IQA achieves the strongest average PLCC/SRCC over regression- or ranking-based RL methods is load-bearing for the practical contribution, yet no error bars, standard deviations, or statistical significance tests are mentioned, leaving the superiority assertion unsupported.
minor comments (1)
- [Abstract] The abstract introduces the term 'quality margin' without a concise one-sentence definition that readers can carry into the derivation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the paper to strengthen the presentation of the unification and the experimental claims.
read point-by-point responses
-
Referee: [Abstract / derivation] Abstract (and derivation section): the central claim that both paradigms fit the same quality-margin quantity at the objective-optimization level requires the explicit mapping from score endpoints (regression) and from preference probabilities (ranking) to be derived step-by-step; without these equations it is impossible to verify that the unification avoids case-specific adjustments not justified by the shared margin concept.
Authors: We agree that the mappings should be presented with full step-by-step equations for verifiability. The manuscript contains a derivation section establishing that regression fits margins induced by score endpoints while ranking fits transformed or sign-level margins via preference probabilities. In the revision we will expand this section with the explicit intermediate equations mapping the endpoint scores and the preference probabilities to the common margin quantity, ensuring no unstated case-specific adjustments remain. revision: yes
-
Referee: [Experiments] Experiments section: the claim that MR-IQA achieves the strongest average PLCC/SRCC over regression- or ranking-based RL methods is load-bearing for the practical contribution, yet no error bars, standard deviations, or statistical significance tests are mentioned, leaving the superiority assertion unsupported.
Authors: The referee is correct that the current version lacks error bars, standard deviations, and significance tests for the average PLCC/SRCC comparisons. In the revised manuscript we will report standard deviations across repeated runs and include paired statistical significance tests (e.g., Wilcoxon or t-tests) to substantiate the superiority claims over the compared RL baselines. revision: yes
Circularity Check
No significant circularity; unification presented as conceptual insight with external validation
full rationale
The paper's abstract and description identify pairwise relational distance (quality margin) as a conceptual bridge and state that a derivation shows both regression and ranking fit such margins at the optimization level. No equations or steps are quoted that reduce the claimed prediction or unification directly to a self-definition, fitted parameter renamed as output, or self-citation chain. The MR-IQA framework is motivated by the insight and evaluated on six independent BIQA benchmarks with PLCC/SRCC metrics, providing external falsifiability. The derivation is therefore treated as self-contained rather than tautological.
Axiom & Free-Parameter Ledger
invented entities (1)
-
quality margin
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arniqa: Learning distortion mani- fold for image quality assessment
Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini, and Alberto Del Bimbo. Arniqa: Learning distortion mani- fold for image quality assessment. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 189–198, 2024
2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun 8 Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[4]
On the use of deep learning for blind image quality assessment.Signal, Image and Video Processing, 12 (2):355–362, 2018
Simone Bianco, Luigi Celona, Paolo Napoletano, and Rai- mondo Schettini. On the use of deep learning for blind image quality assessment.Signal, Image and Video Processing, 12 (2):355–362, 2018
2018
-
[5]
Q-ponder: A unified train- ing pipeline for reasoning-based visual quality assessment
Zhuoxuan Cai, Jian Zhang, Xinbin Yuan, Peng-Tao Jiang, Wenxiang Chen, Bowen Tang, Lujian Yao, Qiyuan Wang, Jinwen Chen, and Bo Li. Q-ponder: A unified train- ing pipeline for reasoning-based visual quality assessment. arXiv preprint arXiv:2506.05384, 2025
-
[6]
Pair- wise comparisons are all you need.arXiv preprint arXiv:2403.09746, 2024
Nicolas Chahine, Sira Ferradans, and Jean Ponce. Pair- wise comparisons are all you need.arXiv preprint arXiv:2403.09746, 2024
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
Perceptual quality assessment of smartphone pho- tography
Yuming Fang, Hanwei Zhu, Yan Zeng, Kede Ma, and Zhou Wang. Perceptual quality assessment of smartphone pho- tography. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3677–3686, 2020
2020
-
[9]
Learn- ing to rank for blind image quality assessment.IEEE trans- actions on neural networks and learning systems, 26(10): 2275–2290, 2015
Fei Gao, Dacheng Tao, Xinbo Gao, and Xuelong Li. Learn- ing to rank for blind image quality assessment.IEEE trans- actions on neural networks and learning systems, 26(10): 2275–2290, 2015
2015
-
[10]
Live in the wild image quality challenge database.Online: http://live
Deepti Ghadiyaram and Alan C Bovik. Live in the wild image quality challenge database.Online: http://live. ece. utexas. edu/research/ChallengeDB/index. html [Mar, 2017], 2(5):6, 2015
2017
-
[11]
No-reference image quality assessment via transformers, rel- ative ranking, and self-consistency
S Alireza Golestaneh, Saba Dadsetan, and Kris M Kitani. No-reference image quality assessment via transformers, rel- ative ranking, and self-consistency. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1220–1230, 2022
2022
-
[12]
No-reference image quality assessment with reinforcement recursive list-wise ranking
Jie Gu, Gaofeng Meng, Cheng Da, Shiming Xiang, and Chunhong Pan. No-reference image quality assessment with reinforcement recursive list-wise ranking. InProceedings of the AAAI conference on artificial intelligence, pages 8336– 8343, 2019
2019
-
[13]
Koniq-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Transactions on Image Processing, 29:4041–4056, 2020
Vlad Hosu, Hanhe Lin, Tamas Sziranyi, and Dietmar Saupe. Koniq-10k: An ecologically valid database for deep learning of blind image quality assessment.IEEE Transactions on Image Processing, 29:4041–4056, 2020
2020
-
[14]
Convolu- tional neural networks for no-reference image quality assess- ment
Le Kang, Peng Ye, Yi Li, and David Doermann. Convolu- tional neural networks for no-reference image quality assess- ment. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1733–1740, 2014
2014
-
[15]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
2021
-
[16]
Most apparent dis- tortion: full-reference image quality assessment and the role of strategy.Journal of electronic imaging, 19(1):011006– 011006, 2010
Eric C Larson and Damon M Chandler. Most apparent dis- tortion: full-reference image quality assessment and the role of strategy.Journal of electronic imaging, 19(1):011006– 011006, 2010
2010
-
[17]
Agiqa-3k: An open database for ai-generated image quality assessment.IEEE Transactions on Circuits and Sys- tems for Video Technology, 34(8):6833–6846, 2023
Chunyi Li, Zicheng Zhang, Haoning Wu, Wei Sun, Xiongkuo Min, Xiaohong Liu, Guangtao Zhai, and Weisi Lin. Agiqa-3k: An open database for ai-generated image quality assessment.IEEE Transactions on Circuits and Sys- tems for Video Technology, 34(8):6833–6846, 2023
2023
-
[18]
Q-insight: Understanding image qual- ity via visual reinforcement learning.Advances in Neural Information Processing Systems, 38:36802–36827, 2026
Weiqi Li, Xuanyu Zhang, Shijie Zhao, Yabin Zhang, Junlin Li, Jian Zhang, et al. Q-insight: Understanding image qual- ity via visual reinforcement learning.Advances in Neural Information Processing Systems, 38:36802–36827, 2026
2026
-
[19]
Yuan Li, Yahan Yu, Youyuan Lin, Yong-Hao Yang, Chen- hui Chu, and Shin’ya Nishida. Guiding perception-reasoning closer to human in blind image quality assessment.arXiv preprint arXiv:2512.16484, 2025
-
[20]
Guoqiang Liang, Jianyi Wang, Zhonghua Wu, and Shangchen Zhou. Zoom-iqa: Image quality assessment with reliable region-aware reasoning.arXiv preprint arXiv:2601.02918, 2026
-
[21]
Kadid-10k: A large-scale artificially distorted iqa database
Hanhe Lin, Vlad Hosu, and Dietmar Saupe. Kadid-10k: A large-scale artificially distorted iqa database. In2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), pages 1–3. IEEE, 2019
2019
-
[22]
Rankiqa: Learning from rankings for no-reference image quality assessment
Xialei Liu, Joost Van De Weijer, and Andrew D Bagdanov. Rankiqa: Learning from rankings for no-reference image quality assessment. InProceedings of the IEEE international conference on computer vision, pages 1040–1049, 2017
2017
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
dipiq: Blind image quality assessment by learning-to-rank discriminable image pairs.IEEE Transac- tions on image processing, 26(8):3951–3964, 2017
Kede Ma, Wentao Liu, Tongliang Liu, Zhou Wang, and Dacheng Tao. dipiq: Blind image quality assessment by learning-to-rank discriminable image pairs.IEEE Transac- tions on image processing, 26(8):3951–3964, 2017
2017
-
[25]
No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12): 4695–4708, 2012
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12): 4695–4708, 2012
2012
-
[26]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Mak- ing a “completely blind” image quality analyzer.IEEE Sig- nal processing letters, 20(3):209–212, 2012
2012
-
[27]
Fu-Zhao Ou, Yuan-Gen Wang, Jin Li, Guopu Zhu, and Sam Kwong. Controllable list-wise ranking for univer- sal no-reference image quality assessment.arXiv preprint arXiv:1911.10566, 2019
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Nima: Neural image assessment.IEEE transactions on image processing, 27(8): 3998–4011, 2018
Hossein Talebi and Peyman Milanfar. Nima: Neural image assessment.IEEE transactions on image processing, 27(8): 3998–4011, 2018
2018
-
[30]
Rank-smoothed pairwise learning in per- ceptual quality assessment
Hossein Talebi, Ehsan Amid, Peyman Milanfar, and Man- fred K Warmuth. Rank-smoothed pairwise learning in per- ceptual quality assessment. In2020 IEEE International 9 Conference on Image Processing (ICIP), pages 3413–3417. IEEE, 2020
2020
-
[31]
A law of comparative judgment.Psy- chological review, 101(2):266, 1994
Louis L Thurstone. A law of comparative judgment.Psy- chological review, 101(2):266, 1994
1994
-
[32]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI conference on artificial intelligence, pages 2555–2563, 2023
2023
-
[33]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Chunyi Li, Liang Liao, Annan Wang, Erli Zhang, Wenxiu Sun, Qiong Yan, Xiongkuo Min, Guangtao Zhai, and Weisi Lin. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. Equal Contribution by Wu, Haon- ing and Zhang, Zicheng. Corresponding Aut...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Q-instruct: Improving low-level visual abilities for multi-modality foundation models
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Kaixin Xu, Chunyi Li, Jingwen Hou, Guangtao Zhai, et al. Q-instruct: Improving low-level visual abilities for multi-modality foundation models. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 25490–25500, 2024
2024
-
[35]
Visualquality-r1: Reasoning-induced image quality assess- ment via reinforcement learning to rank.Advances in Neural Information Processing Systems, 38:88167–88190, 2026
Tianhe Wu, Jian Zou, Jie Liang, Lei Zhang, and Kede Ma. Visualquality-r1: Reasoning-induced image quality assess- ment via reinforcement learning to rank.Advances in Neural Information Processing Systems, 38:88167–88190, 2026
2026
-
[36]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022
2022
-
[37]
Depicting beyond scores: Advanc- ing image quality assessment through multi-modal language models
Zhiyuan You, Zheyuan Li, Jinjin Gu, Zhenfei Yin, Tianfan Xue, and Chao Dong. Depicting beyond scores: Advanc- ing image quality assessment through multi-modal language models. InEuropean Conference on Computer Vision, pages 259–276. Springer, 2024
2024
-
[38]
Teaching large language models to regress accurate image quality scores using score distribution
Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue, and Chao Dong. Teaching large language models to regress accurate image quality scores using score distribution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14483–14494, 2025
2025
-
[39]
Blind image quality assessment using a deep bilinear convolutional neural network.IEEE Transactions on Cir- cuits and Systems for Video Technology, 30(1):36–47, 2018
Weixia Zhang, Kede Ma, Jia Yan, Dexiang Deng, and Zhou Wang. Blind image quality assessment using a deep bilinear convolutional neural network.IEEE Transactions on Cir- cuits and Systems for Video Technology, 30(1):36–47, 2018
2018
-
[40]
Shijie Zhao, Xuanyu Zhang, Weiqi Li, Junlin Li, Li Zhang, Tianfan Xue, and Jian Zhang. Reasoning as representation: Rethinking visual reinforcement learning in image quality assessment.arXiv preprint arXiv:2510.11369, 2025
-
[41]
Thurstone- style
Hanwei Zhu, Haoning Wu, Yixuan Li, Zicheng Zhang, Bao- liang Chen, Lingyu Zhu, Yuming Fang, Guangtao Zhai, Weisi Lin, and Shiqi Wang. Adaptive image quality as- sessment via teaching large multimodal model to compare. Advances in Neural Information Processing Systems, 37: 32611–32629, 2024. 10 Supplementary Material MR-IQA: A Unified Margin View of Regres...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.