Support Vector Machine with a Scalable Quantum Kernel
Pith reviewed 2026-06-28 21:57 UTC · model grok-4.3
The pith
The Hamming quantum kernel avoids exponential concentration in quantum support vector machines by processing full measurement statistics instead of a single fidelity value.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
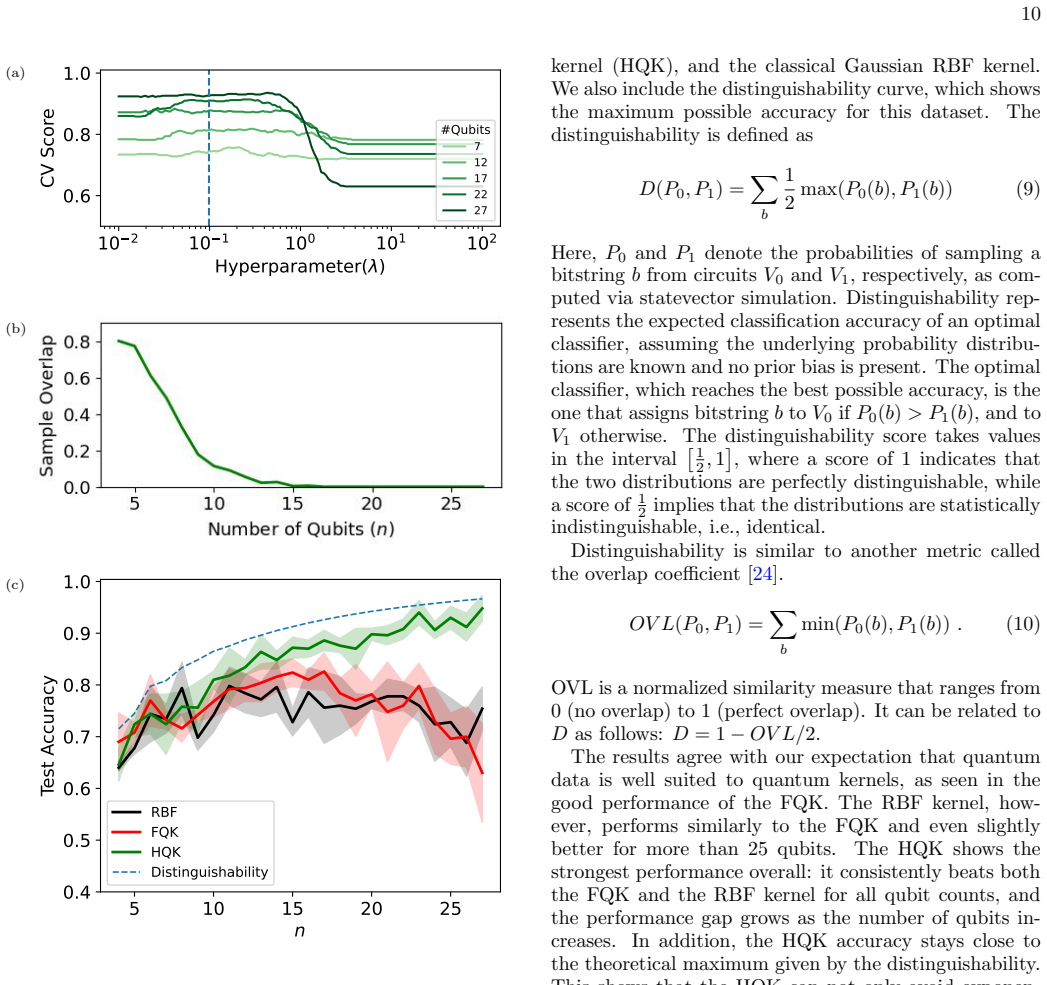
The Hamming quantum kernel is obtained by classical post-processing of the complete set of measurement outcomes rather than a single fidelity estimate; this construction eliminates the exponential concentration that degrades the fidelity kernel and produces higher classification accuracy on both classical MNIST data and synthetic quantum data for all tested systems with 15 or more qubits.
What carries the argument
Hamming quantum kernel: a classical post-processing map that turns the full probability distribution over measurement outcomes into kernel matrix entries.
If this is right
- The kernel maintains useful performance on systems up to at least 27 qubits.
- Classification accuracy exceeds that of the fidelity kernel for every tested case with 15 or more qubits.
- On quantum-generated data the kernel also exceeds the accuracy of the classical Gaussian kernel.
- No additional quantum circuit executions or hardware resources are required beyond those already used for the fidelity kernel.
Where Pith is reading between the lines
- The same full-statistics post-processing idea could be tested on other quantum kernel methods that currently suffer concentration.
- Because the extra work is entirely classical, the approach remains compatible with any quantum device that can already produce the raw measurement counts.
- If the classical post-processing step stays efficient, the method supplies a practical route to larger-scale quantum machine-learning models without waiting for fault-tolerant hardware.
Load-bearing premise
That feeding the complete set of measurement outcomes into the Hamming construction will consistently avoid exponential concentration and produce kernels with better classification performance than the fidelity kernel.
What would settle it
A controlled test on a 20-qubit system in which the Hamming kernel yields equal or lower classification accuracy than the fidelity kernel on the same MNIST or quantum-circuit data sets.
Figures
read the original abstract
Quantum support vector machines are classification algorithms that rely on quantum-generated kernels. The fidelity quantum kernel commonly used in quantum support vector machines suffers from exponential concentration as system size increases, preventing an efficient scaling beyond fewqubit systems. We introduce the Hamming quantum kernel, a classical post-processing method that is based on the same measurement outcomes as the fidelity quantum kernel. However, it avoids the exponential concentration problem by using the full measurement statistics rather than a single fidelity value. We evaluate the approach on both classical data (MNIST) and synthetic data generated from quantum circuits, using systems ranging from 2 to 27 qubits. Throughout the simulations, the Hamming quantum kernel outperforms the fidelity quantum kernel whenever 15 or more qubits are used. Furthermore, for synthetic quantum data, our method consistently outperforms the classical Gaussian kernel. This demonstrates that the Hamming quantum kernel improves the expressivity and robustness at larger qubit scales without requiring any additional quantum ressources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hamming quantum kernel as a classical post-processing of the full measurement statistics from the same quantum circuits used for the fidelity quantum kernel. It claims this avoids exponential concentration, enabling scalable SVM classification. Simulations on MNIST (classical data) and synthetic quantum-generated data for 2–27 qubits show the Hamming kernel outperforming the fidelity kernel for ≥15 qubits and the classical Gaussian kernel on quantum data, without additional quantum resources.
Significance. If the Hamming kernel is positive semi-definite and the performance gains hold under rigorous controls, the result would be significant for quantum machine learning: it offers a route to larger-scale quantum kernels using only existing measurement data and classical post-processing, directly addressing a known barrier (exponential concentration) in fidelity-based approaches.
major comments (2)
- [kernel definition section] Definition of Hamming quantum kernel (likely §3 or equivalent): no algebraic proof or explicit feature-map construction is provided to establish that the kernel is positive semi-definite. The fidelity kernel is PSD by construction as an inner product; the Hamming version applies classical post-processing (Hamming-distance or distribution functions) to the same bit strings. Without a demonstration that the resulting Gram matrix has non-negative eigenvalues for arbitrary inputs, the SVM quadratic program is not guaranteed to be convex, undermining the reported classification accuracies.
- [experimental evaluation] Experimental evaluation (§4–5, Tables/Figures on MNIST and synthetic data): the abstract and reported results omit error bars, exact hyperparameter grids, data-preprocessing steps, and the precise functional form of the Hamming kernel (e.g., whether it is a normalized inner product of empirical distributions). These omissions make it impossible to assess whether the claimed outperformance for ≥15 qubits is statistically robust or sensitive to implementation choices.
minor comments (2)
- [abstract] The abstract states performance claims without referencing the number of shots, circuit depth, or train/test splits; these details belong in the main text or a methods subsection for reproducibility.
- [kernel definition] Notation for the Hamming kernel should be introduced with an explicit equation (e.g., K_H(x,y) = f({p_i}, {q_i})) rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting important points regarding the positive semi-definiteness of the Hamming kernel and the completeness of our experimental reporting. We address each major comment below and will incorporate clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [kernel definition section] Definition of Hamming quantum kernel (likely §3 or equivalent): no algebraic proof or explicit feature-map construction is provided to establish that the kernel is positive semi-definite. The fidelity kernel is PSD by construction as an inner product; the Hamming version applies classical post-processing (Hamming-distance or distribution functions) to the same bit strings. Without a demonstration that the resulting Gram matrix has non-negative eigenvalues for arbitrary inputs, the SVM quadratic program is not guaranteed to be convex, undermining the reported classification accuracies.
Authors: We agree that an explicit demonstration of positive semi-definiteness is required for rigor. The Hamming kernel is constructed as a classical function of the full empirical probability distributions obtained from the same circuits, specifically via a normalized inner product of these distributions after applying a Hamming-distance-based feature map. This construction ensures the kernel is PSD because it corresponds to an inner product in the space of distribution features. We will add a dedicated subsection in the revised manuscript providing the algebraic proof, including the explicit feature-map representation and verification that all eigenvalues of the Gram matrix are non-negative for arbitrary inputs. This will confirm convexity of the SVM optimization. revision: yes
-
Referee: [experimental evaluation] Experimental evaluation (§4–5, Tables/Figures on MNIST and synthetic data): the abstract and reported results omit error bars, exact hyperparameter grids, data-preprocessing steps, and the precise functional form of the Hamming kernel (e.g., whether it is a normalized inner product of empirical distributions). These omissions make it impossible to assess whether the claimed outperformance for ≥15 qubits is statistically robust or sensitive to implementation choices.
Authors: We acknowledge these omissions reduce reproducibility and make it harder to evaluate robustness. In the revised version we will: (i) report all performance metrics with error bars computed over multiple random seeds and data splits; (ii) provide the complete hyperparameter grids and optimization procedure used for both the Hamming and fidelity kernels as well as the classical Gaussian baseline; (iii) detail all preprocessing steps applied to MNIST (including normalization and dimensionality reduction) and the exact circuit parameters for the synthetic quantum data; and (iv) state the precise functional form of the Hamming kernel, confirming it is the normalized inner product of the empirical measurement distributions. These additions will allow direct assessment of statistical significance and sensitivity. revision: yes
Circularity Check
No significant circularity; kernel defined by construction but claims rest on simulations
full rationale
The abstract defines the Hamming kernel explicitly as classical post-processing of the same measurement outcomes used by the fidelity kernel, but using the full statistics rather than a single fidelity value. This is a definitional choice that directly addresses the concentration issue by construction, yet the paper does not claim any first-principles derivation or prediction that reduces to its inputs. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems are referenced in the provided text. Performance superiority is asserted via simulations on MNIST and synthetic data up to 27 qubits, which are external to the definition itself. The derivation chain is therefore self-contained with no load-bearing reductions.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Hamming quantum kernel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Among these, the RBF kernel is particularly common in SVM classification
Classical Gaussian RBF kernel In classical kernel methods, mappings from the input space to a feature space are implicitly defined by positive- definite kernel functions, such as the linear, polynomial, and radial basis function (RBF) kernels [16]. Among these, the RBF kernel is particularly common in SVM classification. For two data pointsx i, xj in the ...
-
[2]
Standard fidelity quantum kernel In the quantum setting, feature maps are implemented by parameterized quantum circuitsU(x) that embed in- put dataxinto a Hilbert space: |ψ(x)⟩=U(x)|0⟩ ⊗n ,(2) where|0⟩ ⊗n denotes the all-zero computational basis state. Although various circuit architectures can serve as feature maps, highly entangling circuits are often p...
-
[3]
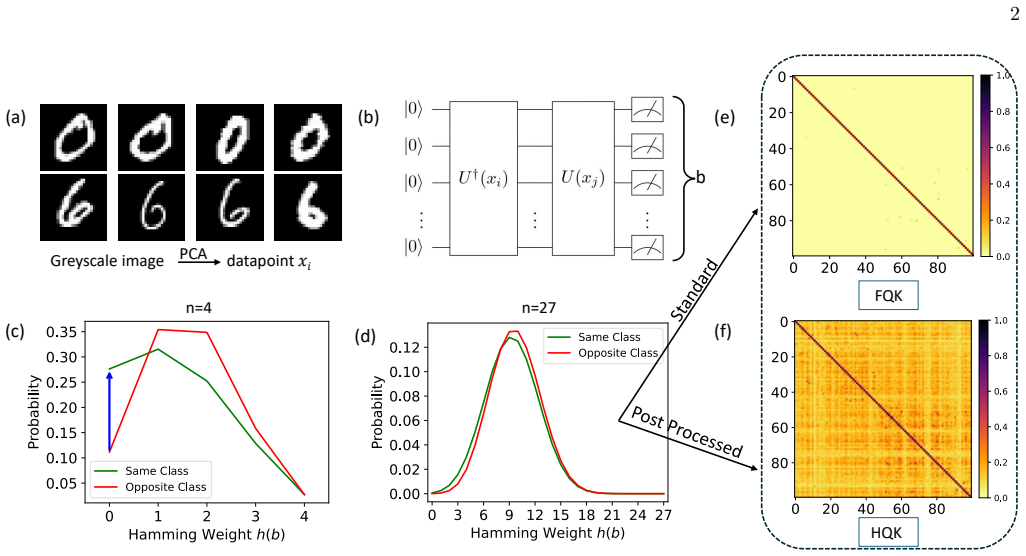
For empirical evaluation, the MNIST dataset is partitioned into three binary classi- fication tasks of increasing difficulty: •T ask 1:Distinguish between the digits0and1
Classical Dataset The classical datasets are based on the MNIST dataset [21], which consists of greyscale images of handwrit- ten digits from 0 to 9. For empirical evaluation, the MNIST dataset is partitioned into three binary classi- fication tasks of increasing difficulty: •T ask 1:Distinguish between the digits0and1. •T ask 2:Distinguish between the di...
-
[4]
memorizes
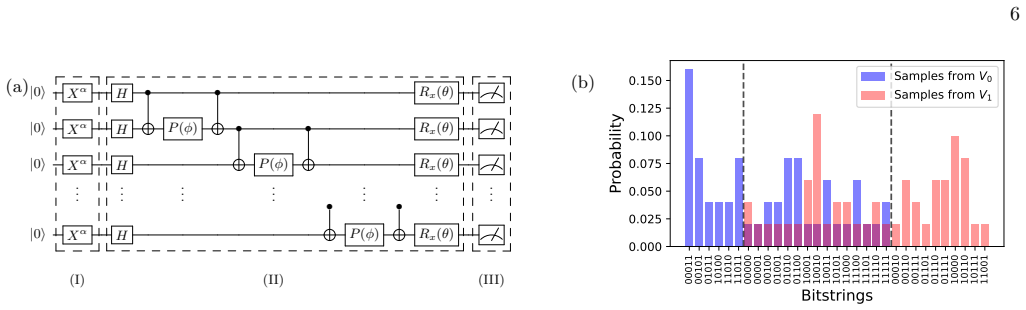
Quantum Dataset The second category of dataset used in this assessment is a synthetically generated quantum dataset (whereby we mean a classical dataset generated by a quantum de- vice). This dataset consists of binary bitstringsxpro- duced as measurement outcomes by one of two quantum circuitsV α, whereα= 0 or 1, see Fig. 2. The classifica- tion task is ...
-
[5]
The numbernof qubits re- quired to encode the data in the quantum kernels is equal to the dimensionality of each sample
is applied to reduce the dimensionality of the data from 784 to a range of 2 to 27 dimensions, enabling a systematic scaling analysis across all three kernel meth- ods: FQK, HQK, and RBF. The numbernof qubits re- quired to encode the data in the quantum kernels is equal to the dimensionality of each sample. For the quantum dataset, the dimensionality is d...
-
[6]
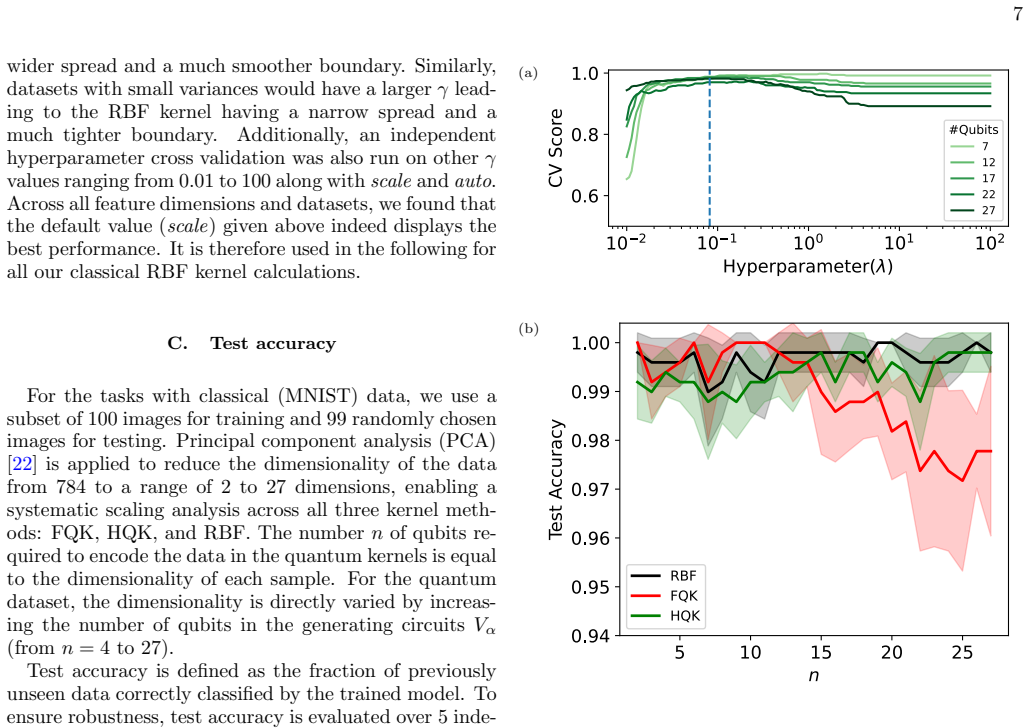
Kernel Quality for 0/1 First, we estimate the optimum value of the HQK hy- perparameterλ. Fig. 2(a) illustrates the cross-validation scores for qubit numbersn= 7,12,17,22 and 27 as a 10 2 10 1 100 101 102 Hyperparameter( ) 0.6 0.8 1.0CV Score #Qubits 7 12 17 22 27 (a) (b) FIG. 3. Comparison of test scores for classification of MNIST digits 0 and 1. (a) HQ...
-
[7]
This dataset also con- sists of 100 training and 99 test samples, comprising dig- its 0 and 6
Kernel Quality for 0/6 A similar binary classification is performed on a dataset of intermediate difficulty. This dataset also con- sists of 100 training and 99 test samples, comprising dig- its 0 and 6. We perform the same hyperparameter opti- mization to extract the optimal value ofλthat maximizes the cross-validation score, see Fig. 3(a). The cross-val...
-
[8]
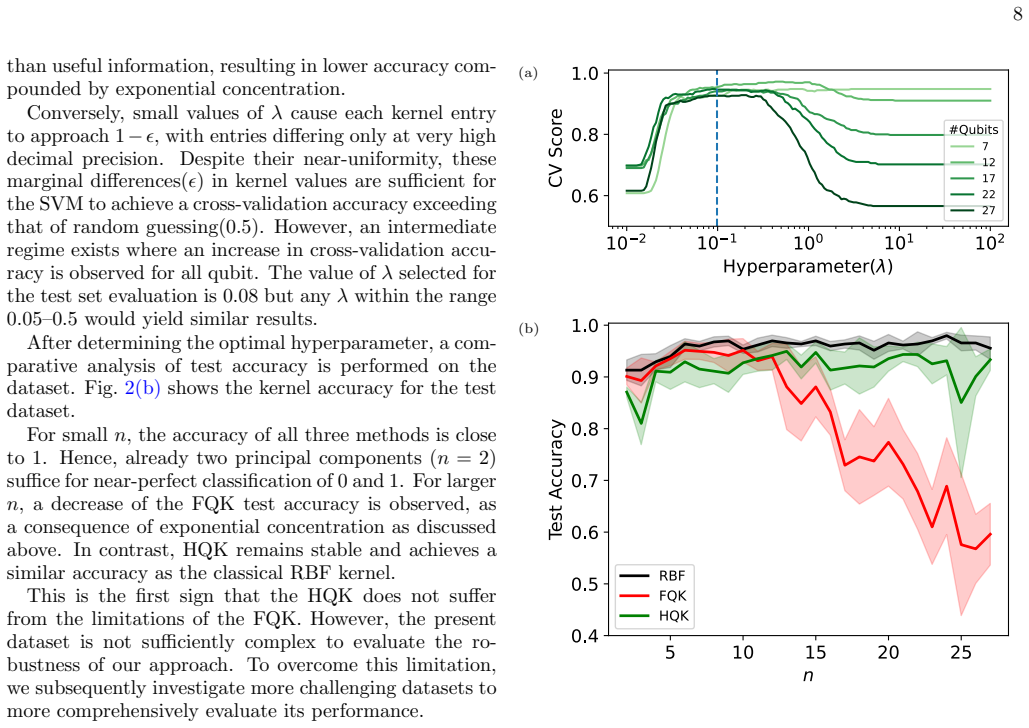
FQK accuracy drops for largern, whereas HQK remains relatively stable and almost reaches RBF performance, demonstrating higher robustness to noisy data than FQK
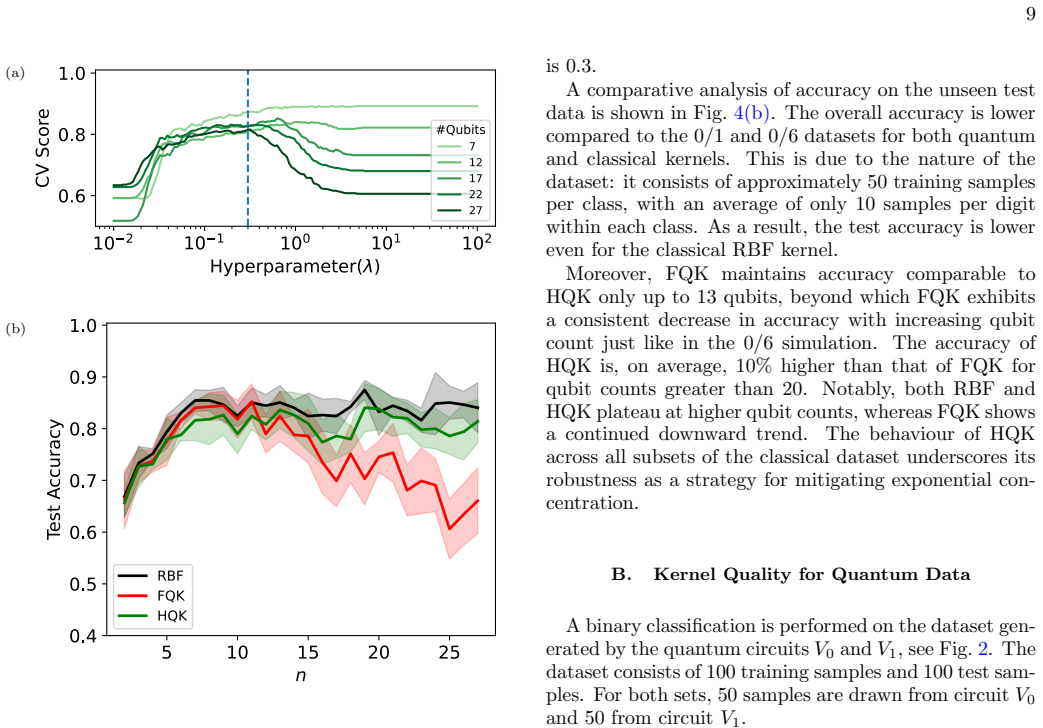
Beyondn= 8, additional dimensions introduce more noise than relevant information. FQK accuracy drops for largern, whereas HQK remains relatively stable and almost reaches RBF performance, demonstrating higher robustness to noisy data than FQK. of the FQK drops sharply, approaching a random guesser (corresponding to test accuracy 1/2) forn≥25 qubits. This ...
-
[9]
We would now like to analyze the behavior of all three kernels on the hardest classical dataset among the three
Kernel Quality for odd/even The behavior of the HQK kernel for the binary classifi- cation of 0/6 for large number of qubits exhibits a better performance than the standard FQK. We would now like to analyze the behavior of all three kernels on the hardest classical dataset among the three. We replicate the previous analysis by performing a hy- perparamete...
-
[10]
Noisy intermediate-scale quantum algorithms,
K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, W.-K. Mok, S. Sim, L.-C. Kwek, and A. Aspuru-Guzik, Noisy intermediate-scale quantum algorithms, Reviews of Modern Physics94, 10.1103/revmodphys.94.015004 (2022)
-
[11]
Rebentrost, M
P. Rebentrost, M. Mohseni, and S. Lloyd, Quantum sup- port vector machine for big data classification, Phys. Rev. Lett.113, 130503 (2014)
2014
-
[12]
Havl´ ıˇ cek, A
V. Havl´ ıˇ cek, A. D. C´ orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Super- vised learning with quantum-enhanced feature spaces, Nature567, 209–212 (2019)
2019
-
[13]
Schuld and N
M. Schuld and N. Killoran, Quantum machine learning in feature hilbert spaces, Phys. Rev. Lett.122, 040504 (2019)
2019
-
[14]
Saini, P
S. Saini, P. Khosla, M. Kaur, and G. Singh, Quantum driven machine learning, International Journal of Theo- retical Physics59(2020)
2020
-
[15]
J. Schnabel and M. Roth, Quantum kernel methods un- der scrutiny: a benchmarking study, Quantum Machine Intelligence7, 10.1007/s42484-025-00273-5 (2025)
-
[16]
Y. Liu, S. Arunachalam, and K. Temme, A rigorous and robust quantum speed-up in supervised machine learn- ing, Nature Physics17, 1013–1017 (2021)
2021
-
[17]
S. Thanasilp, S. Wang, M. Cerezo, and Z. Holmes, Expo- nential concentration in quantum kernel methods (2024), arXiv:2208.11060 [quant-ph]
arXiv 2024
- [18]
-
[19]
H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Power of data in quantum machine learning, Nature Communications12, 10.1038/s41467-021-22539-9 (2021)
-
[20]
L. Slattery, R. Shaydulin, S. Chakrabarti, M. Pistoia, S. Khairy, and S. M. Wild, Numerical evidence against advantage with quantum fidelity kernels on classical data, Physical Review A107, 10.1103/physreva.107.062417 (2023)
-
[21]
G. Agliardi, G. Cortiana, A. Dekusar, K. Ghosh, N. Mohseni, C. O’Meara, V. Valls, K. Yogaraj, and S. Zhuk, Mitigating exponential concentration in covari- ant quantum kernels for subspace and real-world data (2024), arXiv:2412.07915 [quant-ph]
arXiv 2024
-
[22]
V. Belis, K. A. Wo´ zniak, E. Puljak, P. Barkoutsos, G. Dissertori, M. Grossi, M. Pierini, F. Reiter, I. Tav- ernelli, and S. Vallecorsa, Quantum anomaly detection in the latent space of proton collision events at the lhc, Communications Physics7, 10.1038/s42005-024-01811-6 (2024)
-
[23]
T. Hofmann, B. Sch¨ olkopf, and A. J. Smola, Kernel meth- ods in machine learning, The Annals of Statistics36, 10.1214/009053607000000677 (2008)
-
[24]
H. Q. Minh, P. Niyogi, and Y. Yao, Mercer’s theorem, fea- ture maps, and smoothing, inLearning Theory, edited by G. Lugosi and H. U. Simon (Springer Berlin Heidelberg, Berlin, Heidelberg, 2006) pp. 154–168
2006
-
[25]
C. E. Rasmussen and C. K. I. Williams,Gaussian Pro- cesses for Machine Learning(The MIT Press, 2006)
2006
-
[26]
S. Aminpour, Y. Banad, and S. Sharif, Strategic data re- 12 uploads: A pathway to improved quantum classification data re-uploading strategies for improved quantum clas- sifier performance (2024), arXiv:2405.09377 [quant-ph]
arXiv 2024
-
[27]
A. Barenco, A. Berthiaume, D. Deutsch, A. Ekert, R. Jozsa, and C. Macchiavello, Stabilisation of quantum computations by symmetrisation (1996), arXiv:quant- ph/9604028 [quant-ph]
arXiv 1996
-
[28]
Cristianini, J
N. Cristianini, J. Shawe-Taylor, A. Elisseeff, and J. Kan- dola, On kernel-target alignment, inAdvances in Neu- ral Information Processing Systems, Vol. 14, edited by T. Dietterich, S. Becker, and Z. Ghahramani (MIT Press, 2001)
2001
-
[29]
Larocca, S
M. Larocca, S. Thanasilp, S. Wang, K. Sharma, J. Bia- monte, P. J. Coles, L. Cincio, J. R. McClean, Z. Holmes, and M. Cerezo, Barren plateaus in variational quantum computing, Nature Reviews Physics7, 174 (2025)
2025
-
[30]
Deng, The mnist database of handwritten digit images for machine learning research [best of the web], IEEE Signal Processing Magazine29, 141 (2012)
L. Deng, The mnist database of handwritten digit images for machine learning research [best of the web], IEEE Signal Processing Magazine29, 141 (2012)
2012
-
[31]
Ma´ ckiewicz and W
A. Ma´ ckiewicz and W. Ratajczak, Principal components analysis (pca), Computers & Geosciences19, 303 (1993)
1993
-
[32]
V. W. Lumumba, D. Kiprotich, M. L. Mpaine, N. G. Makena, and M. D. Kavita, Comparative analysis of cross-validation techniques: Loocv, k-folds cross- validation, and repeated k-folds cross-validation in ma- chine learning models, American Journal of Theoretical and Applied Statistics13, 127 (2024)
2024
-
[33]
H. F. Inman and E. L. B. Jr, The overlapping co- efficient as a measure of agreement between proba- bility distributions and point estimation of the over- lap of two normal densities, Communications in Statistics - Theory and Methods18, 3851 (1989), https://doi.org/10.1080/03610928908830127
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.