FairTutor: Equity-Aware Pedagogical LLM Routing for Budget-Constrained AI Tutoring
Pith reviewed 2026-06-27 01:27 UTC · model grok-4.3
The pith
FairTutor routes AI tutoring queries through cheap models plus critique to reach 97 percent of premium quality at 28 percent of the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
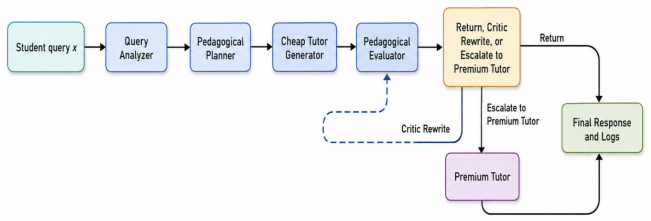
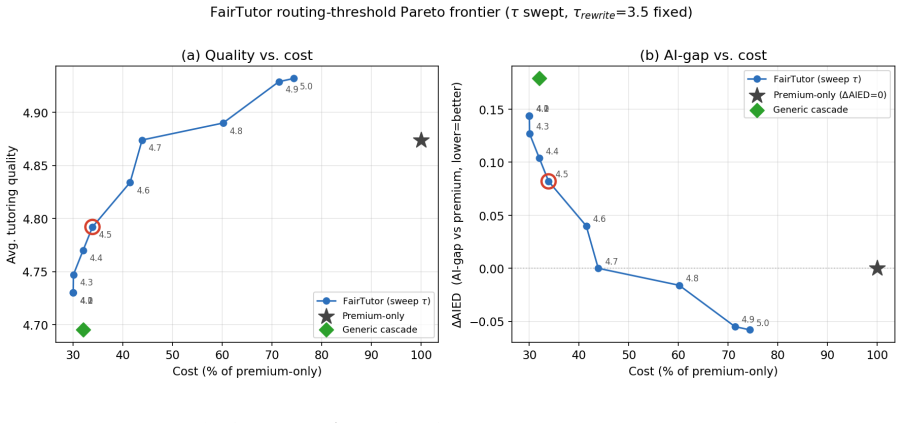
FairTutor is an equity-aware model-routing framework that combines query analysis, pedagogical planning, low-cost model generation, evaluator-guided critique and revision, and selective escalation to premium models. On the TutorAccessEval benchmark it achieves 97.1 percent of premium pedagogical quality in the floor-adjusted Likert scale while reducing serving cost by 71.6 percent, thereby narrowing the access-tier AIED Advantage Gap between premium and budget-constrained tutoring.
What carries the argument
The multi-agent orchestration pipeline that performs query analysis, pedagogical planning, low-cost generation, evaluator-guided critique and revision, then selective escalation.
If this is right
- Budget-constrained tutoring can reach nearly the same pedagogical quality as premium access across the tested subjects.
- The cost-quality tradeoff can be tuned along a Pareto frontier to match different student population needs.
- The AIED Advantage Gap metric can be used to quantify and track equity improvements in AI tutoring deployments.
- Selective escalation reduces average serving cost without requiring every query to use the most expensive model.
Where Pith is reading between the lines
- The same routing pattern could be tested in non-education LLM tasks where cost and output quality must be balanced.
- Platforms could expose the tunable frontier as a user or administrator setting rather than a fixed policy.
- Longer-term student outcome studies would be needed to check whether the measured quality gap translates to learning differences.
Load-bearing premise
The floor-adjusted Likert scale and TutorAccessEval benchmark provide an unbiased measure of pedagogical quality that is not systematically favored by the evaluator-guided critique step.
What would settle it
A blinded side-by-side human rating of tutoring sessions on the same queries, one produced by FairTutor and one by direct premium-model use, that shows the quality gap is materially larger than the reported 2.9 percent.
Figures
read the original abstract
Generative AI tutors provide real-time, personalized learning support, but also create a new education inequity: students with access to premium AI services may receive clearer explanations, more personalized guidance, and better scaffolding than students limited to free or low-cost services. To address this challenge, we propose FairTutor, an equity-aware model-routing framework that achieves cost-effective AI tutoring via pedagogically motivated multi-agent orchestration. FairTutor combines query analysis, pedagogical planning, low-cost model generation, evaluator-guided critique and revision, and selective escalation to premium AI models. We introduce access-tier AI Education (AIED) Advantage Gap to measure the quality difference between premium-access and budget-constrained tutoring, and TutorAccessEval, a benchmark spanning math, reading, writing, science, and language learning. Empirical evaluations show that FairTutor achieves 97.1% of premium pedagogical quality (in floor-adjusted Likert scale) while reducing serving cost by 71.6%. Sensitivity analysis reveals a tunable cost--quality Pareto frontier, enabling FairTutor to be tailored to the needs of diverse student populations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FairTutor, an equity-aware LLM routing framework for budget-constrained AI tutoring. It employs multi-agent orchestration (query analysis, pedagogical planning, low-cost generation, evaluator-guided critique/revision, and selective premium escalation), introduces the AIED Advantage Gap metric and TutorAccessEval benchmark (spanning math, reading, writing, science, language learning), and reports that the system attains 97.1% of premium pedagogical quality on a floor-adjusted Likert scale at 71.6% lower serving cost, with a tunable cost-quality Pareto frontier.
Significance. If the evaluation protocol and custom metrics prove robust, the work could offer a practical approach to mitigating access-tier inequities in AI education tools. The introduction of a domain-specific benchmark and explicit cost-quality trade-off analysis would be a constructive contribution to AIED research, provided the results are reproducible and free of self-referential bias.
major comments (2)
- [Abstract] Abstract: The headline empirical claim (97.1% of premium quality at 71.6% cost reduction) is presented without any description of the underlying LLMs, evaluation protocol, statistical controls, inter-rater reliability, or safeguards against post-hoc model selection. This absence renders the central performance numbers impossible to interpret or replicate.
- [Abstract] Abstract (and implied evaluation section): TutorAccessEval and the floor-adjusted Likert scale are author-introduced constructs whose validity is not supported by external benchmarks, ablation of the evaluator-guided critique step, or evidence that the metric does not systematically favor outputs from the proposed multi-agent pipeline. Without such validation, the reported quality equivalence cannot be taken as unbiased.
minor comments (1)
- [Abstract] The abstract refers to a 'sensitivity analysis' and 'tunable Pareto frontier' but supplies no quantitative details on the sensitivity parameters or frontier points.
Simulated Author's Rebuttal
We thank the referee for highlighting issues of interpretability and validation in our abstract and evaluation design. The full manuscript contains the requested details in the evaluation sections, but we agree the abstract should be expanded for self-containment. We address each comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline empirical claim (97.1% of premium quality at 71.6% cost reduction) is presented without any description of the underlying LLMs, evaluation protocol, statistical controls, inter-rater reliability, or safeguards against post-hoc model selection. This absence renders the central performance numbers impossible to interpret or replicate.
Authors: The abstract is constrained by length, but the manuscript specifies the LLMs and routing logic in Section 3, the full evaluation protocol (including human rating procedures and cost measurement) in Section 4, statistical reporting in Section 4.3, and fixed model versions with no post-hoc selection. We will revise the abstract to include a concise description of the models, protocol, and controls to improve standalone interpretability. revision: yes
-
Referee: [Abstract] Abstract (and implied evaluation section): TutorAccessEval and the floor-adjusted Likert scale are author-introduced constructs whose validity is not supported by external benchmarks, ablation of the evaluator-guided critique step, or evidence that the metric does not systematically favor outputs from the proposed multi-agent pipeline. Without such validation, the reported quality equivalence cannot be taken as unbiased.
Authors: TutorAccessEval and the floor-adjusted Likert scale are motivated and justified against pedagogical literature in Sections 3.3 and 4.1, with internal consistency checks via expert ratings. As novel constructs, external benchmarks are not yet available, but we provide comparative analysis against standard metrics. We did not include an explicit ablation of the critique/revision step; we agree this would strengthen the claims and will add it. The evaluation uses blinded raters and the floor adjustment is intended to reduce bias, but we will expand the discussion of potential pipeline favoritism in the revision. revision: partial
Circularity Check
No circularity: empirical outcomes on introduced benchmark do not reduce to self-definition or fitted inputs
full rationale
The paper reports direct empirical results (97.1% quality retention at 71.6% cost reduction) measured on the author-introduced TutorAccessEval benchmark and floor-adjusted Likert scale. No equations, derivations, or self-citations are shown that would make the reported percentages equivalent to inputs by construction. The evaluation pipeline and metrics are presented as measurement tools rather than tautological redefinitions of the routing performance itself. This is a standard case of a self-contained empirical claim against its own benchmark, warranting score 0 under the rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Wang, T. Xu, H. Li, C. Zhang, J. Liang, J. Tang, P. S. Yu, and Q. Wen. Large language mod- els for education: A survey and outlook.IEEE Signal Processing Magazine, 42(6):51–63, 2025. arXiv:2403.18105. doi:10.1109/MSP.2025.3594309
-
[2]
Z. Chu, S. Wang, J. Xie, T. Zhu, Y. Yan, J. Ye, A. Zhong, X. Hu, J. Liang, P. S. Yu, and Q. Wen. LLM agents for education: Advances and applications. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 13782–13810, 2025. arXiv:2503.11733
arXiv 2025
-
[3]
L. Chen, M. Zaharia, and J. Zou. FrugalGPT: How to use large language models while reducing cost and improving performance.Transactions on Machine Learning Research, 2024
2024
-
[4]
I. Ong, A. Almahairi, V. Wu, W.-L. Chiang, T. Wu, J. E. Gonzalez, M. W. Kadous, and I. Stoica. RouteLLM: Learning to route LLMs with preference data. arXiv preprint arXiv:2406.18665, 2024
Pith/arXiv arXiv 2024
-
[5]
J. Dekoninck, M. Baader, and M. Vechev. A unified approach to routing and cascading for LLMs. InProceedings of the 42nd International Conference on Machine Learning, 2025. arXiv:2410.10347
arXiv 2025
-
[6]
ChatGPT for good? On opportunities and challenges of large language models for education,
E. Kasneci, K. Seßler, S. Küchemann, M. Bannert, D. Dementieva, F. Fischer, U. Gasser, G. Groh, S. Günnemann, E. Hüllermeier, S. Krusche, G. Kutyniok, T. Michaeli, C. Nerdel, J. Pfeffer, O. Poquet, M. Sailer, A. Schmidt, T. Seidel, M. Stadler, J. Weller, J. Kuhn, and G. Kasneci. ChatGPT for good? On opportunities and challenges of large language models fo...
-
[7]
J. Lee, Y. Hicke, R. Yu, C. Brooks, and R. F. Kizilcec. The life cycle of large language models in education: A framework for understanding sources of bias.British Journal of Educational Technology, 55(5):1982–2002, 2024. doi:10.1111/bjet.13505
-
[8]
I. Delikoura, Y. R. Fung, and P. Hui. From superficial outputs to superficial learning: Risks of large language models in education. arXiv preprint arXiv:2509.21972, 2025
arXiv 2025
-
[9]
W. Holmes, K. Porayska-Pomsta, K. Holstein, E. Sutherland, T. Baker, S. B. Shum, O. C. Santos, M. T. Rodrigo, M. Cukurova, I. I. Bittencourt, and K. R. Koedinger. Ethics of AI in education: Towards a community-wide framework.International Journal of Artificial Intelligence in Education, 32(3):504–526, 2022. doi:10.1007/s40593-021-00239-1
-
[10]
B. S. Bloom. The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring.Educational Researcher, 13(6):4–16, 1984. doi:10.3102/0013189X013006004
-
[11]
K. VanLehn. The relative effectiveness of human tutoring, intelligent tutoring systems, and other tutoring systems.Educational Psychologist, 46(4):197–221, 2011. doi:10.1080/00461520.2011.611369
-
[12]
Warschauer.Technology and Social Inclusion: Rethinking the Digital Divide
M. Warschauer.Technology and Social Inclusion: Rethinking the Digital Divide. MIT Press, 2003
2003
-
[13]
J. D. Hansen and J. Reich. Democratizing education? Examining access and usage patterns in massive open online courses.Science, 350(6265):1245–1248, 2015. doi:10.1126/science.aab3782
-
[14]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
Pith/arXiv arXiv 2025
-
[15]
Qwen: Qwen3 8B — API pricing and providers.OpenRouter Model Pricing Page, 2026
OpenRouter. Qwen: Qwen3 8B — API pricing and providers.OpenRouter Model Pricing Page, 2026. https://openrouter.ai/qwen/qwen3-8b. Accessed May 7, 2026. Listed pricing: $0.05 per million input tokens and $0.40 per million output tokens
2026
-
[16]
GPT-5 system card.OpenAI Technical Report, 2025
OpenAI. GPT-5 system card.OpenAI Technical Report, 2025. https://openai.com/index/ gpt-5-system-card/. Published August 13, 2025
2025
-
[17]
id": "math_001
OpenAI. OpenAI API pricing.OpenAI API Documentation, 2026. https://openai.com/api/pricing/. Accessed May 7, 2026. Listed prices are per million tokens and may change over time. A. Pedagogical Evaluation Rubric Table 3 Evaluator dimensions used to estimate pedagogical quality. All dimensions are estimated on a Likert scale from 1 to 5. Dimension Descriptio...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.