Revisiting Pre-Propagation GNNs: Robust Diffusion Operators and Hidden-State Re-Propagation
Pith reviewed 2026-06-30 12:04 UTC · model grok-4.3
The pith
Robust diffusion operators and hidden-state re-propagation let pre-propagation GNNs match message-passing accuracy without losing efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Replacing standard diffusion with robust operators and inserting limited hidden-state re-propagation during training raises pre-propagation GNN validation and test accuracy to match that of message-passing GNNs across common benchmarks.
What carries the argument
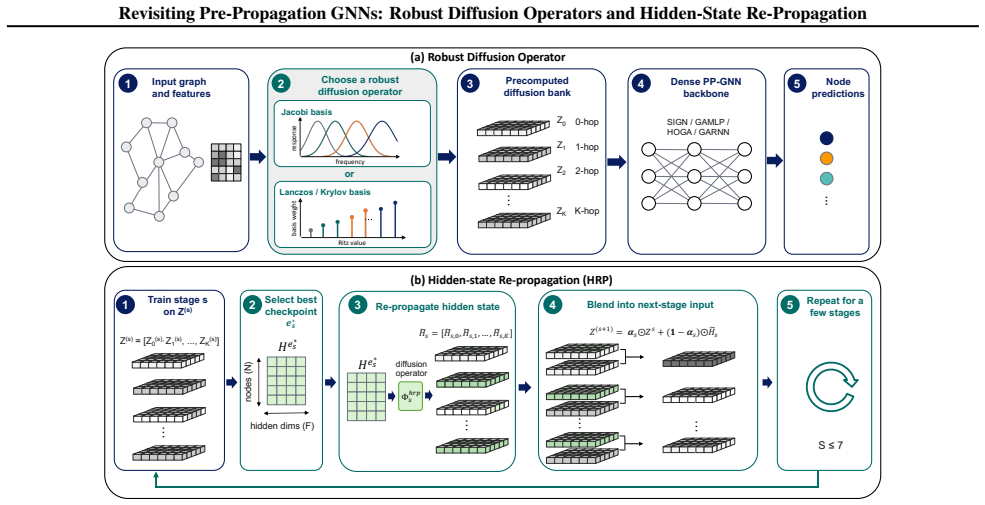
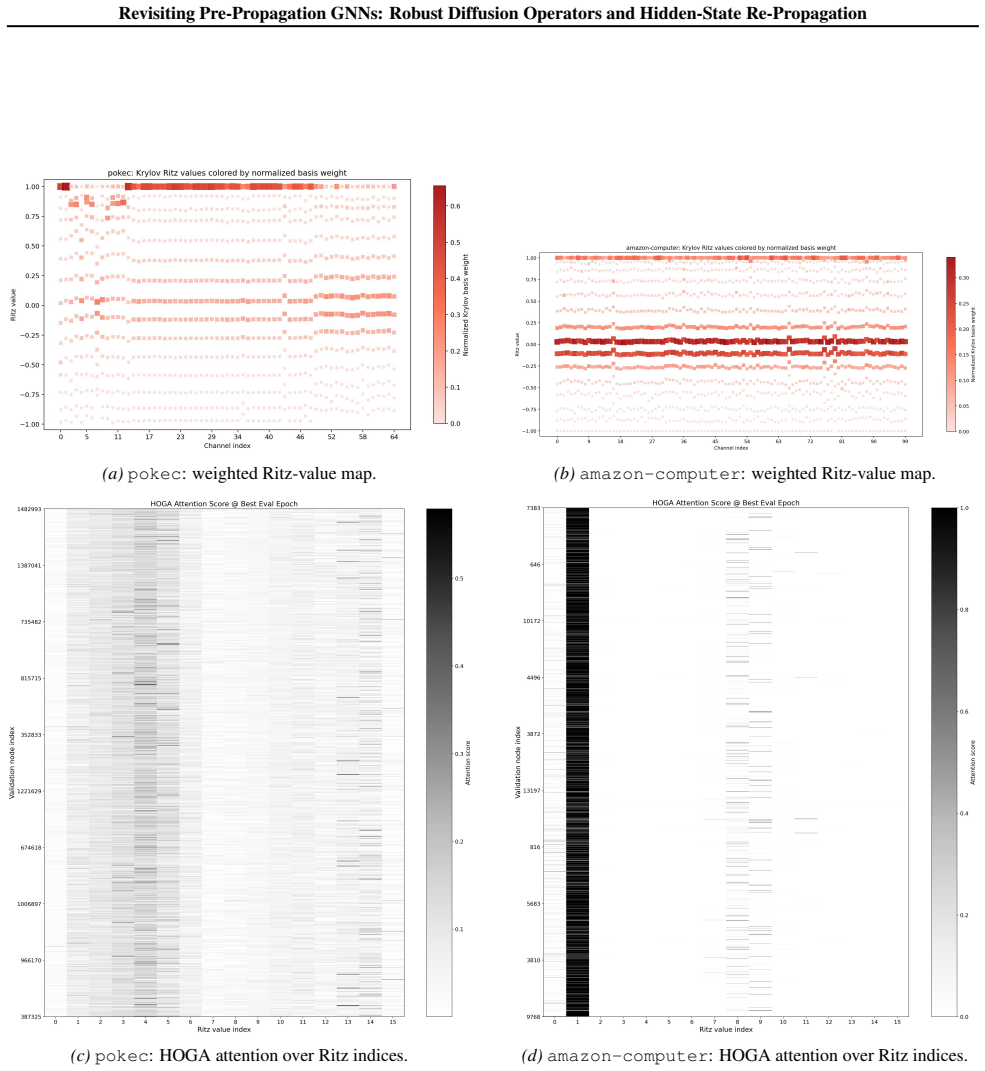
Robust graph diffusion operators for preprocessing plus a few-shot hidden-state re-propagation scheme during training.
If this is right
- PPGNNs become competitive on heterophilic graphs without sacrificing mini-batch training or accelerator-friendly dense compute.
- The preprocessing diffusion step can be made more stable by the choice of robust operators.
- Limited hidden-state re-propagation adds expressivity at low extra cost compared with full message-passing.
- Training pipelines that already use pre-propagation can adopt the new operators and scheme with only small changes to the training loop.
Where Pith is reading between the lines
- The same robust operators might improve other decoupled architectures that rely on a single preprocessing diffusion pass.
- Varying the number of re-propagation shots could trade off accuracy against training cost in a controllable way.
- The approach may reduce the need for full message-passing when graphs are processed at scale on dense-optimized hardware.
Load-bearing premise
The accuracy gains from the robust operators and re-propagation will continue to hold on graphs outside the tested benchmarks and will not create new failure modes on heterophilic data.
What would settle it
Evaluating the method on an unseen collection of heterophilic graphs and checking whether test accuracy stays equal to message-passing baselines while training time and memory remain lower.
Figures

read the original abstract
Pre-propagation graph neural networks (PPGNNs) decouple node feature propagation from transformation: graph diffusion is performed once as preprocessing, and training reduces to dense per-node transformations. This design enables mini-batch training without inter-node dependencies, avoids repeated sparse matrix--matrix multiplications, and better matches modern accelerators optimized for dense compute. However, their expressivity remains unclear, and empirical results show a gap between PPGNNs and their message-passing counterparts on commonly used graph benchmarks, especially heterophilic ones. In this paper, we propose a suite of robust graph diffusion operators for preprocessing and a few-shot hidden-state re-propagation scheme during training. Our methods improve the validation and test accuracy of PPGNNs, enabling them to match the accuracy of message-passing GNNs while maintaining training efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a suite of robust graph diffusion operators for preprocessing combined with a few-shot hidden-state re-propagation scheme during training improves the validation and test accuracy of pre-propagation GNNs (PPGNNs) to match that of message-passing GNNs (especially on heterophilic graphs) while preserving the training efficiency advantages of the PPGNN design.
Significance. If the empirical claims hold with the efficiency preserved, the work would be significant because it would narrow the expressivity gap that has limited adoption of PPGNNs, offering a path to accurate yet scalable GNN training that exploits dense compute on modern accelerators without repeated sparse operations.
major comments (2)
- Abstract: the central claim that the proposed methods 'improve the validation and test accuracy of PPGNNs, enabling them to match the accuracy of message-passing GNNs while maintaining training efficiency' is asserted without any supporting data, error bars, method details, or quantitative efficiency measurements, so the soundness of the result cannot be evaluated from the provided text.
- Abstract (re-propagation scheme): the few-shot hidden-state re-propagation is claimed to maintain training efficiency, but no bound is given on the number of shots or the resulting overhead; because any re-propagation necessarily performs inter-node operations (sparse matrix-vector products or equivalent) inside the training loop, this directly conflicts with the stated PPGNN benefits of one-time preprocessing followed by purely dense per-node transformations with no inter-node dependencies at train time, which is load-bearing for the overall claim.
minor comments (1)
- Abstract: the phrase 'few-shot' is introduced without a definition or citation to prior usage in the GNN literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and planned revisions.
read point-by-point responses
-
Referee: Abstract: the central claim that the proposed methods 'improve the validation and test accuracy of PPGNNs, enabling them to match the accuracy of message-passing GNNs while maintaining training efficiency' is asserted without any supporting data, error bars, method details, or quantitative efficiency measurements, so the soundness of the result cannot be evaluated from the provided text.
Authors: Abstracts are concise summaries by design and do not include full quantitative details. The full manuscript provides all supporting data, error bars across runs, method descriptions, and efficiency measurements in the experimental sections. We will revise the abstract to include a brief reference to the empirical results (e.g., 'as shown in extensive experiments') for better context while respecting length limits. revision: yes
-
Referee: Abstract (re-propagation scheme): the few-shot hidden-state re-propagation is claimed to maintain training efficiency, but no bound is given on the number of shots or the resulting overhead; because any re-propagation necessarily performs inter-node operations (sparse matrix-vector products or equivalent) inside the training loop, this directly conflicts with the stated PPGNN benefits of one-time preprocessing followed by purely dense per-node transformations with no inter-node dependencies at train time, which is load-bearing for the overall claim.
Authors: The few-shot scheme applies re-propagation only a limited number of times (specified in the method section) at selected epochs rather than every step, preserving the one-time preprocessing core while adding minimal overhead, as quantified in runtime tables. We acknowledge the introduction of occasional sparse operations and will revise to explicitly state the bound on shots (e.g., at most a small constant per run) and discuss the resulting efficiency trade-off to eliminate any perceived conflict. revision: yes
Circularity Check
No significant circularity; empirical proposal without self-referential derivations
full rationale
The paper proposes new robust diffusion operators for preprocessing and a few-shot hidden-state re-propagation scheme, claiming empirical accuracy gains on benchmarks while preserving PPGNN training efficiency. No equations, mathematical derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or described text. Central claims rest on external validation against message-passing GNNs rather than reducing to inputs by construction, self-definition, or ansatz smuggling. This is the expected honest outcome for an applied methods paper without a closed derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SIGN: Scalable Inception Graph Neural Networks.arXiv preprint arXiv:2004.11198,
Frasca, F., Rossi, E., Eynard, D., Chamberlain, B., Bron- stein, M., and Monti, F. SIGN: Scalable Inception Graph Neural Networks.arXiv preprint arXiv:2004.11198,
-
[2]
Revisiting Graph Neural Networks: All We Have is Low-Pass Filters
Nt, H. and Maehara, T. Revisiting Graph Neural Net- works: All We Have Is Low-Pass Filters.arXiv preprint arXiv:1905.09550,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[3]
Pitfalls of Graph Neural Network Evaluation
Shchur, O., Mumme, M., Bojchevski, A., and G¨unnemann, S. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Bag of tricks for node classification with graph neural networks.arXiv preprint arXiv:2103.13355,
Wang, Y ., Jin, J., Zhang, W., Yu, Y ., Zhang, Z., and Wipf, D. Bag of tricks for node classification with graph neural networks.arXiv preprint arXiv:2103.13355,
-
[5]
For the four homophilic datasets amazon-comput er, amazon-photo, coauthor-cs, and coauthor-physics, we report mean ± standard deviation over random splits
Split protocol.We follow the standard split protocol for each dataset. For the four homophilic datasets amazon-comput er, amazon-photo, coauthor-cs, and coauthor-physics, we report mean ± standard deviation over random splits. All other datasets use their fixed public splits. B. Hardware settings For the training efficiency study, we use a Linux server wi...
2025
-
[6]
We use the accuracy numbers reported in the original baseline papers and the benchmarking study of Platonov et al. (2023). For baselines without publicly available results on a given dataset, we tune hyperparameters using the search spaces in Table
2023
-
[7]
13 Revisiting Pre-Propagation GNNs: Robust Diffusion Operators and Hidden-State Re-Propagation Table 10.Hyperparameter tuning settings for baseline models without publicly available results on given datasets. Model Fixed hyperparameters Tuned hyperparameters (search space) GCNII Hidden dim512; LR0.001; epochs2000Layers{5,10}; dropout{0.3,0.5,0.7};α∈ {0.3,...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.