Objects Before Words: Object-First Inductive Biases for Grounding Language in Child-View Video
Pith reviewed 2026-06-27 07:24 UTC · model grok-4.3
The pith
BabyMind grounds words in child-view video by aligning sparse utterances to tracked object files instead of whole frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
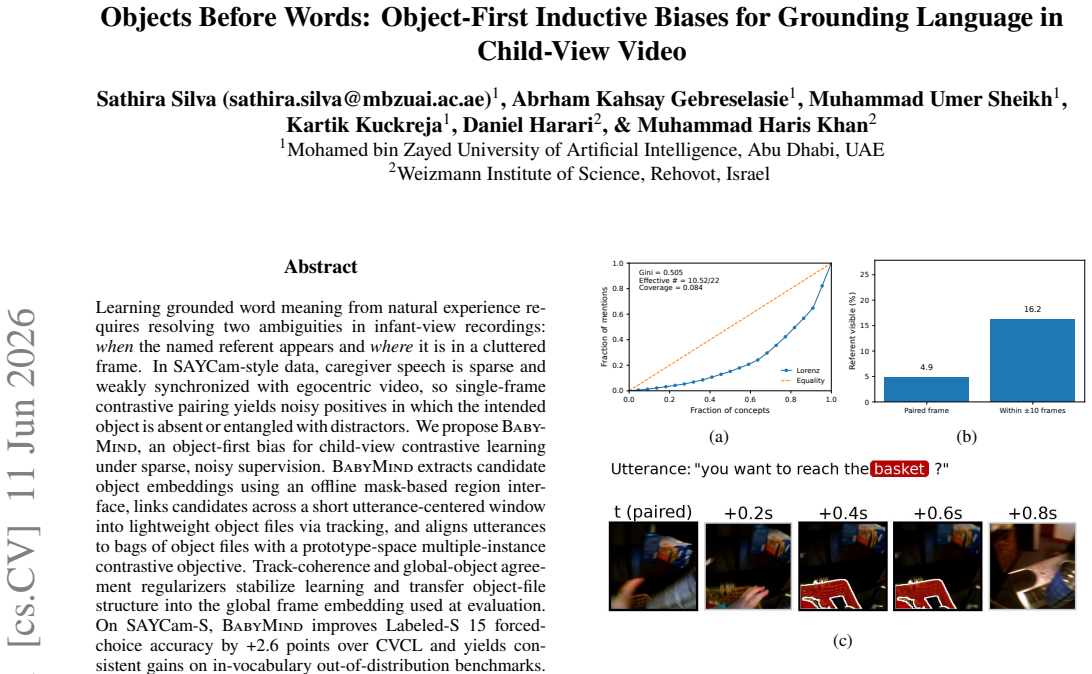
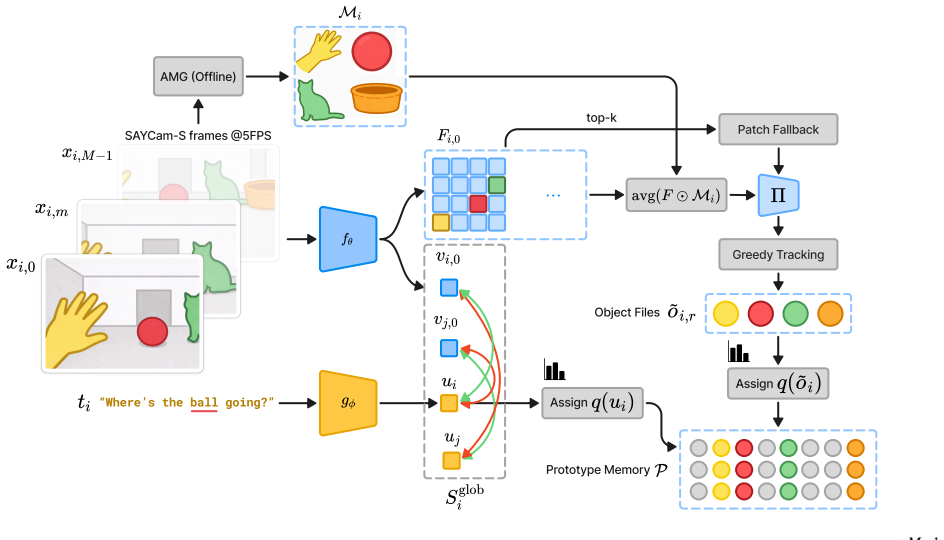
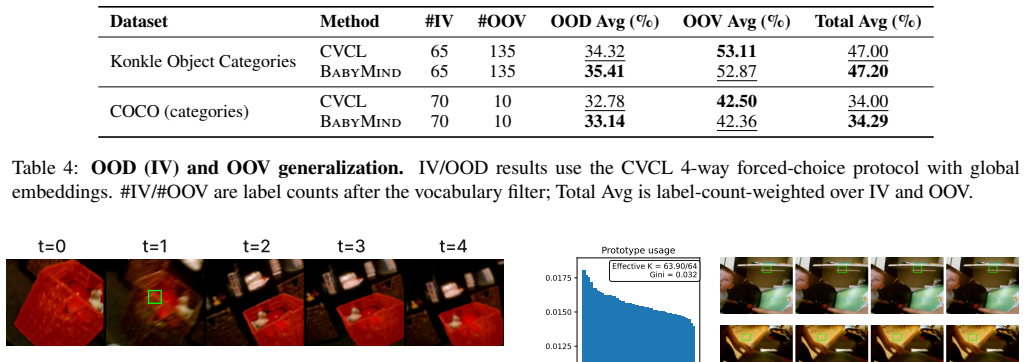
BabyMind extracts candidate object embeddings using an offline mask-based region interface, links candidates across a short utterance-centered window into lightweight object files via tracking, and aligns utterances to bags of object files with a prototype-space multiple-instance contrastive objective. Track-coherence and global-object agreement regularizers stabilize learning and transfer object-file structure into the global frame embedding used at evaluation. On SAYCam-S, BabyMind improves Labeled-S 15 forced-choice accuracy by +2.6 points over CVCL and yields consistent gains on in-vocabulary out-of-distribution benchmarks.
What carries the argument
Object-file construction, which uses offline mask proposals and short-term tracking to create stable visual units that serve as positives for multiple-instance contrastive alignment under noisy, sparse speech supervision.
If this is right
- Yields a 2.6-point accuracy increase on labeled forced-choice word grounding tasks in child-view data.
- Produces consistent gains on in-vocabulary out-of-distribution benchmarks.
- Stabilizes training via track-coherence and global-object agreement regularizers.
- Transfers object-file structure into the global frame embedding used at test time.
Where Pith is reading between the lines
- Visual object segmentation and tracking priors may matter more than linguistic structure for early grounded word learning models.
- Bag-of-objects representations could improve robustness in other video-language tasks that have only weak temporal alignment.
- The method implies that object permanence-like representations help resolve referential ambiguity when speech-visual synchrony is low.
Load-bearing premise
Mask-based region proposals plus short-term tracking can reliably isolate the intended referent of a spoken word even when that object is absent or entangled with distractors across most frames in the utterance window.
What would settle it
An ablation that replaces the tracked object files with either random crops or full-frame embeddings and measures whether the +2.6 point accuracy gain on the SAYCam-S Labeled-S 15 forced-choice task disappears.
Figures

read the original abstract
Learning grounded word meaning from natural experience requires resolving two ambiguities in infant-view recordings: when the named referent appears and where it is in a cluttered frame. In SAYCam-style data, caregiver speech is sparse and weakly synchronized with egocentric video, so single-frame contrastive pairing yields noisy positives in which the intended object is absent or entangled with distractors. We propose BabyMind, an object-first bias for child-view contrastive learning under sparse, noisy supervision. BabyMind extracts candidate object embeddings using an offline mask-based region interface, links candidates across a short utterance-centered window into lightweight object files via tracking, and aligns utterances to bags of object files with a prototype-space multiple-instance contrastive objective. Track-coherence and global-object agreement regularizers stabilize learning and transfer object-file structure into the global frame embedding used at evaluation. On SAYCam-S, BabyMind improves Labeled-S 15 forced-choice accuracy by +2.6 points over CVCL and yields consistent gains on in-vocabulary out-of-distribution benchmarks. Code is available at https://github.com/sathiiii/BabyMind.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BabyMind, an object-first approach to contrastive learning for grounding language in egocentric child-view video (SAYCam-style data). It extracts object embeddings via offline mask-based region proposals, links them across short utterance windows into object files using tracking, and trains with a prototype-space multiple-instance contrastive loss plus track-coherence and global-object agreement regularizers. The central empirical claim is a +2.6 point gain in Labeled-S 15 forced-choice accuracy over CVCL on SAYCam-S, together with consistent gains on in-vocabulary OOD benchmarks.
Significance. If the reported gains prove robust, the work supplies concrete evidence that object-centric inductive biases can reduce the impact of sparse, weakly synchronized supervision in visual grounding, a setting that directly models challenges in infant language acquisition. The availability of code is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the +2.6 point gain and OOD improvements rest on the assumption that offline mask-based proposals plus short-term tracking produce object files whose visual content reliably matches the sparsely uttered referent. No analysis, ablation, or failure-case quantification is supplied for frames in which the named object is absent or entangled with distractors; if tracking drifts or masks select incorrect entities, the multiple-instance objective receives systematically noisy positives and the claimed object-first advantage collapses to standard contrastive learning with extra preprocessing.
- [Abstract] Abstract / experimental protocol: no error bars, confidence intervals, or results across multiple data splits or hyperparameter settings are reported for the +2.6 point figure, so it is impossible to determine whether the improvement is robust or sensitive to the precise choice of mask model, tracker, or utterance window length.
minor comments (1)
- [Abstract] Abstract: the description of the prototype-space multiple-instance contrastive objective and the two regularizers is too terse to allow immediate replication or to judge how they interact with the base contrastive term.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the robustness of our empirical claims. We address each major comment below and commit to revisions that directly target the identified gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the +2.6 point gain and OOD improvements rest on the assumption that offline mask-based proposals plus short-term tracking produce object files whose visual content reliably matches the sparsely uttered referent. No analysis, ablation, or failure-case quantification is supplied for frames in which the named object is absent or entangled with distractors; if tracking drifts or masks select incorrect entities, the multiple-instance objective receives systematically noisy positives and the claimed object-first advantage collapses to standard contrastive learning with extra preprocessing.
Authors: We agree that the absence of direct analysis on object-file reliability is a limitation. The consistent OOD gains provide indirect support, but do not substitute for explicit quantification. In the revised manuscript we will add (i) a failure-case study on a manually annotated subset of SAYCam-S frames quantifying how often the named referent is absent or entangled, (ii) an ablation that replaces the tracked object files with single-frame proposals, and (iii) a controlled perturbation of mask quality and tracking drift to measure degradation of the reported gains. These additions will clarify the conditions under which the object-first bias is effective. revision: yes
-
Referee: [Abstract] Abstract / experimental protocol: no error bars, confidence intervals, or results across multiple data splits or hyperparameter settings are reported for the +2.6 point figure, so it is impossible to determine whether the improvement is robust or sensitive to the precise choice of mask model, tracker, or utterance window length.
Authors: We acknowledge that single-run reporting limits assessment of robustness. In revision we will rerun the main SAYCam-S experiments across three random seeds and report means with standard deviations for the Labeled-S 15 metric. We will also add a sensitivity table varying utterance-window length (3–7 s) and mask-score threshold while keeping other factors fixed. Full cross-validation over multiple data splits is not feasible because SAYCam-S is a single fixed corpus; however, the hyperparameter sweeps and seed-averaged results will address the core concern about sensitivity. revision: partial
Circularity Check
No circularity: empirical method defined directly on inputs with externally measured gains
full rationale
The paper describes an empirical contrastive learning procedure whose core components (offline mask-based region proposals, short-term tracking into object files, prototype-space multiple-instance objective, and two regularizers) are defined directly in terms of the input video and utterance data. Reported accuracy improvements (+2.6 points on Labeled-S 15 forced-choice and OOD gains) are measured on held-out benchmarks and do not reduce to any fitted parameter renamed as a prediction or to a self-citation chain. The derivation chain is therefore self-contained against external evaluation; no load-bearing step collapses by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Benally, Camila D
August, Bingwen C. and Benally, Camila D. and Cadena, Daisuke E. , title =. Proceedings of the Annual Meeting of the Cognitive Science Society , volume =
-
[2]
and Echo, Fernando G
Daphne, Ellie F. and Echo, Fernando G. , title =
-
[3]
and Galli, Hind I
Fitzgerald, Guadalupe H. and Galli, Hind I. , title =
-
[4]
, title =
Hakuole, Indra J. , title =
-
[5]
, title =
Issa, Jin K. , title =. Example edited volume title , editor =
-
[6]
Example edited volume title , date =
-
[7]
and November, Olumide P
Mitanni, Nayeli O. and November, Olumide P. , title =
-
[8]
1982 , publisher =
Vision: A Computational Investigation into the Human Representation and Processing of Visual Information , author =. 1982 , publisher =
1982
-
[9]
Cognitive Science , year =
Principles of Object Perception , author =. Cognitive Science , year =
-
[10]
Cognitive Psychology , year =
Perception of Partly Occluded Objects in Infancy , author =. Cognitive Psychology , year =
-
[11]
Object permanence in 3
Baillargeon, Ren. Object permanence in 3. Developmental Psychology , year =
-
[12]
Cognitive Development , year =
The Importance of Shape in Early Lexical Learning , author =. Cognitive Development , year =
-
[13]
Cognition , year =
Naming in Young Children: A Dumb Attentional Mechanism? , author =. Cognition , year =
-
[14]
Psychological Science , year =
Learning to Recognize Objects , author =. Psychological Science , year =
-
[15]
Infant and Child Development , year =
Learning What to Remember: Vocabulary Knowledge and Children's Memory for Object Names and Features , author =. Infant and Child Development , year =
-
[16]
and Brendel, Wieland , booktitle =
Geirhos, Robert and Rubisch, Patricia and Michaelis, Claudio and Bethge, Matthias and Wichmann, Felix A. and Brendel, Wieland , booktitle =. ImageNet-trained. 2019 , note =
2019
-
[17]
Open Mind , year =
SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded From an Infant's Perspective , author =. Open Mind , year =
-
[18]
arXiv preprint arXiv:2304.02643 , year =
Segment Anything , author =. arXiv preprint arXiv:2304.02643 , year =
-
[19]
and Matthey, Loic and Watters, Nicholas and Kabra, Rishabh and Higgins, Irina and Botvinick, Matthew and Lerchner, Alexander , booktitle =
Burgess, Christopher P. and Matthey, Loic and Watters, Nicholas and Kabra, Rishabh and Higgins, Irina and Botvinick, Matthew and Lerchner, Alexander , booktitle =
-
[20]
Advances in Neural Information Processing Systems , year =
Object-Centric Learning with Slot Attention , author =. Advances in Neural Information Processing Systems , year =
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Perceptual Inductive Bias Is What You Need Before Contrastive Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[22]
Proceedings of the 37th International Conference on Machine Learning , series =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
2020
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Momentum Contrast for Unsupervised Visual Representation Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[24]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Unsupervised Feature Learning via Non-Parametric Instance Discrimination , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[25]
Cognitive Psychology , volume =
The Concept of Object Files: A Tool for Visual Cognition , author =. Cognitive Psychology , volume =
-
[26]
Nature Machine Intelligence , volume =
Learning high-level visual representations from a child's perspective without strong inductive biases , author =. Nature Machine Intelligence , volume =
-
[27]
Science , volume =
Grounded language acquisition through the eyes and ears of a single child , author =. Science , volume =. 2024 , doi =
2024
-
[28]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[29]
Tan, Hao and Bansal, Mohit , booktitle =
-
[30]
Computer Vision -- ECCV 2020 , series =
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks , author =. Computer Vision -- ECCV 2020 , series =
2020
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
VinVL: Revisiting Visual Representations in Vision-Language Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Efficient Visual Pretraining with Contrastive Detection , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[33]
Advances in Neural Information Processing Systems , year =
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments , author =. Advances in Neural Information Processing Systems , year =
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Emerging Properties in Self-Supervised Vision Transformers , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[35]
Journal of Experimental Psychology: General , year =
Compression in Visual Working Memory: Using Statistical Regularities to Form More Efficient Memory Representations , author =. Journal of Experimental Psychology: General , year =
-
[36]
Psychological Review , year =
A Probabilistic Model of Visual Working Memory: Incorporating Higher Order Regularities into Working Memory Capacity Estimates , author =. Psychological Review , year =
-
[37]
Psychological Review , year =
A Probabilistic Clustering Theory of the Organization of Visual Short-Term Memory , author =. Psychological Review , year =
-
[38]
Psychological Review , year =
Chunking as a Rational Strategy for Lossy Data Compression in Visual Working Memory , author =. Psychological Review , year =
-
[39]
Advances in Neural Information Processing Systems , volume =
Neural Discrete Representation Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[40]
Emin Orhan and Vaibhav V
A. Emin Orhan and Vaibhav V. Gupta and Brenden M. Lake , editor =. Self-supervised learning through the eyes of a child , booktitle =. 2020 , url =
2020
-
[41]
, journal =
Mandler, Jean M. , journal =. How to build a baby:. 1992 , doi =
1992
-
[42]
arXiv preprint arXiv:2103.00020 , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. arXiv preprint arXiv:2103.00020 , year =
-
[43]
Advances in Neural Information Processing Systems , year =
A Framework for Multiple-Instance Learning , author =. Advances in Neural Information Processing Systems , year =
-
[44]
arXiv preprint arXiv:1503.02531 , year =
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =
-
[45]
Proceedings of the European Conference on Computer Vision (ECCV) , year =
Deep Clustering for Unsupervised Learning of Visual Features , author =. Proceedings of the European Conference on Computer Vision (ECCV) , year =
-
[46]
Neural Computation , year =
Slow Feature Analysis: Unsupervised Learning of Invariances , author =. Neural Computation , year =
-
[47]
arXiv preprint arXiv:1704.06888 , year =
Time-Contrastive Networks: Self-Supervised Learning from Video , author =. arXiv preprint arXiv:1704.06888 , year =
-
[48]
Grounding
Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Jiang, Qing and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and Zhang, Lei , journal =. Grounding. 2023 , url =
2023
-
[49]
arXiv preprint arXiv:2306.09683 , year =
Scaling Open-Vocabulary Object Detection , author =. arXiv preprint arXiv:2306.09683 , year =
-
[50]
2024 , url =
Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying , journal =. 2024 , url =
2024
-
[51]
arXiv preprint arXiv:2408.00714 , year =
Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R. arXiv preprint arXiv:2408.00714 , year =
-
[52]
2025 , eprint=
Discovering Hidden Visual Concepts Beyond Linguistic Input in Infant Learning , author=. 2025 , eprint=
2025
-
[53]
2026 , eprint =
BabyVision: Visual Reasoning Beyond Language , author =. 2026 , eprint =
2026
-
[54]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. Proceedings of the European Conference on Computer Vision (ECCV) , year =
-
[55]
Physica D: Nonlinear Phenomena , volume =
The Symbol Grounding Problem , author =. Physica D: Nonlinear Phenomena , volume =. 1990 , doi =
1990
-
[56]
Oikarinen, Tuomas and Weng, Tsui-Wei , year =. 2204.10965 , archivePrefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.