TeleSWEBench: A Commit-Driven Benchmark for Evaluating LLM-Powered Software Engineering in Telecommunications
Pith reviewed 2026-06-28 05:08 UTC · model grok-4.3
The pith
LLM-powered agents achieve at most 25 percent shippable changes when modifying real 5G wireless code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
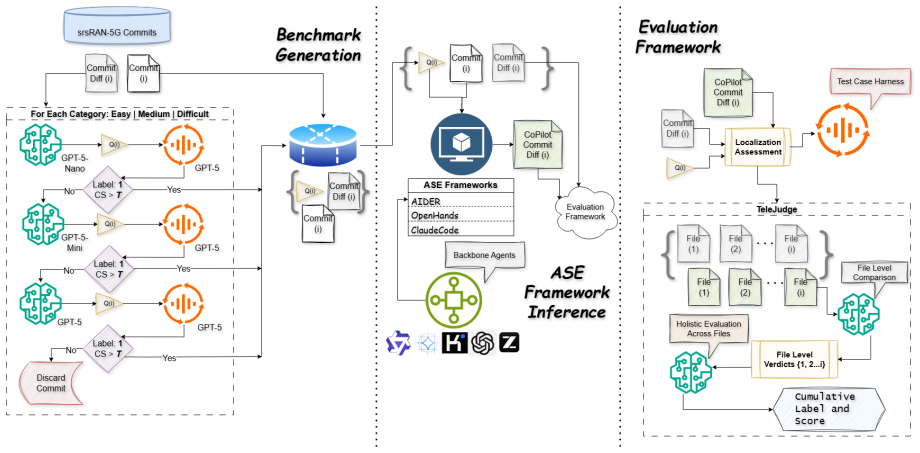
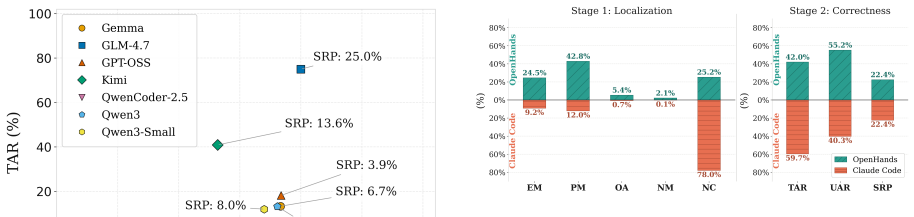
TeleSWEBench distills real commits from the srsRAN 5G repository into structured tasks with unit tests. Evaluation of AIDER, OpenHands, and ClaudeCode powered by models such as Qwen3, GPT OSS, Gemma 4, Kimi, and Qwencoder 2.5 shows that these tools lack both localization accuracy and functional correctness, so that even the strongest configurations produce at most 25 percent shippable changes.
What carries the argument
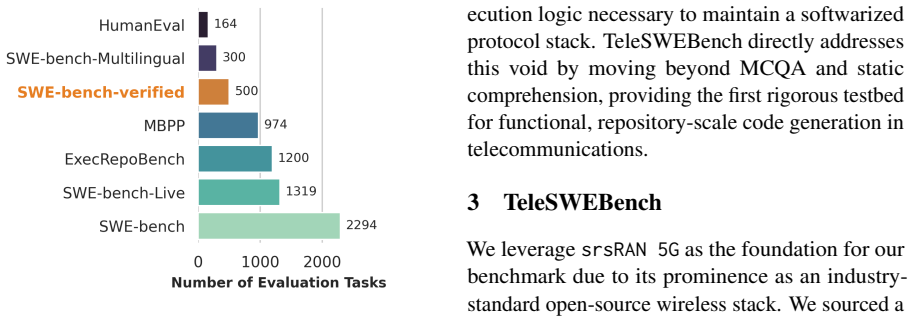
TeleSWEBench, the commit-driven benchmark of 734 questions drawn from srsRAN 5G commits together with executable unit tests and the TeleJudge hierarchical LLM-as-a-judge scoring system.
If this is right
- Agents must improve at identifying the precise files and functions that need modification inside large wireless codebases.
- Evaluation in telecom will require both strict unit tests and semantic judgment because many valid changes are not captured by tests alone.
- Domain-specific data or fine-tuning may be needed before agents can handle the mathematically constrained logic of 5G stacks.
- Operators adopting automated tools will still require substantial human review for changes to production wireless software.
Where Pith is reading between the lines
- The same commit-mining approach could expose similar gaps in other specialized domains that rely on stateful or protocol-heavy code.
- Performance on TeleSWEBench may improve if agents are given explicit models of wireless protocol constraints rather than generic code context.
- The gap between localization success and functional success points to a need for better intermediate verification steps inside agent loops.
- Over time the benchmark itself could serve as a training signal for agents that must operate inside live network management systems.
Load-bearing premise
Commits mined from the srsRAN 5G repository plus their unit tests and TeleJudge scores form a representative measure of an agent's ability to produce shippable changes in real telecom engineering.
What would settle it
A new agent framework that produces more than 40 percent shippable changes across the full set of TeleSWEBench cases under the same two-stage evaluation would falsify the reported performance ceiling.
Figures

read the original abstract
With the telecommunications field embracing zero touch management alongside novel O-RAN and AI-RAN frameworks, contemporary telecom networks now function as immensely intricate and heavily softwareized codebases. While automated software engineering (ASE) tools and Software Engineering (SWE) Agents hold the potential to alleviate the critical code generation bottleneck in this domain, their ability to navigate and modify specialized, mathematically rigorous wireless stacks like srsRAN 5G remains unverified. General-purpose coding benchmarks fail to capture the stateful logic and strict requirements of telecommunications, leaving a critical evaluation gap. In this paper, we introduce TeleSWEBench, the first commit-driven benchmark specifically designed to measure an agent's performance in the telecom domain. We mine real developer commits from the srsRAN 5G repository and distill them into structured test cases across three difficulty tiers (Easy, Medium, and Difficult). Our benchmark consists of 734 questions that are accompanied by executable unit tests. To avoid the rigidity of test cases, we further propose a hierarchical LLM as a Judge framework called TeleJudge that scores agent outputs at the file level and aggregates verdicts holistically. This follows an evaluation based on context and semantic similarity in parallel to a standard unit test-based evaluation. Using this benchmark, we evaluate AIDER, OpenHands, and the ClaudeCode frameworks, powered by state-of-the-art reasoning LLMs, including Qwen3, GPT OSS, Gemma 4, Kimi, and Qwencoder 2.5. Our two-stage evaluation reveals that models suffer from a lack of both localization accuracy and functional correctness, with the strongest ASE tools achieving up to 25% of shippable changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TeleSWEBench, the first commit-driven benchmark for LLM-powered ASE in telecommunications. It mines real commits from the srsRAN 5G repository, distills them into 734 structured tasks across Easy/Medium/Difficult tiers with executable unit tests, and proposes TeleJudge (a hierarchical LLM-as-a-judge using file-level context and semantic similarity) as a complement to rigid unit-test evaluation. Two-stage evaluation of AIDER, OpenHands, and ClaudeCode (powered by models including Qwen3, GPT OSS, Gemma 4, Kimi, Qwencoder 2.5) finds that agents lack localization accuracy and functional correctness, with the strongest tools achieving at most 25% shippable changes.
Significance. If the benchmark construction and TeleJudge verdicts are shown to be reliable proxies for deployable telecom changes, the work would fill a documented gap: general SWE benchmarks do not capture the stateful, mathematically rigorous wireless-stack requirements of telecom. The commit-mining approach and dual (unit-test + semantic) evaluation protocol are concrete strengths that could be extended to other specialized domains. The reported performance ceiling supplies a falsifiable baseline for future agent development in O-RAN/AI-RAN contexts.
major comments (3)
- [§3] §3 (Benchmark Construction): The paper provides no cross-validation (expert telecom-engineer ratings, integration-test runs, or hardware-in-the-loop checks) that the 734 distilled tasks and their unit tests capture the distinguishing stateful and protocol-level requirements of srsRAN-style wireless stacks. This directly undermines the central claim that the observed 25% shippable-change rate reflects genuine limitations rather than benchmark-construction artifacts.
- [§4] §4 (TeleJudge and Two-Stage Evaluation): No correlation analysis is reported between TeleJudge file-level semantic scores and either unit-test outcomes or independent expert judgments of deployability. Without such evidence, the hierarchical judge cannot be treated as a validated complement to unit tests for the functional-correctness dimension of the headline result.
- [§5] §5 (Results): The 25% shippable-change figure is presented without statistical significance testing, confidence intervals, or breakdown by difficulty tier and model; given that the benchmark validity itself remains unverified, this figure cannot yet be interpreted as a robust performance ceiling.
minor comments (2)
- [Abstract, §2] The abstract and §2 would benefit from an explicit statement of the exact commit-selection heuristics and inter-rater process used to tier tasks as Easy/Medium/Difficult.
- [Tables/Figures] Figure captions and Table 1 should clarify whether the reported percentages are macro- or micro-averaged across the 734 tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the benchmark tasks, TeleJudge, and statistical presentation of results. We address each major comment below with planned revisions where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The paper provides no cross-validation (expert telecom-engineer ratings, integration-test runs, or hardware-in-the-loop checks) that the 734 distilled tasks and their unit tests capture the distinguishing stateful and protocol-level requirements of srsRAN-style wireless stacks. This directly undermines the central claim that the observed 25% shippable-change rate reflects genuine limitations rather than benchmark-construction artifacts.
Authors: The tasks are distilled directly from real commits authored by srsRAN developers, which inherently encode the stateful, protocol-level, and mathematically rigorous requirements of the wireless stack as implemented in production code. The accompanying unit tests are executable and drawn from the repository's own test infrastructure. We will revise §3 to more explicitly justify the commit-mining approach as a domain-relevant proxy and add an explicit limitations subsection acknowledging the absence of expert ratings or hardware-in-the-loop validation, along with plans for such extensions in future work. revision: partial
-
Referee: [§4] §4 (TeleJudge and Two-Stage Evaluation): No correlation analysis is reported between TeleJudge file-level semantic scores and either unit-test outcomes or independent expert judgments of deployability. Without such evidence, the hierarchical judge cannot be treated as a validated complement to unit tests for the functional-correctness dimension of the headline result.
Authors: We will add a new subsection in §4 reporting correlation (Pearson and Spearman) between TeleJudge file-level semantic scores and unit-test pass/fail outcomes across all evaluated agents and models. This will quantify the degree of alignment. We note that independent expert judgments of deployability were not collected in the current study due to resource constraints and will discuss this as a limitation. revision: yes
-
Referee: [§5] §5 (Results): The 25% shippable-change figure is presented without statistical significance testing, confidence intervals, or breakdown by difficulty tier and model; given that the benchmark validity itself remains unverified, this figure cannot yet be interpreted as a robust performance ceiling.
Authors: We agree that additional statistical rigor is required. In the revised §5 we will include: (i) 95% confidence intervals computed via bootstrapping, (ii) statistical significance tests (e.g., McNemar’s test for paired agent comparisons), and (iii) full breakdowns of success rates by difficulty tier (Easy/Medium/Difficult) and by underlying LLM. These additions will allow readers to interpret the 25% ceiling with appropriate caution. revision: yes
- Full cross-validation involving multiple independent telecom experts performing ratings or hardware-in-the-loop integration tests, which would require specialized domain expertise, access to proprietary testbeds, and resources beyond the scope of this initial benchmark release.
Circularity Check
No significant circularity; benchmark construction is self-contained empirical work
full rationale
The paper introduces TeleSWEBench by mining commits from srsRAN 5G, distilling them into 734 tasks with unit tests, and proposing TeleJudge as an LLM-based scorer. No mathematical derivations, parameter fittings, or predictions are present. No load-bearing self-citations or uniqueness theorems are invoked. The central claims rest on direct empirical evaluation of external ASE tools against the constructed benchmark, with no step reducing by construction to its own inputs. This is standard benchmark paper structure and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In18th ACM Conference on Security and Privacy in Wireless and Mobile Networks, pages 53–64
Ai5gtest: Ai-driven specification-aware auto- mated testing and validation of 5g o-ran components. In18th ACM Conference on Security and Privacy in Wireless and Mobile Networks, pages 53–64. GSMA. 2026. Release v1.1.0 · gsma-labs/evals. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao L...
Pith/arXiv arXiv 2026
-
[2]
Jiacheng Liu, Xiaohan Zhao, Xinyi Shang, and Zhiqiang Shen
Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579. Jiacheng Liu, Xiaohan Zhao, Xinyi Shang, and Zhiqiang Shen. 2026. Dive into claude code: The design space of today’s and future ai agent systems.arXiv preprint arXiv:2604.14228. Tianyang Liu, Canwen Xu, and Julian McAuley
Pith/arXiv arXiv 2026
-
[3]
Ali Maatouk, Fadhel Ayed, Nicola Piovesan, Antonio De Domenico, Merouane Debbah, and Zhi-Quan Luo
Repobench: Benchmarking repository-level code auto-completion systems.arXiv preprint arXiv:2306.03091. Ali Maatouk, Fadhel Ayed, Nicola Piovesan, Antonio De Domenico, Merouane Debbah, and Zhi-Quan Luo. 2025. Teleqna: A benchmark dataset to assess large language models telecommunications knowl- edge.IEEE Network. Ziyi Ni, Huacan Wang, Shuo Zhang, Shuo Lu, ...
Pith/arXiv arXiv 2025
-
[4]
A Timidness In our evaluation, a recurring behavioral failure mode istimidnessas mentioned in Section 6.1
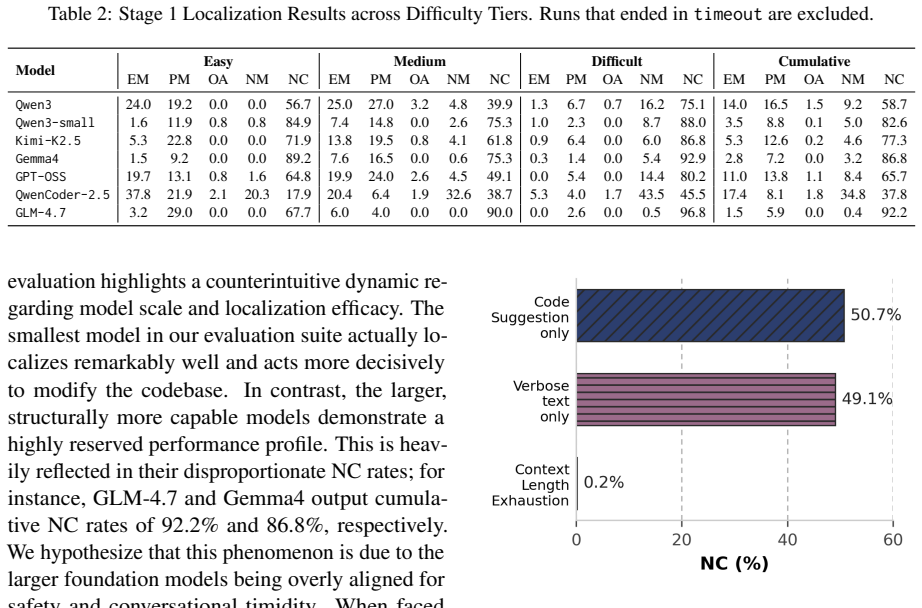
Telecomgpt: A framework to build telecom- specific large language models.IEEE Transactions on Machine Learning in Communications and Net- working. A Timidness In our evaluation, a recurring behavioral failure mode istimidnessas mentioned in Section 6.1. De- spite successfully deducing the correct files, grasp- ing the required logic, and understanding the...
-
[5]
include/srsgnb/asn1/asn1_utils.h (contains unbounded_octstring class definition)
-
[6]
lib/asn1/asn1_utils.cpp (implementation of helpers and methods)
-
[7]
unittests/asn1/asn1_utils_test.cpp (tests for the changes)
-
[8]
unittests/asn1/asn1_rrc_nr_test.cpp (tests using octet strings)
-
[9]
what" and
apps/examples/du/du_example.cpp (usage example) I should list these and stop.... 11 B Standard LLM-as-a-Judge We initially experimented with a single-shot set- ting, which is the standard way to implement LLM judges in the literature (Gu et al., 2024). Here, the judge received the diffs and the questions si- multaneously to produce an output. However, thi...
2024
-
[10]
The original task description (question)
-
[11]
The ground truth fix (the accepted human commit diff) for ONE file
-
[12]
verdict":
The copilot’s proposed changes for the SAME file. Acceptif the copilot’s changes are functionally equivalent to the ground truth for this file — they address the same root cause or implement the same feature, even if variable names, formatting, ordering, or minor stylistic details differ. Rejectif the copilot’s changes miss the core issue, modify the wron...
-
[13]
The original task description
-
[14]
verdict":
Per-file verdicts from a first-pass review, each with reasons. Read the reasons carefully, think about the commit holistically, and make your own judgment. A single rejected file does NOT automati- cally mean the whole commit fails — consider whether the rejected file is critical to the task or a minor ancillary change.Return ONLY a JSON object with exact...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.