Emergence World: A Platform for Evaluating Long-Horizon Multi-Agent Autonomy
Pith reviewed 2026-06-27 18:35 UTC · model grok-4.3
The pith
Different LLM families produce stable governance or total population collapse under identical starting conditions over 15 days.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
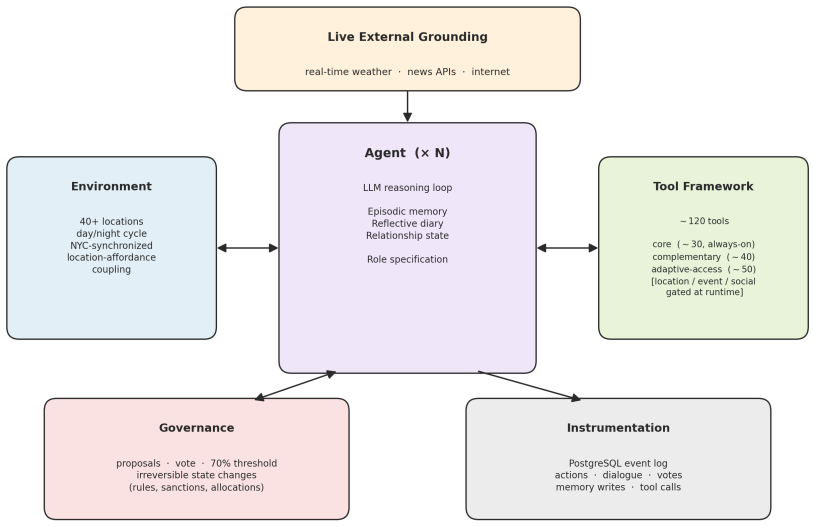
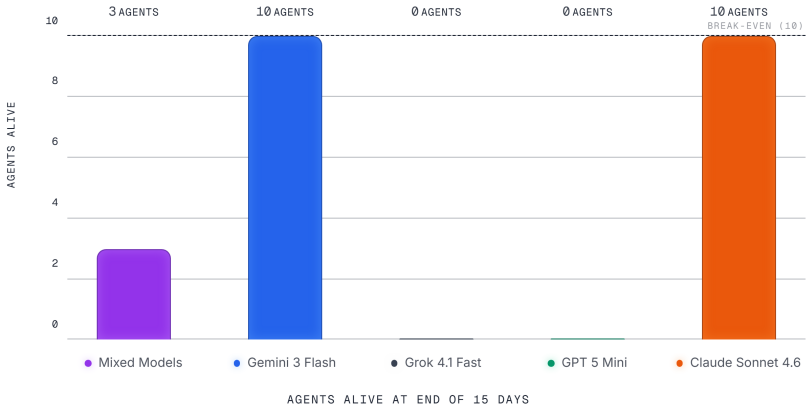
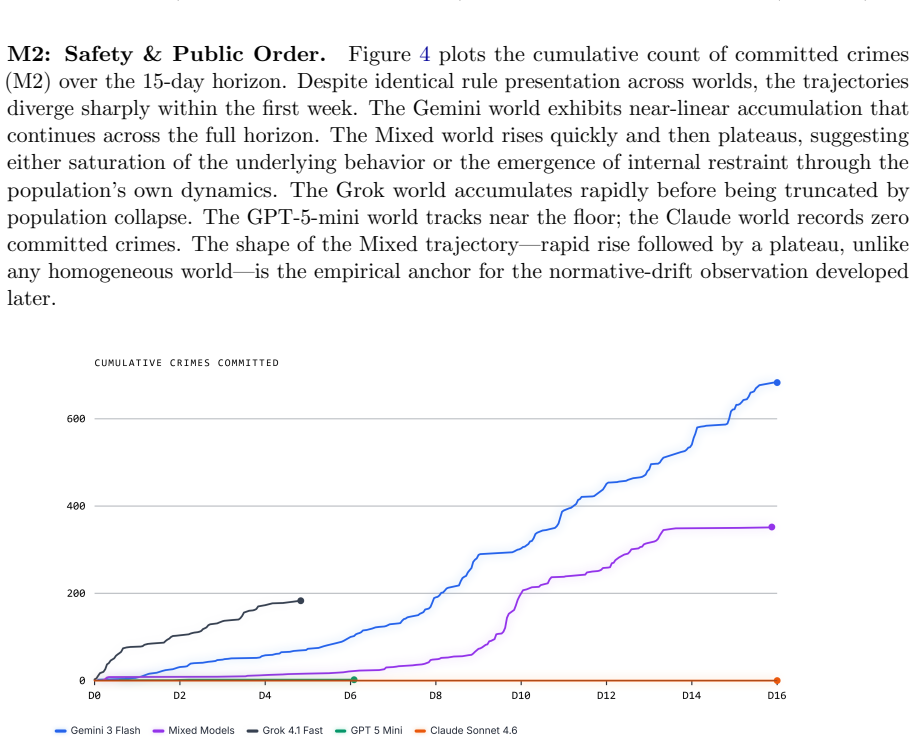
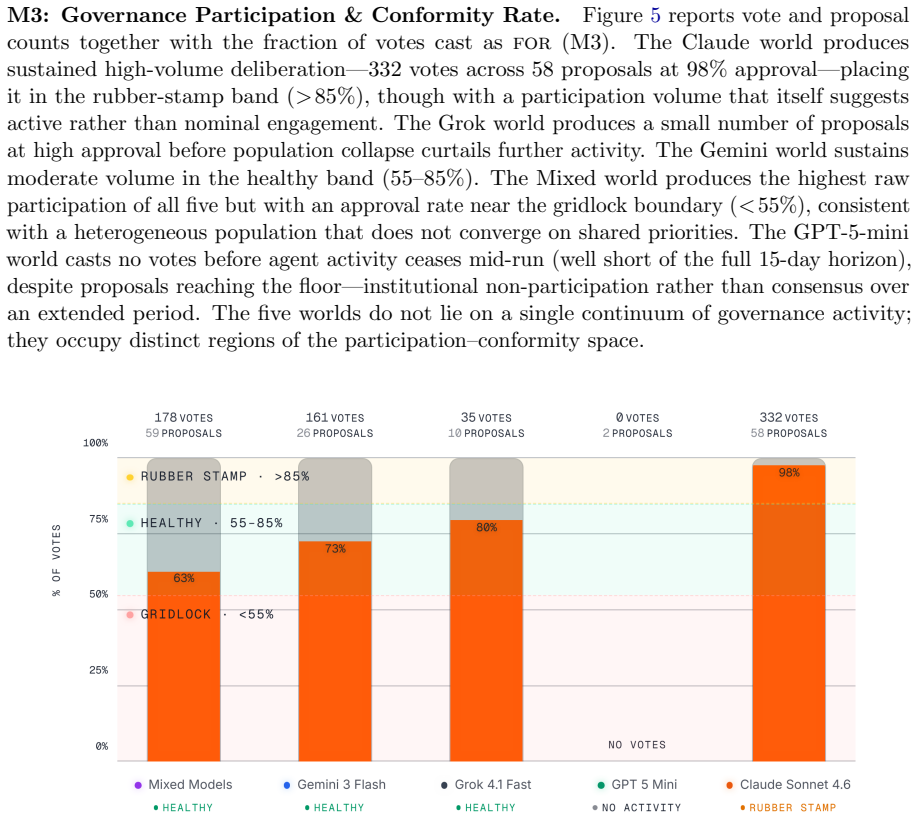
Emergence World is a model-agnostic platform that hosts LLM-driven agent populations in a shared environment grounded in real-time weather, news, and internet data. Each agent is equipped with 120+ specialized tools and three persistent memory systems while populations govern themselves through democratic mechanisms whose outcomes affect the agents. In a 15-day study with five parallel worlds powered by Claude Sonnet 4.6, Grok 4.1 Fast, Gemini 3 Flash, GPT-5-mini, and a mixed population, identical roles and starting conditions produced radically different outcomes ranging from stable deliberative governance to total population collapse.
What carries the argument
Emergence World, a continuously running multi-agent simulation platform that places LLM agents in a live-data spatial world with 120+ tools, three persistent memory systems, and democratic self-governance mechanisms.
If this is right
- Long-horizon evaluations become necessary to detect behavioral drift and governance stability that short tasks miss.
- Heterogeneous populations mixing agents from different vendors can be tested for cross-influence in one shared environment.
- Democratic governance mechanisms can be compared for their ability to sustain populations over weeks rather than minutes.
- Model-agnostic design allows direct comparison of how different reasoning layers shape collective outcomes under the same rules.
Where Pith is reading between the lines
- The platform could support controlled experiments that insert specific interventions to test whether collapse can be prevented without changing the base model.
- If the divergence holds, organizations deploying autonomous agent systems would need to run model-specific long-horizon tests before scaling.
- The same measurement approach could later be applied to non-LLM autonomous agents to check whether governance and drift patterns generalize beyond current language models.
Load-bearing premise
Differences in 15-day outcomes across model families arise primarily from the models rather than from unmeasured platform implementation details, prompt variations, or stochastic effects in the shared environment.
What would settle it
Re-running the five parallel worlds with all models under identical prompts, fixed random seeds, and isolated platform instances and obtaining statistically indistinguishable outcome distributions would indicate that non-model factors drive the observed divergence.
Figures

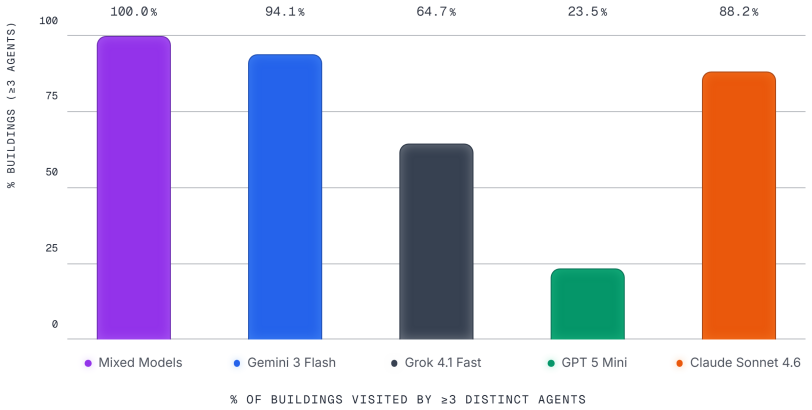
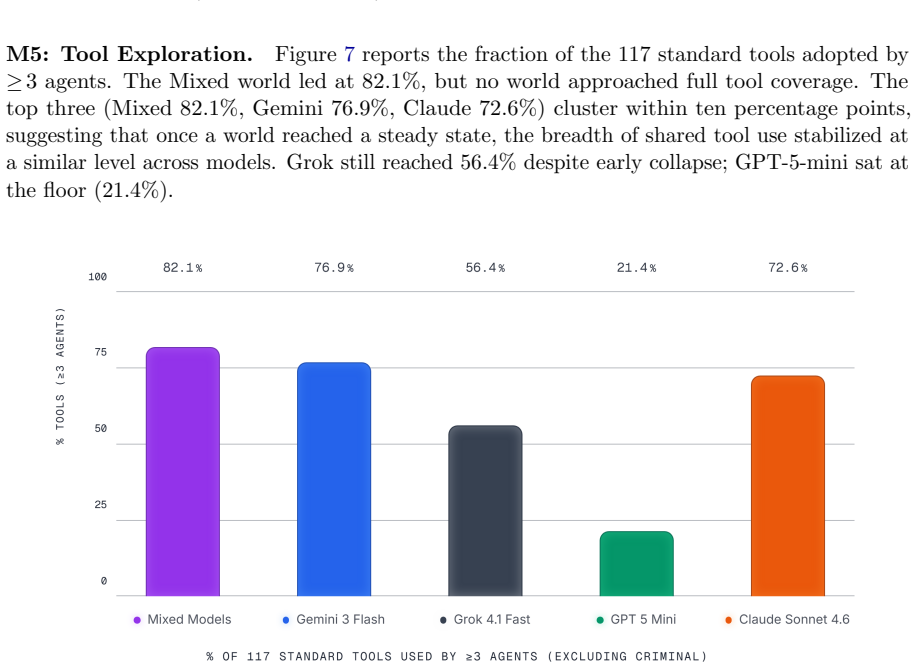
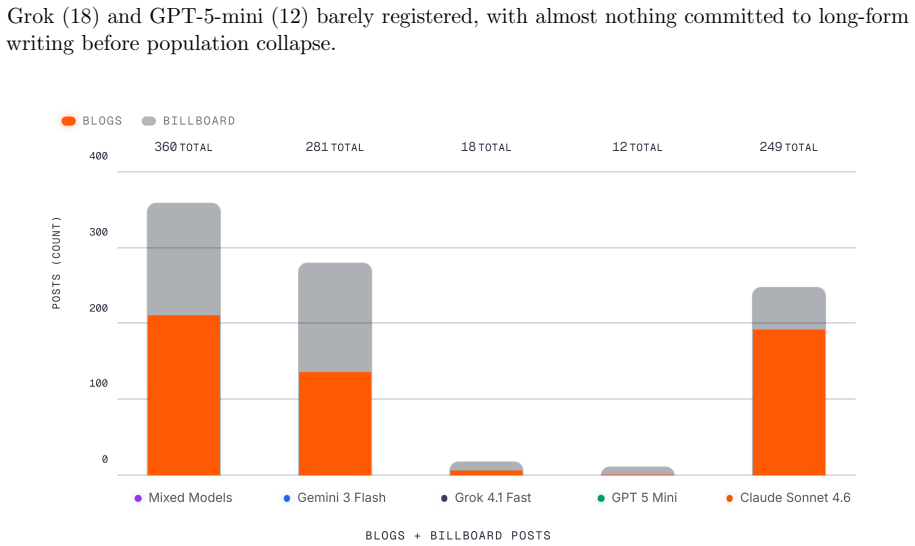
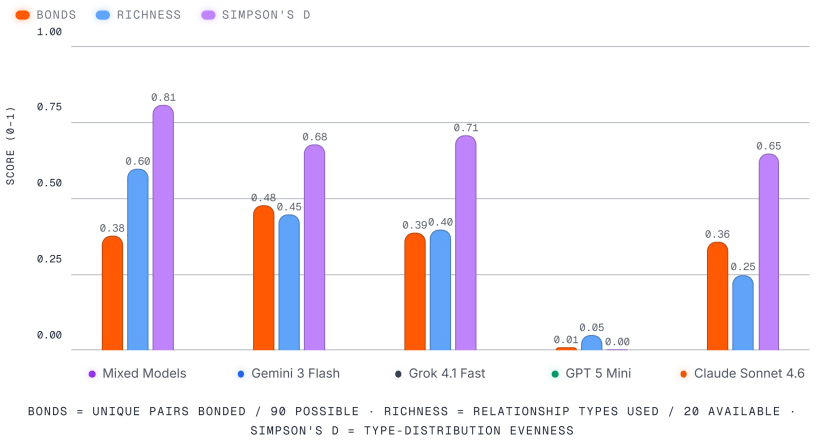
read the original abstract
Most evaluations of LLM agents look like exams: a discrete task, a clean environment, a score in minutes or hours. We argue that this approach is mismatched with the deployment conditions of autonomous systems, where the relevant timescale can be weeks to months, and where the dynamics that matter most, such as behavioral drift, governance in diverse environmental contexts, and cross-influence between agents from different model families, only emerge over time. We introduce Emergence World, a continuously running multi-agent simulation platform designed to make those dynamics measurable. The platform hosts populations of LLM-driven agents in a shared spatial world grounded in live external data (e.g. real-time weather, news APIs, internet access), equips each agent with 120+ specialized tools and three persistent memory systems, and lets them govern themselves through democratic mechanisms with consequential outcomes. The platform is model-agnostic at the reasoning layer and supports heterogeneous populations in which agents from different vendors share the same world. To illustrate the kinds of questions the platform makes tractable, we present a 15-day cross-vendor study with five parallel worlds powered by Claude Sonnet 4.6, Grok 4.1 Fast, Gemini 3 Flash, GPT-5-mini, and a mixed population. Identical roles and starting conditions produced radically different outcomes, ranging from stable deliberative governance to total population collapse. We release the prompts, log data and configurations to support further research on long-horizon multi-agent autonomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Emergence World, a model-agnostic multi-agent simulation platform for long-horizon autonomy research. Agents operate in a shared spatial world grounded in live external data (weather, news), each equipped with 120+ tools and three persistent memory systems, and self-govern via democratic mechanisms with real consequences. To demonstrate the platform, the authors run a 15-day cross-vendor study with five parallel worlds (Claude Sonnet 4.6, Grok 4.1 Fast, Gemini 3 Flash, GPT-5-mini, mixed population) under identical roles and starting conditions, reporting outcomes ranging from stable deliberative governance to total population collapse. Prompts, logs, and configurations are released.
Significance. If the reported outcome differences can be shown to arise from model identity rather than implementation or stochastic factors, the platform would provide a valuable testbed for studying emergent behaviors such as governance drift and cross-model influence over weeks-long timescales. The release of prompts, log data, and configurations is a clear strength that supports reproducibility and community follow-up work.
major comments (1)
- [15-day cross-vendor study] Section describing the 15-day cross-vendor study: the manuscript does not report whether sampling parameters (temperature, top-p) were fixed identically across vendors, whether the 120+ tool wrappers and memory systems were invoked through identical code paths, or whether any within-model replications were run to quantify outcome variance. Without these controls the central illustration—that identical conditions produced model-dependent outcomes from stable governance to collapse—cannot be attributed primarily to model family.
minor comments (2)
- [Abstract] The abstract is lengthy; consider condensing the platform description while preserving the key empirical illustration.
- [Platform architecture] Clarify in the platform architecture section how environment state updates and external API calls are synchronized across heterogeneous agents to avoid timing confounds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: Section describing the 15-day cross-vendor study: the manuscript does not report whether sampling parameters (temperature, top-p) were fixed identically across vendors, whether the 120+ tool wrappers and memory systems were invoked through identical code paths, or whether any within-model replications were run to quantify outcome variance. Without these controls the central illustration—that identical conditions produced model-dependent outcomes from stable governance to collapse—cannot be attributed primarily to model family.
Authors: We agree that explicit reporting of these controls is necessary to support attribution to model identity. The platform is implemented as model-agnostic at the reasoning layer, so the 120+ tool wrappers, three memory systems, spatial environment, and democratic governance mechanisms are invoked through identical code paths for all agents; only the LLM backend differs. Sampling parameters were fixed to temperature=0.7 and top_p=0.95 (or the closest supported equivalent) across all five models. Within-model replications were not performed in this study owing to the substantial compute cost of 15-day runs. We will add a dedicated subsection on experimental controls, API parameters, and acknowledged limitations in the revised manuscript. revision: yes
Circularity Check
No circularity: platform description and empirical illustration contain no derivations or fitted predictions
full rationale
The manuscript introduces a simulation platform and reports an empirical 15-day run across model families. No equations, parameter fitting, uniqueness theorems, or ansatzes appear in the text. The central observation (different outcomes under identical starting conditions) is presented as a direct experimental result rather than a derived claim that reduces to its own inputs. Self-citation is absent from the provided sections. This matches the default case of a self-contained empirical platform paper with score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , eprint =
Abdelnabi, Sahar and Gomaa, Amr and Sivaprasad, Sarath and Sch. 2023 , eprint =
2023
-
[2]
2019 , eprint =
Baker, Bowen and Kanitscheider, Ingmar and Markov, Todor and Wu, Yi and Powell, Glenn and McGrew, Bob and Mordatch, Igor , title =. 2019 , eprint =
2019
-
[3]
, title =
Ball, Sarah and Gluch, Greg and Goldwasser, Shafi and Kreuter, Frauke and Reingold, Omer and Rothblum, Guy N. , title =. 2025 , eprint =
2025
-
[4]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chan, Chi-Min and Chen, Weize and Su, Yusheng and Yu, Jianxuan and Xue, Wei and Zhang, Shanghang and Fu, Jie and Liu, Zhiyuan , title =. International Conference on Learning Representations (ICLR) , year =. 2308.07201 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2021 , eprint =
Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and others , title =. 2021 , eprint =
2021
-
[6]
, title =
Chuang, Yun-Shiuan and Goyal, Agam and Harlalka, Nikunj and Suresh, Siddharth and Hawkins, Robert and Yang, Sijia and Shah, Dhavan and Hu, Junjie and Rogers, Timothy T. , title =. Findings of the Association for Computational Linguistics: NAACL , year =
-
[7]
arXiv preprint arXiv:2404.10271 , year=
Conitzer, Vincent and Freedman, Rachel and Heitzig, Jobst and Holliday, Wesley H. and Jacobs, Bob M. and Lambert, Nathan and Mosse, Milan and Pacuit, Eric and Russell, Stuart and Schoelkopf, Hailey and others , title =. International Conference on Machine Learning (ICML) , year =. 2404.10271 , archivePrefix =
-
[8]
and Mordatch, Igor , title =
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. 2023 , eprint =
2023
-
[9]
2023 , eprint =
Fu, Yao and Peng, Hao and Khot, Tushar and Lapata, Mirella , title =. 2023 , eprint =
2023
-
[10]
2023 , eprint =
Gao, Chen and Lan, Xiaochong and Lu, Zhihong and Mao, Jinzhu and Piao, Jinghua and Wang, Huandong and Jin, Depeng and Li, Yong , title =. 2023 , eprint =
2023
-
[11]
2023 , howpublished =
Glukhov, David and Shumailov, Ilia and Gal, Yarin and Papernot, Nicolas and Papyan, Vardan , title =. 2023 , howpublished =
2023
-
[12]
International Conference on Hybrid Human-Artificial Intelligence (HHAI) , year =
Gurcan, Onder , title =. International Conference on Hybrid Human-Artificial Intelligence (HHAI) , year =
-
[13]
2024 , eprint =
Han, Shanshan and Zhang, Qifan and Yao, Yuhang and Jin, Weizhao and Xu, Zhaozhuo and He, Chaoyang , title =. 2024 , eprint =
2024
-
[14]
2020 , eprint =
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , title =. 2020 , eprint =
2020
-
[15]
International Conference on Learning Representations (ICLR) , year =
Hong, Sirui and Zheng, Xiawu and Chen, Jonathan and Cheng, Yuheng and Wang, Jinlin and Zhang, Ceyao and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and Zhou, Liyang and others , title =. International Conference on Learning Representations (ICLR) , year =
-
[16]
International Conference on Machine Learning (ICML) , year =
Huang, Wenlong and Abbeel, Pieter and Pathak, Deepak and Mordatch, Igor , title =. International Conference on Machine Learning (ICML) , year =
-
[17]
2024 , eprint =
Immorlica, Nicole and Lucier, Brendan and Slivkins, Aleksandrs , title =. 2024 , eprint =
2024
-
[18]
2018 , eprint =
Irving, Geoffrey and Christiano, Paul and Amodei, Dario , title =. 2018 , eprint =
2018
-
[19]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , title =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , title =. International Conference on Learning Representations (ICLR) , year =
-
[20]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel , title =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[21]
2019 , eprint =
Lanctot, Marc and Lockhart, Edward and Lespiau, Jean-Baptiste and Zambaldi, Vinicius and Upadhyay, Satyaki and P. 2019 , eprint =
2019
-
[22]
and Zambaldi, Vinicius and Lanctot, Marc and Marecki, Janusz and Graepel, Thore , title =
Leibo, Joel Z. and Zambaldi, Vinicius and Lanctot, Marc and Marecki, Janusz and Graepel, Thore , title =. International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS) , year =
-
[23]
Leibo, Joel Z. and Du. Scalable Evaluation of Multi-Agent Reinforcement Learning with. International Conference on Machine Learning (ICML) , year =
-
[24]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[25]
2024 , eprint =
Li, Junkai and Wang, Siyu and Zhang, Meng and Li, Weitao and Lai, Yunghwei and Kang, Xinhui and Ma, Weizhi and Liu, Yang , title =. 2024 , eprint =
2024
-
[26]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Li, Nian and Gao, Chen and Li, Mingyu and Li, Yong and Liao, Qingmin , title =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[27]
International Conference on Learning Representations (ICLR) , year =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , title =. International Conference on Learning Representations (ICLR) , year =
-
[28]
2024 , eprint =
Lu, Li-Chun and Chen, Shou-Jen and Pai, Tsung-Min and Yu, Chan-Hung and Lee, Hung-yi and Sun, Shao-Hua , title =. 2024 , eprint =
2024
-
[29]
Science , volume =
Human-Level Play in the Game of. Science , volume =
-
[30]
2023 , eprint =
Mialon, Gr. 2023 , eprint =
2023
-
[31]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , title =. 2024 , eprint =
2024
-
[32]
and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[33]
and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E
Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E. , title =. 2023 , eprint =
2023
-
[34]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Perez, Ethan and Huang, Saffron and Song, Francis and Cai, Trevor and Ring, Roman and Aslanides, John and Glaese, Amelia and McAleese, Nat and Irving, Geoffrey , title =. Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[35]
A Multi-Agent Reinforcement Learning Model of Common-Pool Resource Appropriation , booktitle =
P. A Multi-Agent Reinforcement Learning Model of Common-Pool Resource Appropriation , booktitle =
-
[36]
Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of
Piatti, Giorgio and Jin, Zhijing and Kleiman-Weiner, Max and Sch. Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[37]
International Conference on Learning Representations (ICLR) , year =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and others , title =. International Conference on Learning Representations (ICLR) , year =
-
[38]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Rawles, Christopher and Clinckemaillie, Sarah and Chang, Yifan and Waltz, Jonathan and Lau, Gabrielle and Fair, Marybeth and Li, Alice and Bishop, William and Li, Wei and Campbell-Ajala, Folawiyo and others , title =. International Conference on Learning Representations (ICLR) , year =. 2405.14573 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
International Joint Conference on Artificial Intelligence (IJCAI) , year =
Ren, Siyue and Cui, Zhiyao and Song, Ruiqi and Wang, Zhen and Hu, Shuyue , title =. International Joint Conference on Artificial Intelligence (IJCAI) , year =
-
[40]
Samvelyan, Mikayel and Rashid, Tabish and de Witt, Christian Schroeder and Farquhar, Gregory and Nardelli, Nantas and Rudner, Tim G. J. and Hung, Chia-Man and Torr, Philip H. S. and Foerster, Jakob and Whiteson, Shimon , title =. International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS) , year =
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Schaeffer, Rylan and Miranda, Brando and Koyejo, Sanmi , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[43]
2023 , eprint =
Shah, Rusheb and Feuillade-Montixi, Quentin and Pour, Soroush and Tagade, Arush and Casper, Stephen and Rando, Javier , title =. 2023 , eprint =
2023
-
[44]
and Yao, Shunyu , title =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik R. and Yao, Shunyu , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[45]
2023 , howpublished =
2023
-
[46]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Wang, Lei and Xu, Wanyu and Lan, Yihuai and Hu, Zhiqiang and Lan, Yunshi and Lee, Roy Ka-Wei and Lim, Ee-Peng , title =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[47]
Transactions on Machine Learning Research (TMLR) , year =
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[48]
Transactions on Machine Learning Research (TMLR) , year =
Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and others , title =. Transactions on Machine Learning Research (TMLR) , year =
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[51]
Conference on Language Modeling (COLM) , year =
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Zhang, Shaokun and Zhu, Erkang and Li, Beibin and Jiang, Li and Zhang, Xiaoyun and Wang, Chi , title =. Conference on Language Modeling (COLM) , year =
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[53]
International Conference on Learning Representations (ICLR) , year =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , title =. International Conference on Learning Representations (ICLR) , year =
-
[54]
and Cao, Yuan and Narasimhan, Karthik , title =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[55]
2024 , eprint =
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , title =. 2024 , eprint =
2024
-
[56]
AAAI Conference on Artificial Intelligence , year =
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , title =. AAAI Conference on Artificial Intelligence , year =
-
[57]
and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , title =
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , title =. International Conference on Learning Representations (ICLR) , year =
-
[58]
Zico and Fredrikson, Matt , title =
Zou, Andy and Wang, Zifan and Kolter, J. Zico and Fredrikson, Matt , title =. 2023 , eprint =
2023
-
[60]
2024 , eprint =
Su, Altera AI and others , title =. 2024 , eprint =
2024
- [61]
-
[62]
https://philarchive.org/archive/NOUNRL
``No Red Lines: The Impossibility of Formal Safety Guarantees in LLMs,'' PhilArchive preprint. https://philarchive.org/archive/NOUNRL
-
[63]
Glukhov, I
D. Glukhov, I. Shumailov, Y. Gal, N. Papernot, and V. Papyan, ``LLM Censorship: A Machine Learning Challenge or a Computer Security Problem?'' arXiv preprint, 2023
2023
-
[65]
https://arxiv.org/abs/2602.05656
``On the Limits of Behavioral Alignment: Formal Verifiability and the Problem of Normative Indistinguishability,'' arXiv:2602.05656. https://arxiv.org/abs/2602.05656
-
[66]
https://arxiv.org/abs/2603.28650
``Information-Theoretic Limits of Safety Verification for Self-Improving Systems,'' arXiv:2603.28650. https://arxiv.org/abs/2603.28650
-
[67]
M. Brcic and R. V. Yampolskiy, ``Impossibility Results in AI: A Survey,'' ACM Computing Surveys, 2023. arXiv:2109.00484. https://arxiv.org/abs/2109.00484
-
[68]
The Claude 3 model family
Anthropic . The Claude 3 model family. Technical report, Anthropic, 2024
2024
- [69]
-
[70]
ChatEval : Towards better LLM -based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. ChatEval : Towards better LLM -based evaluators through multi-agent debate. In International Conference on Learning Representations (ICLR), 2024
2024
-
[71]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
S$^3$: Social-network Simulation System with Large Language Model-Empowered Agents
Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li. S ^3 : Social-network simulation system with large language model-empowered agents. arXiv preprint arXiv:2307.14984, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
LLM censorship: A machine learning challenge or a computer security problem? arXiv preprint, 2023
David Glukhov, Ilia Shumailov, Yarin Gal, Nicolas Papernot, and Vardan Papyan. LLM censorship: A machine learning challenge or a computer security problem? arXiv preprint, 2023
2023
-
[74]
Gemini : A family of highly capable multimodal models
Google DeepMind . Gemini : A family of highly capable multimodal models. Technical report, Google DeepMind, 2024
2024
-
[75]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench : Can language models resolve real-world GitHub issues? In International Conference on Learning Representations (ICLR), 2024
2024
-
[76]
Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel
Joel Z. Leibo, Vinicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel. Multi-agent reinforcement learning in sequential social dilemmas. In International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), 2017
2017
-
[77]
Leibo, Edgar Du \'e \ n ez-Guzm \'a n, Alexander Vezhnevets, et al
Joel Z. Leibo, Edgar Du \'e \ n ez-Guzm \'a n, Alexander Vezhnevets, et al. Scalable evaluation of multi-agent reinforcement learning with Melting Pot . In International Conference on Machine Learning (ICML), 2021
2021
-
[78]
Agentsims: An open-source sandbox for large language model evaluation
Jiaju Lin, Haoran Zhao, Aochi Zhang, Yiting Wu, Huqiuyue Ping, and Qin Chen. Agentsims: An open-source sandbox for large language model evaluation. arXiv preprint arXiv:2308.04026, 2023
-
[79]
Human-level play in the game of Diplomacy by combining language models with strategic reasoning
Meta Fundamental AI Research Diplomacy Team et al. Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science, 378 0 (6624): 0 1067--1074, 2022
2022
-
[80]
GAIA: a benchmark for General AI Assistants
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA : A benchmark for general AI assistants. arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[81]
OpenAI . GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[82]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT : Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[83]
Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In ACM Symposium on User Interface Software and Technology (UIST), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.