Topologically Consistent Multi-view 3D Head Reconstruction via Coarse-Guided Layered Surface Sampling
Pith reviewed 2026-06-28 22:50 UTC · model grok-4.3
The pith
SHELLS reconstructs dense 3D heads from multi-view images by using a coarse mesh to guide layered surface sampling shells that keep topology consistent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
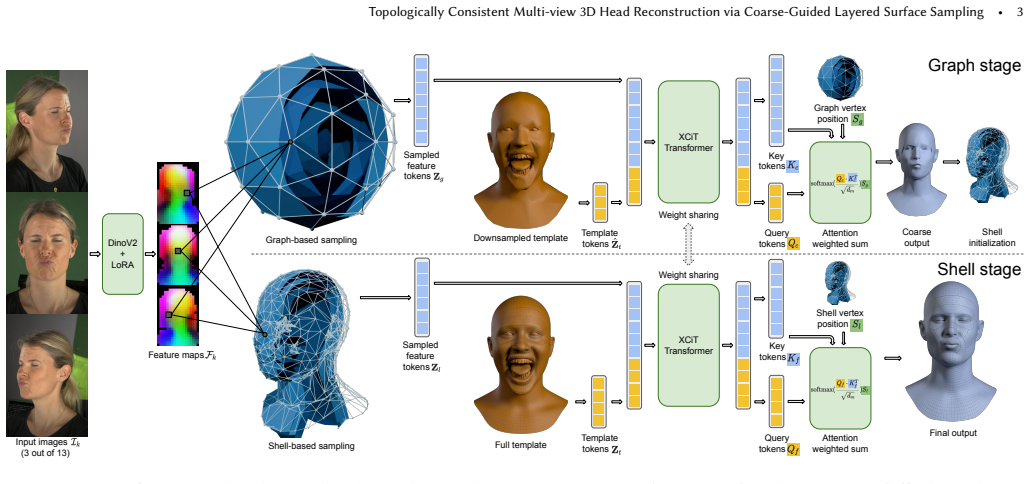
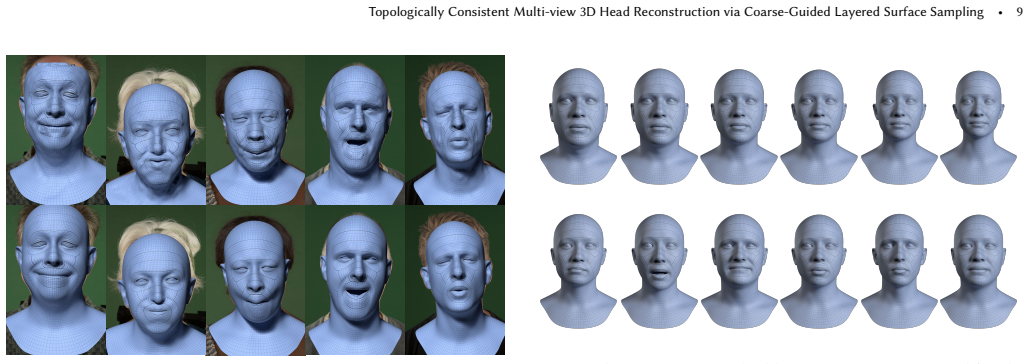
SHELLS extracts multi-view features with a DINOv2 backbone, projects them into a sparse global feature cloud, predicts a coarse mesh, and then builds layered surface-aware sampling shells from that coarse prior; the shells serve as the discrete space in which final vertex positions are regressed, preserving surface consistency across the entire mesh.
What carries the argument
Layered surface-aware sampling shells built from an intermediate coarse mesh, which provide a resolution-independent discrete search space for final vertex placement.
If this is right
- Surface consistency is maintained for meshes larger than 10k vertices without the memory scaling problems of volumetric feature sampling.
- Inference requires only 2.4 GB of GPU memory instead of 20 GB while running in 0.08 seconds instead of 0.29 seconds.
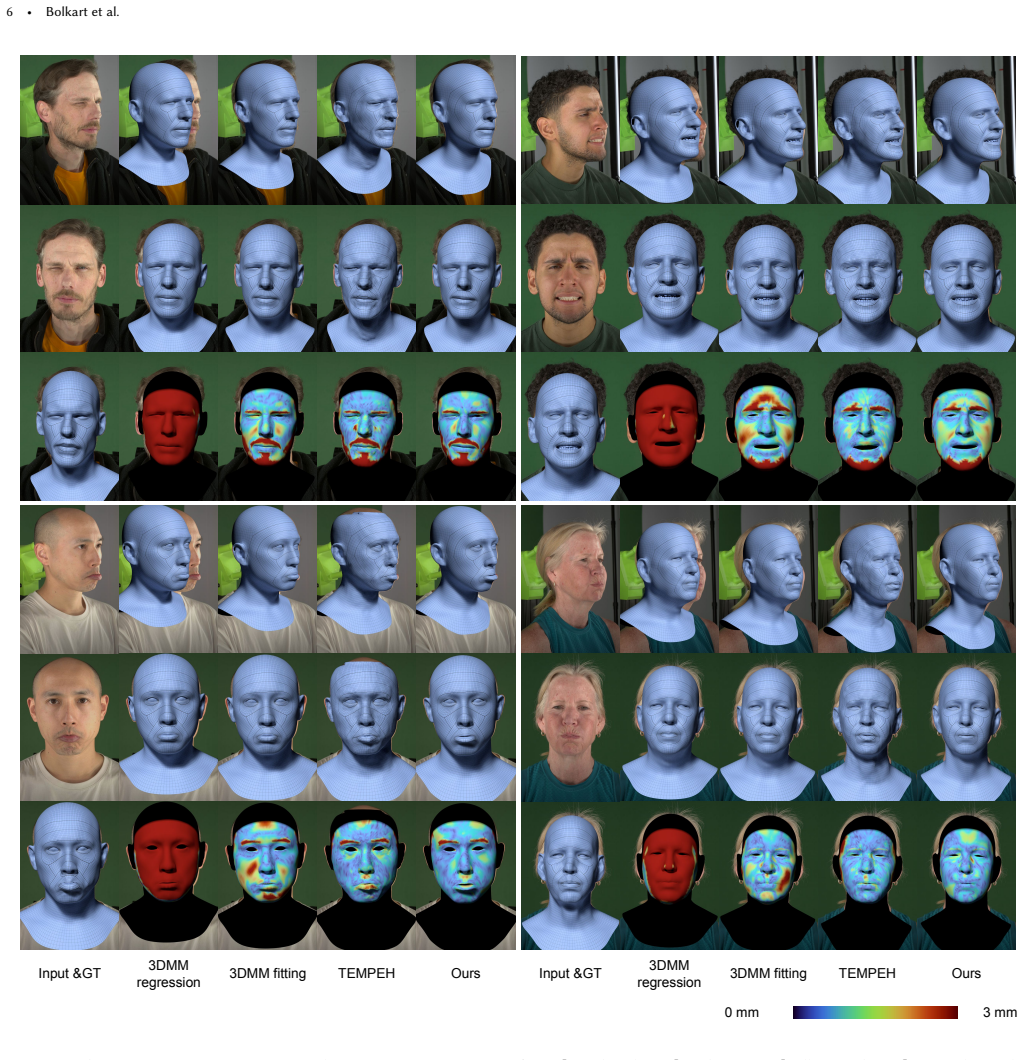
- Median registration error drops 21 to 29 percent relative to prior methods on the same dense topology.
- Training exclusively on synthetic data is sufficient for effective generalization to real multi-view captures, removing the need for pre-registered real datasets.
Where Pith is reading between the lines
- The same coarse-to-layered sampling pattern could be tested on full-body or object reconstruction tasks where memory limits currently force low-resolution outputs.
- Because the method never couples feature volume size to final vertex count, it opens the possibility of producing meshes at 50k vertices or higher on the same hardware budget.
- Synthetic-only training implies that large-scale procedural head datasets could replace labor-intensive real captures for many downstream tasks.
- The 0.08-second inference time suggests the pipeline could support interactive applications such as live facial animation if integrated with real-time pose estimation.
Load-bearing premise
The coarse mesh derived from the sparse feature cloud is accurate enough that the layered shells it defines will enclose every relevant surface detail without gaps or topological mistakes.
What would settle it
A set of real-world multi-view captures where the final 18k-vertex output shows visible surface tearing or missed fine geometry exactly where the coarse mesh deviated from ground truth would falsify the claim.
Figures





read the original abstract
We present SHELLS (Semantic Head Estimation via Layered Local Sampling), an efficient feed-forward framework for 3D head reconstruction in dense semantic correspondence from multi-view images. Existing methods typically refine vertices independently via localized feature volumes. This approach couples memory-intensive feature sampling to mesh resolution, which limits scalability for dense topologies (> 10k vertices) and introduces surface noise. In contrast, SHELLS decouples feature extraction from mesh resolution via a hierarchical sampling strategy. We extract multi-view features using a DINOv2 backbone with LoRA adaptation, projectively sample a sparse global feature cloud, and predict an intermediate coarse mesh. This coarse prior guides the construction of layered, surface-aware sampling shells that serve as a discrete search space for the final reconstruction. SHELLS maintains surface consistency while using 88% less inference GPU memory (2.4GB vs. 20GB) than volumetric baselines. It reduces median registration error by 21% to 29% with a 3.5x inference speedup (0.08s vs. 0.29s) for 18k-vertex meshes. Notably, our model is trained exclusively on synthetic data yet generalizes effectively to real-world captures, eliminating the need for the costly, pre-registered multi-view datasets common in prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHELLS, a feed-forward framework for dense semantic 3D head reconstruction from multi-view images. It extracts features with a DINOv2+LoRA backbone, projects them to a sparse global feature cloud, predicts an intermediate coarse mesh, and uses this prior to construct layered surface-aware sampling shells as the discrete search space for the final dense vertices. The central claims are an 88% reduction in inference GPU memory (2.4 GB vs. 20 GB), 3.5× speedup (0.08 s vs. 0.29 s), and 21–29% lower median registration error for 18 k-vertex meshes, all while training exclusively on synthetic data and generalizing to real captures.
Significance. If the performance numbers and generalization claims hold under rigorous evaluation, the work would provide a practical route to topologically consistent dense head models at scale, removing the need for costly pre-registered real-world multi-view datasets that have limited prior methods. The hierarchical decoupling of feature sampling from final mesh resolution is a clear engineering contribution for memory-constrained settings.
major comments (1)
- [Method description (coarse-mesh prediction and shell construction)] The reported gains in memory, speed, and registration error all rest on the unverified assumption that the coarse mesh derived from the sparse feature cloud is sufficiently accurate to place layered shells that enclose all relevant surface detail without topological errors or missing geometry. No quantitative bound on coarse-mesh deviation (e.g., maximum surface distance in high-curvature regions under view sparsity) or ablation showing robustness when this assumption is stressed appears in the manuscript.
minor comments (2)
- [Abstract] The abstract states quantitative improvements but supplies no information on exact baselines, evaluation protocols, error bars, or dataset statistics, making the central performance assertions difficult to verify from the given text.
- [Experiments] Clarify the precise definition of 'median registration error' and the correspondence metric used, including how semantic labels are transferred and evaluated on real-world captures.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to verify the coarse-mesh prior that underpins the shell construction. We address the concern directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Method description (coarse-mesh prediction and shell construction)] The reported gains in memory, speed, and registration error all rest on the unverified assumption that the coarse mesh derived from the sparse feature cloud is sufficiently accurate to place layered shells that enclose all relevant surface detail without topological errors or missing geometry. No quantitative bound on coarse-mesh deviation (e.g., maximum surface distance in high-curvature regions under view sparsity) or ablation showing robustness when this assumption is stressed appears in the manuscript.
Authors: We agree that the manuscript currently lacks explicit quantitative bounds on coarse-mesh deviation and dedicated ablations that stress the assumption under reduced views or high-curvature regions. The final registration and runtime metrics are measured on the dense output and therefore provide only indirect evidence that the shells enclose the surface. In the revision we will add: (i) mean and maximum surface-to-surface distances between the predicted coarse mesh and ground-truth on the synthetic test set, stratified by local curvature and by the number of input views (2–8); (ii) a controlled ablation that perturbs the coarse mesh vertices by increasing amounts or drops input views, measuring the resulting change in final registration error and topological consistency. These results will be reported in a new subsection of the experiments and will include failure-case visualizations when the coarse prior deviates beyond the shell thickness. revision: yes
Circularity Check
No circularity; empirical architecture with no self-referential derivations
full rationale
The provided abstract and description outline an architectural pipeline (DINOv2 feature extraction, sparse cloud projection, coarse mesh prediction, layered shell sampling) whose performance claims (memory reduction, speedup, registration error) are presented strictly as measured empirical outcomes on synthetic-to-real generalization. No equations, fitted parameters renamed as predictions, self-definitional relations, or load-bearing self-citations appear. The central claim rests on the engineering choice of hierarchical sampling rather than any quantity derived from itself by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shape Transformers: Topology-Independent 3D Shape Models Using Trans- formers.Computer Graphics Forum (CGF)41, 2 (2022), 195–207. Victoria Yue Chen, Daoye Wang, Stephan Garbin, Jan Bednarik, Sebastian Winberg, Timo Bolkart, and Thabo Beeler. 2025. Pixels2Points: Fusing 2D and 3D Features for Facial Skin Segmentation. InEurographics 2025 - Short Papers. Th...
-
[2]
In Advances in Neural Information Processing Systems (NeurIPS)
PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems (NeurIPS). Shenhan Qian. 2024. VHAP: Versatile Head Alignment with Adaptive Appearance Priors. doi:10.5281/zenodo.14988309 Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. 2024....
-
[3]
InConference on Computer Vision and Pattern Recognition (CVPR)
DUSt3R: Geometric 3D Vision Made Easy. InConference on Computer Vision and Pattern Recognition (CVPR). IEEE, 20697–20709. Yating Wang, Ran Yi, Xiaoning Lei, Ke Fan, Jinkun Hao, and Lizhuang Ma. 2026. Re- constructing Topology-Consistent Face Mesh by Volume Rendering from Multi- View Images. InInternational Conference on Acoustics, Speech and Signal Proces...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.