Assessing Sample Quality in Conditional Generation under Compositional Shift
Pith reviewed 2026-06-27 17:19 UTC · model grok-4.3
The pith
A per-sample trust score using only training data ranks and filters conditional generations under compositional shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
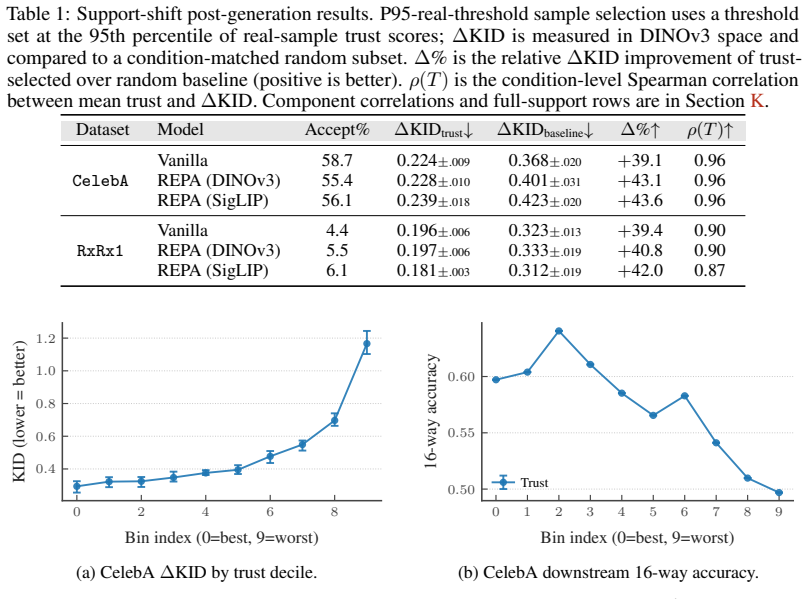
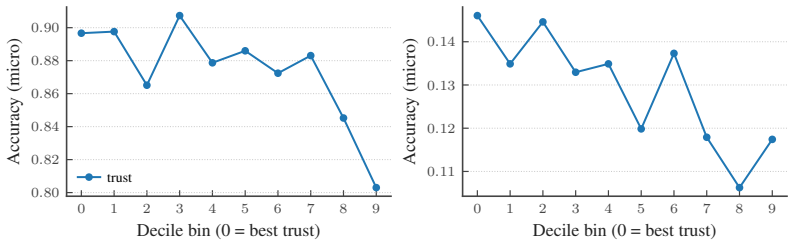
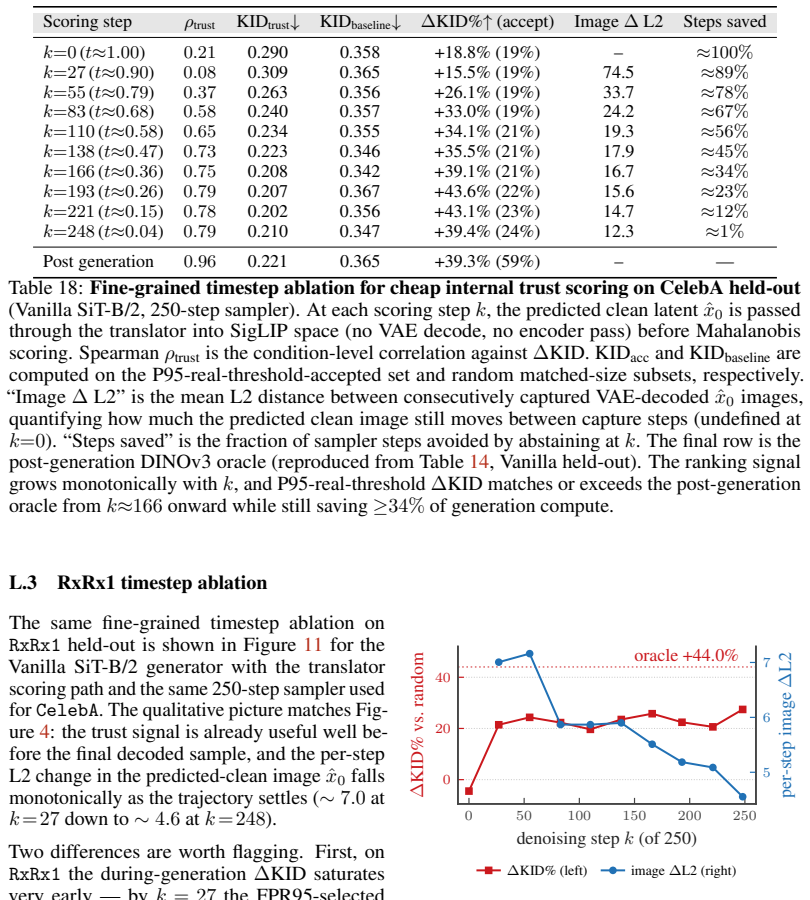
The central claim is that the trust score recovers meaningful comparisons across extrapolated generations under a mild coverage condition on the observed attributes. The score is formed from estimates of global realism and attribute-wise faithfulness, both computable from the training distribution. These comparisons support filtering, ranking, and abstention, and the score applies directly to off-the-shelf pretrained conditional generators. In biological imaging, generations selected by the score preserve real morphological structure better and improve downstream predictive performance, with analogous gains on controlled vision benchmarks. The score can also be used during generation to abst
What carries the argument
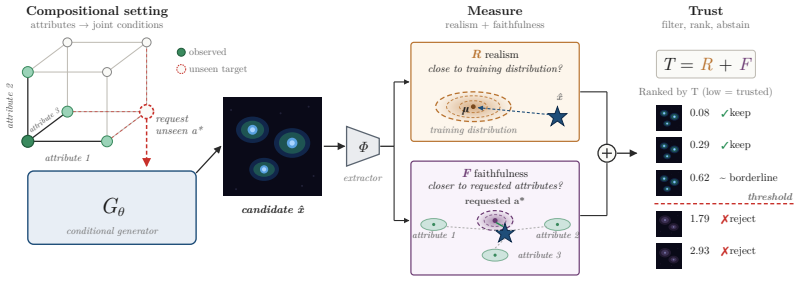
The per-sample trust score that adds global realism (compatibility with the training data manifold) to attribute-wise faithfulness (closer match to requested attributes than to alternatives).
If this is right
- The score enables effective filtering, ranking, and abstention of generations in the extrapolative regime.
- It applies directly to off-the-shelf pretrained conditional models without retraining.
- In biological imaging, selected samples preserve real morphological structure better than unselected ones.
- Downstream predictive performance improves when using samples chosen by the score.
- The score supports abstention decisions before full decoding during the generation process.
Where Pith is reading between the lines
- The same score construction could be tested on generative models for text or audio where novel attribute combinations also arise.
- The coverage condition points to a natural experiment: measure how ranking quality degrades as attribute coverage in the training set is deliberately thinned.
- The score might be inserted into the sampling loop itself to steer generation toward higher-trust outputs without changing the underlying model.
- It offers a concrete way to quantify the gap between in-distribution and out-of-composition performance that could be compared across different conditioning mechanisms.
Load-bearing premise
The mild coverage condition on the observed attributes is needed for the score to produce meaningful comparisons in the extrapolative regime.
What would settle it
A direct comparison in which real samples from the new attribute compositions become available and the score's ranking of generated samples disagrees with the ranking obtained from those real samples.
Figures

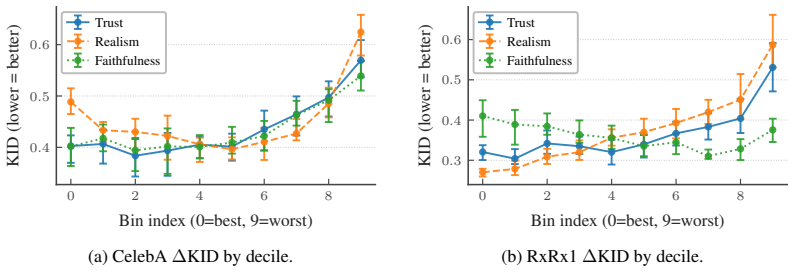
read the original abstract
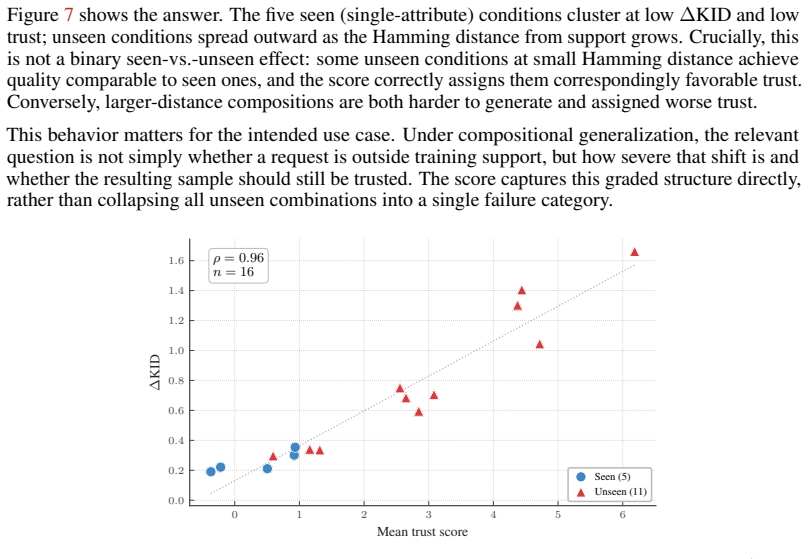
Conditional generators provide a natural tool for controllable generation, including settings where the desired condition is a new composition of observed attributes or experimental factors. In many applications, especially in scientific domains, such models are attractive to explore conditions for which real samples are rare, expensive, or not yet observed. However, this creates a circularity for evaluation: standard conditional quality metrics require a reference target distribution, but in the extrapolative regime that distribution is unavailable by definition. We address this problem with a post-hoc, per-sample trust score for assessing conditional samples using only the training distribution. The score combines two estimable quantities: global realism, measuring compatibility with the real data manifold, and attribute-wise faithfulness, measuring whether a sample is closer to the requested attributes than to plausible alternatives. We show that the score can recover meaningful comparisons across extrapolated generations, under a mild coverage condition on the observed attributes. These comparisons enable effective filtering, ranking, and abstention of generations and can be used directly on off-the-shelf pretrained models. In biological imaging, selected samples preserve real morphological structure better and improve downstream predictive performance, while similar gains are observed on controlled vision benchmarks. Finally, we show how the score can be applied during generation, enabling abstention before full decoding. Code is available at https://github.com/berkerdemirel/faithful-cond-gen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-hoc per-sample trust score for conditional generators in compositional extrapolation settings (where target distributions are unavailable). The score combines global realism (compatibility with the training data manifold) and attribute-wise faithfulness (relative closeness to requested attributes versus alternatives), both estimated solely from the training distribution. It claims that under a mild coverage condition on observed attributes, the score recovers meaningful comparisons that support filtering, ranking, and abstention of generations; this is demonstrated on biological imaging (preserving morphology and improving downstream prediction) and controlled vision benchmarks, and works with off-the-shelf pretrained models. Code is provided.
Significance. If the coverage condition holds with the claimed sufficiency, the approach offers a practical, reference-free method for assessing extrapolated conditional samples in scientific domains where real data for new compositions is scarce. The combination of two estimable quantities and direct applicability to pretrained models is a strength; code availability supports reproducibility.
major comments (2)
- [Theoretical section defining the coverage condition and score properties] The central claim that the score 'recovers meaningful comparisons across extrapolated generations' rests on the mild coverage condition (invoked in the abstract and theoretical development). However, the precise requirements of this condition and its sufficiency to control bias in the attribute-wise faithfulness term (when target compositions are unseen) are not rigorously established; without explicit bounds or a proof that training-distribution distances still induce correct ranking under compositional shift, the justification for filtering/ranking/abstention is load-bearing and under-supported.
- [Experimental results on biological imaging] In the biological imaging experiments, the reported gains in morphological structure preservation and downstream predictive performance are presented as evidence of the score's utility, but the paper does not include controls or ablations testing performance when the coverage condition is mildly violated (e.g., via synthetic shifts that break attribute coverage); this leaves open whether the empirical improvements are attributable to the score or to other factors.
minor comments (2)
- [Abstract] The abstract refers to the 'mild coverage condition' without a one-sentence characterization or pointer to its formal statement, which would improve accessibility.
- [Method section] Notation for the two components of the score (global realism and attribute-wise faithfulness) should be introduced with explicit equations early in the method section to avoid ambiguity when discussing their combination.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below, clarifying the role of the coverage condition and outlining planned revisions to strengthen both the theoretical and experimental sections.
read point-by-point responses
-
Referee: [Theoretical section defining the coverage condition and score properties] The central claim that the score 'recovers meaningful comparisons across extrapolated generations' rests on the mild coverage condition (invoked in the abstract and theoretical development). However, the precise requirements of this condition and its sufficiency to control bias in the attribute-wise faithfulness term (when target compositions are unseen) are not rigorously established; without explicit bounds or a proof that training-distribution distances still induce correct ranking under compositional shift, the justification for filtering/ranking/abstention is load-bearing and under-supported.
Authors: We agree that the manuscript would benefit from a more explicit formalization of how the coverage condition ensures correct ranking under compositional shift. The condition is introduced in the theoretical development to ensure that attribute-wise distances estimated from the training distribution remain informative for unseen compositions. In revision we will add a dedicated proposition that states the precise coverage requirement (every relevant attribute appears with sufficient diversity in the observed data) together with a short proof sketch showing that the faithfulness term preserves the correct ordering in expectation; we will also include a brief discussion of the resulting bias term when coverage is only approximate. revision: yes
-
Referee: [Experimental results on biological imaging] In the biological imaging experiments, the reported gains in morphological structure preservation and downstream predictive performance are presented as evidence of the score's utility, but the paper does not include controls or ablations testing performance when the coverage condition is mildly violated (e.g., via synthetic shifts that break attribute coverage); this leaves open whether the empirical improvements are attributable to the score or to other factors.
Authors: We acknowledge that an explicit ablation under controlled violations of coverage would make the empirical claims more robust. The biological dataset satisfies the coverage condition by design, which is why the reported gains appear. In the revision we will add a controlled synthetic experiment on a vision benchmark in which we deliberately remove selected attribute co-occurrences to create mild coverage violations and report the resulting drop in the score's ability to rank or filter samples; this will directly link the observed improvements to the condition holding. revision: yes
Circularity Check
No significant circularity: score defined from independent training-distribution quantities under explicit assumption.
full rationale
The paper defines its trust score directly from two quantities (global realism and attribute-wise faithfulness) that are estimable from the training distribution alone. The claim that this score recovers meaningful comparisons is conditioned on an explicitly invoked 'mild coverage condition on the observed attributes,' which functions as an assumption rather than a derived equality. No equations, self-citations, or fitted-parameter renamings are shown that would reduce the score or its extrapolation properties to the inputs by construction. The derivation therefore remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela Van Der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International conference on machine learning, pages 290–306. PMLR, 2022
2022
-
[2]
Synthetic data from diffusion models improves ImageNet classification.Transactions on Machine Learning Research, 2023
Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mohammad Norouzi, and David J Fleet. Synthetic data from diffusion models improves ImageNet classification.Transactions on Machine Learning Research, 2023
2023
-
[3]
Demystifying MMD GANs
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. InInternational Conference on Learning Representations, 2018
2018
-
[4]
Cellprofiler: image analysis software for identifying and quantifying cell phenotypes.Genome biology, 7:R100, 2006
Anne E Carpenter, Thouis R Jones, Michael R Lamprecht, Colin Clarke, In Han Kang, Ola Friman, David A Guertin, Joo Han Chang, Robert A Lindquist, Jason Moffat, et al. Cellprofiler: image analysis software for identifying and quantifying cell phenotypes.Genome biology, 7:R100, 2006
2006
-
[5]
Berker Demirel, Marco Fumero, Theofanis Karaletsos, and Francesco Locatello. Mor- phgen: Controllable and morphologically plausible generative cell-imaging.arXiv preprint arXiv:2510.01298, 2025
-
[6]
Out-of-distribution detection with relative angles
Berker Demirel, Marco Fumero, and Francesco Locatello. Out-of-distribution detection with relative angles. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[7]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. In Advances in Neural Information Processing Systems, 2021
2021
-
[8]
Alessandro Favero, Antonio Sclocchi, Francesco Cagnetta, Pascal Frossard, and Matthieu Wyart. How compositional generalization and creativity improve as diffusion models are trained.arXiv preprint arXiv:2502.12089, 2025
-
[9]
Coind: Enabling logical compositions in diffusion models
Sachit Gaudi, Gautam Sreekumar, and Vishnu Boddeti. Coind: Enabling logical compositions in diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
Is synthetic data from generative models ready for image recognition? In International Conference on Learning Representations, 2023
Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip Torr, Song Bai, and Xiaojuan Qi. Is synthetic data from generative models ready for image recognition? In International Conference on Learning Representations, 2023
2023
-
[11]
GANs trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, 2017
2017
-
[12]
Masked autoencoders for microscopy are scalable learners of cellular biology
Oren Kraus, Kian Kenyon-Dean, Saber Saberian, Maryam Fallah, Peter McLean, Jess Leung, Vasudev Sharma, Ayla Khan, Jia Balakrishnan, Safiye Celik, et al. Masked autoencoders for microscopy are scalable learners of cellular biology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11757–11768, 2024
2024
-
[13]
Improved precision and recall metric for assessing generative models.Advances in neural information processing systems, 32, 2019
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models.Advances in neural information processing systems, 32, 2019. 10
2019
-
[14]
A well-conditioned estimator for large-dimensional covariance matrices.Journal of Multivariate Analysis, 88(2):365–411, 2004
Olivier Ledoit and Michael Wolf. A well-conditioned estimator for large-dimensional covariance matrices.Journal of Multivariate Analysis, 88(2):365–411, 2004
2004
-
[15]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks.Advances in neural information processing systems, 31, 2018
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks.Advances in neural information processing systems, 31, 2018
2018
-
[16]
Fast decision boundary based out-of-distribution detector
Litian Liu and Yao Qin. Fast decision boundary based out-of-distribution detector. InForty-first International Conference on Machine Learning, 2024
2024
-
[17]
Energy-based out-of-distribution detection.Advances in neural information processing systems, 33:21464–21475, 2020
Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection.Advances in neural information processing systems, 33:21464–21475, 2020
2020
-
[18]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InInternational Conference on Computer Vision, 2015
2015
-
[19]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024
2024
-
[20]
Mahalanobis++: Improving OOD detection via feature normalization
Maximilian Müller and Matthias Hein. Mahalanobis++: Improving OOD detection via feature normalization. InForty-second International Conference on Machine Learning, 2025
2025
-
[21]
Reliable fidelity and diversity metrics for generative models
Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. InInternational Conference on Machine Learning, 2020
2020
-
[22]
Morphodiff: Cellular morphology painting with diffusion models
Zeinab Navidi, Jun Ma, Esteban Miglietta, Le Liu, Anne E Carpenter, Beth A Cimini, Benjamin Haibe-Kains, and Bo Wang. Morphodiff: Cellular morphology painting with diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[23]
Dick, and Hidenori Tanaka
Maya Okawa, Ekdeep Singh Lubana, Robert P. Dick, and Hidenori Tanaka. Compositional abilities emerge multiplicatively: Exploring diffusion models on a synthetic task. InThirty- seventh Conference on Neural Information Processing Systems, 2023
2023
-
[24]
Emergence of hidden capabilities: Exploring learning dynamics in concept space.Advances in Neural Information Processing Systems, 37:84698–84729, 2024
Core F Park, Maya Okawa, Andrew Lee, Hidenori Tanaka, and Ekdeep S Lubana. Emergence of hidden capabilities: Exploring learning dynamics in concept space.Advances in Neural Information Processing Systems, 37:84698–84729, 2024
2024
-
[25]
Probabilistic precision and recall towards reliable evaluation of generative models
Dogyun Park and Suhyun Kim. Probabilistic precision and recall towards reliable evaluation of generative models. InProceedings of the IEEE/CVF international conference on computer vision, pages 20099–20109, 2023
2023
-
[26]
Nearest neighbor guidance for out-of-distribution detection
Jaewoo Park, Yoon Gyo Jung, and Andrew Beng Jin Teoh. Nearest neighbor guidance for out-of-distribution detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 1686–1695, 2023
2023
-
[27]
Early Estimation of Language to Latent Alignment in Diffusion Models
Vasco Ramos, Regev Cohen, Idan Szpektor, and Joao Magalhaes. Beyond the noise: Aligning prompts with latent representations in diffusion models.arXiv preprint arXiv:2512.08505, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Jie Ren, Stanislav Fort, Jeremiah Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Laksh- minarayanan. A simple fix to mahalanobis distance for improving near-ood detection.arXiv preprint arXiv:2106.09022, 2021
-
[29]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[30]
As- sessing generative models via precision and recall.Advances in neural information processing systems, 31, 2018
Mehdi SM Sajjadi, Olivier Bachem, Mario Lucic, Olivier Bousquet, and Sylvain Gelly. As- sessing generative models via precision and recall.Advances in neural information processing systems, 31, 2018. 11
2018
-
[31]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Out-of-distribution detection with deep nearest neighbors
Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out-of-distribution detection with deep nearest neighbors. InInternational conference on machine learning, pages 20827–20840. PMLR, 2022
2022
-
[33]
Rxrx1: A dataset for evaluating experimental batch correction methods
Maciej Sypetkowski, Morteza Rezanejad, Saber Saberian, Oren Kraus, John Urbanik, James Taylor, Ben Mabey, Mason Victors, Jason Yosinski, Alborz Rezazadeh Sereshkeh, et al. Rxrx1: A dataset for evaluating experimental batch correction methods. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4285–4294, 2023
2023
-
[34]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[35]
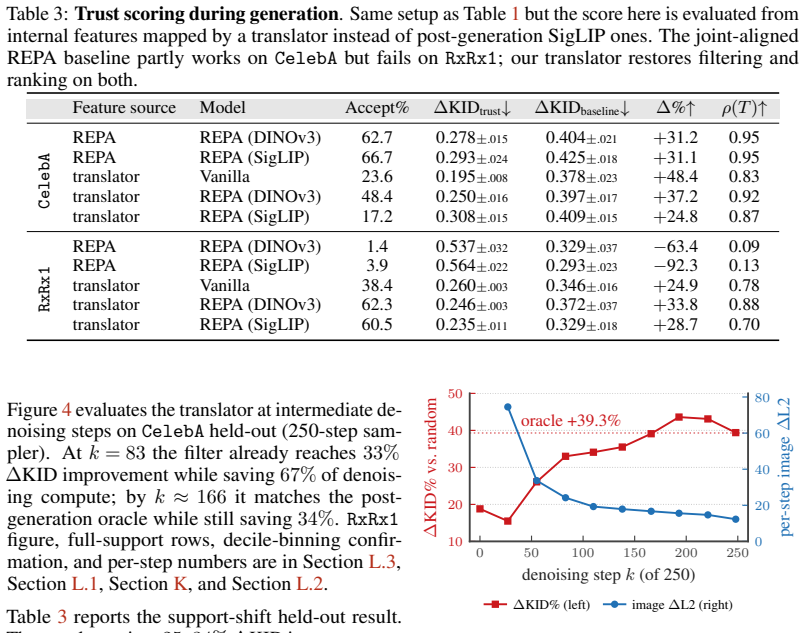
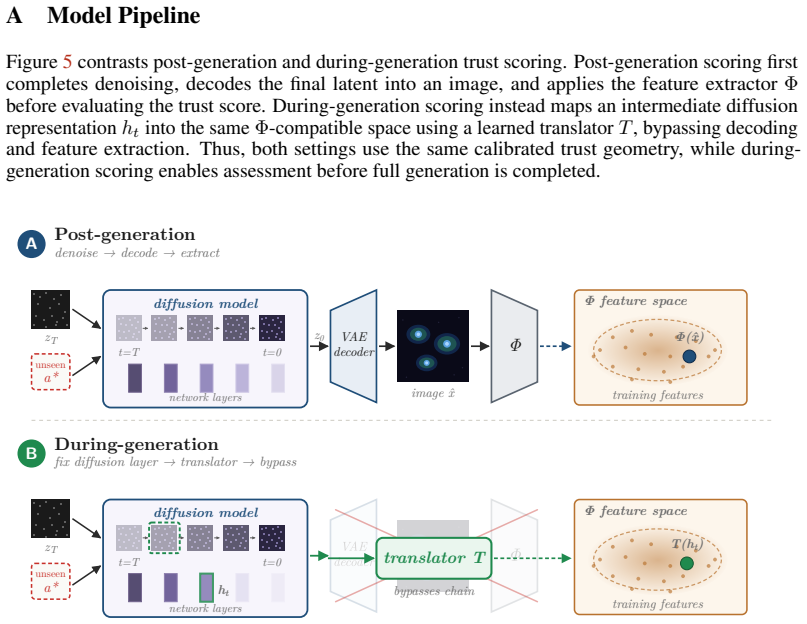
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 12 A Model Pipeline Figure 5 contrasts post-generation and during-generation trust scoring. Post-generation scoring first completes denoising, ...
-
[36]
This is below any stable per-condition KID bootstrap
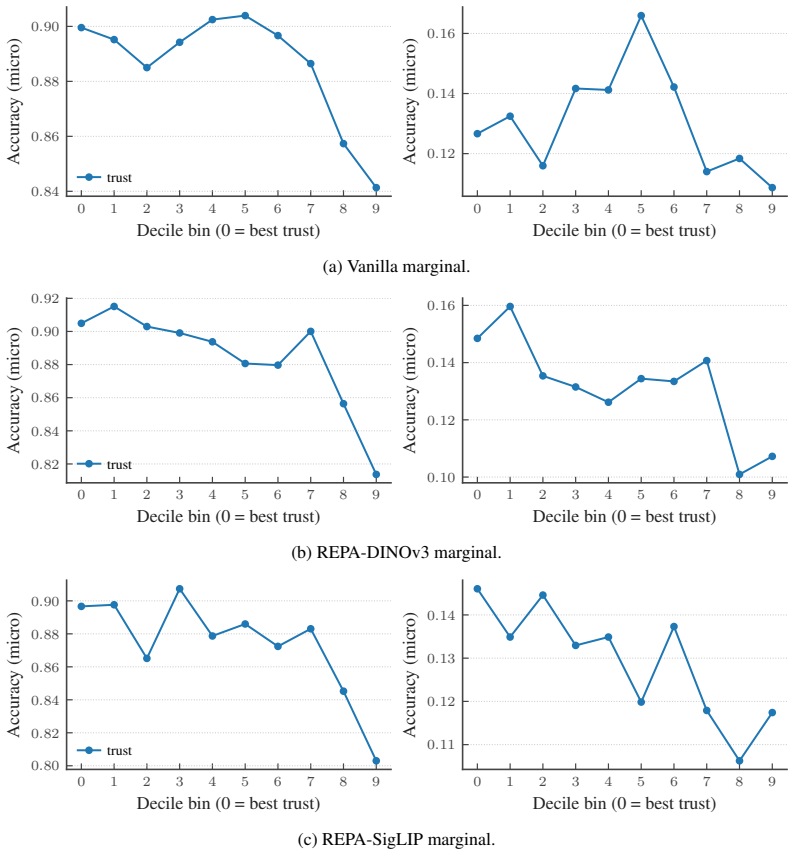
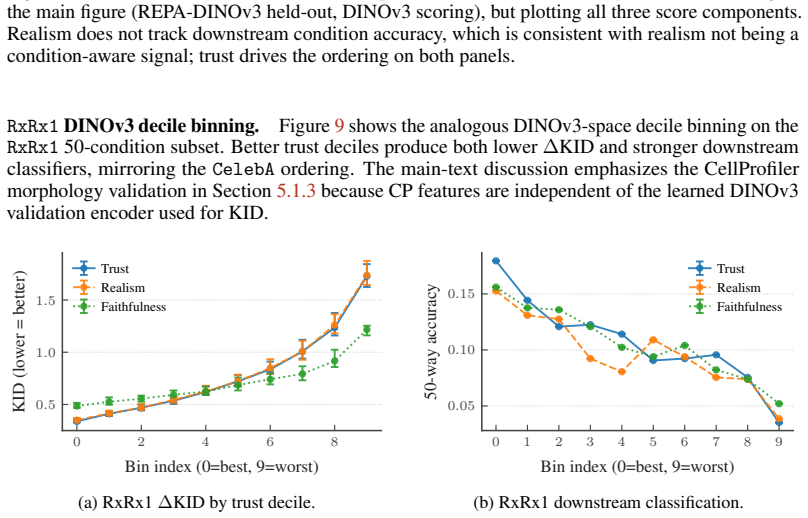
Filler rows.13 of the 25 seen conditions (all ct=0 and ct=2 non-controls) had only n=14 real samples each. This is below any stable per-condition KID bootstrap. Under a class-balanced probe on the 50-class subproblem, these rows collapse to top-1 ≈0—the probe cannot distinguish them from each other or from the rest of the catalog. They contribute no usabl...
-
[37]
The support-shift test therefore covered a single class of perturbations rather than the diversity the held-out set was designed to provide
No unseen functional diversity.The unseen part of the test set contained only control wells, even though several non-control held-out perturbations were available in held-out set of the diffusion training. The support-shift test therefore covered a single class of perturbations rather than the diversity the held-out set was designed to provide
-
[38]
Trust spread
Imbalance-probe confound.A class-imbalanced probe resulted in a class-frequency artifact: controls dominate the per-class sample counts. Under a class-balanced probe restricted to the 50-class subproblem, the controls collapse and the genuinely discriminable rows are the non-control siRNAs together with a smaller subset of controls. Any subset that does n...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.