Transformed Latent Variable Multi-Output Gaussian Processes
Pith reviewed 2026-05-21 07:56 UTC · model grok-4.3
The pith
A Lipschitz-regularised neural network embeds inputs and output latents to build a scalable deep kernel for multi-output Gaussian processes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
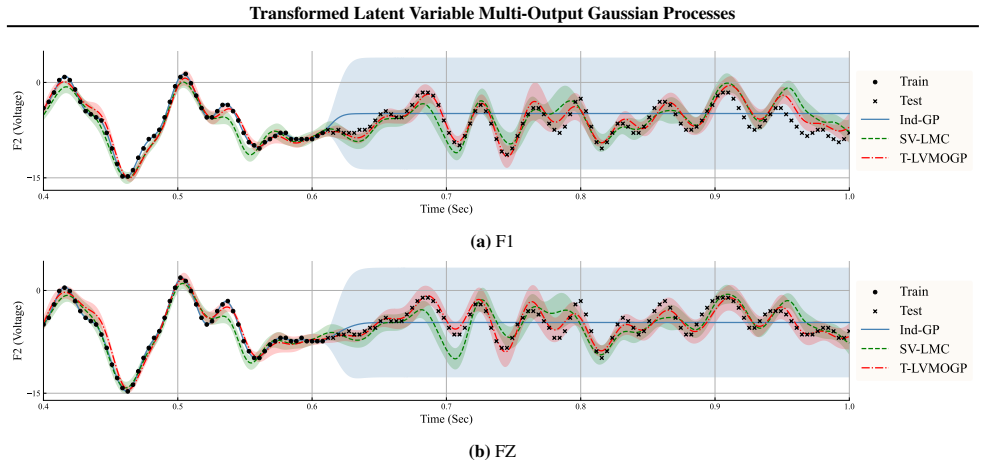
The Transformed Latent Variable Multi-Output Gaussian Process constructs a flexible multi-output deep kernel by mapping inputs and output-specific latent variables into an embedding space using a Lipschitz-regularised neural network; when combined with stochastic variational inference the resulting model scales to high-dimensional output settings while retaining the capacity to capture meaningful inter-output dependencies and yields improved predictive accuracy and computational efficiency on benchmarks such as climate data with more than 10,000 outputs.
What carries the argument
The Lipschitz-regularised neural network that maps each input together with output-specific latent variables into a shared embedding space to define the multi-output deep kernel.
If this is right
- The model delivers higher predictive accuracy than low-rank or separable-kernel baselines on climate and transcriptomics tasks.
- Training and prediction remain computationally tractable for output spaces exceeding 10,000 dimensions.
- Inter-output dependencies are captured without imposing low-rank or sum-of-separable restrictions on the kernel.
- The same framework applies directly to zero-inflated count data arising in spatial transcriptomics.
Where Pith is reading between the lines
- The embedding construction could be reused inside other kernel families to obtain scalable multi-task models beyond Gaussian processes.
- Because the regularization controls Lipschitz constants, the same architecture may remain stable when output dimensionality grows further.
- The latent-variable embedding suggests a natural route for incorporating side information about output relationships into the kernel.
Load-bearing premise
The neural network mapping yields embeddings that define a positive definite kernel compatible with the Gaussian process prior and its variational inference scheme.
What would settle it
On a dataset with thousands of outputs and known ground-truth correlations, the model would be falsified if it produced worse predictive accuracy or slower training than a low-rank baseline while also failing to recover the known inter-output structure in its posterior.
Figures









read the original abstract
Multi-Output Gaussian Processes (MOGPs) provide a principled probabilistic framework for modelling correlated outputs but face scalability bottlenecks when applied to datasets with high-dimensional output spaces. To maintain tractability, existing methods typically resort to restrictive assumptions, such as employing low-rank or sum-of-separable kernels, which can limit expressiveness. We propose the Transformed Latent Variable MOGP (T-LVMOGP), a novel framework that scales MOGPs to a massive number of outputs while preserving the capacity to capture meaningful inter-output dependencies. T-LVMOGP constructs a flexible multi-output deep kernel by mapping inputs and output-specific latent variables into an embedding space using a Lipschitz-regularised neural network. Combined with stochastic variational inference, our model effectively scales to high-dimensional output settings. Across diverse benchmarks, including climate modelling with over 10,000 outputs and zero-inflated spatial transcriptomics data, T-LVMOGP outperforms baselines in both predictive accuracy and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Transformed Latent Variable Multi-Output Gaussian Process (T-LVMOGP) to scale MOGPs to high-dimensional output spaces. It constructs a flexible multi-output deep kernel by embedding inputs and output-specific latent variables via a Lipschitz-regularised neural network, then applies stochastic variational inference for tractability. The approach is evaluated on climate modelling (>10,000 outputs) and zero-inflated spatial transcriptomics, claiming improved predictive accuracy and efficiency over baselines while retaining inter-output dependency modeling.
Significance. If the kernel construction is valid and the empirical gains hold with proper controls, this would represent a meaningful step toward expressive yet scalable multi-output GPs, relaxing the low-rank or separable assumptions common in prior work. The combination of latent variables per output with Lipschitz-regularised embeddings is a constructive idea that could extend deep kernel learning to massive output regimes.
major comments (1)
- [§3] §3 (Kernel Construction): The central claim that the Lipschitz-regularised NN produces a valid PSD multi-output kernel k((x,u_y),(x',u_y')) when composed with output-specific latent variables is not rigorously established. Lipschitz regularization bounds gradient norms but supplies no automatic guarantee that the induced kernel matrix remains positive semi-definite for arbitrary finite sets of (x,u) pairs; without an additional argument (e.g., via the base kernel choice or an explicit PSD projection), the GP definition and the SVI evidence lower bound are at risk. This is load-bearing for the scalability claim to >10k outputs.
minor comments (2)
- [Experiments] Experiments section: quantitative results should report standard errors or confidence intervals across multiple runs; ablation on the Lipschitz regularization coefficient and on the dimensionality of the output-specific latents would strengthen the empirical case.
- [Notation] Notation: clarify whether the embedding network is shared across outputs or output-specific, and specify the exact form of the base kernel used inside the embedding space.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address the major comment regarding the kernel construction in detail below.
read point-by-point responses
-
Referee: [§3] §3 (Kernel Construction): The central claim that the Lipschitz-regularised NN produces a valid PSD multi-output kernel k((x,u_y),(x',u_y')) when composed with output-specific latent variables is not rigorously established. Lipschitz regularization bounds gradient norms but supplies no automatic guarantee that the induced kernel matrix remains positive semi-definite for arbitrary finite sets of (x,u) pairs; without an additional argument (e.g., via the base kernel choice or an explicit PSD projection), the GP definition and the SVI evidence lower bound are at risk. This is load-bearing for the scalability claim to >10k outputs.
Authors: We appreciate the referee pointing out the need for a rigorous justification of the positive semi-definiteness of our multi-output kernel. The kernel in T-LVMOGP is constructed by first embedding the input x and the output-specific latent variable u_y using a neural network φ to obtain an embedding vector. The multi-output kernel is then defined as k((x, u_y), (x', u_y')) = k_0(φ(x, u_y), φ(x', u_y')), where k_0 is a standard positive definite base kernel, such as the radial basis function kernel. It is a well-known result that the composition of a positive definite kernel with an arbitrary mapping yields another positive definite kernel. Therefore, the resulting kernel matrix is positive semi-definite for any finite collection of points by construction. The Lipschitz regularization on the neural network is introduced to promote Lipschitz continuity of the embedding, which aids in controlling the model's sensitivity and improving generalization, but it is not required for the PSD property. We will revise Section 3 to include this explicit argument and a reference to the relevant literature on deep kernel learning to address this concern. revision: partial
Circularity Check
No significant circularity; constructive model definition with independent content
full rationale
The paper defines T-LVMOGP via an explicit construction: a Lipschitz-regularised neural network maps inputs and output-specific latent variables into an embedding space to form a multi-output deep kernel, then applies SVI for scalability. This is a forward architectural proposal rather than a reduction of any claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. No equations are shown that equate a derived quantity to its own inputs (e.g., no per-period scale fitted then renamed as a ratio prediction). Self-citations, if present, are not load-bearing for the central claim; the framework retains independent content from the proposed NN embedding and remains compatible with standard GP positive-definiteness requirements under the stated assumptions. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network architecture and Lipschitz regularization strength
axioms (1)
- domain assumption The Lipschitz-regularised mapping produces a valid positive-definite multi-output kernel
invented entities (1)
-
Output-specific latent variables
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
T-LVMOGP constructs a flexible multi-output deep kernel by mapping inputs and output-specific latent variables into an embedding space using a Lipschitz-regularised neural network.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We regularise the neural network via residual connections and spectral normalisation. This encourages the transformation to be Lipschitz continuous
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.