MADE: Beyond Scoring via a Multilingual Agentic Diagnosing Engine for Fine-Grained Evaluation Insights
Pith reviewed 2026-06-27 22:14 UTC · model grok-4.3
The pith
MADE decomposes multilingual benchmark diagnosis into planning, inspection, reflection and synthesis steps to produce reports that experts prefer over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
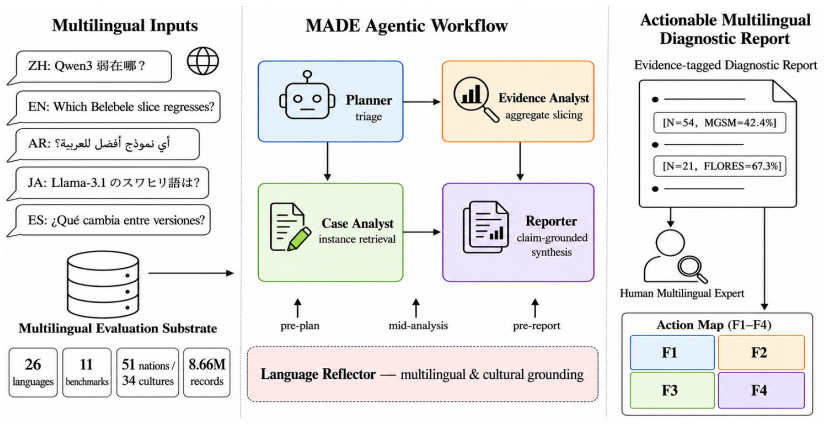
MADE is a Multilingual Agentic Diagnosing Engine that decomposes post-evaluation analysis into five explicit stages—planning, aggregate analysis, instance-level case inspection, multilingual and cultural reflection, and grounded report synthesis—and pairs this workflow with an expert-led 54-query diagnostic set spanning 15 languages; when run over a large multilingual evaluation substrate the resulting reports are rated 47 percent higher in quality than those from the strongest baseline and are chosen by human multilingual experts in 87.9 percent of pairwise comparisons.
What carries the argument
MADE, the agentic workflow that sequences planning, aggregate analysis, instance inspection, cultural reflection and report synthesis over long diagnostic inputs.
If this is right
- Benchmark score tables can be converted into model-selection and remediation guidance rather than remaining metric-rich and insight-poor.
- Four actionable findings on deployment, iteration and cross-cultural pitfalls become visible once diagnosis reports are produced at scale.
- Single LLMs and open-ended agents are shown to be insufficient for long, noisy diagnostic inputs, establishing the need for structured decomposition.
- The same five-stage workflow can be reused across different model families and benchmarks without redesigning the diagnostic taxonomy.
Where Pith is reading between the lines
- Extending the diagnostic query set to additional languages would test whether the current 47 percent quality gain holds or shrinks.
- The structured reports could be fed back into model training loops as targeted supervision signals for cross-lingual robustness.
- Similar agentic decomposition might improve diagnosis of other complex evaluation outputs such as safety or reasoning traces.
- If the reflection stage is removed, report quality would likely fall closer to baseline levels, isolating the contribution of cultural analysis.
Load-bearing premise
The expert-designed set of 54 queries in 15 languages is representative enough to measure report quality reliably across the full range of 26 languages and 34 cultures in the evaluation substrate.
What would settle it
Human experts rating MADE-generated reports lower than baseline reports on a new collection of languages and cultures outside the original 15-language query set would falsify the claim of consistent superiority.
Figures
read the original abstract
Multilingual and multicultural benchmarks now cover dozens of languages and model families, but the resulting score landscapes remain metric-rich and insight-poor, necessitating fine-grained multilingual post-evaluation diagnosis. However, single LLMs and open-ended agents are easily swamped by the long, noisy diagnostic input, and no reusable taxonomy exists for it. To address this, we propose MADE, a Multilingual Agentic Diagnosing Engine that decomposes post-evaluation analysis into planning, aggregate analysis, instance-level case inspection, multilingual and cultural reflection, and grounded report synthesis. MADE is paired with an expert-led 54-query and 15-language diagnostic set, evaluated on top of a large-scale multilingual evaluation substrate (33 model families, 11 benchmarks, 26 languages, 34 cultures, 8.66M evaluation records). Experiments show that MADE outperforms the strongest shared baseline by 47% in diagnosis report quality and is preferred by human multilingual experts in 87.9% of pairwise comparisons. Applied with multilingual experts, MADE further surfaces four actionable findings on deployment, iteration, and cross-cultural pitfalls, turning benchmark score tables into model-selection and remediation guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MADE, a Multilingual Agentic Diagnosing Engine that decomposes post-evaluation analysis of multilingual benchmarks into planning, aggregate analysis, instance-level case inspection, multilingual and cultural reflection, and grounded report synthesis. It introduces an expert-led 54-query 15-language diagnostic set and evaluates the system on a large substrate spanning 33 model families, 11 benchmarks, 26 languages, 34 cultures, and 8.66M records. The central empirical claims are a 47% improvement in diagnosis report quality over the strongest shared baseline and 87.9% preference by human multilingual experts in pairwise comparisons, plus four actionable findings on deployment and cross-cultural issues.
Significance. If the results hold after addressing sampling concerns, the work supplies a structured, reusable method for converting dense multilingual score tables into interpretable diagnostic reports that support model selection and remediation. The scale of the underlying evaluation substrate (8.66M records across 26 languages) is a clear strength that enables broad coverage not typical in prior diagnostic efforts.
major comments (2)
- [Abstract] Abstract: The 47% quality gain and 87.9% expert preference are measured exclusively on the 54-query/15-language diagnostic set. The substrate spans 26 languages and 34 cultures; without evidence of stratified sampling across low-resource languages, script families, or cultural axes, these margins are conditional on an untested representativeness assumption and do not establish robustness for the full substrate.
- [Abstract] Abstract and evaluation description: No details are supplied on baseline construction, statistical testing for the 47% claim, or inter-annotator agreement in the human preference study, leaving the soundness of the reported margins difficult to assess.
minor comments (1)
- [Abstract] The phrase 'expert-led' for the diagnostic set would benefit from explicit criteria used to select the 54 queries and ensure coverage of the 34 cultures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and commit to revisions that improve clarity and completeness without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 47% quality gain and 87.9% expert preference are measured exclusively on the 54-query/15-language diagnostic set. The substrate spans 26 languages and 34 cultures; without evidence of stratified sampling across low-resource languages, script families, or cultural axes, these margins are conditional on an untested representativeness assumption and do not establish robustness for the full substrate.
Authors: The reported quality metrics (47% improvement and 87.9% preference) were obtained on the expert-curated 54-query diagnostic set spanning 15 languages, while the 8.66M-record substrate (26 languages, 34 cultures) supplies the evaluation instances to which MADE is applied. The diagnostic set was intentionally scoped to enable controlled, high-quality human assessment. We agree that explicit documentation of language and query selection criteria is needed. In revision we will add a dedicated subsection describing the expert-led construction process, including how languages were chosen to span resource levels, scripts, and cultural axes within the 15-language scope. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No details are supplied on baseline construction, statistical testing for the 47% claim, or inter-annotator agreement in the human preference study, leaving the soundness of the reported margins difficult to assess.
Authors: We acknowledge these omissions. The revised manuscript will expand the evaluation section to specify: (i) the exact architecture and prompting of the strongest shared baseline, (ii) the statistical tests (including test type, sample size, and p-values) used to support the 47% quality gain, and (iii) inter-annotator agreement statistics (e.g., Fleiss’ kappa) computed on the human preference annotations. These additions will allow independent assessment of the reported margins. revision: yes
Circularity Check
No significant circularity; claims rest on external human evaluations.
full rationale
The paper introduces MADE as an agentic system for diagnosis report generation and reports empirical gains (47% quality improvement, 87.9% expert preference) measured via human multilingual experts on an expert-led diagnostic set. No equations, parameter fits, self-citations, or uniqueness theorems are invoked that reduce these outcomes to definitions or inputs by construction. The evaluation substrate and human judgments function as independent external benchmarks, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[2]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[3]
arXiv preprint arXiv:2412.04342 , year=
Retrieval-Augmented Machine Translation with Unstructured Knowledge , author=. arXiv preprint arXiv:2412.04342 , year=
-
[4]
arXiv preprint arXiv:2412.17498 , year=
DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought , author=. arXiv preprint arXiv:2412.17498 , year=
-
[5]
Translation journal , volume=
Translation procedures, strategies and methods , author=. Translation journal , volume=
-
[6]
International Conference on Learning Representations (ICLR) , year=
Language Models are Multilingual Chain-of-Thought Reasoners , author=. International Conference on Learning Representations (ICLR) , year=
-
[7]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[8]
Proceedings of the Ninth Conference on Machine Translation , pages=
Findings of the WMT24 General Machine Translation Shared Task: The LLM Era Is Here but MT Is Not Solved Yet , author=. Proceedings of the Ninth Conference on Machine Translation , pages=
-
[9]
1964 , publisher=
Toward a science of translating: with special reference to principles and procedures involved in Bible translating , author=. 1964 , publisher=
1964
-
[10]
An Encyclopaedia of Translation: Chinese-English, English-Chinese , volume=
Back-translation , author=. An Encyclopaedia of Translation: Chinese-English, English-Chinese , volume=. 2001 , publisher=
2001
-
[11]
T as T e: Teaching Large Language Models to Translate through Self-Reflection
Wang, Yutong and Zeng, Jiali and Liu, Xuebo and Meng, Fandong and Zhou, Jie and Zhang, Min. T as T e: Teaching Large Language Models to Translate through Self-Reflection. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.333
-
[12]
arXiv preprint arXiv:2410.18982 , year=
O1 Replication Journey: A Strategic Progress Report--Part 1 , author=. arXiv preprint arXiv:2410.18982 , year=
-
[13]
arXiv preprint arXiv:2412.00154 , year=
o1-coder: an o1 replication for coding , author=. arXiv preprint arXiv:2412.00154 , year=
-
[14]
arXiv preprint arXiv:2411.14405 , year=
Marco-o1: Towards open reasoning models for open-ended solutions , author=. arXiv preprint arXiv:2411.14405 , year=
-
[15]
Shen, Haozhan and Zhang, Zilun and Zhang, Qianqian and Xu, Ruochen and Zhao, Tiancheng , title =
-
[16]
arXiv preprint arXiv:2501.14431 , year=
Domaino1s: Guiding LLM Reasoning for Explainable Answers in High-Stakes Domains , author=. arXiv preprint arXiv:2501.14431 , year=
-
[17]
2020 , organization=
ParaCrawl: Web-scale acquisition of parallel corpora , author=. 2020 , organization=
2020
-
[18]
Transactions of the Association for Computational Linguistics , volume=
The flores-101 evaluation benchmark for low-resource and multilingual machine translation , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[19]
Findings of the 2018 Conference on Machine Translation ( WMT 18)
Bojar, Ond r ej and Federmann, Christian and Fishel, Mark and Graham, Yvette and Haddow, Barry and Huck, Matthias and Koehn, Philipp and Monz, Christof. Findings of the 2018 Conference on Machine Translation ( WMT 18). Proceedings of the Third Conference on Machine Translation: Shared Task Papers. 2018. doi:10.18653/v1/W18-6401
-
[20]
arXiv preprint arXiv:2501.02448 , year=
Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap , author=. arXiv preprint arXiv:2501.02448 , year=
-
[21]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[22]
arXiv preprint arXiv:2301.08745 , year=
Is ChatGPT a good translator? A preliminary study , author=. arXiv preprint arXiv:2301.08745 , year=
-
[23]
Procesamiento del Lenguaje Natural , volume=
Gradable ChatGPT Translation Evaluation , author=. Procesamiento del Lenguaje Natural , volume=
-
[24]
arXiv preprint arXiv:2303.13780 , year=
Towards making the most of chatgpt for machine translation , author=. arXiv preprint arXiv:2303.13780 , year=
-
[25]
The Twelfth International Conference on Learning Representations , year=
A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
arXiv preprint arXiv:2401.06468 , year=
Adapting large language models for document-level machine translation , author=. arXiv preprint arXiv:2401.06468 , year=
-
[27]
Proceedings of the Eighth Conference on Machine Translation , pages=
Machine translation with large language models: Prompting, few-shot learning, and fine-tuning with QLoRA , author=. Proceedings of the Eighth Conference on Machine Translation , pages=
-
[28]
Proceedings of The Second Arabic Natural Language Processing Conference , pages=
Improving Language Models Trained on Translated Data with Continual Pre-Training and Dictionary Learning Analysis , author=. Proceedings of The Second Arabic Natural Language Processing Conference , pages=
-
[29]
First Conference on Language Modeling , year=
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities , author=. First Conference on Language Modeling , year=
-
[30]
arXiv preprint arXiv:2410.03115 , year=
X-alma: Plug & play modules and adaptive rejection for quality translation at scale , author=. arXiv preprint arXiv:2410.03115 , year=
-
[31]
Information Processing & Management , volume=
Overcoming language barriers via machine translation with sparse Mixture-of-Experts fusion of large language models , author=. Information Processing & Management , volume=. 2025 , publisher=
2025
-
[32]
, author=
LKMT: Linguistics Knowledge-Driven Multi-Task Neural Machine Translation for Urdu and English. , author=. Computers, Materials & Continua , volume=
-
[33]
arXiv e-prints , pages=
Improving llm-based machine translation with systematic self-correction , author=. arXiv e-prints , pages=
-
[34]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Revisiting Catastrophic Forgetting in Large Language Model Tuning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
Overcoming Catastrophic Forgetting During Domain Adaptation of Neural Machine Translation , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[37]
Advances in Neural Information Processing Systems , volume=
On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Handbook of translation studies , volume=
Relay translation , author=. Handbook of translation studies , volume=. 2012 , publisher=
2012
-
[39]
Translating Mircea Eliade's" Ivan" from Romanian to English: A Triangular Approach Using the French Translation , author=
-
[40]
Perspectives , volume=
The use of context in multiword-term translation , author=. Perspectives , volume=. 2023 , publisher=
2023
-
[41]
2015 , publisher=
Contextualizing translation theories: Aspects of Arabic--English interlingual communication , author=. 2015 , publisher=
2015
-
[42]
Translation studies: Perspectives on an emerging discipline , pages=
Translation as interpretation , author=. Translation studies: Perspectives on an emerging discipline , pages=. 2002 , publisher=
2002
-
[43]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[44]
COMET : A Neural Framework for MT Evaluation
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[45]
ArXiv , year=
Qwen2.5 Technical Report , author=. ArXiv , year=
-
[46]
Transactions of the Association for Computational Linguistics , year=
The Flores-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation , author=. Transactions of the Association for Computational Linguistics , year=
-
[47]
arXiv preprint arXiv:2501.17161 , year=
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
-
[48]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[49]
arXiv preprint arXiv:2308.07702 , year=
Better zero-shot reasoning with role-play prompting , author=. arXiv preprint arXiv:2308.07702 , year=
-
[50]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[51]
arXiv preprint arXiv:1903.08542 , year=
Learning gentle object manipulation with curiosity-driven deep reinforcement learning , author=. arXiv preprint arXiv:1903.08542 , year=
Pith/arXiv arXiv 1903
-
[52]
arXiv preprint arXiv:2407.19884 , year=
Preliminary wmt24 ranking of general mt systems and llms , author=. arXiv preprint arXiv:2407.19884 , year=
-
[53]
arXiv preprint arXiv:2502.11544 , year=
Evaluating o1-like llms: Unlocking reasoning for translation through comprehensive analysis , author=. arXiv preprint arXiv:2502.11544 , year=
-
[54]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Understanding and improving the robustness of terminology constraints in neural machine translation , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
arXiv preprint arXiv:2503.03308 , year=
The box is in the pen: Evaluating commonsense reasoning in neural machine translation , author=. arXiv preprint arXiv:2503.03308 , year=
-
[56]
arXiv preprint arXiv:2305.14328 , year=
Benchmarking Machine Translation with Cultural Awareness , author=. arXiv preprint arXiv:2305.14328 , year=
-
[57]
Freitag, Markus and Rei, Ricardo and Mathur, Nitika and Lo, Chi-kiu and Stewart, Craig and Avramidis, Eleftherios and Kocmi, Tom and Foster, George and Lavie, Alon and Martins, Andr \'e F. T. Results of WMT 22 Metrics Shared Task: Stop Using BLEU -- Neural Metrics Are Better and More Robust. Proceedings of the Seventh Conference on Machine Translation (WMT). 2022
2022
-
[58]
Results of WMT 23 Metrics Shared Task: Metrics Might Be Guilty but References Are Not Innocent
Freitag, Markus and Mathur, Nitika and Lo, Chi-kiu and Avramidis, Eleftherios and Rei, Ricardo and Thompson, Brian and Kocmi, Tom and Blain, Frederic and Deutsch, Daniel and Stewart, Craig and Zerva, Chrysoula and Castilho, Sheila and Lavie, Alon and Foster, George. Results of WMT 23 Metrics Shared Task: Metrics Might Be Guilty but References Are Not Inno...
-
[59]
Pitfalls and Outlooks in Using COMET
Zouhar, Vil \'e m and Chen, Pinzhen and Lam, Tsz Kin and Moghe, Nikita and Haddow, Barry. Pitfalls and Outlooks in Using COMET. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.121
-
[60]
2019 , organization=
Findings of the 2019 conference on machine translation (WMT19) , author=. 2019 , organization=
2019
-
[61]
Transactions of the Association for Computational Linguistics , volume=
Experts, errors, and context: A large-scale study of human evaluation for machine translation , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
2021
-
[62]
Findings of EMNLP , year =
ParroT: Translating during Chat using Large Language Models tuned with Human Translation and Feedback , author=. Findings of EMNLP , year =
-
[63]
arXiv preprint arXiv:2207.04672 , year=
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[64]
arXiv preprint arXiv:2405.18348 , year=
Can Automatic Metrics Assess High-Quality Translations? , author=. arXiv preprint arXiv:2405.18348 , year=
-
[65]
arXiv preprint arXiv:2507.08538 , year=
The AI Language Proficiency Monitor--Tracking the Progress of LLMs on Multilingual Benchmarks , author=. arXiv preprint arXiv:2507.08538 , year=
-
[66]
Hashimoto , title =
Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , month =
2023
-
[67]
Advances in Neural Information Processing Systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Proceedings of the 62th Annual Meeting of the Association for Computational Linguistics , year=
PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning , author=. Proceedings of the 62th Annual Meeting of the Association for Computational Linguistics , year=
-
[69]
arXiv preprint arXiv:2402.13524 , year=
OMGEval: An Open Multilingual Generative Evaluation Benchmark for Large Language Models , author=. arXiv preprint arXiv:2402.13524 , year=
-
[70]
2010 , publisher=
Organizational culture and leadership , author=. 2010 , publisher=
2010
-
[71]
1976 , publisher=
Beyond culture , author=. 1976 , publisher=
1976
-
[72]
2001 , publisher=
A taxonomy for learning, teaching, and assessing: A revision of Bloom's taxonomy of educational objectives: complete edition , author=. 2001 , publisher=
2001
-
[73]
2024 , howpublished =
Multilingual Massive Multitask Language Understanding (MMMLU) , author =. 2024 , howpublished =
2024
-
[74]
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Bandarkar, Lucas and Liang, Davis and Muller, Benjamin and Artetxe, Mikel and Shukla, Satya Narayan and Husa, Donald and Goyal, Naman and Krishnan, Abhinandan and Zettlemoyer, Luke and Khabsa, Madian. The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants. Proceedings of the 62nd Annual Meeting of the Association for Com...
-
[75]
1988 , publisher=
A study of dragonology, East and West , author=. 1988 , publisher=
1988
-
[76]
Inquiry-Based Global Learning in the K--12 Social Studies Classroom , pages=
What Is the Difference Between the Chinese Dragon and Its Depiction in the West? , author=. Inquiry-Based Global Learning in the K--12 Social Studies Classroom , pages=. 2020 , publisher=
2020
-
[77]
Cities , volume=
Exploring the rich-club characteristic in internal migration: Evidence from Chinese Chunyun migration , author=. Cities , volume=. 2021 , publisher=
2021
-
[78]
arXiv preprint arXiv:2509.16188 , year=
CultureScope: A Dimensional Lens for Probing Cultural Understanding in LLMs , author=. arXiv preprint arXiv:2509.16188 , year=
-
[79]
The Thirteenth International Conference on Learning Representations , year=
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge , author=. The Thirteenth International Conference on Learning Representations , year=
-
[80]
Advances in Neural Information Processing Systems , volume=
Blend: A benchmark for llms on everyday knowledge in diverse cultures and languages , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.