Distributional Approximate Nearest Neighbour Search for Uncertainty-Aware Retrieval
Pith reviewed 2026-06-28 04:14 UTC · model grok-4.3
The pith
DINOSAUR samples multiple embeddings per item and user to marginalize uncertainty during approximate nearest neighbor search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DINOSAUR constructs an ANN index over S_i sampled embeddings per item and samples the user embedding at serving time; this two-sided stochastic process marginalizes embedding uncertainty, recovers standard point-estimate retrieval when variance vanishes, and expands the latent-space regions from which high-variance items remain retrievable.
What carries the argument
Two-sided stochastic retrieval that indexes multiple sampled embeddings per item and samples the user embedding at query time.
If this is right
- Standard point-estimate retrieval is recovered exactly as embedding uncertainty vanishes.
- Higher embedding variance enlarges the latent-space regions in which uncertain items can be retrieved.
- Coverage of long-tail items increases while offline recall suffers only small losses.
- No modifications to model architecture or existing ANN index infrastructure are required.
Where Pith is reading between the lines
- The same sampling principle could be applied to other sources of uncertainty that arise after training, such as temporal drift in user preferences.
- Production systems using DINOSAUR might surface more serendipitous long-tail items without separate diversity reranking stages.
- Exact retrieval probability for an item could be derived as a function of its embedding variance and the user distribution, yielding testable predictions on synthetic data.
Load-bearing premise
Independently sampling embeddings from per-item and per-user distributions accurately marginalizes over the true posterior uncertainty induced by sparse training data.
What would settle it
An experiment in which sampling from the per-item and per-user distributions produces no coverage gain for long-tail items, or in which point-estimate retrieval is not recovered as variance is driven to zero, would falsify the central claims.
Figures
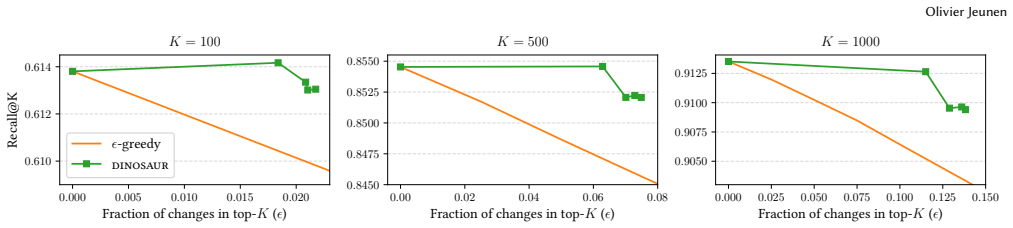
read the original abstract
Approximate Nearest Neighbour search indices form the backbone of real-world recommender systems, enabling real-time candidate retrieval over million-item catalogues. Typically, a single point estimate embedding is learnt for every user and every item. At serving time, the user embedding queries the index for relevant items. Since these representations are learnt from sparse interaction data, they are noisy and might fail to capture all the nuances that contribute to ``relevance'' -- ignoring the fundamental uncertainty that is inherent to them. The result is a retrieval pipeline that is systematically biased toward the small minority of popular head items with well-estimated embeddings, at the expense of the long-tail majority of niche, diverse, and serendipitous content. We propose DINOSAUR (Distributional Approximate Nearest Neighbour Search for Uncertainty-Aware Retrieval): a simple and infrastructure-compatible framework to incorporate embedding uncertainty into candidate generation. Rather than indexing point estimates, DINOSAUR samples $S_i$ embeddings per item and constructs an index on this augmented set. Analogously, at query time, a user embedding is sampled. This two-sided stochastic retrieval process implicitly marginalises over embedding uncertainty, without requiring changes to model architecture or ANN index infrastructure. On the analytical side, we show that DINOSAUR recovers standard point-estimate retrieval as uncertainty vanishes, and we characterise how increased embedding variance expands the regions of latent space in which uncertain items are retrievable. Reproducible empirical observations align with these expectations, showing large coverage gains with small losses in offline recall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DINOSAUR, a framework for uncertainty-aware approximate nearest-neighbour retrieval in recommender systems. Rather than indexing single point-estimate embeddings, it samples multiple embeddings per item to construct an augmented index and samples a user embedding at query time; the resulting two-sided stochastic process is claimed to marginalise embedding uncertainty. Analytically, the manuscript states that DINOSAUR recovers standard point-estimate retrieval as uncertainty vanishes and characterises how increased embedding variance expands the regions of latent space in which uncertain items become retrievable. Empirical results are reported to show large coverage gains accompanied by only small losses in offline recall, all while remaining compatible with existing ANN infrastructure.
Significance. If the recovery and region-expansion results hold under a sampling distribution that correctly represents posterior uncertainty, the approach would provide a practical route to reducing head-item bias in candidate generation without architectural changes to models or indices, potentially improving long-tail coverage and diversity in production retrieval pipelines.
major comments (2)
- [analytical results paragraph] § on analytical results (the paragraph beginning "On the analytical side"): the stated recovery of point-estimate retrieval as variance → 0 and the characterisation of expanded retrievable regions are derived under independent sampling from per-item and per-user distributions; the manuscript does not demonstrate that this sampling marginalises the joint posterior p(embeddings | sparse interactions), which would generally induce correlations between user and item uncertainties.
- [method description and abstract] Method description and abstract: the claim that the procedure "implicitly marginalises over embedding uncertainty" is load-bearing for the bias-correction motivation, yet the paper provides no derivation or approximation argument showing that independent per-item/per-user sampling recovers the relevant marginal under the true posterior induced by shared sparse training data.
minor comments (2)
- [abstract] The abstract uses nested double quotes around "relevance"; standard LaTeX or typographic conventions would improve readability.
- [analytical claims] No equation numbers or explicit statements of the sampling distributions (e.g., the precise form of the per-item variance) are referenced in the provided summary of the analytical claims, making cross-referencing difficult.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the distinction between independent per-item/per-user sampling and marginalization of the joint posterior. We address both major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [analytical results paragraph] § on analytical results (the paragraph beginning "On the analytical side"): the stated recovery of point-estimate retrieval as variance → 0 and the characterisation of expanded retrievable regions are derived under independent sampling from per-item and per-user distributions; the manuscript does not demonstrate that this sampling marginalises the joint posterior p(embeddings | sparse interactions), which would generally induce correlations between user and item uncertainties.
Authors: We agree that the analytical results (recovery at zero variance and expansion of retrievable regions) are formally derived under the modeling assumption of independent sampling. The recovery result continues to hold because each sampled embedding converges in probability to its point estimate as variance vanishes, regardless of correlations. The region-expansion characterisation likewise follows directly from the per-embedding variance under independence. We will revise the relevant paragraph to state the independence assumption explicitly and to note that correlations induced by shared sparse data are not modelled. This is a genuine limitation of the current analysis. revision: yes
-
Referee: [method description and abstract] Method description and abstract: the claim that the procedure "implicitly marginalises over embedding uncertainty" is load-bearing for the bias-correction motivation, yet the paper provides no derivation or approximation argument showing that independent per-item/per-user sampling recovers the relevant marginal under the true posterior induced by shared sparse training data.
Authors: The manuscript presents independent sampling as a practical, infrastructure-compatible heuristic that accounts for embedding uncertainty. We acknowledge that no derivation is given showing that this procedure recovers the exact marginal under the joint posterior p(embeddings | data). We will revise the abstract and method section to replace the phrase "implicitly marginalises" with language that describes the procedure as "approximating marginalization via independent sampling from per-entity uncertainty distributions" and to flag the independence assumption as a modeling choice whose fidelity to the true posterior remains an open question. revision: yes
Circularity Check
No circularity detected; analytical claims are independent derivations
full rationale
The paper derives that DINOSAUR recovers point-estimate retrieval as uncertainty vanishes and that higher variance expands retrievable regions of latent space. These are presented as direct mathematical consequences of the two-sided sampling process rather than reductions to fitted parameters, self-definitions, or self-citation chains. The modeling assumption of independent per-item/per-user sampling is stated explicitly as an approximation and does not create a circular equivalence between inputs and outputs. No load-bearing self-citations, ansatzes, or renamings of known results are evident.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embeddings can be sampled from distributions that represent uncertainty from sparse data
Reference graph
Works this paper leans on
-
[1]
Himan Abdollahpouri. 2019. Popularity Bias in Ranking and Recommendation. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’19). ACM, 529–530. doi:10.1145/3306618.3314309
-
[2]
Nima Asadi and Jimmy Lin. 2013. Effectiveness/efficiency tradeoffs for candi- date generation in multi-stage retrieval architectures. InProceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’13). ACM, 997–1000. doi:10.1145/2484028.2484132
-
[3]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems87 (2020), 101374. doi:10.1016/j.is.2019.02.006
-
[4]
2018.Annoy: Approximate Nearest Neighbors in C++/Python
Erik Bernhardsson. 2018.Annoy: Approximate Nearest Neighbors in C++/Python. https://pypi.org/project/annoy/ Python package version 1.13.0
2018
-
[5]
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. 2015. Weight Uncertainty in Neural Networks. InProceedings of the 32nd International Conference on Machine Learning
2015
-
[6]
Allison J. B. Chaney, Brandon M. Stewart, and Barbara E. Engelhardt. 2018. How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. InProceedings of the 12th ACM Conference on Recommender Systems (RecSys ’18). ACM, 224–232. doi:10.1145/3240323.3240370
-
[7]
Minmin Chen, Yuyan Wang, Can Xu, Ya Le, Mohit Sharma, Lee Richardson, Su-Lin Wu, and Ed Chi. 2021. Values of User Exploration in Recommender Systems. InProceedings of the 15th ACM Conference on Recommender Systems (RecSys ’21). ACM, 85–95. doi:10.1145/3460231.3474236
-
[8]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProc. of the 10th ACM Conference on Recommender Systems (RecSys ’16). ACM, 191–198. doi:10.1145/2959100.2959190
-
[9]
Fernando Diaz, Bhaskar Mitra, Michael D. Ekstrand, Asia J. Biega, and Ben Carterette. 2020. Evaluating Stochastic Rankings with Expected Exposure. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM ’20). ACM, 275–284. doi:10.1145/3340531.3411962
-
[10]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2026. The Faiss Library.IEEE Transactions on Big Data12, 2 (2026), 346–361. doi:10. 1109/TBDATA.2025.3618474
arXiv 2026
-
[11]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. InProc. of The 33rd Inter- national Conference on Machine Learning (Proc. of Machine Learning Research, Vol. 48). PMLR, 1050–1059
2016
-
[12]
Dalin Guo, Sofia Ira Ktena, Pranay Kumar Myana, Ferenc Huszar, Wenzhe Shi, Alykhan Tejani, Michael Kneier, and Sourav Das. 2020. Deep Bayesian Bandits: Exploring in Online Personalized Recommendations. InProceedings of the 14th ACM Conference on Recommender Systems (RecSys ’20). ACM, 456–461. doi:10. 1145/3383313.3412214
arXiv 2020
-
[13]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119). PMLR, 3887–3896
2020
-
[14]
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context.ACM Trans. Interact. Intell. Syst.5, 4, Article 19 (Dec. 2015), 19 pages. doi:10.1145/2827872
-
[15]
Karl Higley, Even Oldridge, Ronay Ak, Sara Rabhi, and Gabriel de Souza Pereira Moreira. 2022. Building and Deploying a Multi-Stage Recommender System with Merlin. InProceedings of the 16th ACM Conference on Recommender Systems (RecSys ’22). ACM, 632–635. doi:10.1145/3523227.3551468
-
[16]
Eyke Hüllermeier and Willem Waegeman. 2021. Aleatoric and epistemic uncer- tainty in machine learning: an introduction to concepts and methods.Machine Learning110, 3 (2021), 457–506
2021
-
[17]
Jadidinejad, Craig Macdonald, and Iadh Ounis
Amir H. Jadidinejad, Craig Macdonald, and Iadh Ounis. 2021. The Simpson’s Paradox in the Offline Evaluation of Recommendation Systems.ACM Trans. Inf. Syst.40, 1, Article 4 (sep 2021), 22 pages. doi:10.1145/3458509
-
[18]
Olivier Jeunen. 2019. Revisiting Offline Evaluation for Implicit-Feedback Recom- mender Systems. InProc. of the 13th ACM Conference on Recommender Systems (RecSys ’19). ACM, 596–600. doi:10.1145/3298689.3347069
-
[19]
Olivier Jeunen and Bart Goethals. 2021. Top-K Contextual Bandits with Equity of Exposure. InProc. of the 15th ACM Conference on Recommender Systems (RecSys ’21). ACM, 310–320. doi:10.1145/3460231.3474248
-
[20]
Olivier Jeunen, Eleanor Hanna, and Schaun Wheeler. 2026. Sustained Impact of Agentic Personalisation: A Longitudinal Case-Study. InProc. of the 34th ACM Conference on User Modeling, Adaptation and Personalization (UMAP ’26). ACM
2026
-
[21]
Olivier Jeunen, David Rohde, and Flavian Vasile. 2019. On the Value of Bandit Feedback for Offline Recommender System Evaluation. InProc. of the ACM RecSys Workshop on Reinforcement Learning and Robust Estimators for Recommendation (REVEAL ’19)
2019
-
[22]
Olivier Jeunen, Hitesh Sagtani, Himanshu Doi, Rasul Karimov, Neeti Pokharna, Danish Kalim, Aleksei Ustimenko, Christopher Green, Rishabh Mehrotra, and Wenzhe Shi. 2024. On Gradient Boosted Decision Trees and Neural Rankers: A Case-Study on Short-Video Recommendations at ShareChat. InProceedings of the 15th Annual Meeting of the Forum for Information Retri...
-
[23]
Olivier Jeunen, Koen Verstrepen, and Bart Goethals. 2018. Fair Offline Evalua- tion Methodologies for Implicit-Feedback Recommender Systems with MNAR Data. InWorkshop on Offline Evaluation for Recommender Systems at RecSys ’18 (REVEAL ’18)
2018
-
[24]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. InInternational Conference on Learning Representations
2014
-
[25]
Deepak Kumar, Tessa Grosz, Navid Rekabsaz, Elisabeth Greif, and Markus Schedl
-
[26]
doi:10.3389/fdata.2023.1245198
Fairness of recommender systems in the recruitment domain: an analysis from technical and legal perspectives.Frontiers in Big DataVolume 6 - 2023 (2023). doi:10.3389/fdata.2023.1245198
-
[27]
Liu, Stephanie Rogers, Raymond Shiau, Dmitry Kislyuk, Kevin C
David C. Liu, Stephanie Rogers, Raymond Shiau, Dmitry Kislyuk, Kevin C. Ma, Zhigang Zhong, Jenny Liu, and Yushi Jing. 2017. Related Pins at Pinterest: The Evolution of a Real-World Recommender System. InProceedings of the 26th International Conference on World Wide Web Companion (WWW ’17 Companion). International World Wide Web Conferences Steering Commit...
arXiv 2017
-
[28]
Yong Liu, Zhiqi Shen, Yinan Zhang, and Lizhen Cui. 2022. Diversity-Promoting Deep Reinforcement Learning for Interactive Recommendation. In5th Interna- tional Conference on Crowd Science and Engineering (ICCSE ’21). ACM, 132–139. doi:10.1145/3503181.3503203
-
[29]
Yuli Liu and Yuan Zhang. 2025. Diversity-Promoting Recommendation With Dual-Objective Optimization and Dual Consideration.IEEE Trans. on Knowl. and Data Eng.37, 5 (May 2025), 2391–2404. doi:10.1109/TKDE.2025.3543285
-
[30]
Malkov and D
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence42, 4 (2020), 824–
2020
-
[31]
doi:10.1109/TPAMI.2018.2889473
-
[32]
Steffen Rendle, Walid Krichene, Li Zhang, and Yehuda Koren. 2022. Revisiting the Performance of iALS on Item Recommendation Benchmarks. InProceedings of the 16th ACM Conference on Recommender Systems (RecSys ’22). ACM, 427–435
2022
-
[33]
Otmane Sakhi, Stephen Bonner, David Rohde, and Flavian Vasile. 2020. BLOB: A Probabilistic Model for Recommendation that Combines Organic and Bandit Signals. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’20). ACM, 783–793. doi:10.1145/ 3394486.3403121
arXiv 2020
-
[34]
Ruslan Salakhutdinov and Andriy Mnih. 2008. Bayesian probabilistic ma- trix factorization using Markov chain Monte Carlo. InProceedings of the 25th International Conference on Machine Learning (ICML ’08). ACM, 880–887. doi:10.1145/1390156.1390267
-
[35]
Chi, Cristos Goodrow, Su-Lin Wu, Lexi Baugher, and Minmin Chen
Yi Su, Xiangyu Wang, Elaine Ya Le, Liang Liu, Yuening Li, Haokai Lu, Benjamin Lipshitz, Sriraj Badam, Lukasz Heldt, Shuchao Bi, Ed H. Chi, Cristos Goodrow, Su-Lin Wu, Lexi Baugher, and Minmin Chen. 2024. Long-Term Value of Ex- ploration: Measurements, Findings and Algorithms. InProceedings of the 17th ACM International Conference on Web Search and Data Mi...
- [36]
-
[37]
Zheqing Zhu and Benjamin Van Roy. 2023. Deep Exploration for Recommenda- tion Systems. InProceedings of the 17th ACM Conference on Recommender Systems (RecSys ’23). ACM, 963–970. doi:10.1145/3604915.3608855
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.