Vision-Default, Prior-Override: Causal Mechanisms of Perception-Knowledge Conflict in Vision-Language Models
Pith reviewed 2026-06-29 03:49 UTC · model grok-4.3
The pith
Vision-language models default to visual evidence but use a small set of late attention heads to override with stored knowledge on conflict.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
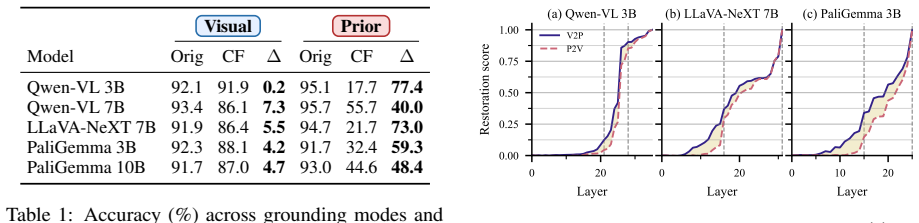
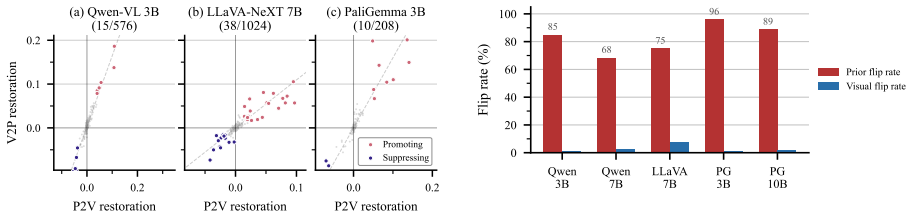
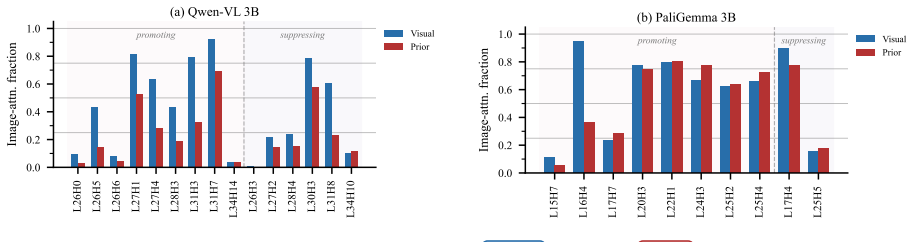
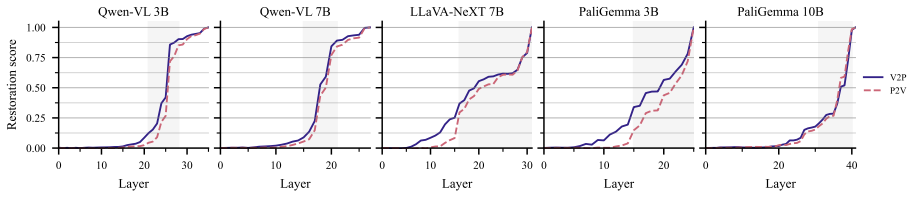
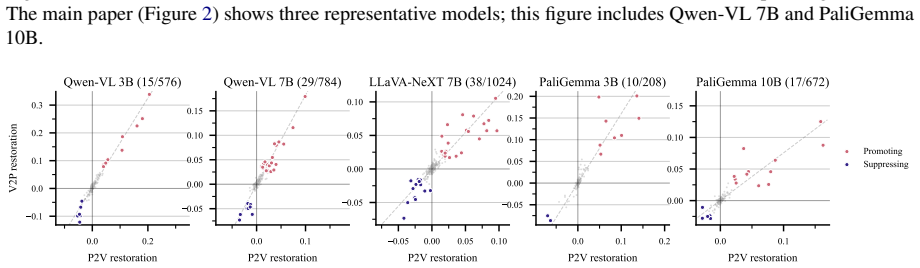
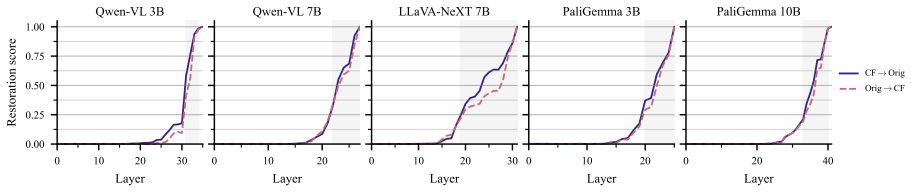
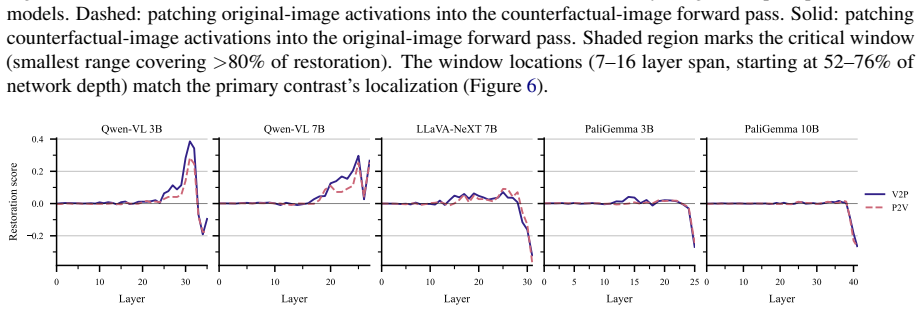
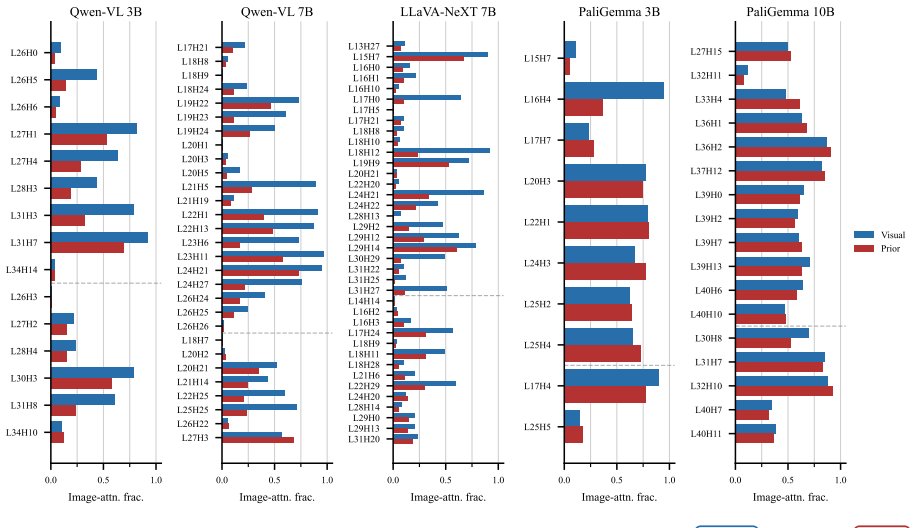
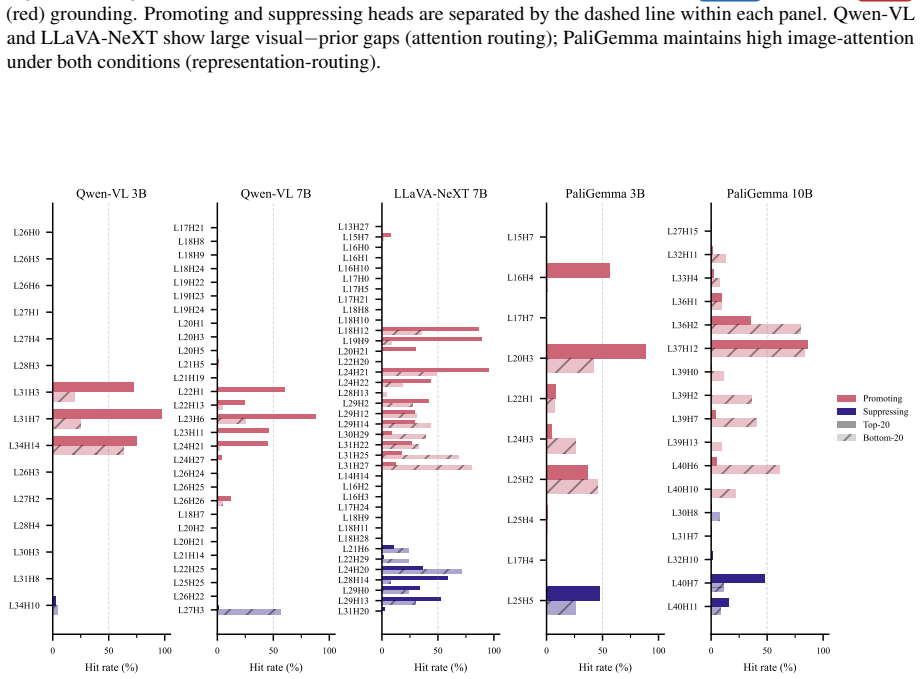
Across three VLM families, visual grounding emerges by default, whereas prior grounding depends on a small set of causally necessary attention heads (2.5-4.8%) concentrated in the second half of the network. These heads enable answers from stored world knowledge despite conflicting visual input. Ablating them flips predictions from knowledge-grounded to visually grounded answers in 68-96% of cases under prior-knowledge prompts, but changes only 0.8-7.5% of visually grounded predictions. The identified heads decompose into routing heads, which modulate information flow, and writing heads, which directly project answer tokens into the residual stream. This structure is consistent across model
What carries the argument
A sparse set of 2.5-4.8% of attention heads in later layers that split into routing heads controlling information flow and writing heads injecting knowledge tokens into the residual stream.
If this is right
- Ablating the heads shifts 68-96% of prior-knowledge answers to visual ones while affecting only 0.8-7.5% of visual answers.
- The same heads and routing-writing decomposition appear in multiple VLM families and scales.
- Prior grounding requires these specific heads; visual grounding does not.
- The circuit explains the mechanism of override rather than distributed processing across the whole model.
Where Pith is reading between the lines
- Targeted interventions on these heads could selectively increase or decrease reliance on world knowledge in deployed VLMs.
- Similar sparse circuits may exist for other evidence conflicts, such as between text sources or between different sensory inputs.
- Training procedures could be designed to strengthen or weaken these heads to improve model reliability under conflicting inputs.
- The asymmetry suggests that default visual behavior might be harder to override without precise circuit-level edits.
Load-bearing premise
The prompts and conflict cases chosen for patching and ablation truly isolate perception-knowledge conflicts without artifacts from prompt design or dataset selection.
What would settle it
A new set of conflict examples in which ablating the reported heads fails to flip the majority of prior-knowledge answers to visual ones would falsify the claim of causal necessity.
Figures

read the original abstract
Vision-language models must reconcile visual evidence with memorized world knowledge when the two conflict. How they resolve this conflict shapes the reliability of multimodal systems, yet prior work characterizes it behaviorally without a component-level causal account. We combine activation patching across three granularities (residual stream, attention heads, and MLP sublayers) with model-component ablation studies and mechanistic analysis. Across three VLM families, we find that visual grounding emerges by default, whereas prior grounding depends on a small set of causally necessary attention heads (2.5-4.8%) concentrated in the second half of the network. These heads enable answers from stored world knowledge (e.g., "red" for a strawberry) despite conflicting visual input. Ablating them flips predictions from knowledge-grounded to visually grounded answers in 68-96% of cases under prior-knowledge prompts, but changes only 0.8-7.5% of visually grounded predictions, establishing an asymmetric causal structure. The identified heads decompose into routing heads, which modulate information flow, and writing heads, which directly project answer tokens into the residual stream. This structure is consistent across model families and scales, revealing a sparse causal circuit underlying perception-knowledge conflict in VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision-language models resolve perception-knowledge conflicts with visual grounding as the default behavior, while prior (knowledge-based) grounding depends on a sparse set of causally necessary attention heads (2.5-4.8% of total heads, concentrated in the second half of the network). These heads are decomposed into routing and writing types. Using activation patching at residual, head, and MLP levels plus ablation studies across three VLM families, ablating the heads flips predictions from knowledge-grounded to visually-grounded answers in 68-96% of cases under prior-knowledge prompts, but only 0.8-7.5% under visual prompts, establishing an asymmetric causal structure.
Significance. If the results hold, the work supplies a component-level mechanistic account of how VLMs handle conflicting visual evidence and memorized knowledge, identifying a consistent sparse causal circuit. The empirical approach via multi-granularity patching and ablation, plus cross-family consistency, is a strength that could guide targeted interventions for more reliable multimodal outputs.
major comments (2)
- [Methods / Experimental Setup (prompt and case selection)] The construction of prior-knowledge prompts and curation of conflict cases (introduced when defining the experimental conditions for patching and ablation) is load-bearing for the central causal claim. The manuscript must demonstrate that these prompts do not systematically increase the salience of knowledge answers or attenuate visual evidence, as any such artifact would make the 68-96% flip rates appear more diagnostic of the identified heads than they are in neutral settings.
- [Results (head identification and ablation)] The identification of the specific 2.5-4.8% attention heads appears post-hoc from the patching results. The paper should specify the exact selection procedure (e.g., threshold, held-out data) and report per-model variance or statistical tests on the flip rates to rule out selection bias inflating the apparent necessity of these heads.
minor comments (2)
- [Abstract] The abstract states ranges (68-96%, 2.5-4.8%) without per-family breakdowns or error bars; adding these would strengthen the quantitative claims.
- [Mechanistic Analysis] The decomposition into 'routing heads' and 'writing heads' is introduced without explicit operational definitions or examples of their distinct effects on the residual stream.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the presentation of our methods and results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods / Experimental Setup (prompt and case selection)] The construction of prior-knowledge prompts and curation of conflict cases (introduced when defining the experimental conditions for patching and ablation) is load-bearing for the central causal claim. The manuscript must demonstrate that these prompts do not systematically increase the salience of knowledge answers or attenuate visual evidence, as any such artifact would make the 68-96% flip rates appear more diagnostic of the identified heads than they are in neutral settings.
Authors: We agree that it is important to rule out potential artifacts in prompt construction. In the revised manuscript, we will include additional validation experiments and analyses demonstrating that our prior-knowledge prompts do not systematically increase the salience of knowledge-based answers relative to neutral settings. This will involve reporting response distributions on matched control prompts. revision: yes
-
Referee: [Results (head identification and ablation)] The identification of the specific 2.5-4.8% attention heads appears post-hoc from the patching results. The paper should specify the exact selection procedure (e.g., threshold, held-out data) and report per-model variance or statistical tests on the flip rates to rule out selection bias inflating the apparent necessity of these heads.
Authors: The head identification procedure is described in the methods, but we acknowledge the need for greater clarity on selection criteria to address concerns about post-hoc selection. We will revise the relevant sections to explicitly detail the selection procedure, including any thresholds or data splits used, and add per-model variance along with appropriate statistical tests for the reported flip rates. revision: yes
Circularity Check
No circularity: empirical interventions are independent of inputs
full rationale
The paper reports results from activation patching, ablation studies, and mechanistic analysis across VLM families. These are direct experimental interventions on model components (residual stream, attention heads, MLPs) whose outcomes (flip rates of 68-96% vs 0.8-7.5%) are measured observations rather than quantities derived from equations or parameters fitted to the same data. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the central claim of an asymmetric causal circuit is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation patching and component ablation can isolate the causal roles of attention heads in resolving perception-knowledge conflicts without confounding effects from the intervention itself.
Reference graph
Works this paper leans on
-
[1]
Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, and Daniela Massiceti
Do VLMs have bad eyes? diag- nosing compositional failures via mechanistic inter- pretability.Preprint, arXiv:2508.16652. Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, and Daniela Massiceti
-
[2]
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei
Understanding information storage and trans- fer in multi-modal large language models.Preprint, arXiv:2406.04236. Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei
-
[3]
NNsight and NDIF: Democratiz- ing access to open-weight foundation model internals. Preprint, arXiv:2407.14561. Mor Geva, Avi Caciularu, Kevin Ro Wang, and Yoav Goldberg
-
[4]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy
Transformer feed-forward layers build predictions by promoting concepts in the vo- cabulary space.Preprint, arXiv:2203.14680. Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy
-
[5]
Transformer feed-forward layers are key-value memories.Preprint, arXiv:2012.14913. Michal Golovanevsky, William Rudman, Michael Lep- ori, Amir Bar, Ritambhara Singh, and Carsten Eick- hoff. 2025a. Pixels versus priors: Controlling knowl- edge priors in vision-language models through visual counterfacts.Preprint, arXiv:2505.17127. Michal Golovanevsky, Will...
Pith/arXiv arXiv 2012
-
[6]
Finding visual task vectors. Preprint, arXiv:2404.05729. Tianze Hua, Tian Yun, and Ellie Pavlick
-
[7]
Nick Jiang, Anish Kachinthaya, Suzie Petryk, and Yossi Gandelsman
How do vision-language models process conflicting informa- tion across modalities?Preprint, arXiv:2507.01790. Nick Jiang, Anish Kachinthaya, Suzie Petryk, and Yossi Gandelsman
-
[8]
Interpreting and editing vision- language representations to mitigate hallucinations. Preprint, arXiv:2410.02762. Zhuoran Jin, Pengfei Cao, Hongbang Yuan, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao
-
[9]
Omri Kaduri, Shai Bagon, and Tali Dekel
Cutting off the head ends the conflict: A mechanism for interpreting and mitigating knowledge conflicts in language models.Preprint, arXiv:2402.18154. Omri Kaduri, Shai Bagon, and Tali Dekel
-
[10]
Benlin Liu, Amita Kamath, Madeleine Grunde- McLaughlin, Winson Han, and Ranjay Krishna
What’s in the image? a deep-dive into the vision of vision language models.Preprint, arXiv:2411.17491. Benlin Liu, Amita Kamath, Madeleine Grunde- McLaughlin, Winson Han, and Ranjay Krishna
-
[11]
Visual representations inside the language model. Preprint, arXiv:2510.04819. Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuan- han Zhang, Sheng Shen, and Yong Jae Lee
-
[12]
Julian Minder, Clément Dumas, Caden Juang, Bilal Chughtai, and Neel Nanda
Locating and editing factual associa- tions in gpt.Preprint, arXiv:2202.05262. Julian Minder, Clément Dumas, Caden Juang, Bilal Chughtai, and Neel Nanda
-
[13]
Overcoming spar- sity artifacts in crosscoders to interpret chat-tuning. Preprint, arXiv:2504.02922. Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez
-
[14]
9 Yaniv Nikankin, Dana Arad, Yossi Gandelsman, and Yonatan Belinkov
Towards interpret- ing visual information processing in vision-language models.Preprint, arXiv:2410.07149. 9 Yaniv Nikankin, Dana Arad, Yossi Gandelsman, and Yonatan Belinkov
-
[15]
Farhad Nooralahzadeh, Omid Rohanian, Yi Zhang, Jonathan Fürst, and Kurt Stockinger
Same task, different cir- cuits: Disentangling modality-specific mechanisms in VLMs.Preprint, arXiv:2506.09047. Farhad Nooralahzadeh, Omid Rohanian, Yi Zhang, Jonathan Fürst, and Kurt Stockinger
-
[16]
Vedant Palit, Rohan Pandey, Aryaman Arora, and Paul Pu Liang
When seeing overrides know- ing: Disentangling knowledge conflicts in vision- language models.Preprint, arXiv:2507.13868. Vedant Palit, Rohan Pandey, Aryaman Arora, and Paul Pu Liang
-
[17]
Mechanisms of prompt-induced hallucination in vision-language models.arXiv preprint arXiv:2601.05201. Andreas Steiner, André Susano Pinto, Michael Tschan- nen, Daniel Keysers, Xiao Wang, Yonatan Bit- ton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, Siyang Qin, Reeve Ingle, Emanuele Bugliarello, Sahar Kazemzadeh, Thomas Mesnard,...
-
[18]
PaliGemma 2: A family of versatile VLMs for transfer.Preprint, arXiv:2412.03555. Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Simas Sakenis, Jason Huang, Yaron Singer, and Stuart Shieber
-
[19]
Causal mediation analysis for interpreting neural nlp: The case of gender bias.Preprint, arXiv:2004.12265. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhi- hao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin
arXiv 2004
-
[20]
Qidong Wang, Junjie Hu, and Ming Jiang
Qwen2-VL: Enhancing vision-language model’s per- ception of the world at any resolution.Preprint, arXiv:2409.12191. Qidong Wang, Junjie Hu, and Ming Jiang
-
[21]
V- seam: Visual semantic editing and attention modu- lating for causal interpretability of vision-language models.Preprint, arXiv:2509.14837. Fred Zhang and Neel Nanda
-
[22]
Towards best prac- tices of activation patching in language models: Met- rics and methods.Preprint, arXiv:2309.16042. Model Total Correct conflict Qwen-VL 3B 467 73 Qwen-VL 7B 467 212 LLaV A-NeXT 7B 467 80 PaliGemma 3B 467 121 PaliGemma 10B 467 177 Table 3: Number of correctly conflicting examples per model, used for all quantitative analyses. Model V2P P...
-
[23]
When modalities conflict: How unimodal reasoning un- certainty governs preference dynamics in MLLMs. Preprint, arXiv:2511.02243. A Dataset and Example Selection The Visual-Counterfact dataset (Golovanevsky et al., 2025a) contains 469 examples of common objects with digitally recolored images. Each ex- ample pairs an object (e.g., banana, elephant) with it...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.