nuReasoning: A Reasoning-Centric Dataset and Benchmark for Long-Tail Autonomous Driving
Pith reviewed 2026-06-28 22:33 UTC · model grok-4.3
The pith
nuReasoning supplies human-verified reasoning annotations across 20,000 driving clips to improve both question answering and planning in long-tail autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
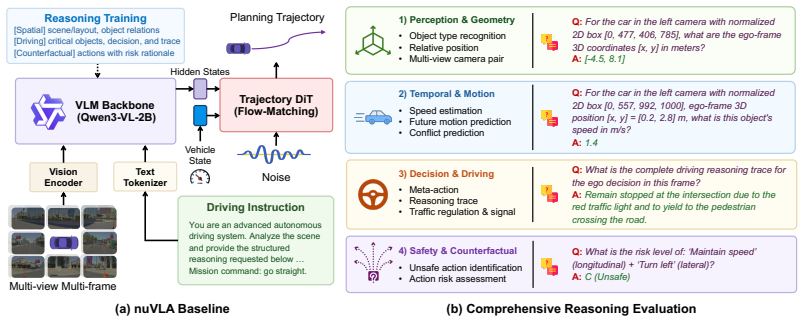
The central claim is that a large-scale real-world dataset with human-verified reasoning annotations for spatial relations, agent interactions, and safe decisions enables both improved reasoning evaluation and improved planning evaluation, with experiments confirming that fine-tuning vision-language models on the data raises driving question-answering accuracy while reasoning supervision during vision-language-action training raises planning performance even when textual reasoning outputs are disabled at inference.
What carries the argument
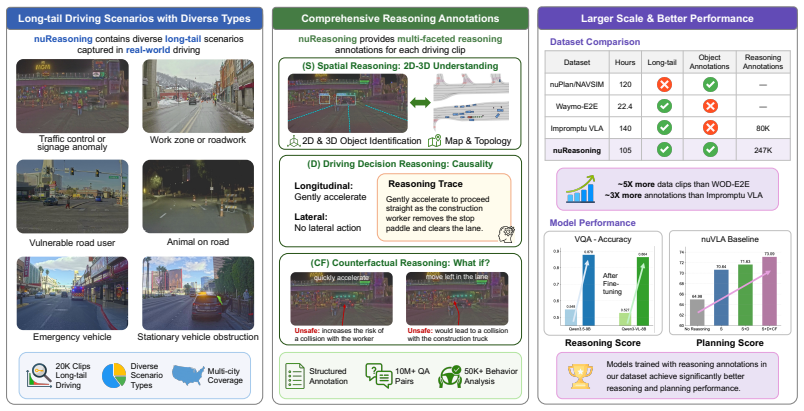
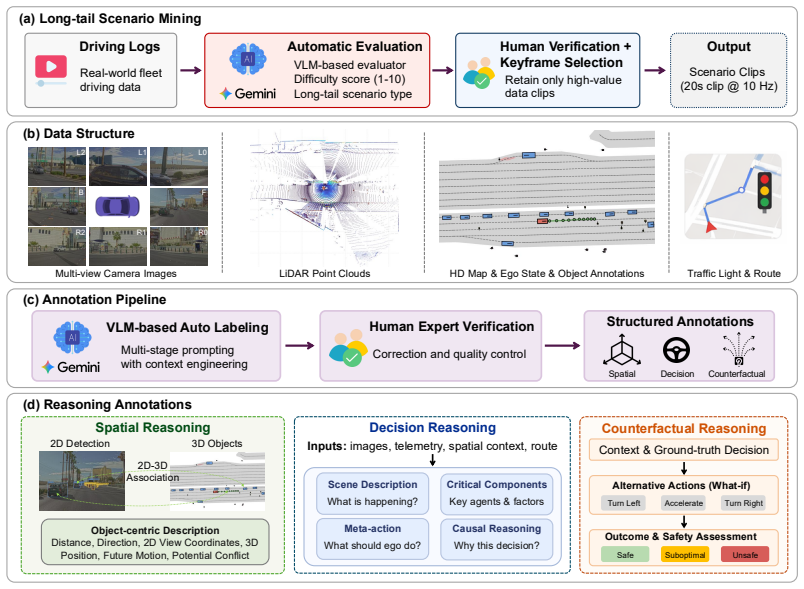
The nuReasoning dataset, which pairs multi-camera images, LiDAR, HD maps, and object annotations with three categories of human-verified reasoning annotations for each of the 20,000 clips.
If this is right
- Fine-tuning vision-language models on nuReasoning substantially improves performance on driving-specific question answering.
- Incorporating reasoning supervision into vision-language-action training improves planning performance.
- Planning performance gains hold even when textual reasoning outputs are disabled at inference time.
- The dataset structure allows a direct study of how reasoning supervision affects driving performance separate from perception or prediction tasks.
Where Pith is reading between the lines
- The separation of reasoning and planning evaluation tracks could be used to measure whether reasoning supervision produces more interpretable intermediate representations inside the model.
- If the annotations prove reliable, the same clip-level reasoning labels could serve as supervision for other sensor modalities or for simulation-to-real transfer.
- Extending the same annotation protocol to additional cities or weather conditions would test whether the observed planning gains generalize beyond the current collection sites.
Load-bearing premise
The human-verified reasoning annotations accurately capture the commonsense knowledge, spatial relations, and inferences required for safe decisions in long-tail driving scenes.
What would settle it
An experiment in which models trained with nuReasoning reasoning supervision show no planning improvement over models trained only on perception data when both are tested on held-out long-tail scenes, or a comparison showing that the annotations diverge from judgments by experienced drivers on key counterfactual inferences.
Figures


read the original abstract
Reasoning is essential for autonomous driving (AD) in long-tail scenarios, where vehicles must apply commonsense knowledge, understand spatial relations, infer agent interactions, and make safe decisions. However, existing AD datasets and benchmarks mainly target perception, prediction, or planning, and provide limited supervision for reasoning over realistic long-tail driving scenes. We introduce nuReasoning, a large-scale real-world dataset and benchmark for reasoning-centric AD. Following the lineage of nuScenes and nuPlan, nuReasoning advances real-world AD datasets and benchmarks toward reasoning in long-tail driving scenarios. The dataset contains 20,000 clips, each 20 seconds long, collected across multiple cities, with synchronized multi-camera images, LiDAR data, HD maps, object annotations, and human-verified reasoning annotations spanning Spatial Reasoning, Decision Reasoning, and Counterfactual Reasoning. Unlike prior datasets that focus primarily on visual question answering, nuReasoning supports both reasoning evaluation and planning evaluation, enabling a direct study of how reasoning supervision affects driving performance. Experiments show that fine-tuning VLMs on nuReasoning substantially improves driving-specific question answering, while incorporating reasoning supervision into VLA training improves planning performance even when textual reasoning outputs are disabled at inference time. These results establish nuReasoning as a foundation for evaluating and improving robust, interpretable, reasoning-driven AD systems in realistic long-tail settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces nuReasoning, a dataset of 20,000 20-second real-world driving clips with synchronized multi-camera, LiDAR, HD maps, and object annotations, augmented by human-verified reasoning labels in three categories (Spatial Reasoning, Decision Reasoning, Counterfactual Reasoning). It supports both VQA-style reasoning evaluation and planning evaluation, with experiments claiming that fine-tuning VLMs on the dataset improves driving-specific question answering and that adding reasoning supervision to VLA training boosts planning metrics even when textual reasoning is disabled at inference.
Significance. If the annotations reliably capture the required commonsense and spatial inferences, nuReasoning would be a useful addition to the nuScenes/nuPlan lineage by enabling controlled study of how explicit reasoning supervision transfers to closed-loop planning. The reported transfer effect (reasoning supervision helping planning without explicit outputs) would be a concrete empirical contribution if robustly demonstrated.
major comments (3)
- [§3.2 and §4.1] §3.2 (Dataset Construction) and §4.1 (Annotation Process): The claim that annotations are 'human-verified' is load-bearing for both the VLM QA and VLA planning results, yet the manuscript provides no inter-annotator agreement statistics, number of reviewers per clip, qualification criteria for annotators, or protocol for resolving disagreements on ambiguous long-tail cases. Without these, it is impossible to assess whether the supervision signal is reliable or whether gains could be explained by scale alone.
- [§5.2 and Table 4] §5.2 (VLA Experiments) and Table 4: The planning improvement from reasoning supervision is presented as evidence that the annotations encode useful inferences, but the section does not report controls that isolate reasoning content from dataset size or from the base VLA architecture; e.g., no ablation comparing reasoning-augmented data against an equal-sized non-reasoning subset. This directly affects attribution of the reported gains.
- [§5.1] §5.1 (VLM Experiments): The driving-specific QA gains are reported without details on the train/test split construction, whether test scenes overlap with training cities, or statistical significance testing across multiple seeds. These omissions make it difficult to judge whether the improvements generalize beyond the particular data partition used.
minor comments (2)
- [Abstract and §1] The abstract and §1 use 'long-tail' without a precise operational definition or quantitative characterization of how the 20k clips were selected to emphasize tail events.
- [Figure 3] Figure 3 (example annotations) would benefit from clearer indication of which reasoning category each highlighted sentence belongs to.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on annotation reliability and experimental controls. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3.2 and §4.1] §3.2 (Dataset Construction) and §4.1 (Annotation Process): The claim that annotations are 'human-verified' is load-bearing for both the VLM QA and VLA planning results, yet the manuscript provides no inter-annotator agreement statistics, number of reviewers per clip, qualification criteria for annotators, or protocol for resolving disagreements on ambiguous long-tail cases. Without these, it is impossible to assess whether the supervision signal is reliable or whether gains could be explained by scale alone.
Authors: We agree that these details are essential for assessing annotation quality. The annotations were produced by qualified annotators with driving domain expertise, with multiple reviewers per clip and a structured disagreement resolution process. In the revised manuscript we will report inter-annotator agreement (Cohen’s kappa), the exact number of reviewers per clip, annotator qualification criteria, and the disagreement protocol. revision: yes
-
Referee: [§5.2 and Table 4] §5.2 (VLA Experiments) and Table 4: The planning improvement from reasoning supervision is presented as evidence that the annotations encode useful inferences, but the section does not report controls that isolate reasoning content from dataset size or from the base VLA architecture; e.g., no ablation comparing reasoning-augmented data against an equal-sized non-reasoning subset. This directly affects attribution of the reported gains.
Authors: We acknowledge the value of an explicit size-matched ablation. The current experiments compare reasoning-augmented training against the base VLA trained on the identical data volume without reasoning labels; however, we will add a new ablation that trains on an equal-sized non-reasoning subset drawn from the same distribution and report the results in the revised §5.2 and Table 4. revision: yes
-
Referee: [§5.1] §5.1 (VLM Experiments): The driving-specific QA gains are reported without details on the train/test split construction, whether test scenes overlap with training cities, or statistical significance testing across multiple seeds. These omissions make it difficult to judge whether the improvements generalize beyond the particular data partition used.
Authors: We will expand §5.1 to describe the train/test split construction (including city-level separation to avoid scene overlap), confirm that test scenes are drawn from held-out cities, and report mean and standard deviation across three random seeds with statistical significance tests. revision: yes
Circularity Check
No circularity; dataset introduction and empirical results contain no derivations or self-referential reductions
full rationale
The paper presents a new dataset (nuReasoning) with human-verified annotations across Spatial/Decision/Counterfactual reasoning and reports empirical results on VLM fine-tuning and VLA planning improvements. No equations, mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on dataset construction and external experimental evaluation rather than any chain that reduces outputs to inputs by definition or construction. Annotation verification details are unspecified, but this concerns evidence quality rather than circularity in any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. InEuropean Conference on Computer Vision, pages 533–549. Springer, 2022
2022
-
[2]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020– 2036, 2024
2020
-
[3]
Collaborative semantic occupancy prediction with hybrid feature fusion in connected automated vehicles
Rui Song, Chenwei Liang, Hu Cao, Zhiran Yan, Walter Zimmer, Markus Gross, Andreas Festag, and Alois Knoll. Collaborative semantic occupancy prediction with hybrid feature fusion in connected automated vehicles. In2024 IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, 2024
2024
-
[4]
V2XPnP: Vehicle-to-everything spatio-temporal fusion for multi-agent perception and prediction.Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025
Zewei Zhou, Hao Xiang, Zhaoliang Zheng, Seth Z Zhao, Mingyue Lei, Yun Zhang, Tianhui Cai, Xinyi Liu, Johnson Liu, Maheswari Bajji, et al. V2XPnP: Vehicle-to-everything spatio-temporal fusion for multi-agent perception and prediction.Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[5]
Maptr: Structured modeling and learning for online vectorized hd map construction
Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. Maptr: Structured modeling and learning for online vectorized hd map construction. InThe Eleventh International Conference on Learning Representations
-
[6]
Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving
Zhiyu Huang, Haochen Liu, and Chen Lv. Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3903–3913, 2023
2023
-
[7]
Tianhui Cai, Yun Zhang, Zewei Zhou, Zhiyu Huang, and Jiaqi Ma. Relmap: Enhancing online map construction with class-aware spatial relation and semantic priors.arXiv preprint arXiv:2507.21567, 2025
arXiv 2025
-
[8]
IPFormer: Visual 3d panoptic scene completion with context-adaptive instance proposals
Markus Gross, Aya Fahmy, Danit Niwattananan, Dominik Muhle, Rui Song, Daniel Cremers, and Henri Meeß. IPFormer: Visual 3d panoptic scene completion with context-adaptive instance proposals. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[9]
Parting with mis- conceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with mis- conceptions about learning-based vehicle motion planning. InConference on Robot Learning (CoRL), 2023
2023
-
[10]
Zhiyu Huang, Zewei Zhou, Tianhui Cai, Yun Zhang, and Jiaqi Ma. Mdg: Masked denois- ing generation for multi-agent behavior modeling in traffic environments.arXiv preprint arXiv:2511.17496, 2025
arXiv 2025
-
[11]
Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning
Zhiyu Huang, Xinshuo Weng, Maximilian Igl, Yuxiao Chen, Yulong Cao, Boris Ivanovic, Marco Pavone, and Chen Lv. Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3445–3451. IEEE, 2025. 10
2025
-
[12]
End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
2024
-
[13]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[14]
Genad: Gen- erative end-to-end autonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Gen- erative end-to-end autonomous driving. InEuropean Conference on Computer Vision, pages 87–104. Springer, 2024
2024
-
[15]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline.Advances in Neural Information Processing Systems, 35:6119–6132, 2022
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline.Advances in Neural Information Processing Systems, 35:6119–6132, 2022
2022
-
[16]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[17]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[18]
Drivetransformer: Unified trans- former for scalable end-to-end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified trans- former for scalable end-to-end autonomous driving. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[19]
Bozhou Zhang, Nan Song, Jingyu Li, Xiatian Zhu, Jiankang Deng, and Li Zhang. Future-aware end-to-end driving: Bidirectional modeling of trajectory planning and scene evolution.arXiv preprint arXiv:2510.11092, 2025
arXiv 2025
-
[20]
Perception in plan: Coupled perception and planning for end-to-end autonomous driving
Bozhou Zhang, Jingyu Li, Nan Song, and Li Zhang. Perception in plan: Coupled perception and planning for end-to-end autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12376–12384, 2026
2026
-
[21]
Simscale: Learning to drive via real-world simulation at scale.arXiv preprint arXiv:2511.23369, 2025
Haochen Tian, Tianyu Li, Haochen Liu, Jiazhi Yang, Yihang Qiu, Guang Li, Junli Wang, Yinfeng Gao, Zhang Zhang, Liang Wang, et al. Simscale: Learning to drive via real-world simulation at scale.arXiv preprint arXiv:2511.23369, 2025
Pith/arXiv arXiv 2025
-
[22]
Yuping Wang, Shuo Xing, Cui Can, Renjie Li, Hongyuan Hua, Kexin Tian, Zhaobin Mo, Xiangbo Gao, Keshu Wu, Sulong Zhou, et al. Generative ai for autonomous driving: Frontiers and opportunities.arXiv preprint arXiv:2505.08854, 2025
arXiv 2025
-
[23]
Driving with regulation: Trustworthy and interpretable decision-making for autonomous driving with retrieval-augmented reasoning
Tianhui Cai, Yifan Liu, Zewei Zhou, Haoxuan Ma, Seth Z Zhao, Zhiwen Wu, Xu Han, Zhiyu Huang, and Jiaqi Ma. Driving with regulation: Trustworthy and interpretable decision-making for autonomous driving with retrieval-augmented reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 38287–38295, 2026
2026
-
[24]
Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6585–6597, 2025
2025
-
[25]
Emma: End-to-end multimodal model for autonomous driving.Transactions on Machine Learning Research, 2025
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.Transactions on Machine Learning Research, 2025
2025
-
[26]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024. 11
2024
-
[27]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the computer vision and pattern recognition conference, pages 22442–22452, 2025
2025
-
[28]
Driving everywhere with large language model policy adaptation
Boyi Li, Yue Wang, Jiageng Mao, Boris Ivanovic, Sushant Veer, Karen Leung, and Marco Pavone. Driving everywhere with large language model policy adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14948–14957, 2024
2024
-
[29]
S4-driver: Scalable self-supervised driving multimodal large language model with spatio-temporal visual representation
Yichen Xie, Runsheng Xu, Tong He, Jyh-Jing Hwang, Katie Luo, Jingwei Ji, Hubert Lin, Letian Chen, Yiren Lu, Zhaoqi Leng, et al. S4-driver: Scalable self-supervised driving multimodal large language model with spatio-temporal visual representation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1622–1632, 2025
2025
-
[30]
Latent chain-of-thought world modeling for end-to-end driving.arXiv preprint arXiv:2512.10226, 2025
Shuhan Tan, Kashyap Chitta, Yuxiao Chen, Ran Tian, Yurong You, Yan Wang, Wenjie Luo, Yulong Cao, Philipp Krahenbuhl, Marco Pavone, et al. Latent chain-of-thought world modeling for end-to-end driving.arXiv preprint arXiv:2512.10226, 2025
Pith/arXiv arXiv 2025
-
[31]
Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jianhua Han, Hang Xu, and Li Zhang. Reason2drive: Towards interpretable and chain-based reasoning for autonomous driving. In European Conference on Computer Vision, pages 292–308. Springer, 2024
2024
-
[32]
Tianshuai Hu, Xiaolu Liu, Song Wang, Yiyao Zhu, Ao Liang, Lingdong Kong, Guoyang Zhao, Zeying Gong, Jun Cen, Zhiyu Huang, et al. Vision-language-action models for autonomous driving: Past, present, and future.arXiv preprint arXiv:2512.16760, 2025
arXiv 2025
-
[33]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025
Pith/arXiv arXiv 2025
-
[34]
Open- drivevla: Towards end-to-end autonomous driving with large vision language action model
Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, V olker Tresp, and Alois Knoll. Open- drivevla: Towards end-to-end autonomous driving with large vision language action model. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 13782–13790, 2026
2026
-
[35]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
Pith/arXiv arXiv 2025
-
[36]
Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[37]
Qihang Peng, Xuesong Chen, Chenye Yang, Shaoshuai Shi, and Hongsheng Li. Colavla: Leveraging cognitive latent reasoning for hierarchical parallel trajectory planning in autonomous driving.arXiv preprint arXiv:2512.22939, 2025
arXiv 2025
-
[38]
Qiqi Liu, Huan Xu, Jingyu Li, Bin Sun, Zhihui Hao, Dangen She, Xiatian Zhu, and Li Zhang. Uni-world vla: Interleaved world modeling and planning for autonomous driving.arXiv preprint arXiv:2603.27287, 2026
arXiv 2026
-
[39]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Hongwei Xie, Bing Wang, Guang Chen, Dingkang Liang, and Xiang Bai. Minddrive: A vision-language-action model for autonomous driving via online reinforcement learning.arXiv preprint arXiv:2512.13636, 2025
arXiv 2025
-
[40]
Real-ad: Towards human-like reasoning in end-to-end autonomous driving
Yuhang Lu, Jiadong Tu, Yuexin Ma, and Xinge Zhu. Real-ad: Towards human-like reasoning in end-to-end autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27783–27793, 2025
2025
-
[41]
Lmdrive: Closed-loop end-to-end driving with large language models
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Yu Liu, and Hong- sheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15120–15130, 2024. 12
2024
-
[42]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[43]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[44]
Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R Qi, Yin Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. InProceedings of the IEEE/CVF international conference on computer vision, pages 9710–9719, 2021
2021
-
[45]
Argoverse: 3d tracking and forecasting with rich maps
Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, and James Hays. Argoverse: 3d tracking and forecasting with rich maps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[46]
Trends in motion predic- tion toward deployable and generalizable autonomy: A revisit and perspectives.Foundations and Trends® in Robotics, 13(1-2):1–269, 2026
Letian Wang, Marc-Antoine Lavoie, Sandro Papais, Barza Nisar, Yuxiao Chen, Wenhao Ding, Boris Ivanovic, Hao Shao, Abulikemu Abuduweili, Evan Cook, et al. Trends in motion predic- tion toward deployable and generalizable autonomy: A revisit and perspectives.Foundations and Trends® in Robotics, 13(1-2):1–269, 2026
2026
-
[47]
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021
Pith/arXiv arXiv 2021
-
[48]
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Ekaterina Tolstaya, Sarah Tang, Brandyn White, et al. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios.arXiv preprint arXiv:2510.26125, 2025
arXiv 2025
-
[49]
Seth Z Zhao, Luobin Wang, Hongwei Ruan, Yuxin Bao, Yilan Chen, Ziyang Leng, Abhijit Ravichandran, Honglin He, Zewei Zhou, Xu Han, et al. Bridgesim: Unveiling the ol-cl gap in end-to-end autonomous driving.arXiv preprint arXiv:2604.10856, 2026
Pith/arXiv arXiv 2026
-
[50]
Haibao Yu, Wenxian Yang, Ruiyang Hao, Chuanye Wang, Jiaru Zhong, Ping Luo, and Zaiqing Nie. Drivee2e: Closed-loop benchmark for end-to-end autonomous driving through real-to- simulation.arXiv preprint arXiv:2509.23922, 2025
arXiv 2025
-
[51]
Nuplanqa: A large-scale dataset and benchmark for multi-view driving scene understanding in multi-modal large language models
Sung-Yeon Park, Can Cui, Yunsheng Ma, Ahmadreza Moradipari, Rohit Gupta, Kyungtae Han, and Ziran Wang. Nuplanqa: A large-scale dataset and benchmark for multi-view driving scene understanding in multi-modal large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8066–8076, 2025
2025
-
[52]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4542–4550, 2024
2024
-
[53]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024
2024
-
[54]
Yi Gu, Yan Wang, Yuxiao Chen, Yurong You, Wenjie Luo, Yue Wang, Wenhao Ding, Boyi Li, Heng Yang, Boris Ivanovic, et al. Accelerating structured chain-of-thought in autonomous vehicles.arXiv preprint arXiv:2602.02864, 2026
arXiv 2026
-
[55]
Seungjun Yu, Seonho Lee, Namho Kim, Jaeyo Shin, Junsung Park, Wonjeong Ryu, Raehyuk Jung, and Hyunjung Shim. Waymoqa: A multi-view visual question answering dataset for safety-critical reasoning in autonomous driving.arXiv preprint arXiv:2511.20022, 2025. 13
arXiv 2025
-
[56]
Covla: Comprehensive vision-language-action dataset for autonomous driving
Hidehisa Arai, Keita Miwa, Kento Sasaki, Kohei Watanabe, Yu Yamaguchi, Shunsuke Aoki, and Issei Yamamoto. Covla: Comprehensive vision-language-action dataset for autonomous driving. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1933–1943. IEEE, 2025
1933
-
[57]
Haohan Chi, Huan-ang Gao, Ziming Liu, Jianing Liu, Chenyu Liu, Jinwei Li, Kaisen Yang, Yangcheng Yu, Zeda Wang, Wenyi Li, et al. Impromptu vla: Open weights and open data for driving vision-language-action models.arXiv preprint arXiv:2505.23757, 2025
arXiv 2025
-
[58]
Spatial-aware vision language model for autonomous driving.arXiv preprint arXiv:2512.24331, 2025
Weijie Wei, Zhipeng Luo, Ling Feng, and Venice Erin Liong. Spatial-aware vision language model for autonomous driving.arXiv preprint arXiv:2512.24331, 2025
Pith/arXiv arXiv 2025
-
[59]
Peizheng Li, Zhenghao Zhang, David Holtz, Hang Yu, Yutong Yang, Yuzhi Lai, Rui Song, Andreas Geiger, and Andreas Zell. Spacedrive: Infusing spatial awareness into vlm-based autonomous driving.arXiv preprint arXiv:2512.10719, 2, 2025
Pith/arXiv arXiv 2025
-
[60]
Reasonplan: Unified scene prediction and decision reasoning for closed-loop autonomous driving
Xueyi Liu, Zuodong Zhong, Qichao Zhang, Yuxin Guo, Yupeng Zheng, Junli Wang, Dongbin Zhao, Yun-Fu Liu, Zhiguo Su, Yinfeng Gao, et al. Reasonplan: Unified scene prediction and decision reasoning for closed-loop autonomous driving. InConference on Robot Learning, pages 3051–3068. PMLR, 2025
2025
-
[61]
Zhenghao Peng, Wenhao Ding, Yurong You, Yuxiao Chen, Wenjie Luo, Thomas Tian, Yulong Cao, Apoorva Sharma, Danfei Xu, Boris Ivanovic, et al. Counterfactual vla: Self-reflective vision-language-action model with adaptive reasoning.arXiv preprint arXiv:2512.24426, 2025
arXiv 2025
-
[62]
Towards learning-based planning: The nuplan benchmark for real-world autonomous driving
Napat Karnchanachari, Dimitris Geromichalos, Kok Seang Tan, Nanxiang Li, Christopher Eriksen, Shakiba Yaghoubi, Noushin Mehdipour, Gianmarco Bernasconi, Whye Kit Fong, Yiluan Guo, et al. Towards learning-based planning: The nuplan benchmark for real-world autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 629...
2024
-
[63]
Para-drive: Par- allelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Par- allelized architecture for real-time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024
2024
-
[64]
Sparsedrive: End-to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End-to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025
2025
-
[65]
David Holtz, Niklas Hanselmann, Simon Doll, Marius Cordts, and Bernt Schiele. What matters for scalable and robust learning in end-to-end driving planners?arXiv preprint arXiv:2603.15185, 2026
arXiv 2026
-
[66]
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
Pith/arXiv arXiv 2024
-
[67]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11993–12003, 2025
2025
-
[68]
Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24823–24834, 2025
2025
-
[69]
Dapeng Zhang, Zhenlong Yuan, Zhangquan Chen, Chih-Ting Liao, Yinda Chen, Fei Shen, Qingguo Zhou, and Tat-Seng Chua. Reasoning-vla: A fast and general vision-language-action reasoning model for autonomous driving.arXiv preprint arXiv:2511.19912, 2025
arXiv 2025
-
[70]
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting.arXiv preprint arXiv:2301.00493, 2023. 14
Pith/arXiv arXiv 2023
-
[71]
Navsim: Data-driven non- reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non- reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024
2024
-
[72]
Pseudo-simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo-simulation for autonomous driving. InConference on Robot Learning (CoRL), 2025
2025
-
[73]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017
2017
-
[74]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
2024
-
[75]
Fail2drive: Benchmarking closed-loop driving generalization.arXiv preprint arXiv:2604.08535, 2026
Simon Gerstenecker, Andreas Geiger, and Katrin Renz. Fail2drive: Benchmarking closed-loop driving generalization.arXiv preprint arXiv:2604.08535, 2026
Pith/arXiv arXiv 2026
-
[76]
Embodied scene understanding for vision language models via metavqa
Weizhen Wang, Chenda Duan, Zhenghao Peng, Yuxin Liu, and Bolei Zhou. Embodied scene understanding for vision language models via metavqa. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22453–22464, 2025
2025
-
[77]
Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models
Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, Wei Zhang, and Xiaomeng Li. Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13668–13677, 2024
2024
-
[78]
Are vision llms road-ready? a comprehensive benchmark for safety-critical driving video understanding
Tong Zeng, Longfeng Wu, Liang Shi, Dawei Zhou, and Feng Guo. Are vision llms road-ready? a comprehensive benchmark for safety-critical driving video understanding. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5972–5983, 2025
2025
-
[79]
Bench2drive-vl: Benchmarks for closed-loop autonomous driving with vision-language models
Xiaosong Jia, Yuqian Shao, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive-vl: Benchmarks for closed-loop autonomous driving with vision-language models. arXiv preprint arXiv:2604.01259, 2026
arXiv 2026
-
[80]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, 2026. Accessed: 2026-05-01
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.