TacVerse: A Multi-Sensor Dataset and Benchmark for Cross-Sensor Vision-Based Tactile Perception
Pith reviewed 2026-06-25 20:41 UTC · model grok-4.3
The pith
Vision-based tactile sensors exhibit substantial performance degradation in cross-sensor transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
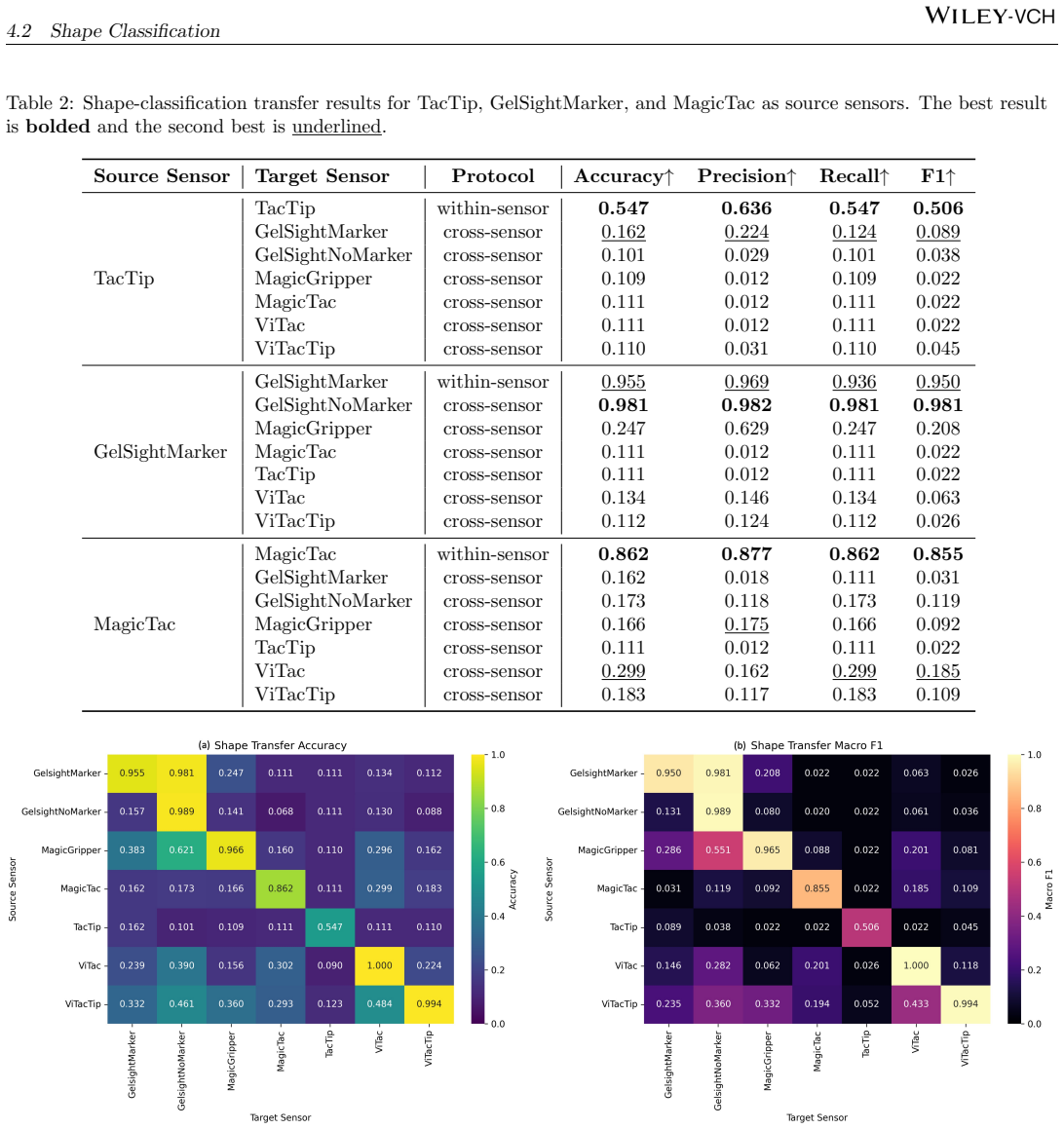
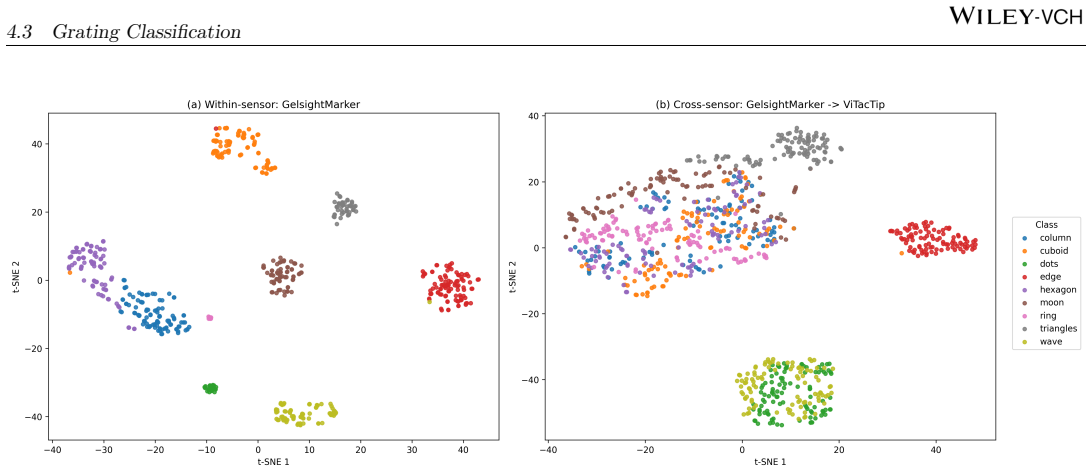
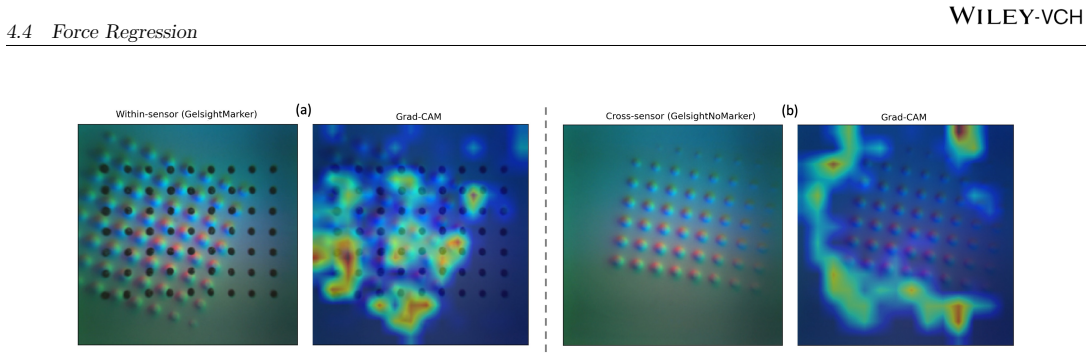
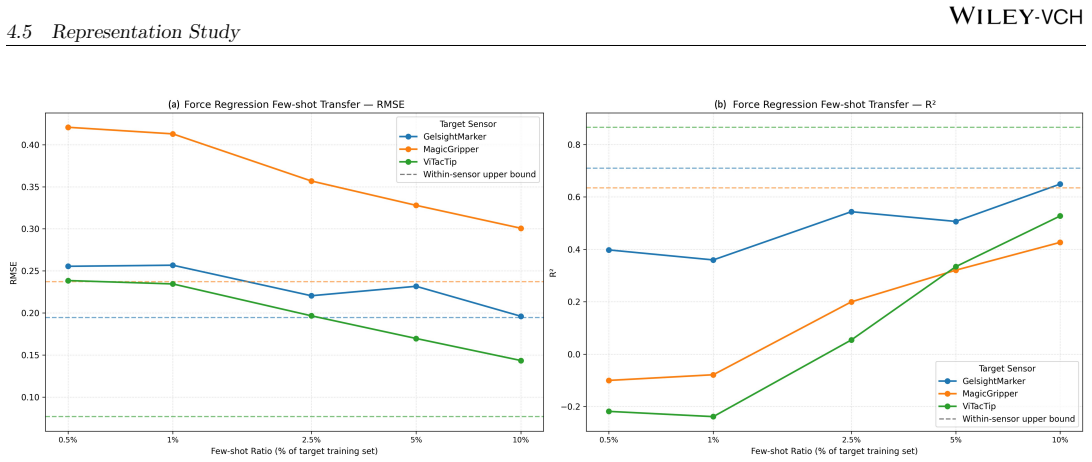
The paper establishes that tactile observations from various VBTS designs are informative within each sensor but suffer from domain shift that degrades direct cross-sensor performance, especially in grating classification and force regression, while shape classification is more robust. Few-shot adaptation narrows but does not eliminate the gap to within-sensor performance, and MAE pretraining yields consistent improvements.
What carries the argument
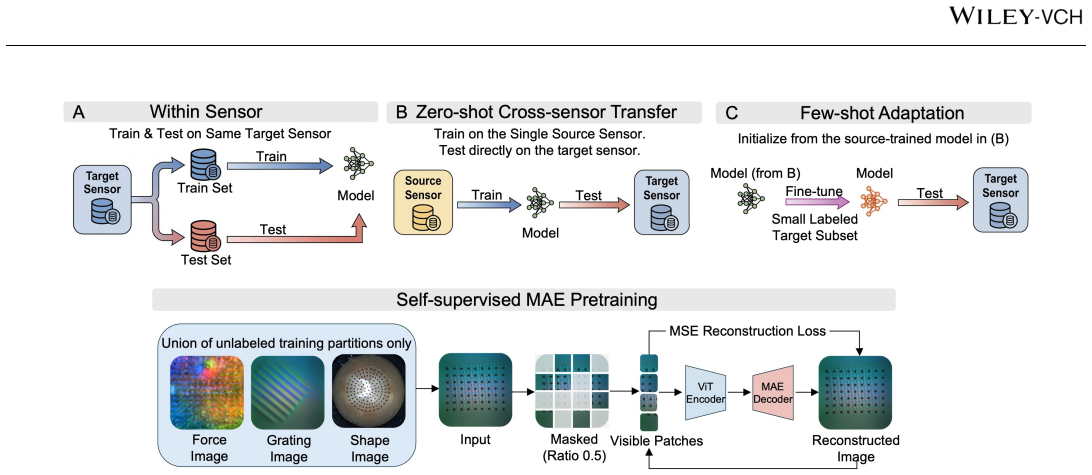
The TacVerse multi-sensor dataset together with its three experimental settings (within-sensor, zero-shot transfer, few-shot adaptation) for evaluating perception across seven VBTS designs.
If this is right
- Direct cross-sensor transfer leads to substantial degradation in model performance.
- Shape classification is more robust to sensor shift than grating classification or force regression.
- Few-shot adaptation improves results on target sensors but does not reach within-sensor performance.
- MAE pretraining provides consistent gains across tasks and sensors.
Where Pith is reading between the lines
- Developers of tactile systems may need to account for sensor-specific variations when deploying models in real-world settings with mixed hardware.
- The results highlight the potential value of self-supervised pretraining for creating representations that are less sensitive to sensor differences.
- The benchmark could support tests of whether standardizing particular hardware elements, such as gel properties or camera placement, would shrink the observed gaps.
Load-bearing premise
That the seven chosen sensor designs and three tasks capture the main sources of variation, so that measured performance gaps arise primarily from sensor differences rather than from inconsistencies in data collection or labeling.
What would settle it
If cross-sensor models matched within-sensor accuracy when data collection procedures and labeling rules were held exactly constant across all seven sensors, the claim of substantial sensor-induced degradation would be falsified.
Figures

read the original abstract
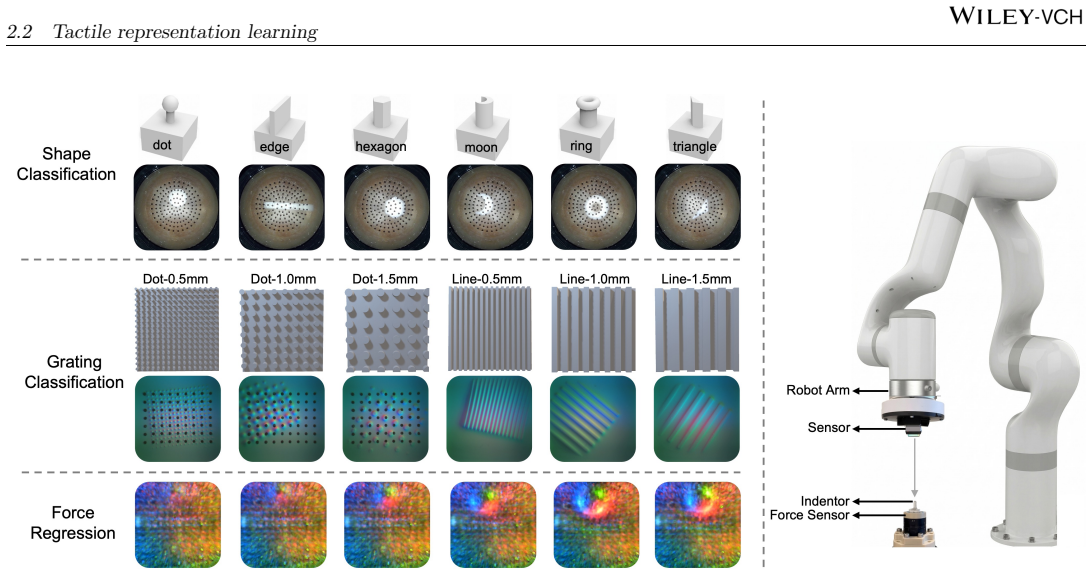
Vision-based tactile sensors (VBTSs) enable robots to infer contact geometry and force-related cues by imaging deformation through an internal camera, yet generalisation across sensor designs remains poorly understood. We present TacVerse, a multi-sensor dataset and benchmark for cross-sensor vision-based tactile perception. The dataset contains 106,800 tactile images from seven VBTSs and supports three downstream tasks: shape classification, grating classification, and force regression. Experiments are conducted under three settings: within-sensor training, zero-shot cross-sensor transfer, and few-shot adaptation. Strong within-sensor performance across all tasks indicates that the collected tactile observations are informative for the target objectives. Direct cross-sensor transfer, however, leads to substantial degradation. Shape classification is comparatively robust, whereas grating classification and force regression are more sensitive to sensor shift. Few-shot adaptation for force regression consistently improves performance on unseen target sensors but does not fully close the gap to within-sensor upper bounds. A representation study further shows that MAE (Masked Autoencoder) pretraining provides the most consistent gains across tasks and sensors. TacVerse provides a controlled testbed for studying sensor shift, data-efficient adaptation, and self-supervised learning in tactile perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TacVerse, a multi-sensor dataset with 106,800 tactile images collected from seven vision-based tactile sensors (VBTSs). It supports three tasks—shape classification, grating classification, and force regression—and evaluates performance under within-sensor training, zero-shot cross-sensor transfer, and few-shot adaptation. The central claims are that within-sensor performance is strong (indicating informative observations), direct cross-sensor transfer causes substantial degradation (with shape classification more robust than the other tasks), few-shot adaptation improves results on unseen sensors without fully closing the gap, and MAE pretraining yields consistent gains.
Significance. If the data collection protocols are verifiably standardized across sensors, TacVerse would provide a valuable public benchmark and testbed for studying hardware-induced distribution shift in tactile perception, an underexplored issue that limits practical robotics applications. The dataset scale, multi-task design, and inclusion of self-supervised pretraining experiments constitute a concrete contribution that could accelerate work on data-efficient adaptation methods.
major comments (2)
- [Experimental protocol description (Methods/Experiments section)] Experimental protocol description (Methods/Experiments section): The manuscript provides no sensor specifications, details on matched data collection procedures (contact objects, force application, image acquisition parameters), labeling consistency, or verification that protocols were identical across the seven VBTS designs except for physical differences. This information is required to attribute the reported cross-sensor degradation primarily to sensor shift rather than procedural variations, which is load-bearing for the central claim.
- [Results presentation (Results section)] Results presentation (Results section): Performance trends are stated without error bars, statistical significance tests, or details on the number of runs or variance across trials. This weakens confidence in the magnitude and consistency of the degradation and adaptation effects reported for grating classification and force regression.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the manuscript to provide the requested details on experimental protocols and results reporting.
read point-by-point responses
-
Referee: Experimental protocol description (Methods/Experiments section): The manuscript provides no sensor specifications, details on matched data collection procedures (contact objects, force application, image acquisition parameters), labeling consistency, or verification that protocols were identical across the seven VBTS designs except for physical differences. This information is required to attribute the reported cross-sensor degradation primarily to sensor shift rather than procedural variations, which is load-bearing for the central claim.
Authors: We agree that additional detail on the data collection protocol is necessary to support attribution of performance differences to sensor hardware. In the revised manuscript, we will add a dedicated subsection in Methods that specifies all seven VBTS designs (including camera intrinsics, elastomer thickness and material, and LED configurations), provides a table of matched contact objects and force application parameters (indentation depths, velocities, and dwell times), lists image acquisition settings (resolution, exposure, frame rate), and describes the labeling pipeline with verification steps confirming identical procedures across sensors. revision: yes
-
Referee: Results presentation (Results section): Performance trends are stated without error bars, statistical significance tests, or details on the number of runs or variance across trials. This weakens confidence in the magnitude and consistency of the degradation and adaptation effects reported for grating classification and force regression.
Authors: We acknowledge the value of reporting variability and statistical support. In the revision, we will augment all performance tables and figures with error bars (standard deviation across runs), explicitly state that each experiment was repeated with five random seeds, and add statistical significance tests (paired t-tests with p-values) for the key comparisons involving grating classification and force regression under zero-shot transfer and few-shot adaptation. revision: yes
Circularity Check
No circularity: empirical dataset/benchmark with no derivations or fitted predictions
full rationale
The paper is a data-collection and benchmarking study. It reports collection of 106800 images across seven VBTS designs and evaluates three tasks under within-sensor, zero-shot cross-sensor, and few-shot settings. No equations, parameter fitting, uniqueness theorems, or self-citation chains appear in the provided text. All performance numbers are direct empirical measurements on externally collected data; none reduce by construction to inputs or prior self-citations. The central claims rest on the external validity of the data-collection protocol rather than any internal definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of supervised machine learning on image data (i.i.d. samples within sensor, label consistency) apply to the collected tactile images.
Reference graph
Works this paper leans on
-
[1]
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y. Sun, B. Fang, D. Hu,arXiv preprint arXiv:2502.12191 2025
arXiv 2025
-
[2]
C. Higuera, A. Sharma, C. K. Bodduluri, T. Fan, P. Lancaster, M. Kalakrishnan, M. Kaess, B. Boots, M. Lambeta, T. Wu, et al.,arXiv preprint arXiv:2410.240902024
- [3]
-
[4]
W. Yuan, S. Dong, E. H. Adelson,Sensors2017,17, 12 2762
-
[5]
W. Fan, H. Li, Q. Cong, D. Zhang,IEEE Transactions on Automation Science and Engineering 2025,2224311
2025
-
[6]
W. Fan, H. Li, D. Zhang, In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE,2024388–394
-
[7]
N. F. Lepora,IEEE Sensors Journal2021,21, 19 21131
-
[8]
S. Luo, N. F. Lepora, U. Martinez-Hernandez, J. Bimbo, H. Liu, Vitac: Integrating vision and touch for multimodal and cross-modal perception,2021
2021
-
[9]
W. Fan, H. Li, W. Si, S. Luo, N. Lepora, D. Zhang, In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE,20241056–1062
-
[10]
Q. Cong, S. Oh, W. Fan, S. Luo, K. Althoefer, D. Zhang,Advanced Intelligent Systems2026, e202501179
-
[11]
T. Schneider, G. Duret, C. de Farias, R. Calandra, L. Chen, J. Peters,arXiv preprint arXiv:2506.063612025
-
[12]
Q. K. Luu, P. Zhou, Z. Xu, Z. Zhang, Q. Qiu, Y. She,arXiv preprint arXiv:2505.184722025
-
[13]
F. Yang, C. Feng, Z. Chen, H. Park, D. Wang, Y. Dou, Z. Zeng, X. Chen, R. Gangopadhyay, A. Owens, et al., InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.202426340–26353
-
[14]
V. Dave, F. Lygerakis, E. Rueckert, In2024 IEEE International Conference on Robotics and Au- tomation (ICRA). IEEE,20248013–8020
-
[15]
Rodriguez, Y
S. Rodriguez, Y. Dou, W. van den Bogert, M. Oller, K. So, A. Owens, N. Fazeli, In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA). IEEE,20255857–5863
-
[16]
Z. Xu, R. Uppuluri, X. Zhang, C. Fitch, P. G. Crandall, W. Shou, D. Wang, Y. She,IEEE Robotics and Automation Letters2025
-
[17]
Grella, A
F. Grella, A. Albini, G. Cannata, P. Maiolino, In2025 IEEE 21st International Conference on Au- tomation Science and Engineering (CASE). IEEE,20251998–2004
2004
-
[18]
Z. Chen, N. Ou, X. Zhang, Z. Wu, Y. Zhao, Y. Wang, E. S. Papastavridis, N. Lepora, L. Jamone, J. Deng, et al.,Nature Communications2026,17, 1 2101
-
[19]
Jianu, D
T. Jianu, D. F. Gomes, S. Luo, In2022 International Conference on Robotics and Automation (ICRA). IEEE,20228305–8311
-
[20]
K. He, X. Zhang, S. Ren, J. Sun, InProceedings of the IEEE conference on computer vision and pattern recognition.2016770–778
-
[21]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al.,arXiv preprint arXiv:2010.119292020
Pith/arXiv arXiv 2010
-
[22]
K. He, X. Chen, S. Xie, Y. Li, P. Doll´ ar, R. Girshick, InProceedings of the IEEE/CVF conference on computer vision and pattern recognition.202216000–16009. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.