Frozen Foundation-Model Embeddings Discard Small-Lesion Signal in Chest Radiography: Implications for Pre-Deployment Evaluation
Pith reviewed 2026-06-27 10:34 UTC · model grok-4.3
The pith
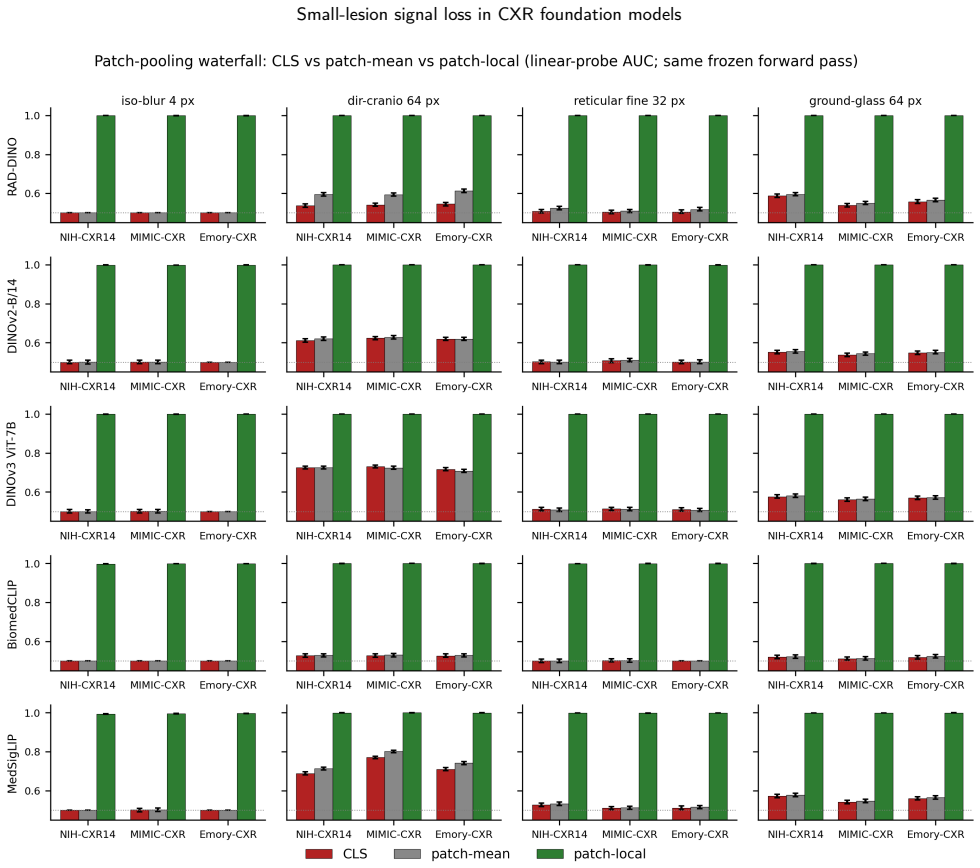
Frozen ViT embeddings for chest X-rays suppress small-lesion signal during global pooling but recover it from patch tokens given a region of interest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frozen ViT embeddings silently suppress small-scale signal at the global-aggregation step; the signal is recoverable from patch tokens conditional on a region of interest.
What carries the argument
Comparison of three pooling modes (CLS token, patch-mean, bounding-box-restricted patch-local) extracted from the identical frozen forward pass on real and perturbed CXR images.
If this is right
- Any downstream CXR classifier that ingests only CLS or global-mean embeddings will under-detect small lesions.
- Patch-local extraction from the same frozen ViT can be inserted into existing pipelines without retraining the backbone.
- Architectural controls such as ResNet-50 exhibit the same global-pooling loss, indicating the effect is not ViT-specific.
- Model selection for pre-deployment CXR screening must include small-lesion stratified evaluation rather than image-level AUC alone.
Where Pith is reading between the lines
- Deployment pipelines could add an ROI-guided patch readout stage without changing the frozen encoder.
- The same global-pooling loss may appear in other small-object medical imaging tasks that rely on frozen ViT backbones.
- Future foundation-model training objectives could add explicit small-scale contrast preservation losses.
Load-bearing premise
The small-scale perturbation panel and bounding-box-stratified probe isolate embedding-level signal retention without being confounded by dataset labeling noise or pretraining objectives.
What would settle it
Re-running the same perturbation panel and bounding-box probe on a new CXR cohort with independently verified small-lesion annotations and obtaining the same AUC gap between CLS and patch-local pooling.
Figures
read the original abstract
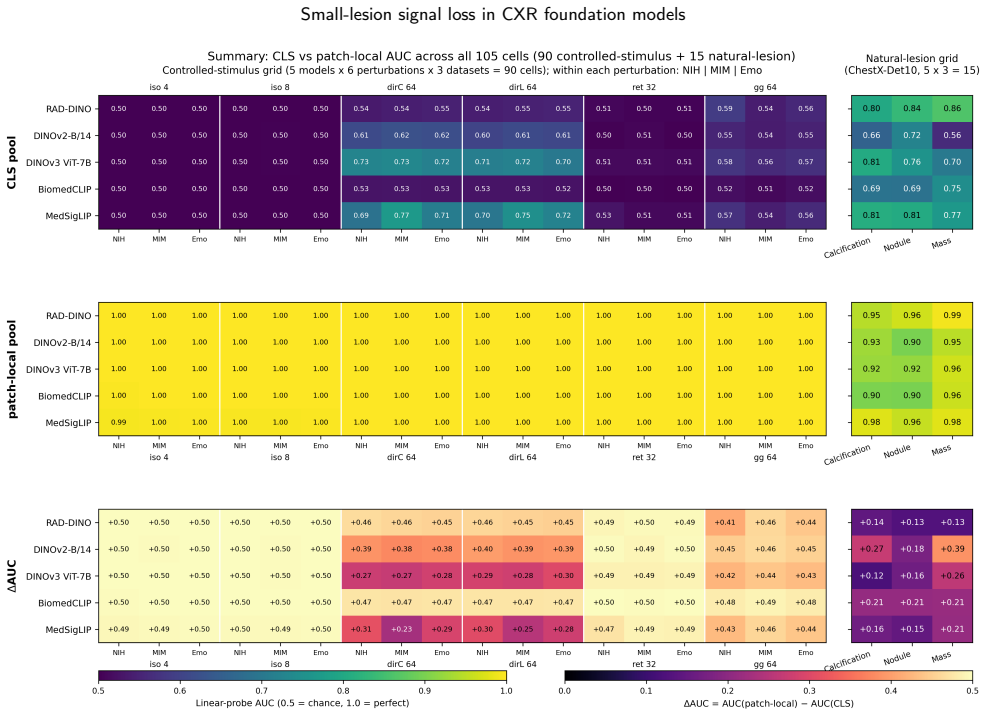
Frozen vision-transformer (ViT) foundation-model embeddings increasingly serve as the substrate for downstream chest-radiography (CXR) pipelines, yet where small-scale, low-contrast signal is retained or lost in the frozen forward pass has not been systematically quantified across architectures, pretraining domains, and objectives. We probed five frozen ViTs (RAD-DINO, DINOv2-B/14, DINOv3 ViT-7B, BiomedCLIP, MedSigLIP) and a frozen DINO-pretrained ResNet-50 architectural control across three large CXR cohorts (NIH-CXR14, MIMIC-CXR, Emory-CXR; aggregate pool n=492,724) and ChestX-Det10 (n=3,543; 1,462 small-lesion bounding boxes across Calcification, Nodule, Mass). Each model was evaluated with a small-scale-perturbation panel and a region-aware bounding-box-stratified probe on real lesions, comparing three pooling modes from the same forward pass: classification token (CLS), patch-mean (mean over all final-layer patch tokens), and bounding-box-restricted patch-local. On the perturbation panel, CLS embeddings sat at the chance floor (area under the ROC curve [AUC] 0.500-0.524); patch-mean was indistinguishable from CLS on iso-blur and reticular-fine cells but rose with CLS on larger directional-blur footprints, while disease AUC on globally decided tasks ranged 0.642-0.913. Patch-local probes recovered AUC ~1.0 from the same forward pass (per-model mean improvement +0.412 to +0.488); the ResNet-50 control reproduced the chance floor. On ChestX-Det10, image-level CLS classification showed within-class small-versus-large stratum gaps up to +0.243 AUC; bounding-box-level patch-local pooling on the same forward pass recovered AUC >= 0.899 on every (model x class) cell. Frozen ViT embeddings silently suppress small-scale signal at the global-aggregation step; the signal is recoverable from patch tokens conditional on a region of interest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that frozen ViT foundation-model embeddings for chest radiography suppress small-scale, low-contrast lesion signals at the global-aggregation step (CLS token or full-image patch-mean pooling), with AUCs near chance (0.500-0.524) on a synthetic perturbation panel and small-vs-large stratum gaps up to 0.243 on ChestX-Det10; the suppressed signal is recoverable (AUC >=0.899, mean gains +0.412 to +0.488) from the same forward pass when patch tokens are restricted to ground-truth bounding boxes. This is shown consistently across five ViTs plus ResNet-50 control on aggregate n=492k CXR images plus ChestX-Det10 (n=3,543).
Significance. If the central empirical distinction between global aggregation loss and patch-local recovery holds after addressing potential confounds, the result is significant for pre-deployment evaluation of foundation models in medical imaging: it quantifies a previously unmeasured failure mode for small-lesion tasks and supplies a concrete diagnostic (bounding-box-restricted patch probes) that could guide ROI-aware fine-tuning or hybrid pooling strategies. The large aggregate sample, directional consistency across five ViTs, and dual synthetic-plus-real-lesion design are strengths that make the observation reproducible and falsifiable.
major comments (2)
- [Abstract / ChestX-Det10 results] Abstract and ChestX-Det10 bounding-box probe (n=1,462 small-lesion boxes): the claim that the observed +0.243 AUC small-vs-large gaps and +0.412–0.488 patch-local recovery isolate signal loss specifically at the global-aggregation step is load-bearing for the central thesis, yet the manuscript provides no sensitivity analysis to bounding-box jitter or localization precision; if small-lesion boxes contain typical annotation noise, the CLS depression could arise from mislocalized examples while patch-local AUC remains high simply because selected patches still capture residual signal.
- [Abstract / perturbation panel] Perturbation panel results (CLS AUC 0.500-0.524, patch-mean indistinguishable on iso-blur/reticular-fine cells): the reported values are presented without error bars, exact statistical tests, or full exclusion criteria, leaving open the possibility that unstated post-hoc choices affect the directional findings; this weakens attribution of the chance-floor behavior solely to aggregation mechanics rather than dataset or model-specific factors.
minor comments (2)
- [Methods / control model] The ResNet-50 architectural control is stated to reproduce the chance floor, but the exact pooling implementation (CLS-equivalent vs. global average) and layer from which tokens are taken should be specified to confirm equivalence with the ViT forward-pass setup.
- [Abstract / model list] Model naming (DINOv3 ViT-7B) and pretraining-domain details for each of the five ViTs could be clarified with a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / ChestX-Det10 results] Abstract and ChestX-Det10 bounding-box probe (n=1,462 small-lesion boxes): the claim that the observed +0.243 AUC small-vs-large gaps and +0.412–0.488 patch-local recovery isolate signal loss specifically at the global-aggregation step is load-bearing for the central thesis, yet the manuscript provides no sensitivity analysis to bounding-box jitter or localization precision; if small-lesion boxes contain typical annotation noise, the CLS depression could arise from mislocalized examples while patch-local AUC remains high simply because selected patches still capture residual signal.
Authors: We agree a sensitivity analysis to bounding-box jitter would further isolate aggregation effects from annotation noise. In revision we will add experiments that apply controlled Gaussian perturbations (sigma = 5–20 pixels) to the ground-truth boxes on ChestX-Det10 and recompute patch-local AUCs; we will also report the fraction of boxes whose perturbed regions still overlap the original lesion. The synthetic perturbation panel supplies orthogonal evidence that does not depend on any bounding-box annotations and already shows CLS AUC at the chance floor across five ViTs. revision: yes
-
Referee: [Abstract / perturbation panel] Perturbation panel results (CLS AUC 0.500-0.524, patch-mean indistinguishable on iso-blur/reticular-fine cells): the reported values are presented without error bars, exact statistical tests, or full exclusion criteria, leaving open the possibility that unstated post-hoc choices affect the directional findings; this weakens attribution of the chance-floor behavior solely to aggregation mechanics rather than dataset or model-specific factors.
Authors: We will add bootstrap 95 % confidence intervals for every AUC, state the use of DeLong’s test for AUC comparisons, and include the complete exclusion criteria, cohort definitions, and image-level filtering steps in the Methods. These changes will allow readers to evaluate the statistical support for the reported chance-floor behavior. revision: yes
Circularity Check
No significant circularity; purely empirical forward-pass measurements
full rationale
The paper consists entirely of empirical evaluations: forward passes of five frozen ViTs plus a ResNet control on public CXR cohorts (NIH-CXR14, MIMIC-CXR, Emory-CXR, ChestX-Det10), followed by direct AUC comparisons across three pooling modes (CLS, patch-mean, bounding-box-restricted patch-local) on a synthetic perturbation panel and real-lesion bounding-box stratification. No equations, fitted parameters, derivations, or predictions appear; the reported AUC gaps (+0.243, +0.412–0.488) are raw measurement outputs, not reductions of any claimed derivation. No self-citations are invoked as load-bearing premises. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbation panel and bounding-box probes isolate embedding signal retention independent of downstream classifier choice or labeling noise.
Reference graph
Works this paper leans on
-
[1]
Foundation models for radiology: Fundamentals, applications, opportunities, chal- lenges, risks, and prospects
AkinciD’Antonoli,T.,Bluethgen,C.,Cuocolo,R.,etal.,2025. Foundation models for radiology: Fundamentals, applications, opportunities, chal- lenges, risks, and prospects. Diagnostic and Interventional Radiology . Banerjee, I., Bhattacharjee, K., Burns, J.L., Trivedi, H., Purkayastha, S., Seyyed-Kalantari, L., Patel, B.N., Shiradkar, R., Gichoya, J.W.,
2025
-
[2]
“shortcuts”causingbiasinradiologyartificialintelligence:Causes,eval- uation, and mitigation. Journal of the American College of Radiology 20, 842–851. doi:10.1016/j.jacr.2023.06.025. Benjamini, Y., Hochberg, Y.,
-
[3]
MedImageInsight:Anopen-source embedding model for general domain medical imaging
Codella,N.,Jin,Y.,Jain,S.,etal.,2024. MedImageInsight:Anopen-source embedding model for general domain medical imaging. arXiv preprint arXiv:2410.06542 . Dapamede, T., Li, F., Khosravi, B., Purkayastha, S., Trivedi, H., Gichoya, J.,
-
[4]
JournalofImagingInformaticsinMedicine 38, 3040–3048
DICOM LUT is a key step in medical image preprocessing towardsAIgeneralizability. JournalofImagingInformaticsinMedicine 38, 3040–3048. doi:10.1007/s10278-025-01418-5. Darcet,T.,Oquab,M.,Mairal,J.,Bojanowski,P.,2024.Visiontransformers need registers. International Conference on Learning Representations (ICLR). DeLong, E., DeLong, D., Clarke-Pearson, D.,
-
[5]
Biometrics 44, 837–845
Comparing the areas undertwoormorecorrelatedreceiveroperatingcharacteristiccurves:A nonparametric approach. Biometrics 44, 837–845. Fang,M.,Wang,Z.,Pan,S.,etal.,2025. Largemodelsinmedicalimaging: Advances and prospects. Chinese Medical Journal 138, 1647–1664. Hansell,D.M.,Bankier,A.A.,MacMahon,H.,McLoud,T.C.,Müller,N.L., Remy, J.,
2025
-
[6]
Radiology 246, 697–722
Fleischner society: Glossary of terms for thoracic imaging. Radiology 246, 697–722. Henschke, C.I., Yankelevitz, D.F., Libby, D.M., Pasmantier, M.W., Smith, J.P.,Miettinen,O.S.,2006. SurvivalofpatientswithstageIlungcancer detectedonCTscreening.NewEnglandJournalofMedicine355,1763–
2006
-
[7]
R. Muthyala et al.:Preprint Page 22 of 23 Small-lesion signal loss in CXR foundation models Khoiwal,R.,McMillan,A.,2024. Embeddingsareallyouneed!achieving high performance medical image classification through training-free embedding analysis. arXiv preprint arXiv:2412.09445 . Khosravi, B., Li, F., Dapamede, T., Rouzrokh, P., Gamble, C.U., Trivedi, H.M., W...
-
[8]
arXiv preprint arXiv:2509.06467
Does DINOv3 set a new medical vision standard? benchmarking2Dand3Dclassification,segmentation,andregistration. arXiv preprint arXiv:2509.06467 . Liu, J., Lian, J., Yu, Y.,
-
[9]
Marouani, A., Siméoni, O., Jégou, H., Bojanowski, P., Vo, H.V.,
ChestX-Det10: Chest x-ray dataset on detection of thoracic abnormalities.arXiv:2006.10550v3. Marouani, A., Siméoni, O., Jégou, H., Bojanowski, P., Vo, H.V.,
-
[10]
Revisiting [CLS] and patch token interaction in vision transformers,
Revisiting [CLS] and patch token interaction in vision transformers. arXiv:2602.08626. McInnes, L., Healy, J., Melville, J.,
-
[11]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 . Morin, R., Mahesh, M.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Nature Machine Intelligence 7, 119–130
RAD-DINO: Exploring scalable medical image encoders beyond text supervision. Nature Machine Intelligence 7, 119–130. Ranftl,R.,Bochkovskiy,A.,Koltun,V.,2021.Visiontransformersfordense prediction, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 12179–12188. Rashtchian, C., Herrmann, C., Ferng, C.S., Chakrabarti, A., ...
2021
-
[13]
Substance or style: What does your image embedding know? arXiv preprint arXiv:2307.05610 . Rousseeuw, P.,
-
[14]
MedGemma technical report. arXiv preprint arXiv:2507.05201 . Siméoni, O., Vo, H., Seitzer, M., et al.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DINOv3.arXiv:2508.10104. Sun, X., Xu, W.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
3462–3471
ChestX-ray8: Hospital-scale chest x-raydatabaseandbenchmarksonweakly-supervisedclassificationand localization of common thorax diseases, in: CVPR, pp. 3462–3471. Yang,Z.,Xu,X.,Zhang,J.,Wang,G.,Kalra,M.K.,Yan,P.,2025. ChestX- ray foundation model with global and local representations integration. IEEE Transactions on Medical Imaging 44, 4787–4799. Zedda, L...
2025
-
[17]
Large-scale domain-specific pretraining for biomedical vision-language processing. arXiv preprint arXiv:2303.00915 . Zhou, D., Yu, Z., Xie, E., et al.,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.