Rethinking Speech-LLM Integration for ASR: Effective Joint Speech-Text Training by Interleaving
Pith reviewed 2026-07-03 15:15 UTC · model grok-4.3
The pith
Interleaving speech and text in pretraining improves entity accuracy for large-scale automatic speech recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
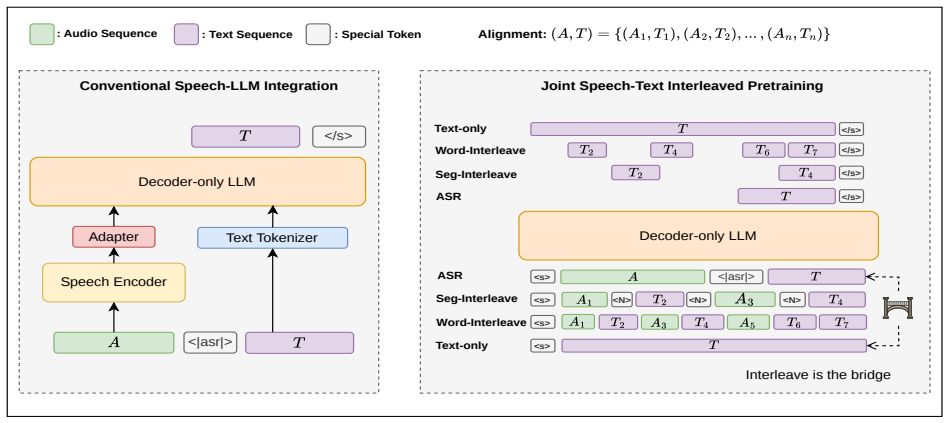
Joint Speech-Text Interleaved Pretraining (JSTIP) constructs word-level and segment-level interleaved speech-text sequences within aligned pairs for speech-LLM architectures that accept continuous inputs. Experiments on 38k hours of ASR data show consistent entity accuracy improvement compared to ASR-only and joint speech-text training baselines. JSTIP achieves on-par entity recognition performance using domain transcription text compared to synthetic speech-text pairs. The zero-shot speech question answering behaviors further suggest that interleaving reduces the speech-text modality gap and preserves the LLM generative prior, which is likely the reason for the entity improvements on the AS
What carries the argument
Joint Speech-Text Interleaved Pretraining (JSTIP), which builds word-level and segment-level interleaved sequences from aligned speech-text pairs to train continuous-input speech-LLM models for ASR.
If this is right
- Consistent entity accuracy gains appear on 38k hours of ASR data relative to ASR-only and standard joint baselines.
- Domain adaptation reaches equivalent entity recognition when real transcription text replaces synthetic speech-text pairs.
- Medical entity recognition becomes competitive with open-source ASR and Speech-LLM systems.
- Zero-shot speech question answering indicates reduced modality gap and retained generative prior.
Where Pith is reading between the lines
- The same interleaving pattern may reduce the need to synthesize speech for additional text data during domain adaptation.
- Preservation of the generative prior could support stronger zero-shot or few-shot performance on other speech understanding tasks.
- Interleaving might extend to other modality pairs where one side already carries extensive pretraining.
Load-bearing premise
The accuracy gains come from the interleaving mechanism itself rather than from differences in total compute, data ordering, or other training details.
What would settle it
A controlled run that matches total training steps, data volume, and ordering exactly between an interleaved version and a non-interleaved joint-training version, then checks whether the entity accuracy gap on the same test sets disappears.
Figures
read the original abstract
Speech-LLM integration has shown promising results by leveraging extensive textual pretraining, yet its specific benefits for automatic speech recognition (ASR) remain unclear. We observe that as supervised ASR training data increases, the contribution of LLM priors becomes less evident, and simple speech-text joint training under-utilizes textual knowledge. We therefore propose Joint Speech-Text Interleaved Pretraining (JSTIP), an ASR-oriented pretraining strategy that constructs word-level and segment-level interleaved speech-text sequences within aligned pairs for speech-LLM architectures that accept continuous inputs. Experiments on 38k hours of ASR data show consistent entity accuracy improvement compared to ASR-only and joint speech-text training baselines. JSTIP achieves on-par entity recognition performance using domain transcription text compared to synthetic speech-text pairs, simplifying domain adaptation. Benefiting from textual pretraining and domain text data, JSTIP is competitive with open-source ASR and Speech-LLM systems in medical entity recognition. The zero-shot speech question answering behaviors further suggest that interleaving reduces the speech-text modality gap and preserves the LLM generative prior, which is likely the reason for the entity improvements on the ASR task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Joint Speech-Text Interleaved Pretraining (JSTIP), a strategy for speech-LLM architectures that interleaves word-level and segment-level speech-text sequences within aligned pairs. Experiments on 38k hours of ASR data are reported to show consistent entity accuracy improvements over ASR-only and joint speech-text baselines. JSTIP is said to achieve on-par entity recognition with domain transcription text compared to synthetic pairs, be competitive in medical entity recognition, and zero-shot QA behaviors suggest reduced modality gap and preserved LLM prior.
Significance. Should the gains prove attributable specifically to the interleaving approach after appropriate controls, the method could provide an effective way to leverage extensive textual pretraining for ASR without relying on synthetic data, thereby simplifying domain adaptation. The indication that interleaving helps maintain the LLM's generative capabilities while bridging modalities may have implications for multi-modal speech applications.
major comments (1)
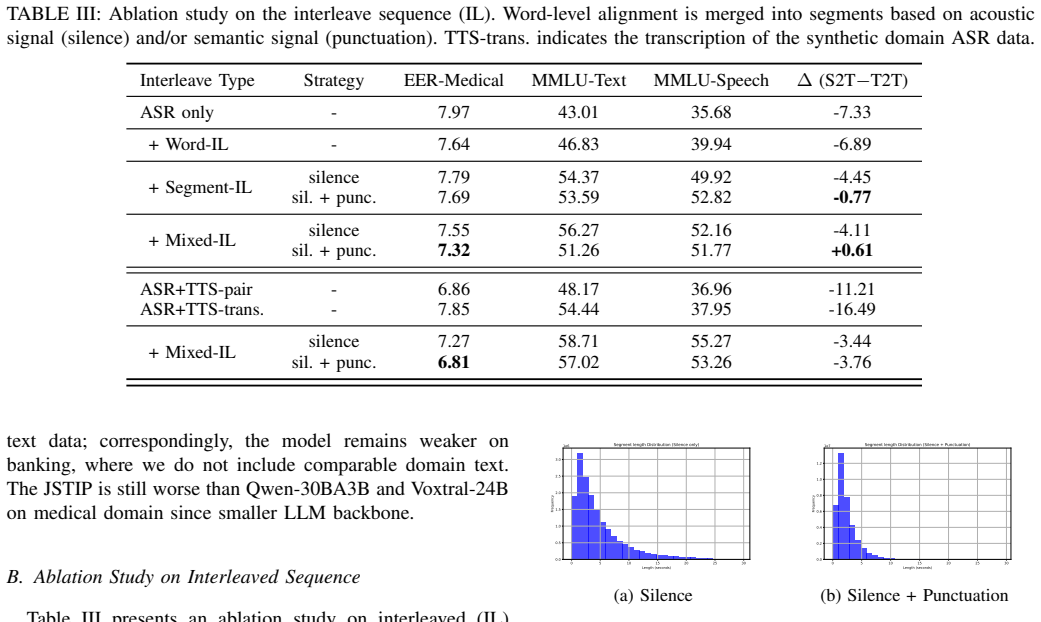
- [Experimental section] The attribution of entity accuracy gains to the interleaving mechanism (abstract) lacks support from a controlled experiment that fixes total tokens, data ordering, and sequence length while varying only the interleaving construction. Current baselines do not isolate this factor, raising the possibility that gains arise from other unstated training details.
minor comments (1)
- The abstract would be strengthened by including at least one quantitative result (e.g., absolute accuracy numbers or relative improvement) to convey the scale of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper accordingly to strengthen the experimental claims.
read point-by-point responses
-
Referee: [Experimental section] The attribution of entity accuracy gains to the interleaving mechanism (abstract) lacks support from a controlled experiment that fixes total tokens, data ordering, and sequence length while varying only the interleaving construction. Current baselines do not isolate this factor, raising the possibility that gains arise from other unstated training details.
Authors: We agree that a fully isolated ablation fixing total tokens, data ordering, and sequence length while varying solely the interleaving construction would provide stronger evidence. Our joint speech-text baseline uses identical ASR training data (38k hours), the same total token volume, and comparable training hyperparameters and shuffling procedures, with the primary difference being sequence construction (concatenated pairs versus word- and segment-level interleaving within aligned pairs). However, interleaving inherently affects per-sequence token distribution and effective length, so sequence length was not strictly fixed across conditions. We will revise the experimental section to explicitly document token counts, ordering, and length statistics for all conditions and add a clarifying discussion of these controls. If compute resources permit, we will also include a limited additional ablation that enforces stricter matching on sequence length. revision: partial
Circularity Check
No circularity; empirical comparisons independent of inputs
full rationale
The paper is an empirical study that proposes the JSTIP training strategy and reports measured entity accuracy improvements on 38k hours of ASR data against baselines. No equations, derivations, or parameter-fitting steps are described that reduce any reported result to a self-referential definition or fitted input. Central claims rest on experimental outcomes rather than theoretical reductions, self-citation chains, or renamed known results. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Aligned speech-text pairs exist and can be segmented at word and segment levels without introducing alignment errors that would dominate the training signal.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ram ´e, M. Rivi `ereet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
On decoder-only architecture for speech-to-text and large language model integration,
J. Wu, Y . Gaur, Z. Chen, L. Zhou, Y . Zhu, T. Wang, J. Li, S. Liu, B. Ren, L. Liuet al., “On decoder-only architecture for speech-to-text and large language model integration,” inProc. ASRU, 2023
2023
-
[7]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar ´e, M. Orsini, A. Royer, P. P ´erez, H. J ´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. MA, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inProc. ICLR, 2024
2024
-
[9]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chenet al., “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture- of-LoRAs,”arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,”arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
SLM-S2ST: A multimodal language model for direct speech- to-speech translation,
Y . Hu, H. Wu, R. Fan, X. Wang, H. Lu, Y . Qian, and J. Li, “SLM-S2ST: A multimodal language model for direct speech- to-speech translation,” inProc. ASRU, 2025. [Online]. Available: https://arxiv.org/abs/2506.04392
-
[14]
Fun-audio-chat technical report,
T. F. Team, Q. Chen, L. Cheng, C. Deng, X. Li, J. Liu, C.-H. Tan, W. Wang, J. Xu, J. Yeet al., “Fun-audio-chat technical report,”arXiv preprint arXiv:2512.20156, 2025
-
[15]
K.-T. Xu, F.-L. Xie, X. Tang, and Y . Hu, “FireRedASR: Open-source industrial-grade mandarin speech recognition models from encoder- decoder to LLM integration,”arXiv preprint arXiv:2501.14350, 2025
-
[16]
Seed-ASR: Understanding diverse speech and contexts with LLM-based speech recognition,
Y . Bai, J. Chen, J. Chen, W. Chen, Z. Chen, C. Ding, L. Dong, Q. Dong, Y . Du, K. Gaoet al., “Seed-ASR: Understanding diverse speech and contexts with LLM-based speech recognition,”arXiv preprint arXiv:2407.04675, 2024
-
[17]
K. An, Y . Chen, C. Deng, C. Gao, Z. Gao, B. Gong, X. Li, Y . Li, X. Lv, Y . Jiet al., “Fun-ASR technical report,”arXiv preprint arXiv:2509.12508, 2025
-
[18]
Z. Song, L. Wang, W. Deng, Z. Yang, Y . Wu, and B. Xia, “Index-ASR technical report,”arXiv preprint arXiv:2601.00890, 2025
-
[19]
Speech recognition meets large language model: Benchmarking, models, and exploration,
Z. Ma, G. Yanget al., “Speech recognition meets large language model: Benchmarking, models, and exploration,” inProc. AAAI, 2025
2025
-
[20]
Efficient scaling for LLM- based ASR,
B. Mu, Y . Shao, K. Wei, D. Yu, and L. Xie, “Efficient scaling for LLM- based ASR,”arXiv preprint arXiv:2508.04096, 2025
-
[21]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yanget al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Transducer-Llama: Integrating LLMs into streamable transducer-based speech recognition,
K. Deng, J. Guoet al., “Transducer-Llama: Integrating LLMs into streamable transducer-based speech recognition,” inProc. ICASSP, 2025
2025
-
[23]
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities,
G. Saon, A. Dekel, A. Brooks, T. Nagano, A. Daniels, A. Satt, A. Mittal, B. Kingsbury, D. Haws, E. Moraiset al., “Granite-speech: Open-source speech-aware llms with strong english asr capabilities,”arXiv preprint arXiv:2505.08699, 2025
-
[24]
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, infer long: Speech-llm enables zero-shot streamable joint asr and diarization on long audio,”arXiv preprint arXiv:2511.16046, 2025
-
[25]
Rlbr: Reinforcement learning with biasing rewards for contextual speech large language models,
B. Ren, R. Fan, Y . Shen, W. Chen, and J. Li, “Rlbr: Reinforcement learning with biasing rewards for contextual speech large language models,” inProc. ICASSP, 2026. [Online]. Available: https://arxiv.org/abs/2601.13409
-
[26]
Wav2Prompt: End-to-end speech prompt learning and task-based fine-tuning for text-based LLMs,
K. Deng, G. Sun, and P. C. Woodland, “Wav2Prompt: End-to-end speech prompt learning and task-based fine-tuning for text-based LLMs,” in Proc. NAACL (V olume 1: Long Papers), 2025
2025
-
[27]
Alignformer: Modality matching can achieve better zero-shot instruction-following speech-LLM,
R. Fan, B. Ren, Y . Hu, R. Zhao, S. Liu, and J. Li, “Alignformer: Modality matching can achieve better zero-shot instruction-following speech-LLM,”IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[28]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [29]
-
[30]
SpiRit- LM: Interleaved spoken and written language model,
T. A. Nguyen, B. Muller, B. Yu, M. R. Costa-jussa, M. Elbayad, S. Popuri, C. Ropers, P.-A. Duquenne, R. Algayres, R. Mavlyutov, I. Gat, M. Williamson, G. Synnaeve, J. Pino, B. Sagot, and E. Dupoux, “SpiRit- LM: Interleaved spoken and written language model,”Transactions of the Association for Computational Linguistics, vol. 13, pp. 30–52,
-
[31]
Available: https://aclanthology.org/2025.tacl-1.2/
[Online]. Available: https://aclanthology.org/2025.tacl-1.2/
2025
-
[32]
J. Xie, X. Li, H. Wang, Y . Yu, Y . Xiang, X. Wu, and Z. Wu, “Enhancing generalization of speech large language models with multi-task behavior imitation and speech-text interleaving,” inProc. Interspeech, 2025. [Online]. Available: https://arxiv.org/abs/2505.18644
-
[33]
Injecting text in self-supervised speech pretraining,
Z. Chen, Y . Zhang, A. Rosenberg, B. Ramabhadran, G. Wang, and P. Moreno, “Injecting text in self-supervised speech pretraining,” inProc. ASRU, 2021
2021
-
[34]
SpeechLM: Enhanced speech pre-training with unpaired textual data,
Z. Zhang, S. Chen, L. Zhou, Y . Wu, S. Ren, S. Liu, Z. Yao, X. Gong, L. Dai, J. Liet al., “SpeechLM: Enhanced speech pre-training with unpaired textual data,”arXiv preprint arXiv:2209.15329, 2022
-
[35]
SpeechT5: Unified-modal encoder- decoder pre-training for spoken language processing,
J. Ao, R. Wang, L. Zhou, S. Liu, S. Ren, Y . Wu, T. Ko, Q. Li, Y . Zhang, Z. Wei, Y . Qian, J. Li, and F. Wei, “SpeechT5: Unified-modal encoder- decoder pre-training for spoken language processing,” inProc. ACL, 2022
2022
-
[36]
SLAM: A unified encoder for speech and language modeling via speech-text joint pre-training,
A. Bapna, Y .-a. Chung, N. Wu, A. Gulati, Y . Jia, J. H. Clark, M. Johnson, J. Riesa, A. Conneau, and Y . Zhang, “SLAM: A unified encoder for speech and language modeling via speech-text joint pre-training,”ArXiv, vol. abs/2110.10329, 2021
-
[37]
JOIST: A joint speech and text streaming model for ASR,
T. N. Sainath, R. Prabhavalkar, A. Bapna, Y . Zhang, Z. Huo, Z. Chen, B. Li, W. Wang, and T. Strohman, “JOIST: A joint speech and text streaming model for ASR,” inProc. SLT, 2023
2023
-
[38]
Joint unsupervised and supervised training for multilingual ASR,
J. Bai, B. Li, Y . Zhang, A. Bapna, N. Siddhartha, K. C. Sim, and T. N. Sainath, “Joint unsupervised and supervised training for multilingual ASR,” inProc. ICASSP, 2022
2022
-
[39]
FastInject: Injecting unpaired text data into CTC-based ASR training,
K. Deng and P. C. Woodland, “FastInject: Injecting unpaired text data into CTC-based ASR training,” inProc. ICASSP, 2024
2024
-
[40]
Multitask training with text data for end-to-end speech recognition,
P. Wang, T. N. Sainath, and R. J. Weiss, “Multitask training with text data for end-to-end speech recognition,” inProc. Interspeech, 2021
2021
-
[41]
An attention-based joint acoustic and text on-device end-to-end model,
T. N. Sainath, R. Pang, R. J. Weiss, Y . He, C.-c. Chiu, and T. Strohman, “An attention-based joint acoustic and text on-device end-to-end model,” inProc. ICASSP, 2020
2020
-
[42]
Maestro: Matched speech text representations through modality matching,
Z. Chen, Y . Zhang, A. Rosenberg, B. Ramabhadran, P. J. Moreno, A. Bapna, and H. Zen, “Maestro: Matched speech text representations through modality matching,” inProc. Interspeech, 2022
2022
-
[43]
Improving joint speech-text repre- sentations without alignment,
C. Peyser, Z. Meng, R. Prabhavalkar, A. Rosenberg, T. Sainath, M. Picheny, K. Cho, and K. Hu, “Improving joint speech-text repre- sentations without alignment,” inProc. Interspeech, 2023
2023
-
[44]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[45]
Ultraeval-audio: A unified framework for comprehensive evaluation of audio foundation models,
Q. Shi, J. Zhou, B. Lin, J. Cui, G. Zeng, Y . Zhou, Z. Wang, X. Liu, Z. Luo, Y . Wanget al., “Ultraeval-audio: A unified framework for comprehensive evaluation of audio foundation models,”arXiv preprint arXiv:2601.01373, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.