Again-Pose: Anchor-Guided Adaptive Inter-Frame Motion Cues Propagating for High-quality Human Pose Reconstruction
Pith reviewed 2026-06-30 07:41 UTC · model grok-4.3
The pith
Explicit identification of high-quality anchor frames and propagation of their kinematic cues recovers plausible 3D human poses in video frames degraded by blur or occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
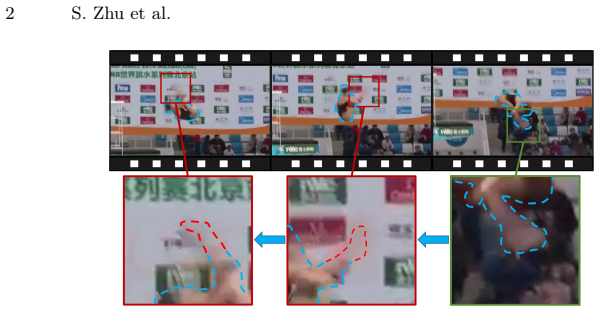
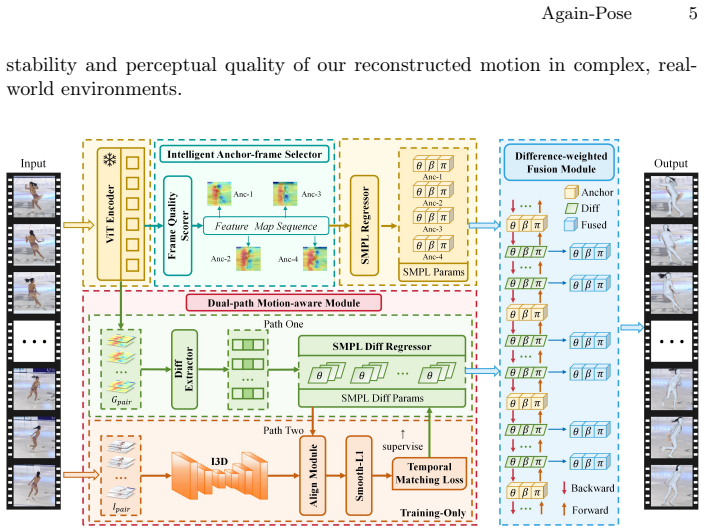
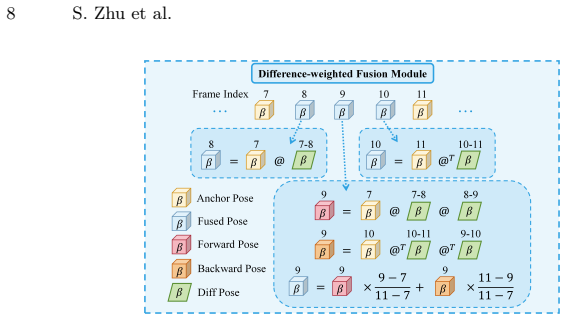
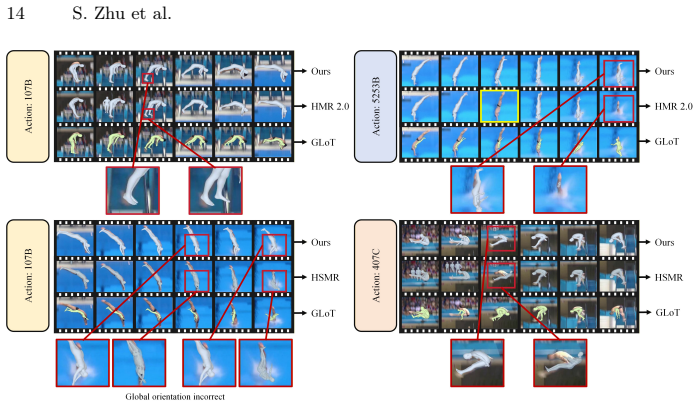
Again-Pose reformulates pose estimation in degraded frames as a motion-guided recovery task by explicitly identifying high-quality Anchor Frames based on feature saliency and propagating reliable kinematic cues to inpaint the poses of degraded intermediate frames. A Dual-path Motion-aware Module captures fine-grained inter-frame dynamics while a Difference-weighted Fusion Module adaptively propagates these cues to suppress drift. On Human3.6M, 3DPW, PoseTrack and the challenging FineDiving dataset the approach recovers plausible poses where state-of-the-art implicit methods fail.
What carries the argument
Anchor-guided adaptive inter-frame motion cues propagating, which selects salient anchor frames and uses dual-path motion capture plus difference-weighted fusion to propagate kinematic cues to degraded frames.
If this is right
- The method outperforms prior approaches in robustness on Human3.6M, 3DPW, PoseTrack and FineDiving under extreme motion degradation.
- Explicit anchor selection and cue propagation succeeds where implicit feature aggregation collapses under blur or occlusion.
- The dual-path module supplies fine-grained dynamics while the fusion module limits drift during inpainting.
- Plausible poses are recovered in frames that defeat standard temporal attention pipelines.
Where Pith is reading between the lines
- The anchoring principle could transfer to other video tasks that require stable reconstruction under partial signal loss, such as object tracking or scene flow.
- If anchor selection proves reliable it may enable lighter models that allocate heavy computation only around high-saliency frames rather than across entire sequences.
- Hybrid explicit-implicit pipelines might improve temporal coherence in general video understanding beyond pose alone.
Load-bearing premise
High-quality anchor frames can be reliably identified based on feature saliency and their kinematic cues can be propagated to degraded frames without introducing new errors.
What would settle it
A controlled test set of videos in which frames chosen by feature saliency produce propagated poses that are less accurate or more inconsistent than those from implicit aggregation methods.
Figures
read the original abstract
Reconstructing continuous 3D human poses from unconstrained videos is challenging, especially in extreme motion scenarios involving severe motion blur and occlusion. Current state-of-the-art methods typically rely on implicit temporal attention to aggregate features across frames. However, under severe visual degradation, input features often suffer from collapse, rendering them indistinguishable from noise. In such cases, implicit aggregation fails to distinguish valid signals, leading to catastrophic reconstruction errors. To address this robustness gap, we propose a simple yet effective framework called Anchor-guided adaptive inter-frame motion cues propagating (Again-Pose), reformulating pose estimation in degraded frames as a motion-guided recovery task. Instead of blindly smoothing features, we explicitly identify high-quality Anchor Frames based on feature saliency and propagate reliable kinematic cues to "inpaint" the poses of degraded intermediate frames. Specifically, a Dual-path Motion-aware Module captures fine-grained inter-frame dynamics, while a Difference-weighted Fusion Module adaptively propagates these cues to suppress drift. Extensive experiments on standard benchmarks (Human3.6M, 3DPW, PoseTrack) and the challenging FineDiving dataset demonstrate that Again-Pose significantly outperforms state-of-the-art methods in robustness and stability, effectively recovering plausible poses where other methods fail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Again-Pose, a framework that reformulates 3D human pose reconstruction in degraded video frames as an anchor-guided motion inpainting task. High-quality anchor frames are selected via feature saliency; kinematic cues are then captured by a Dual-path Motion-aware Module and adaptively propagated to intermediate frames by a Difference-weighted Fusion Module. Experiments on Human3.6M, 3DPW, PoseTrack, and the challenging FineDiving dataset are said to show improved robustness and stability over prior implicit temporal-attention methods.
Significance. If the reported gains are reproducible and the anchor-selection mechanism proves reliable, the work would address a recognized failure mode of current video pose estimators under severe blur and occlusion, offering a concrete alternative to blind feature aggregation.
major comments (2)
- [Abstract and §3] Abstract and §3 (anchor identification): the claim that feature saliency reliably identifies high-quality anchors is load-bearing for the entire propagation pipeline, yet no independent verification (e.g., correlation between saliency scores and ground-truth pose error on collapsed-feature subsets of FineDiving) is provided. When all frames suffer feature collapse, saliency computed on the same collapsed features has no guaranteed relationship to actual pose quality, risking systematic drift in the Difference-weighted Fusion Module.
- [§4] §4 (experiments): the abstract asserts “significantly outperforms” on multiple benchmarks, but the provided text contains no quantitative tables, error bars, or per-sequence breakdowns on FineDiving. Without these data it is impossible to judge whether the Dual-path and fusion modules actually suppress drift or merely average errors.
minor comments (2)
- [§3.2] Notation for the saliency metric and the weighting function in the Difference-weighted Fusion Module should be defined explicitly with equations rather than prose descriptions.
- [§3.1] The manuscript should clarify whether anchor selection is performed once per sequence or re-evaluated per frame, and how long-term drift is prevented when anchors themselves become unreliable.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. The feedback highlights important aspects of the anchor selection mechanism and experimental presentation that we will address in revision. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (anchor identification): the claim that feature saliency reliably identifies high-quality anchors is load-bearing for the entire propagation pipeline, yet no independent verification (e.g., correlation between saliency scores and ground-truth pose error on collapsed-feature subsets of FineDiving) is provided. When all frames suffer feature collapse, saliency computed on the same collapsed features has no guaranteed relationship to actual pose quality, risking systematic drift in the Difference-weighted Fusion Module.
Authors: We agree that an explicit correlation analysis between saliency scores and ground-truth pose error on degraded subsets would strengthen the justification for the anchor mechanism. In the revised manuscript we will add this verification (a scatter plot and Pearson correlation on FineDiving frames with severe blur/occlusion). Regarding the all-collapse case, our method selects the relatively highest-saliency frames as anchors and the Difference-weighted Fusion Module down-weights unreliable cues; we will expand the discussion in §3 to acknowledge this edge case and its potential for drift. revision: yes
-
Referee: [§4] §4 (experiments): the abstract asserts “significantly outperforms” on multiple benchmarks, but the provided text contains no quantitative tables, error bars, or per-sequence breakdowns on FineDiving. Without these data it is impossible to judge whether the Dual-path and fusion modules actually suppress drift or merely average errors.
Authors: The reviewed version omitted the full experimental tables; the complete manuscript contains Table 3 reporting MPJPE on FineDiving. To enable direct assessment of drift suppression, the revision will include (i) standard-deviation error bars across sequences and (ii) per-sequence breakdowns for the top-10 most degraded clips, allowing readers to verify that gains are not due to simple averaging. revision: yes
Circularity Check
No circularity; empirical framework with no derivation chain
full rationale
The paper presents Again-Pose as an engineering framework that identifies anchor frames via feature saliency and propagates kinematic cues through Dual-path Motion-aware and Difference-weighted Fusion modules. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Performance claims rest on benchmark experiments (Human3.6M, 3DPW, PoseTrack, FineDiving) rather than any reduction of outputs to inputs by construction. The method is therefore self-contained against external evaluation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Again-Pose 19 CVPR (2018)
Andriluka, M., Iqbal, U., Insafutdinov, E., Pishchulin, L., Milan, A., Gall, J., Schiele, B.: Posetrack: A benchmark for human pose estimation and tracking. In: Again-Pose 19 CVPR (2018)
2018
-
[2]
In: CVPR (2014)
Andriluka, M., Pishchulin, L., Gehler, P., Schiele, B.: 2d human pose estimation: New benchmark and state of the art analysis. In: CVPR (2014)
2014
-
[3]
In: CVPR (2017)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: CVPR (2017)
2017
-
[4]
In: CVPR (2020)
Choi, H., Moon, G., Chang, J.Y., Lee, K.M.: Beyond static features for temporally consistent 3d human pose and shape from a video. In: CVPR (2020)
2020
-
[5]
In: ICCV (2023)
Cui, Y., Zeng, C., et al.: Sportsmot: A large multi-object tracking dataset in mul- tiple sports scenes. In: ICCV (2023)
2023
-
[6]
In: CoRL (2024)
Fu, Z., Zhao, Q., Wu, Q., Wetzstein, G., Finn, C.: Humanplus: Humanoid shad- owing and imitation from humans. In: CoRL (2024)
2024
-
[7]
In: ICCV (2023)
Goel, H., Pavlakos, G., Rajasegaran, J., Kanazawa, A., Malik, J.: Humans in 4d: Reconstructing and tracking humans with transformers. In: ICCV (2023)
2023
-
[8]
In: CVPR (2018)
Gu, C., Sun, C., Ross, D.A., Vondrick, C., Pantofaru, C., Li, Y., Vijayanarasimhan, S., Toderici, G., Ricco, S., Sukthankar, R., Schmid, C., Malik, J.: Ava: A video dataset of spatio-temporally localized atomic visual actions. In: CVPR (2018)
2018
-
[9]
Mantis: Mamba-native Tuning is Efficient for 3D Point Cloud Foundation Models
Guo, Z., Zhu, J., Liu, J., Mian, A.S.: Mantis: Mamba-native tuning is efficient for 3d point cloud foundation models. arXiv preprint arXiv:2605.03438 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
PAMI (2013)
Ionescu, C., Papava, D., Olaru, V., Sminchisescu, C.: Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. PAMI (2013)
2013
-
[11]
In: CVPR (2018)
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: CVPR (2018)
2018
-
[12]
In: CVPR (2019)
Kanazawa, A., Zhang, J.Y., Felsen, P., Malik, J.: Learning 3d human dynamics from video. In: CVPR (2019)
2019
-
[13]
In: CVPR (2020)
Kocabas, M., Athanasiou, N., Black, M.J.: Vibe: Video inference for human body pose and shape estimation. In: CVPR (2020)
2020
-
[14]
In: ICCV (2021)
Kocabas, M., Huang, C.H.P., Hilliges, O., Black, M.J.: Pare: Part attention regres- sor for 3d human body estimation. In: ICCV (2021)
2021
- [15]
-
[16]
In: ICCV (2019)
Kolotouros, N., Pavlakos, G., Black, M.J., Daniilidis, K.: Learning to reconstruct 3d human pose and shape via model-fitting in the loop. In: ICCV (2019)
2019
-
[17]
In: CVPR (2019)
Kolotouros, N., Pavlakos, G., Daniilidis, K.: Convolutional mesh regression for single-image human shape reconstruction. In: CVPR (2019)
2019
-
[18]
In: CVPR (2021)
Li, J., Xu, C., Chen, Z., Bian, S., Yang, L., Lu, C.: Hybrik: A hybrid analytical- neural inverse kinematics solution for 3d human pose and shape estimation. In: CVPR (2021)
2021
-
[19]
In: CoRL (2024)
Li, J., Zhu, Y., Xie, Y., Jiang, Z., Seo, M., Pavlakos, G., Zhu, Y.: Okami: Teaching humanoid robots manipulation skills through single video imitation. In: CoRL (2024)
2024
-
[20]
In: ICCV (2021)
Li, Y., Chen, L., et al.: Multisports: A multi-person video dataset of spatiotempo- rally localized sports actions. In: ICCV (2021)
2021
-
[21]
In: ECCV (2022)
Li, Z., Liu, J., Zhang, Z., Xu, S., Yan, Y.: Cliff: Carrying location information in full frames into human pose and shape estimation. In: ECCV (2022)
2022
-
[22]
In: CVPR (2021)
Lin, K., Wang, L., Liu, Z.: End-to-end human pose and mesh reconstruction with transformers. In: CVPR (2021)
2021
-
[23]
In: ICCV (2021)
Lin, K., Wang, L., Liu, Z.: Mesh graphormer. In: ICCV (2021)
2021
-
[24]
In: ECCV (2014) 20 S
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014) 20 S. Zhu et al
2014
-
[25]
ACM Trans
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia)34(6), 248:1–248:16 (2015)
2015
-
[26]
In: ACCV (2020)
Luo, Z., Golestaneh, S.A., Kitani, K.M.: 3d human motion estimation via motion compression and refinement. In: ACCV (2020)
2020
-
[27]
In: 3DV (2017)
Mehta, D., Rhodin, H., Casas, D., Fua, P., Sotnychenko, O., Xu, W., Theobalt, C.: Monocular 3d human pose estimation in the wild using improved cnn supervision. In: 3DV (2017)
2017
-
[28]
TOG37(6), 1–14 (2018)
Peng, X.B., Kanazawa, A., Malik, J., Abbeel, P., Levine, S.: Sfv: Reinforcement learning of physical skills from videos. TOG37(6), 1–14 (2018)
2018
-
[29]
In: NeurIPS (2024)
Radosavovic, I., Zhang, B., Shi, B., Rajasegaran, J., Kamat, S., Darrell, T., Sreenath, K., Malik, J.: Humanoid locomotion as next token prediction. In: NeurIPS (2024)
2024
-
[30]
In: CVPR (2023)
Shen, X., Yang, Z., Wang, X., Ma, J., Zhou, C., Yang, Y.: Global-to-local modeling for video-based 3d human pose and shape estimation. In: CVPR (2023)
2023
-
[31]
In: CVPR (2023)
Shetty, K., Birkhold, A., Jaganathan, S., Strobel, N., Kowarschik, M., Maier, A., Egger, B.: Pliks: A pseudo-linear inverse kinematic solver for 3d human body esti- mation. In: CVPR (2023)
2023
-
[32]
Pattern Recognition p
Sun, Y., Cheng, H., Lu, C., Li, Z., Wu, M., Lu, H., Zhu, J.: Hyperpoint: Multimodal 3d foundation model in hyperbolic space. Pattern Recognition p. 112800 (2025)
2025
-
[33]
IEEE Transactions on Multimedia (2026)
Sun, Y., Zhu, J., Cheng, H., Lu, C., Yang, Z., Chen, L., Wang, Y.: Align then adapt: Rethinking parameter-efficient transfer learning in 4d perception. IEEE Transactions on Multimedia (2026)
2026
-
[34]
In: ICCV (2019)
Sun, Y., Ye, Y., Liu, W., Gao, W., Fu, Y., Mei, T.: Human mesh recovery from monocular images via a skeleton-disentangled representation. In: ICCV (2019)
2019
-
[35]
In: ICCV (2019)
Tome, D., Peluse, P., Agapito, L., Badino, H.: xr-egopose: Egocentric 3d human pose from an hmd camera. In: ICCV (2019)
2019
-
[36]
In: ECCV (2018)
Von Marcard, T., Henschel, R., Black, M.J., Rosenhahn, B., Pons-Moll, G.: Re- covering accurate 3d human pose in the wild using imus and a moving camera. In: ECCV (2018)
2018
-
[37]
In: ICME (2026)
Wang, Y., Sun, Y., Wang, Q., Li, P., Lu, C., Zhang, D.: Pointrft: Explicit rein- forcement fine-tuning for point cloud few-shot learning. In: ICME (2026)
2026
-
[38]
In: ECCV (2024)
Wang, Y., Wang, Z., Liu, L., Daniilidis, K.: Tram: Global trajectory and motion of 3d humans from in-the-wild videos. In: ECCV (2024)
2024
- [39]
-
[40]
In: CVPR (2025)
Xia, Y., Zhou, X., Vouga, E., Huang, Q., Pavlakos, G.: Reconstructing humans with a biomechanically accurate skeleton. In: CVPR (2025)
2025
-
[41]
In: CVPR (2022)
Xu, J., Rao, Y., et al.: Finediving: A fine-grained dataset for procedure-aware action quality assessment. In: CVPR (2022)
2022
-
[42]
In: CVPR (2024)
Xu, J., Yin, S., et al.: Fineparser: A fine-grained spatio-temporal action parser for human-centric action quality assessment. In: CVPR (2024)
2024
-
[43]
PAMI (2023)
Zhang, H., Tian, Y., Zhang, Y., Li, M., An, L., Sun, Z., Liu, Y.: Pymaf-x: Towards well-aligned full-body model regression from monocular images. PAMI (2023)
2023
-
[44]
In: ICCV (2021)
Zhang, H., Tian, Y., Zhou, X., Ouyang, W., Liu, Y., Wang, L., Sun, Z.: Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feedback loop. In: ICCV (2021)
2021
-
[45]
In: CVPR
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation repre- sentations in neural networks. In: CVPR. pp. 5745–5753 (2019) Again-Pose 21
2019
-
[46]
Zhu, S., Yang, Y., Sun, C.: Pose-aware multi-level motion parsing for action quality assessment (2025), arXiv preprint arXiv:2511.05611 22 S. Zhu et al. Fig.S-2: High-fidelity reconstruction in mixed extreme sports.Our method maintains structural integrity and smooth continuous tracking despite catastrophic motion blur. Again-Pose 23 Fig.S-3: Continuous t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.