Error Highways: Scaling Predictive Coding to Very Deep Networks
Pith reviewed 2026-06-26 09:40 UTC · model grok-4.3
The pith
Highway error propagation lets predictive coding networks train 128-layer MLPs with depth-robust accuracy on MNIST.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
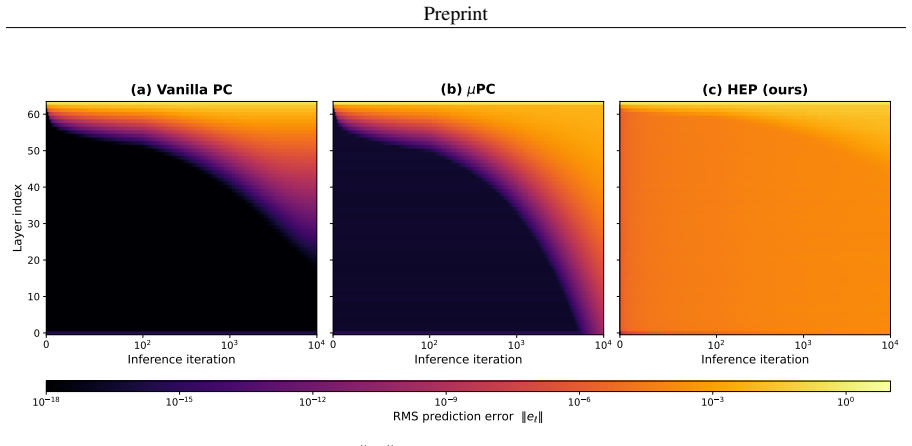
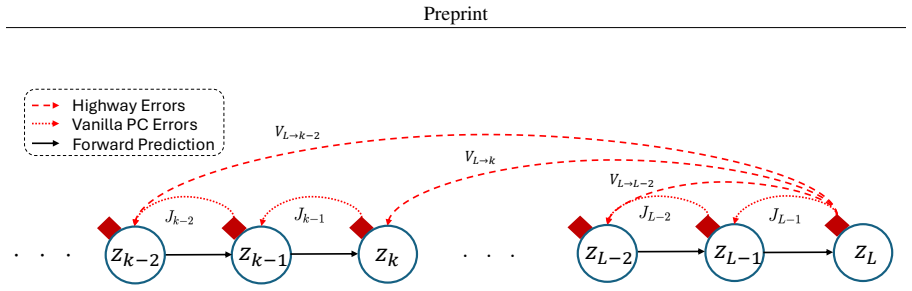
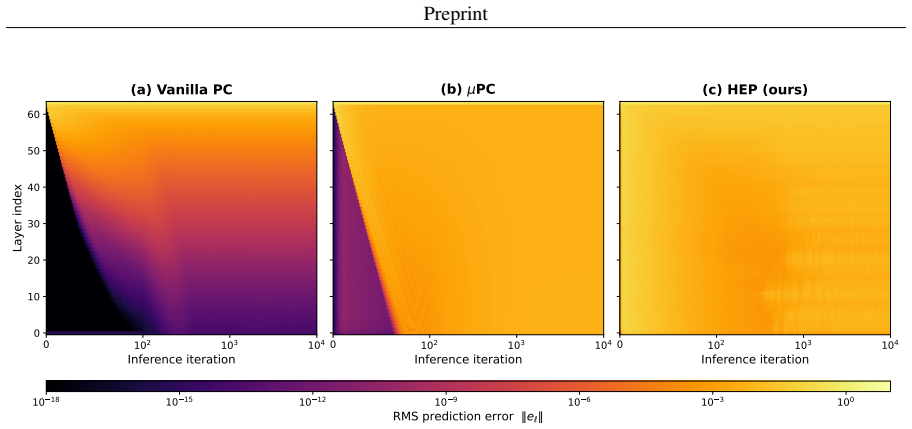
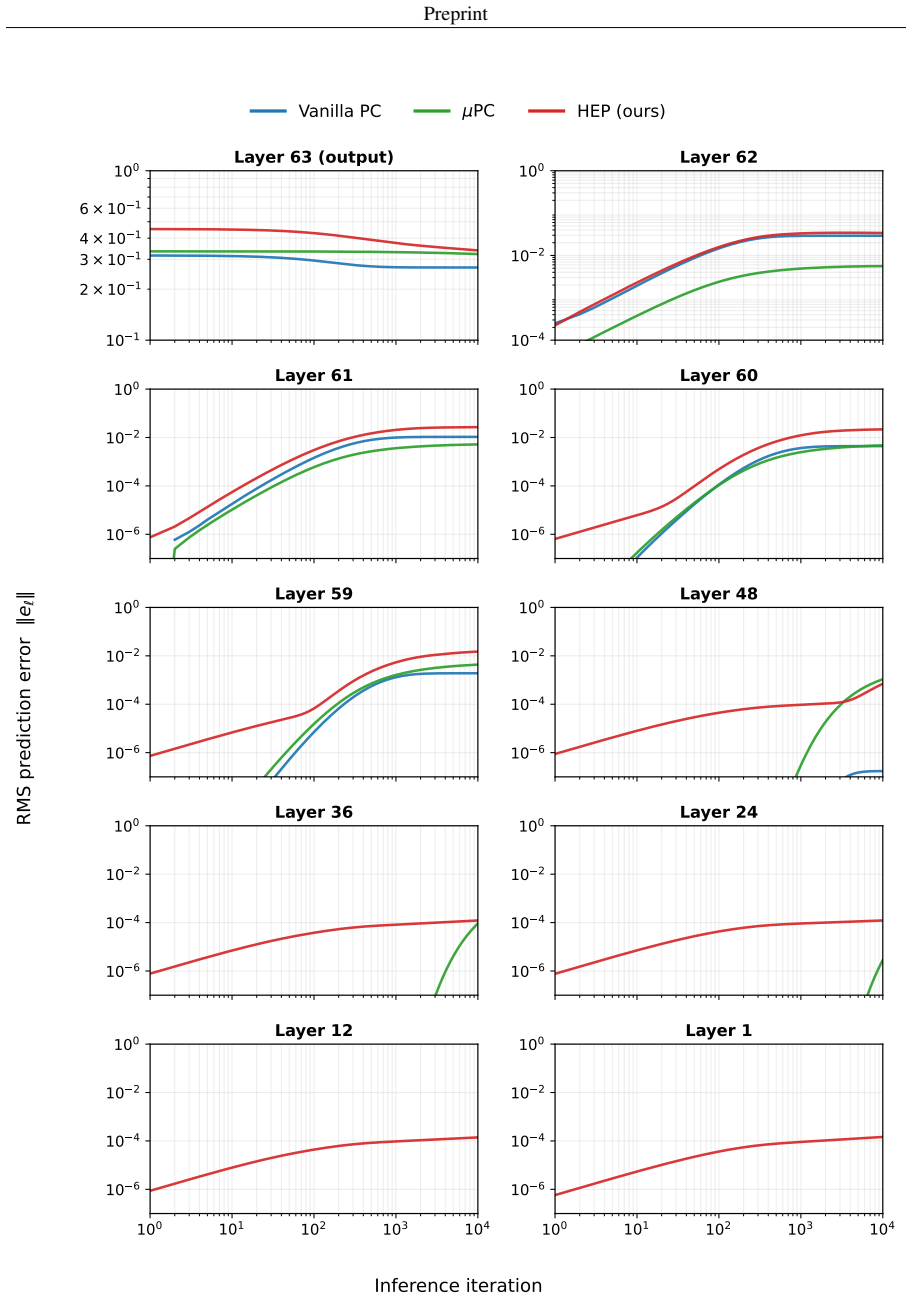
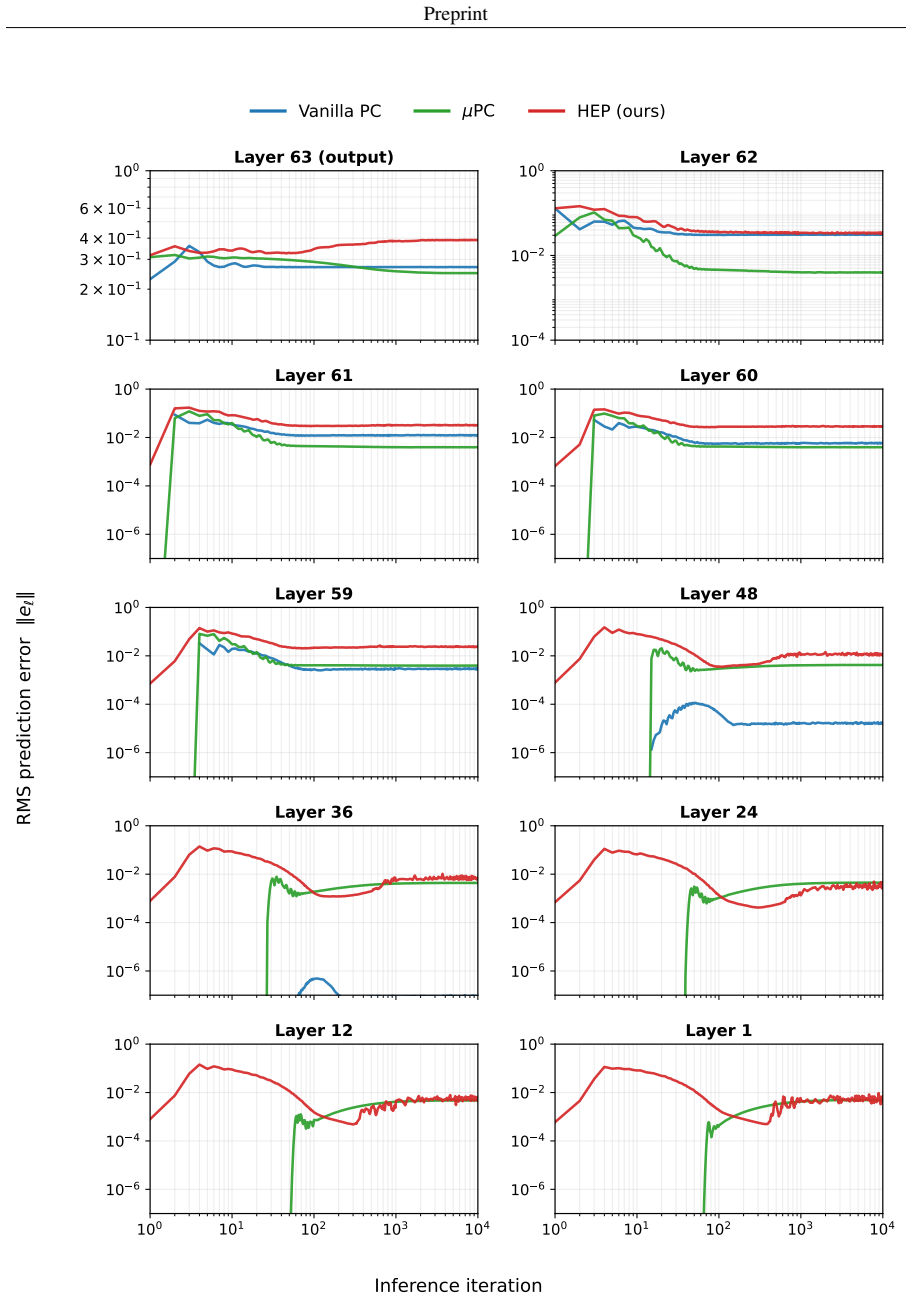
Augmenting the free energy function with feedback matrices V_{L→i} that couple selected hidden states directly to the clamped output error supplies a depth-independent correction at every inference step; because the coupling is linear, the highway pathway reaches interior layers without the exponential decay that occurs when error propagates through the usual Jacobian chain, while the local PC synaptic update rule remains intact.
What carries the argument
Highway error propagation (HEP) via linear feedback matrices V_{L→i} that couple hidden states directly to output error.
If this is right
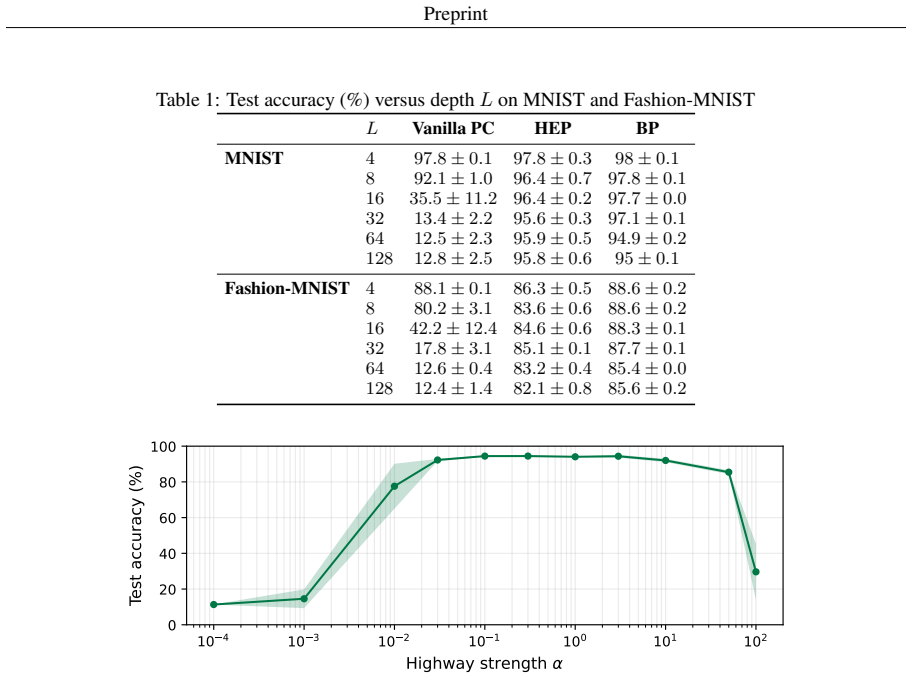
- MLPs up to 128 layers deep can be trained effectively under predictive coding on MNIST and Fashion-MNIST.
- Classification accuracy remains stable as network depth increases when HEP is used.
- The error correction magnitude delivered to any hidden layer stays independent of total depth.
- The local synaptic update rules of predictive coding continue to apply without modification.
Where Pith is reading between the lines
- Similar linear bypass paths might be added to other local-learning schemes to improve depth scaling.
- The approach could be tested on datasets larger than MNIST to check whether the depth robustness generalizes.
- Because the correction is linear, hardware implementations that support only local updates might adopt HEP without extra global communication.
Load-bearing premise
Inserting the linear feedback matrices supplies a depth-independent correction at every inference step while leaving the local PC synaptic update rule intact.
What would settle it
Train identical 128-layer MLPs on MNIST once with HEP and once with standard predictive coding, then compare final test accuracy to check whether the non-HEP version shows clear depth-dependent degradation.
Figures
read the original abstract
Predictive coding networks (PCNs) offer a biologically-plausible, local-learning alternative to back-propagation of errors (backprop). Nevertheless, they have remained largely confined to shallow architectures and evaluated on simple machine intelligence benchmarks. A central obstacle to scaling PCNs is that the learning signal decays rapidly as it propagates away from the clamped boundaries, leaving interior layers effectively unchanged. To directly counter this problem, we propose highway error propagation (HEP), a scheme that augments the free energy function underlying predictive coding (PC) by altering its neural structure with feedback matrices $V_{L\to i}$ that couple selected hidden states directly to the clamped output error. Since this coupling is linear in the hidden state, the highway pathway delivers a correction at every inference step whose magnitude is independent of depth, in contrast to vanilla PC where the output error reaches the $i$-th hidden layer with attenuation that decays exponentially in depth. This bypasses the Jacobian chain while preserving the local PC synaptic update rule. On MNIST and Fashion-MNIST, we show that HEP effectively trains MLPs of up to 128 layers with accuracy that is robust with respect to depth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes highway error propagation (HEP) to scale predictive coding networks (PCNs) to deep architectures. It augments the free energy function with linear feedback matrices V_{L→i} that directly couple selected hidden states h_i to the clamped output error. This is claimed to deliver a depth-independent additive drive on the inference dynamics, bypassing the exponential attenuation of error signals through the Jacobian chain in vanilla PC, while preserving the local PC synaptic update rule. The central empirical claim is that HEP trains MLPs of up to 128 layers on MNIST and Fashion-MNIST with accuracy robust to depth.
Significance. If the locality of all updates (including for the V matrices) is rigorously preserved and the depth-robust accuracy is demonstrated with proper controls, the result would be significant for the field of biologically plausible alternatives to backprop, as it directly targets the vanishing-signal obstacle that has confined PCNs to shallow networks.
major comments (2)
- [Abstract] Abstract (paragraph describing HEP): the claim that the linear coupling via V_{L→i} 'preserves the local PC synaptic update rule' is load-bearing for the contribution but lacks a derivation showing the update for V itself. If V_{L→i} are trainable parameters, their learning rule would require non-local information spanning from layer L to layer i, which cannot be realized by the standard local PC rule (product of adjacent pre- and post-synaptic activities). This distinction must be resolved to substantiate the 'local-learning alternative' framing.
- [Abstract] Abstract (empirical claim): the statement that HEP 'effectively trains MLPs of up to 128 layers with accuracy that is robust with respect to depth' is central but unsupported by any protocol, baseline (standard PC or backprop), ablation on V, number of runs, or error bars in the supplied text; without these the robustness claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address each of the major comments below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing HEP): the claim that the linear coupling via V_{L→i} 'preserves the local PC synaptic update rule' is load-bearing for the contribution but lacks a derivation showing the update for V itself. If V_{L→i} are trainable parameters, their learning rule would require non-local information spanning from layer L to layer i, which cannot be realized by the standard local PC rule (product of adjacent pre- and post-synaptic activities). This distinction must be resolved to substantiate the 'local-learning alternative' framing.
Authors: The V matrices are fixed feedback connections that do not undergo learning; they are architectural augmentations to the free energy function. Consequently, there is no update rule for V, and the standard local PC synaptic updates for the weight matrices are preserved without modification. The full manuscript elaborates on this structure. We will revise the abstract and relevant sections to explicitly note that the V matrices are fixed and not subject to the PC learning rule. revision: yes
-
Referee: [Abstract] Abstract (empirical claim): the statement that HEP 'effectively trains MLPs of up to 128 layers with accuracy that is robust with respect to depth' is central but unsupported by any protocol, baseline (standard PC or backprop), ablation on V, number of runs, or error bars in the supplied text; without these the robustness claim cannot be evaluated.
Authors: The abstract provides a high-level summary of the results. The full manuscript contains the detailed experimental setup, including protocols, baselines such as standard PC and backpropagation, ablations on the role of V, statistics over multiple runs, and error bars, all demonstrating the depth-independent performance on MNIST and Fashion-MNIST. We believe the claim is substantiated in the body of the paper. revision: no
Circularity Check
No significant circularity; structural augmentation with empirical results
full rationale
The paper proposes HEP by augmenting the free energy function with linear feedback matrices V_{L→i} that couple hidden states to output error. This is presented as a direct structural change that yields depth-independent drive by construction of the added linear terms, while the claim of preserved local PC updates is asserted as a consequence of the formulation. No parameters are fitted to data and then relabeled as predictions, no self-citations form the load-bearing justification, and the MNIST/Fashion-MNIST accuracy results are reported as experimental outcomes rather than derived tautologies. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
feedback matrices V_{L o i}
no independent evidence
Reference graph
Works this paper leans on
-
[1]
How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation
BENGIO, Y. How auto-encoders could provide credit assignment in deep networks via target propagation. arXiv preprint arXiv:1407.7906(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Accelerated predictive coding networks via direct kolen–pollack feedback alignment, 2026
CASNICI, D., LEFEBVRE, M., DAUWELS, J.,ANDFRENKEL, C. Accelerated predictive coding networks via direct kolen–pollack feedback alignment, 2026
2026
-
[3]
P., LAIRD, N
DEMPSTER, A. P., LAIRD, N. M.,ANDRUBIN, D. B. Maximum likelihood from incomplete data via the em algorithm.Journal of the royal statistical society: series B (methodological) 39, 1 (1977), 1–22
1977
-
[4]
A theory of cortical responses.Philosophical Transactions of the Royal Society B: Biological Sciences 360, 1456 (04 2005), 815–836
FRISTON, K. A theory of cortical responses.Philosophical Transactions of the Royal Society B: Biological Sciences 360, 1456 (04 2005), 815–836
2005
-
[5]
epc: Fast and deep predictive coding for digital hardware, 2026
GOEMAERE, C., OLIVIERS, G., BOGACZ, R.,ANDDEMEESTER, T. epc: Fast and deep predictive coding for digital hardware, 2026
2026
-
[6]
H., KIM, H., SUNG, Y., JO, Y., KANG, M
HA, M. H., KIM, H., SUNG, Y., JO, Y., KANG, M. S.,ANDLEE, S. W. Stable and scalable deep predictive coding networks with meta-prediction errors. InThe Fourteenth International Conference on Learning Representations(2026)
2026
-
[7]
HAWKINS, J., LEADHOLM, N.,ANDCLAY, V. Hierarchy or heterarchy? a theory of long-range connections for the sensorimotor brain.arXiv preprint arXiv:2507.05888(2025)
-
[8]
Deep residual learning for image recognition
HE, K., ZHANG, X., REN, S.,ANDSUN, J. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition(2016), pp. 770–778
2016
-
[9]
M.,ANDBUCKLEY, C
INNOCENTI, F., ACHOUR, E. M.,ANDBUCKLEY, C. L. µPC: Scaling predictive coding to 100+ layer networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2025)
2025
-
[10]
P.,ANDBA, J
KINGMA, D. P.,ANDBA, J. Adam: A method for stochastic optimization. InICLR (Poster)(2015)
2015
-
[11]
MILLIDGE, B., TSCHANTZ, A.,ANDBUCKLEY, C. L. Predictive coding approximates backprop along arbitrary computation graphs.Neural Computation 34, 6 (05 2022), 1329–1368
2022
-
[12]
Direct feedback alignment provides learning in deep neural networks
NØKLAND, A. Direct feedback alignment provides learning in deep neural networks. InAdvances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain(2016), D. D. Lee, M. Sugiyama, U. von Luxburg, I. Guyon, and R. Garnett, Eds., pp. 1037–1045
2016
-
[13]
The neural coding framework for learning generative models.Nature Communications 13, 1 (Apr
ORORBIA, A.,ANDKIFER, D. The neural coding framework for learning generative models.Nature Communications 13, 1 (Apr. 2022)
2022
-
[14]
L.,ANDKIFER, D
ORORBIA, A., MALI, A., GILES, C. L.,ANDKIFER, D. Continual learning of recurrent neural networks by locally aligning distributed representations.IEEE transactions on neural networks and learning systems 31, 10 (2020), 4267–4278
2020
-
[15]
L.,ANDKIFER, D
ORORBIA, A., MALI, A., GILES, C. L.,ANDKIFER, D. Lifelong neural predictive coding: Learning cumulatively online without forgetting.Advances in Neural Information Processing Systems 35(2022), 5867–5881
2022
- [16]
-
[17]
G.,ANDMALI, A
ORORBIA, A. G.,ANDMALI, A. Biologically motivated algorithms for propagating local target representa- tions. InProceedings of the aaai conference on artificial intelligence(2019), vol. 33, pp. 4651–4658
2019
-
[18]
G., MALI, A., KIFER, D.,ANDGILES, C
ORORBIA, A. G., MALI, A., KIFER, D.,ANDGILES, C. L. Backpropagation-free deep learning with recursive local representation alignment.Proceedings of the AAAI Conference on Artificial Intelligence 37, 8 (2023), 9327–9335
2023
-
[19]
On the difficulty of training recurrent neural networks
PASCANU, R., MIKOLOV, T.,ANDBENGIO, Y. On the difficulty of training recurrent neural networks. In International conference on machine learning(2013), Pmlr, pp. 1310–1318
2013
-
[20]
The entangled brain.Journal of cognitive neuroscience 35, 3 (2023), 349–360
PESSOA, L. The entangled brain.Journal of cognitive neuroscience 35, 3 (2023), 349–360
2023
-
[21]
Faster predictive coding networks via better initialization, 2026
PINCHETTI, L., FRIEDER, S., LUKASIEWICZ, T.,ANDSALVATORI, T. Faster predictive coding networks via better initialization, 2026. 9 Preprint
2026
-
[22]
Towards the training of deeper predictive coding neural networks, 2025
QI, C., FORASASSI, M., LUKASIEWICZ, T.,ANDSALVATORI, T. Towards the training of deeper predictive coding neural networks, 2025
2025
-
[23]
RAO, R. P. N.,ANDBALLARD, D. H. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nature Neuroscience 2, 1 (1999), 79–87
1999
-
[24]
E., HINTON, G
RUMELHART, D. E., HINTON, G. E.,ANDWILLIAMS, R. J. Learning representations by back-propagating errors.nature 323, 6088 (1986), 533–536
1986
-
[25]
L., LUKASIEWICZ, T., RAO, R
SALVATORI, T., MALI, A., BUCKLEY, C. L., LUKASIEWICZ, T., RAO, R. P., FRISTON, K.,ANDORORBIA, A. A survey on neuro-mimetic deep learning via predictive coding.Neural Networks(2025), 108161
2025
-
[26]
A stable, fast, and fully automatic learning algorithm for predictive coding networks
SALVATORI, T., SONG, Y., YORDANOV, Y., MILLIDGE, B., SHA, L., EMDE, C., XU, Z., BOGACZ, R., ANDLUKASIEWICZ, T. A stable, fast, and fully automatic learning algorithm for predictive coding networks. InInternational Conference on Learning Representations(2024), vol. 2024, pp. 19607–19631
2024
-
[27]
Recurrent dynamics in the cerebral cortex: Integration of sensory evidence with stored knowledge.Proceedings of the National Academy of Sciences 118, 33 (2021), e2101043118
SINGER, W. Recurrent dynamics in the cerebral cortex: Integration of sensory evidence with stored knowledge.Proceedings of the National Academy of Sciences 118, 33 (2021), e2101043118
2021
-
[28]
SRIVASTAVA, R. K., GREFF, K.,ANDSCHMIDHUBER, J. Highway networks.arXiv preprint arXiv:1505.00387(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
WHITTINGTON, J. C. R.,ANDBOGACZ, R. An approximation of the error backpropagation algorithm in a predictive coding network with local hebbian synaptic plasticity.Neural Computation 29, 5 (05 2017), 1229–1262
2017
-
[30]
NeuroAI and Beyond: Bridging Between Advances in Neuroscience and ArtificialIntelligence
ZADOR, A., FELLOUS, J.-M., SEJNOWSKI, T., ADAM, G., AIMONE, J. B., AKWABOAH, A., ALOIMONOS, Y., ALONSO, C. A., BARTOLOZZI, C., BENNINGTON, M. J.,ET AL. Neuroai and beyond: Bridging between advances in neuroscience and artificialintelligence.arXiv preprint arXiv:2604.18637(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
G., SRIVASTAVA, R
ZILLY, J. G., SRIVASTAVA, R. K., KOUTNIK, J.,ANDSCHMIDHUBER, J. Recurrent highway networks. In International conference on machine learning(2017), PMLR, pp. 4189–4198. 10 Preprint A The Vanishing Learning Signal: Transient and Steady-State Derivations The analyses in this appendix consolidate two complementary results established by recent studies of dept...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.