Gated Multiple Feedback Network for Image Super-Resolution
Pith reviewed 2026-05-25 00:22 UTC · model grok-4.3
The pith
A network reroutes multiple high-level features back through gated modules to refine low-level features for image super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cascading multiple residual dense blocks and recurrently unfolding them across time steps, combined with multiple feedback connections between adjacent time steps and a gated feedback module, allows high-level features captured under large receptive fields to efficiently enrich low-level features that lack sufficient contextual information, leading to more accurate single-image super-resolution.
What carries the argument
The gated feedback module that selects and further enhances useful information from multiple rerouted high-level features before refining the low-level features.
If this is right
- The network outperforms state-of-the-art super-resolution methods on standard benchmarks in both quantitative metrics and visual quality.
- High-level features from large receptive fields can be reused to supply missing context to low-level features that would otherwise remain under-informed.
- Gated selection prevents irrelevant or noisy high-level information from degrading the low-level representation during refinement.
- Recurrent unfolding of the blocks enables the feedback paths to operate without requiring an entirely new architecture for each time step.
Where Pith is reading between the lines
- The same feedback-and-gating pattern could be tested on related tasks such as image denoising or deblurring where contextual enrichment is also needed.
- If the recurrent structure proves stable, it might allow variable numbers of unfoldings at inference time to trade compute for quality on different images.
- The gated module's selection logic could be inspected post-training to determine which high-level features are most frequently chosen for different image regions.
Load-bearing premise
The multiple feedback connections and gated selection will consistently enrich low-level features with useful high-level context without introducing training instability or artifacts during recurrent unfolding of the residual dense blocks.
What would settle it
Training the network without the feedback connections or gated module on the same datasets and observing no drop in PSNR, SSIM, or visual quality compared to the full model.
Figures














read the original abstract
The rapid development of deep learning (DL) has driven single image super-resolution (SR) into a new era. However, in most existing DL based image SR networks, the information flows are solely feedforward, and the high-level features cannot be fully explored. In this paper, we propose the gated multiple feedback network (GMFN) for accurate image SR, in which the representation of low-level features are efficiently enriched by rerouting multiple high-level features. We cascade multiple residual dense blocks (RDBs) and recurrently unfolds them across time. The multiple feedback connections between two adjacent time steps in the proposed GMFN exploits multiple high-level features captured under large receptive fields to refine the low-level features lacking enough contextual information. The elaborately designed gated feedback module (GFM) efficiently selects and further enhances useful information from multiple rerouted high-level features, and then refine the low-level features with the enhanced high-level information. Extensive experiments demonstrate the superiority of our proposed GMFN against state-of-the-art SR methods in terms of both quantitative metrics and visual quality. Code is available at https://github.com/liqilei/GMFN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Gated Multiple Feedback Network (GMFN) for single-image super-resolution. It cascades multiple residual dense blocks (RDBs) and recurrently unfolds them, using multiple feedback connections between adjacent time steps together with a gated feedback module (GFM) that selects and enhances high-level features to refine low-level representations. The central empirical claim is that GMFN outperforms prior state-of-the-art SR methods on standard quantitative metrics and visual quality, with code released at the cited GitHub repository.
Significance. If the reported gains are reproducible, the work shows that gated multi-scale feedback can usefully enrich low-level features with high-level context in recurrent SR architectures. The public code release is a clear strength that supports direct verification and extension.
minor comments (3)
- [§3.2] §3.2 and Fig. 3: the gating equations inside the GFM are described only in prose; adding an explicit equation for the selection weights would improve precision and ease of re-implementation.
- [Table 2] Table 2: the PSNR/SSIM entries for competing methods on Urban100 and Manga109 are given without standard deviations or number of runs; reporting variability would strengthen the superiority claim.
- [§4.3] §4.3: the ablation study removes the GFM but does not isolate the effect of the number of feedback connections; a more granular ablation would clarify which component drives the reported gains.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our Gated Multiple Feedback Network (GMFN) and for recommending minor revision. We appreciate the recognition of the gated multi-scale feedback mechanism and the value placed on the public code release.
Circularity Check
No significant circularity
full rationale
The paper proposes the GMFN architecture for single-image super-resolution by cascading and recurrently unfolding residual dense blocks with gated feedback modules. Its central claim is empirical superiority on quantitative metrics and visual quality versus prior SR methods, demonstrated via experiments on held-out test sets with released code. No derivation chain, mathematical prediction, or first-principles result is presented that reduces to its own inputs by construction; the design choices are architectural and validated externally rather than self-referential. No self-citation load-bearing steps, fitted parameters renamed as predictions, or ansatz smuggling appear in the performance claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Low-complexity single-image super-resolution based on nonnegative neighbor embed- ding
Marco Bevilacqua, Aline Roumy, Christine Guillemot, and Marie Line Alberi-Morel. Low-complexity single-image super-resolution based on nonnegative neighbor embed- ding. In BMVC, 2012
work page 2012
-
[2]
Human pose estimation with iterative error feedback
Joao Carreira, Pulkit Agrawal, Katerina Fragkiadaki, and Jitendra Malik. Human pose estimation with iterative error feedback. In CVPR, 2016
work page 2016
-
[3]
Learning a deep con- volutional network for image super-resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep con- volutional network for image super-resolution. In ECCV, 2014
work page 2014
-
[4]
Accelerating the super-resolution convolutional neural network
Chao Dong, Chen Change Loy, and Xiaoou Tang. Accelerating the super-resolution convolutional neural network. In ECCV, 2016
work page 2016
-
[5]
Image super-resolution via dual-state recurrent networks
Wei Han, Shiyu Chang, Ding Liu, Mo Yu, Michael Witbrock, and Thomas S Huang. Image super-resolution via dual-state recurrent networks. In CVPR, 2018
work page 2018
-
[6]
Deep back- projection networks for super-resolution
Muhammad Haris, Gregory Shakhnarovich, and Norimichi Ukita. Deep back- projection networks for super-resolution. In CVPR, 2018
work page 2018
-
[7]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015
work page 2015
-
[8]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016
work page 2016
-
[9]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018
work page 2018
-
[10]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In CVPR, 2017
work page 2017
-
[11]
Single image super-resolution from transformed self-exemplars
Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. In CVPR, 2015
work page 2015
-
[12]
Multi-path feedback recurrent neural networks for scene parsing
Xiaojie Jin, Yunpeng Chen, Zequn Jie, Jiashi Feng, and Shuicheng Yan. Multi-path feedback recurrent neural networks for scene parsing. In AAAI, 2017
work page 2017
-
[13]
Accurate image super-resolution using very deep convolutional networks
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, 2016
work page 2016
-
[14]
Deeply-recursive convolutional network for image super-resolution
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Deeply-recursive convolutional network for image super-resolution. In CVPR, 2016
work page 2016
-
[15]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2014
work page 2014
-
[16]
Photo-realistic single image super-resolution using a generative adversarial network
Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, 2017
work page 2017
-
[17]
Feed- back network for image super-resolution
Zhen Li, Jinglei Yang, Zheng Liu, Xiaomin Yang, Gwanggil Jeon, and Wei Wu. Feed- back network for image super-resolution. In CVPR, 2019. 12 LI, LI, LU, JEON, LIU, Y ANG: GMFN FOR IMAGE SUPER-RESOLUTION
work page 2019
-
[18]
Convolutional neural networks with intra- layer recurrent connections for scene labeling
Ming Liang, Xiaolin Hu, and Bo Zhang. Convolutional neural networks with intra- layer recurrent connections for scene labeling. In NeurIPS, 2015
work page 2015
-
[19]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. In CVPRW, 2017
work page 2017
-
[20]
Non-local recurrent network for image restoration
Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. In NeurIPS, 2018
work page 2018
-
[21]
David Martin, Charless Fowlkes, Doron Tal, Jitendra Malik, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In ICCV, 2001
work page 2001
-
[22]
Sketch-based manga retrieval using manga109 dataset
Yusuke Matsui, Kota Ito, Yuji Aramaki, Azuma Fujimoto, Toru Ogawa, Toshihiko Ya- masaki, and Kiyoharu Aizawa. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools and Applications, 2017
work page 2017
-
[23]
Recurrent convolutional neural networks for scene parsing
Ronan Collobert Pedro HO Pinherio and H Pedro. Recurrent convolutional neural networks for scene parsing. In ICML, 2014
work page 2014
-
[24]
Top-down feedback for crowd counting convolutional neural network
Deepak Babu Sam and R Venkatesh Babu. Top-down feedback for crowd counting convolutional neural network. In AAAI, 2018
work page 2018
-
[25]
Image super-resolution via deep recursive residual network
Ying Tai, Jian Yang, and Xiaoming Liu. Image super-resolution via deep recursive residual network. In CVPR, 2017
work page 2017
-
[26]
Image super-resolution using dense skip connections
Tong Tong, Gen Li, Xiejie Liu, and Qinquan Gao. Image super-resolution using dense skip connections. In ICCV, 2017
work page 2017
-
[27]
Esrgan: Enhanced super-resolution generative adversarial networks
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: Enhanced super-resolution generative adversarial networks. In ECCV, 2018
work page 2018
-
[28]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, Eero P Simoncelli, et al. Image quality assessment: from error visibility to structural similarity. TIP, 2004
work page 2004
-
[29]
Amir R Zamir, Te-Lin Wu, Lin Sun, William B Shen, Bertram E Shi, Jitendra Malik, and Silvio Savarese. Feedback networks. In CVPR, 2017
work page 2017
-
[30]
On single image scale-up using sparse-representations
Roman Zeyde, Michael Elad, and Matan Protter. On single image scale-up using sparse-representations. In Curves and Surfaces, 2010
work page 2010
-
[31]
Progressive attention guided recurrent network for salient object detection
Xiaoning Zhang, Tiantian Wang, Jinqing Qi, Huchuan Lu, and Gang Wang. Progressive attention guided recurrent network for salient object detection. In CVPR, 2018
work page 2018
-
[32]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. In ECCV, 2018
work page 2018
-
[33]
Residual dense network for image super-resolution
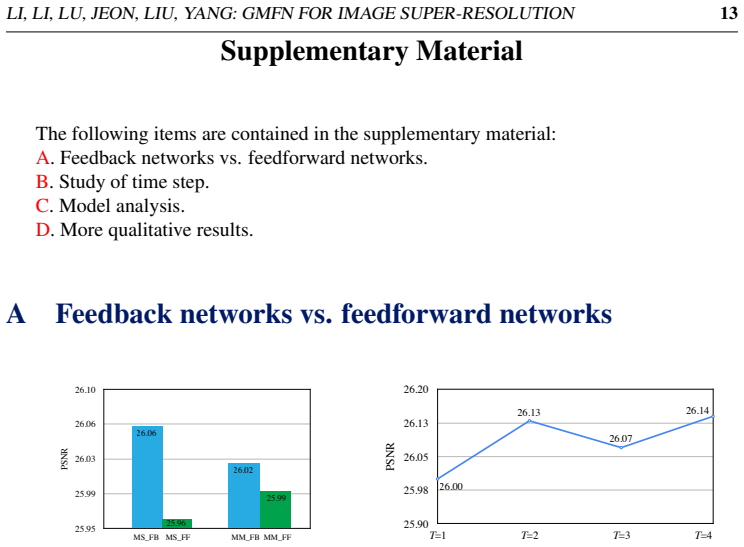
Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In CVPR, 2018. LI, LI, LU, JEON, LIU, Y ANG: GMFN FOR IMAGE SUPER-RESOLUTION 13 Supplementary Material The following items are contained in the supplementary material: A. Feedback networks vs. feedforward networks. B. Study of time step. C. Mode...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.