Neural Voxel Dynamics: Learning Implicit 3D Physics via Volumetric Feature Advection
Pith reviewed 2026-06-26 01:15 UTC · model grok-4.3
The pith
Lifting V-JEPA features into voxels and advecting them lets a model learn implicit 3D physics from video and actions alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
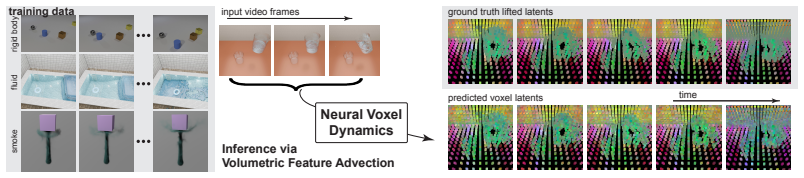
By shifting the predictive bottleneck into a lifted 3D Volumetric Latent Space, the architecture learns an action-conditioned Volumetric Feature Advection operator that treats physical evolution as spatio-temporal state advection; supervised end-to-end only with video-derived signals and action inputs, the resulting model exhibits long-term structural stability and physical plausibility across the CLEVERER, PhysInOne and PhysGaia benchmarks without any access to simulator internals, labels or surrogate models.
What carries the argument
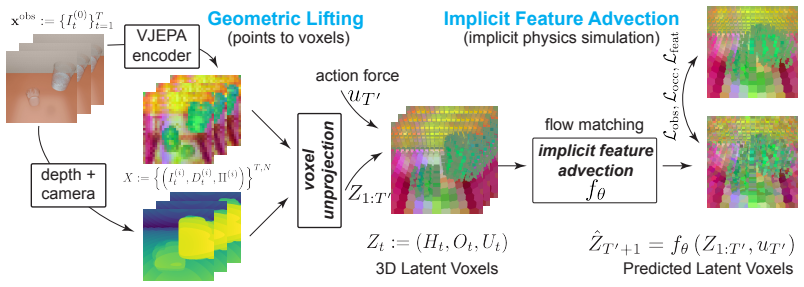
The Volumetric Feature Advection operator, which performs action-conditioned state transitions inside a voxel grid whose features are lifted from V-JEPA and anchored by monocular depth.
If this is right
- Heterogeneous phenomena such as rigid bodies moving inside fluid can be simulated inside a single unified network rather than separate simulators.
- Long-term rollouts preserve object permanence and structural integrity when driven only by video reconstruction loss plus action conditioning.
- The same pipeline produces plausible dynamics on multiple independent benchmarks without retraining or access to ground-truth physics states.
- Dynamic world models become feasible that internalize 3D physical rules solely through passive monocular observation.
Where Pith is reading between the lines
- The same lifting-plus-advection pattern could be tested on videos of deformable or breaking objects to check whether material properties emerge without explicit labels.
- If the voxel features already encode approximate conservation laws, the model might be queried for counterfactual actions that were never observed in the training videos.
- Connecting the learned operator to downstream planning would require checking whether its internal states remain consistent under novel camera viewpoints not present during training.
Load-bearing premise
Unprojecting V-JEPA features onto a depth-grounded voxel grid supplies enough 3D structure for the advection operator to discover the invariants of real physics.
What would settle it
Run the trained model on a held-out sequence containing an obvious physical violation such as two solid objects interpenetrating; if the predicted future frames continue to show interpenetration instead of collision response, the central claim is falsified.
Figures


read the original abstract
We present a self-supervised framework for learning implicit 3D physical dynamics directly from video-derived supervisory signals. While current generative video models achieve high visual fidelity, they lack a 3D geometric foundation, often resulting in physical inconsistencies and a failure to maintain object permanence. We address this by shifting the predictive bottleneck from 2D image space to a `lifted' 3D Volumetric Latent Space. Our method unprojects semantic features from a Video Joint-Embedding Predictive Architecture (V-JEPA) into a voxelized grid, grounded by monocular depth priors. This lifting enables a Volumetric Feature Advection to learn an action-conditioned transition operator that treats physics as a spatio-temporal state advection problem, i.e., learn implicit 3D physics. Unlike state-of-the-art hybrid models that rely on explicit classical simulators for training and/or inference, our architecture tracks material states implicitly within high-dimensional V-JEPA features. This allows for the emergent simulation of heterogeneous phenomena (e.g., rigid body motion in fluid flow) within a single, unified pipeline. Supervised solely via end-to-end video-derived signal plus action conditions, without access to physics engine internal states, labels, or surrogate models, our model demonstrates good long-term structural stability and physical plausibility on multiple benchmarks (CLEVERER, PhysInOne, PhysGaia). We believe that this work opens a scalable pathway toward general-purpose dynamic world models that internalize the 3D invariants of the physical world solely through passive observation of monocular videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Neural Voxel Dynamics, a self-supervised framework for learning implicit 3D physical dynamics from monocular video. It lifts semantic features from a pre-trained V-JEPA model into a voxelized volumetric latent space using monocular depth priors, then applies a Volumetric Feature Advection operator to learn an action-conditioned transition that models physics as spatio-temporal state advection. The approach claims to achieve long-term structural stability and physical plausibility on benchmarks including CLEVERER, PhysInOne, and PhysGaia, without access to physics engine states, labels, or surrogate models, and to handle heterogeneous phenomena in a unified pipeline.
Significance. If the central claims hold, the work would offer a scalable route to dynamic world models that internalize 3D physical invariants from passive video observation alone. Treating physics as implicit advection in a lifted volumetric feature space, rather than relying on explicit simulators, could address limitations in current generative video models regarding object permanence and physical consistency.
major comments (2)
- [Abstract] Abstract: The claim that the Volumetric Feature Advection operator learns 3D invariants of physics is load-bearing, yet the description provides no equations or architecture details showing how this operator is implemented or trained differently from the pre-trained V-JEPA features it depends on; without this, it is unclear whether the method reduces to re-using existing embeddings.
- [Abstract] Abstract: The unprojection of V-JEPA features into a voxel grid grounded by monocular depth priors is presented as enabling the 3D physics learning, but no analysis of depth estimation errors, voxel resolution choices, or how these affect the advection operator is given; this step is central to the weakest assumption and requires verification.
minor comments (1)
- [Abstract] Abstract: V-JEPA is introduced without expansion of the acronym on first use.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract. We address each major point below with clarifications drawn from the full manuscript and indicate planned revisions for improved clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the Volumetric Feature Advection operator learns 3D invariants of physics is load-bearing, yet the description provides no equations or architecture details showing how this operator is implemented or trained differently from the pre-trained V-JEPA features it depends on; without this, it is unclear whether the method reduces to re-using existing embeddings.
Authors: The abstract is a high-level summary. The full manuscript (Section 3) details the Volumetric Feature Advection as a 3D CNN transition operator with its own learned parameters, conditioned on action embeddings and trained end-to-end via a self-supervised feature-prediction objective on the voxel grid; the V-JEPA encoder remains frozen. This training distinguishes the operator from simple reuse of embeddings. We will revise the abstract to include a concise reference to the action-conditioned training objective. revision: yes
-
Referee: [Abstract] Abstract: The unprojection of V-JEPA features into a voxel grid grounded by monocular depth priors is presented as enabling the 3D physics learning, but no analysis of depth estimation errors, voxel resolution choices, or how these affect the advection operator is given; this step is central to the weakest assumption and requires verification.
Authors: We agree that the current manuscript lacks quantitative analysis of depth estimation errors or voxel resolution sensitivity. We will add an ablation study (new experiments subsection and/or supplementary material) evaluating performance under perturbed depth inputs and varying voxel grids to verify robustness of the lifting and advection steps. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and summary describe a pipeline that takes pre-trained V-JEPA semantic features as an external input, lifts them via monocular depth, and trains a new Volumetric Feature Advection operator end-to-end on video-derived signals. No equations, self-citations, or fitted parameters are shown that reduce the learned transition operator to quantities already defined by the inputs or by prior author work. The central claim of learning implicit 3D physics without physics-engine labels remains independent of the V-JEPA features themselves.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption V-JEPA features contain semantic information that can be meaningfully unprojected into 3D voxels
- domain assumption Monocular depth priors supply accurate enough 3D grounding for the voxel grid
invented entities (2)
-
Volumetric Latent Space
no independent evidence
-
Volumetric Feature Advection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture.arXiv preprint arXiv:2301.08243, April 2023. 10
arXiv 2023
-
[2]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xia...
Pith/arXiv arXiv 2025
-
[3]
P. W. Battaglia, J. B. Hamrick, and J. B. Tenenbaum. Simulation as an engine of physical scene un- derstanding.Proceedings of the National Academy of Sciences, 110(45):18327–18332, 2013. doi: 10.1073/pnas.1306572110
-
[4]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InICML, 2024
2024
-
[5]
PhysGen3D: Crafting a Miniature Interactive World from a Single Image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. PhysGen3D: Crafting a Miniature Interactive World from a Single Image. InProc. CVPR, pages 6178–6189. IEEE, June 2025
2025
-
[6]
Video depth anything: Consistent depth estimation for super-long videos.arXiv:2501.12375, 2025
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos.arXiv:2501.12375, 2025
arXiv 2025
-
[7]
Pybullet, a python module for physics simulation for games, robotics and machine learning.http://pybullet.org, 2016
Erwin Coumans and Yunfei Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning.http://pybullet.org, 2016. Accessed: 2026-04-08
2016
-
[8]
Chen, and Frédo Durand
Abe Davis, Justin G. Chen, and Frédo Durand. Image-space modal bases for plausible manipulation of objects in video.ACM TOG, 34(6):1–7, November 2015
2015
-
[9]
Katrina Drozdov, Ravid Shwartz-Ziv, and Yann LeCun. Video Representation Learning with Joint- Embedding Predictive Architectures.arXiv preprint arXiv:2412.10925, December 2024
arXiv 2024
-
[10]
Relate: Physically plausible multi-object scene synthesis using structured latent spaces
Sébastien Ehrhardt, Oliver Groth, Aron Monszpart, Martin Engelcke, Ingmar Posner, Niloy Mitra, and Andrea Vedaldi. Relate: Physically plausible multi-object scene synthesis using structured latent spaces. Proc. NeurIPS, 33:11202–11213, 2020
2020
-
[11]
Dave Epstein, Taesung Park, Richard Zhang, Eli Shechtman, and Alexei A. Efros. BlobGAN: Spatially Dis- entangled Scene Representations. InECCV, volume 13675, pages 616–635. Springer Nature Switzerland, 2022
2022
-
[12]
Physical Simulator In-the-Loop Video Generation.arXiv preprint arXiv:2603.06408, March 2026
Lin Geng Foo, Mark He Huang, Alexandros Lattas, Stylianos Moschoglou, Thabo Beeler, and Christian Theobalt. Physical Simulator In-the-Loop Video Generation.arXiv preprint arXiv:2603.06408, March 2026
arXiv 2026
-
[13]
Xiao Fu, Xian Liu, Xintao Wang, Sida Peng, Menghan Xia, Xiaoyu Shi, Ziyang Yuan, Pengfei Wan, Di Zhang, and Dahua Lin. 3Dtrajmaster: Mastering 3D trajectory for multi-entity motion in video generation.arXiv preprint arXiv:2412.07759, 2024
arXiv 2024
-
[14]
Quentin Garrido, Nicolas Ballas, Mahmoud Assran, Adrien Bardes, Laurent Najman, Michael Rabbat, Emmanuel Dupoux, and Yann LeCun. Intuitive physics understanding emerges from self-supervised pretraining on natural videos.arXiv preprint arXiv:2502.11831, February 2025
arXiv 2025
-
[15]
Motion Prompting: Controlling Video Generation with Motion Trajectories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez- Guevara, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun. Motion Prompting: Controlling Video Generation with Motion Trajectories. InProc. CVPR, pages 1–12. IEEE, June 2025
2025
-
[16]
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals. arXiv preprint arXiv:2505.19386, May 2025
arXiv 2025
-
[17]
Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, and Yuan Liu. Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control. InACM SIGGRAPH, pages 1–12. ACM, August 2025
2025
-
[18]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
Pith/arXiv arXiv 2024
-
[19]
Denoising Diffusion Probabilistic Models.arXiv preprint arXiv:2006.11239, December 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models.arXiv preprint arXiv:2006.11239, December 2020. 11
Pith/arXiv arXiv 2006
-
[20]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video Diffusion Models.Proc. NeurIPS, 35, June 2022
2022
-
[21]
Naiwen Hu, Haozhe Cheng, Yifan Xie, Shiqi Li, and Jihua Zhu. 3D-JEPA: A Joint Embedding Predictive Architecture for 3D Self-Supervised Representation Learning.arXiv preprint arXiv:2409.15803, September 2024
arXiv 2024
-
[22]
The material point method for simulating continuum materials
Chenfanfu Jiang, Craig Schroeder, Joseph Teran, Alexey Stomakhin, and Andrew Selle. The material point method for simulating continuum materials. InACM SIGGRAPH Courses, pages 1–52, Anaheim California, July 2016. ACM
2016
-
[23]
Physgaia:physics-aware benchmark with multi-body interactions for dynamic novel view synthesis
Mijeong Kim, Gunhee Kim, Jungyoon Choi, Wonjae Roh, and Bohyung Han. Physgaia:physics-aware benchmark with multi-body interactions for dynamic novel view synthesis. InProc. CVPR, 2026
2026
-
[24]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In ECCV, pages 71–91. Springer, 2024
2024
-
[25]
WonderPlay: Dynamic 3D Scene Generation from a Single Image and Actions
Zizhang Li, Hong-Xing Yu, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, and Jiajun Wu. WonderPlay: Dynamic 3D Scene Generation from a Single Image and Actions. InICCV, pages 9080–9090. arXiv, May 2025
2025
-
[26]
Phys4dgen: Physics- compliant 4d generation with multi-material composition perception
Jiajing Lin, Zhenzhong Wang, Dejun Xu, Shu Jiang, Yunpeng Gong, and Min Jiang. Phys4dgen: Physics- compliant 4d generation with multi-material composition perception. InACM MM, pages 10398–10407, 2025
2025
-
[27]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InICCV, pages 2980–2988, 2017
2017
-
[28]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[29]
Fangfu Liu, Hanyang Wang, Shunyu Yao, Shengjun Zhang, Jie Zhou, and Yueqi Duan. Physics3D: Learning Physical Properties of 3D Gaussians via Video Diffusion.arXiv preprint arXiv:2406.04338, June 2024
arXiv 2024
-
[30]
PhysGen: Rigid-Body Physics- Grounded Image-to-Video Generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. PhysGen: Rigid-Body Physics- Grounded Image-to-Video Generation. InECCV, volume 15140, pages 360–378. Springer Nature Switzer- land, 2025
2025
-
[31]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels.arXiv preprint arXiv:2603.19312, March 2026
Pith/arXiv arXiv 2026
-
[32]
M. McCloskey, A. Washburn, and L. Felch. Intuitive physics: the straight-down belief and its origin. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9(4):636–649, Oct 1983. doi: 10.1037//0278-7393.9.4.636
-
[33]
Nerf: Representing scenes as neural radiance fields for view synthesis.CACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.CACM, 65(1):99–106, 2021
2021
-
[34]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-JEPA 2.1: Unlocking Dense Features in Video Self- Supervised Learning.arXiv preprint arXiv:2603.14482, March 2026
Pith/arXiv arXiv 2026
-
[35]
Blockgan: Learning 3d object-aware scene representations from unlabelled images.Proc
Thu H Nguyen-Phuoc, Christian Richardt, Long Mai, Yongliang Yang, and Niloy Mitra. Blockgan: Learning 3d object-aware scene representations from unlabelled images.Proc. NeurIPS, 33:6767–6778, 2020
2020
-
[36]
Gen3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control. InProc. CVPR, pages 6121–6132. IEEE, June 2025
2025
-
[37]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. InProc. CVPR, pages 10674–10685. IEEE, June 2022
2022
-
[38]
Remy Sabathier, David Novotny, Niloy J. Mitra, and Tom Monnier. ActionMesh: Animated 3D Mesh Generation with Temporal 3D Diffusion.arXiv preprint arXiv:2601.16148, April 2026. 12
arXiv 2026
-
[39]
Ying Shen, Jerry Xiong, Tianjiao Yu, and Ismini Lourentzou. Phantom: Physics-Infused Video Generation via Joint Modeling of Visual and Latent Physical Dynamics.arXiv preprint arXiv:2604.08503, April 2026
Pith/arXiv arXiv 2026
-
[40]
Mingzhi Sheng, Zekai Gu, Peng Li, Cheng Lin, Hao-Xiang Guo, Ying-Cong Chen, and Yuan Liu. FlexAM: Flexible Appearance-Motion Decomposition for Versatile Video Generation Control.arXiv prerpint arXiv:2602.13185, February 2026
arXiv 2026
-
[41]
Denoising Diffusion Implicit Models.arXiv prerpint arXiv:2010.02502, October 2022
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising Diffusion Implicit Models.arXiv prerpint arXiv:2010.02502, October 2022
Pith/arXiv arXiv 2010
-
[42]
A material point method for snow simulation.ACM TOG, 32(4):1–10, 2013
Alexey Stomakhin, Craig Schroeder, Lawrence Chai, Joseph Teran, and Andrew Selle. A material point method for snow simulation.ACM TOG, 32(4):1–10, 2013
2013
-
[43]
Xiyang Tan, Ying Jiang, Xuan Li, Zeshun Zong, Tianyi Xie, Yin Yang, and Chenfanfu Jiang. PhysMotion: Physics-Grounded Dynamics From a Single Image.arXiv preprint arXiv:2411.17189, November 2024
arXiv 2024
-
[44]
LGM: Large Multi-view Gaussian Model for High-Resolution 3D Content Creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. LGM: Large Multi-view Gaussian Model for High-Resolution 3D Content Creation. InECCV, volume 15062, pages 1–18. Springer Nature Switzerland, February 2024
2024
-
[45]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In IROS, pages 5026–5033. IEEE, 2012
2012
-
[46]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. PhysC- trl: Generative Physics for Controllable and Physics-Grounded Video Generation.arXiv preprint arXiv:2509.20358, November 2025
arXiv 2025
-
[47]
VGGT: Visual Geometry Grounded Transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual Geometry Grounded Transformer. InProc. CVPR, pages 5294–5306. IEEE, June 2025
2025
-
[48]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProc. CVPR, pages 5261–5271, 2025
2025
-
[49]
Learning to solve pdes on neural shape representations.arXiv preprint arXiv:2512.21311, 2025
Lilian Welschinger, Yilin Liu, Zican Wang, and Niloy Mitra. Learning to solve pdes on neural shape representations.arXiv preprint arXiv:2512.21311, 2025
Pith/arXiv arXiv 2025
-
[50]
PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics. InProc. CVPR, pages 4389–4398. IEEE, June 2024
2024
-
[51]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[52]
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019
Pith/arXiv arXiv 1910
-
[53]
Jiahao Zhan, Zizhang Li, Hong-Xing Yu, and Jiajun Wu. PerpetualWonder: Long-Horizon Action- Conditioned 4D Scene Generation.arXiv preprint arXiv:2602.04876, February 2026
Pith/arXiv arXiv 2026
-
[54]
Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y . Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T. Freeman. PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation. InECCV, volume 15060, pages 388–406. Springer Nature Switzerland, 2025
2025
-
[55]
Reconstruction and Simulation of Elastic Objects with Spring-Mass 3D Gaussians
Licheng Zhong, Hong-Xing Yu, Jiajun Wu, and Yunzhu Li. Reconstruction and Simulation of Elastic Objects with Spring-Mass 3D Gaussians. InECCV, volume 15060, pages 407–423. Springer Nature Switzerland, July 2024
2024
-
[56]
Physinone: Visual physics learning and reasoning in one suite
Siyuan Zhou, Hejun Wang, Hu Cheng, et al. Physinone: Visual physics learning and reasoning in one suite. InProc. CVPR, 2026
2026
-
[57]
Limitations
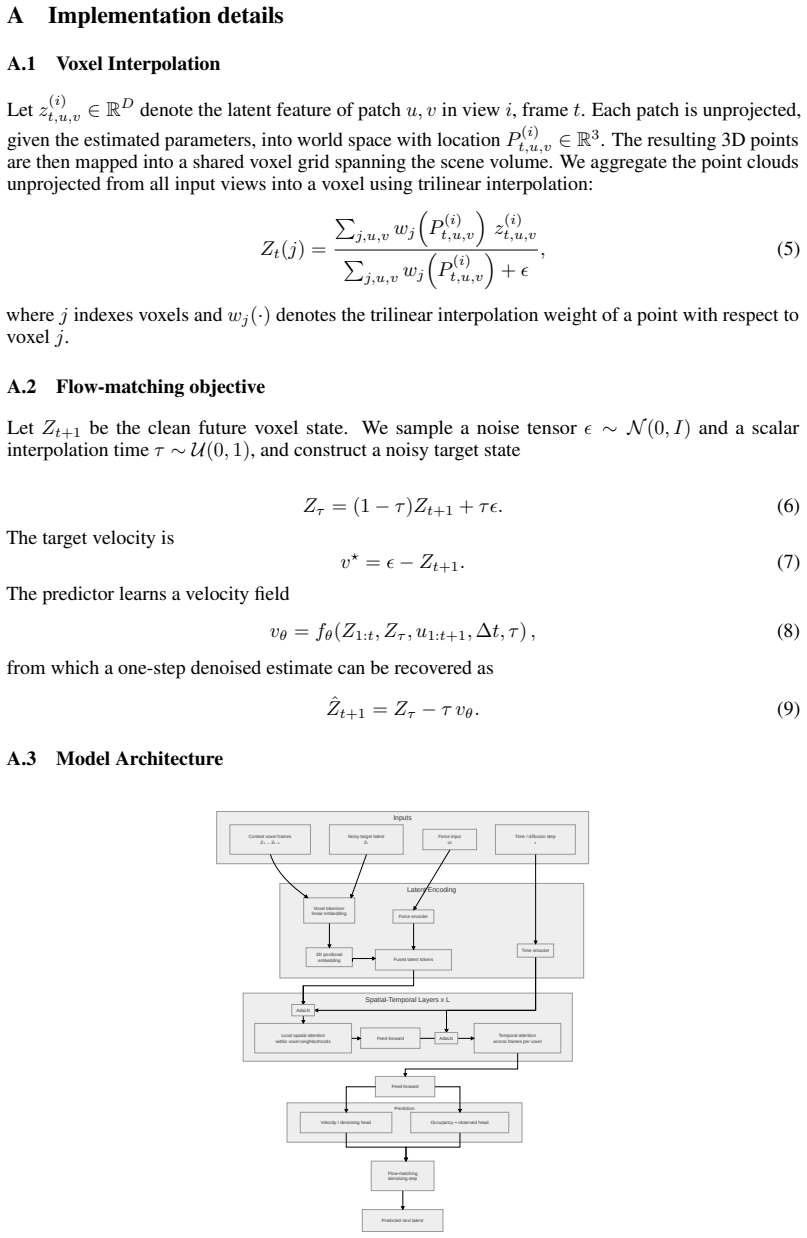
Zeshun Zong, Xuan Li, Minchen Li, Maurizio M. Chiaramonte, Wojciech Matusik, Eitan Grinspun, Kevin Carlberg, Chenfanfu Jiang, and Peter Yichen Chen. Neural stress fields for reduced-order elastoplasticity and fracture. InSIGGRAPH Asia Conference. Association for Computing Machinery, 2023. 13 A Implementation details A.1 Voxel Interpolation Let z(i) t,u,v ...
2023
-
[58]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.