The Warrant Gap: Claim-Conditioned Re-scoring for Fact-Checking
Pith reviewed 2026-06-25 23:40 UTC · model grok-4.3
The pith
Claim-conditioned re-scoring of evidence recovers accuracy lost in structured fact-checking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
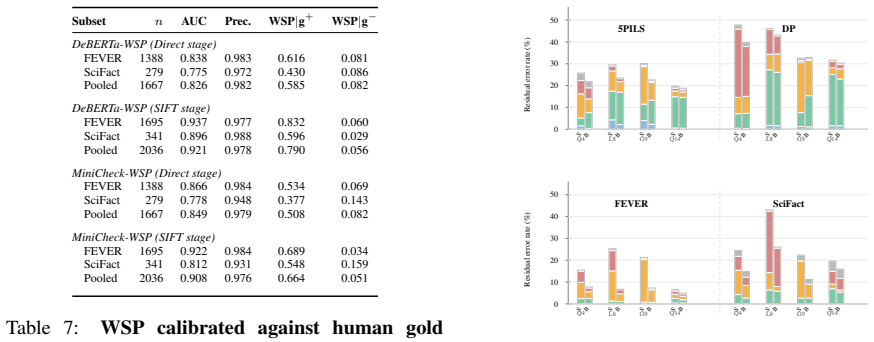
SIFT recovers accuracy on cells where naive decomposition costs up to 27.6 points, while raising WSP above direct prompting; WSP itself calibrates against human gold evidence at AUC 0.92 and precision 0.98.
What carries the argument
SIFT, claim-conditioned re-scoring of extracted evidence spans against the full claim, paired with WSP, an automatic NLI check that the cited warrant entails the claim.
If this is right
- Structured decomposition protocols can preserve full-claim context through targeted re-scoring without sacrificing inspection of individual warrants.
- WSP offers an automatic, high-precision substitute for human review of whether cited evidence supports a claim.
- Performance improvements from SIFT hold across multiple fact-checking benchmarks and different open-source LLM backbones.
- Direct prompting yields lower warrant quality than the re-scoring approach on the same models and datasets.
Where Pith is reading between the lines
- Similar conditioning on the original claim could reduce grounding failures in other LLM tasks that rely on step-by-step decomposition.
- Evidence extraction pipelines may benefit from always retaining the full claim as context rather than discarding it after initial parsing.
- The approach suggests a general pattern for closing warrant gaps in any system that breaks complex claims into sub-questions.
Load-bearing premise
The NLI model used to compute WSP provides a faithful proxy for whether extracted evidence actually entails the full claim, and that performance on the chosen benchmarks generalizes to real-world fact-checking distributions.
What would settle it
A new human evaluation set of evidence-claim pairs where WSP scores show low correlation with entailment judgments, or a decomposition-based fact-checking task where SIFT fails to recover the reported accuracy gains.
Figures


read the original abstract
Fact-checking systems built on LLMs achieve high verdict accuracy on standard benchmarks, yet routinely output Supports labels whose cited evidence does not license the claim. Structured decomposition is the natural way to inspect those warrants, but rigid extraction protocols strip the full-claim context that facets need. We introduce SIFT -- claim-conditioned re-scoring of extracted evidence spans against the full claim -- paired with WSP (Warranted Supports Proportion), an automatic NLI check that the cited warrant entails the claim. We evaluate on FEVER, SciFact, 5PILS, and DP across four open-source backbones. SIFT recovers accuracy on cells where naive decomposition costs up to 27.6 points, while raising WSP above direct prompting; WSP itself calibrates against human gold evidence at AUC 0.92 and precision 0.98.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based fact-checking systems suffer from a 'warrant gap' in which cited evidence spans fail to entail the full claim. It introduces SIFT (claim-conditioned re-scoring of extracted spans) paired with WSP (Warranted Supports Proportion), an automatic NLI-based check that the warrant entails the claim. On FEVER, SciFact, 5PILS and DP with four open-source backbones, SIFT recovers up to 27.6 accuracy points lost under naive decomposition while raising WSP above direct prompting; WSP itself is reported to calibrate against human gold at AUC 0.92 and precision 0.98.
Significance. If the central results hold, the work supplies a practical mechanism for closing the warrant gap and an automatic metric that could reduce reliance on human evidence annotation. The multi-benchmark, multi-backbone evaluation is a positive feature.
major comments (2)
- [Abstract and §4] Abstract and evaluation sections: the reported accuracy recovery (up to 27.6 points) and WSP improvements are presented without ablation studies, error analysis, or per-backbone breakdowns. It is therefore impossible to determine whether the gains are attributable to the claim-conditioned re-scoring itself or to other experimental choices.
- [WSP definition] WSP definition and calibration paragraph: the claim that WSP provides a faithful proxy for full-claim entailment rests on an NLI model whose architecture, training regime, and exposure to the target claim distributions are not described. Although aggregate calibration (AUC 0.92, precision 0.98) against human gold is stated, no analysis is given of whether NLI errors correlate with the warrant-gap cases the method targets.
minor comments (1)
- The four open-source backbones are referenced but not named in the abstract or evaluation summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and evaluation sections: the reported accuracy recovery (up to 27.6 points) and WSP improvements are presented without ablation studies, error analysis, or per-backbone breakdowns. It is therefore impossible to determine whether the gains are attributable to the claim-conditioned re-scoring itself or to other experimental choices.
Authors: We agree that the current presentation reports aggregate results across backbones without isolating the contribution of SIFT via ablations or providing per-backbone breakdowns and error analysis. In the revised manuscript we will expand §4 with (i) an ablation removing the claim-conditioned re-scoring step, (ii) per-backbone accuracy and WSP tables, and (iii) a qualitative error analysis of cases where SIFT recovers or fails to recover accuracy. These additions will make the source of the reported gains transparent. revision: yes
-
Referee: [WSP definition] WSP definition and calibration paragraph: the claim that WSP provides a faithful proxy for full-claim entailment rests on an NLI model whose architecture, training regime, and exposure to the target claim distributions are not described. Although aggregate calibration (AUC 0.92, precision 0.98) against human gold is stated, no analysis is given of whether NLI errors correlate with the warrant-gap cases the method targets.
Authors: We acknowledge that the NLI model underlying WSP is not fully specified and that no error-correlation analysis is provided. In the revision we will add a dedicated paragraph describing the NLI model (architecture, training data, and any overlap with the evaluation claim distributions) together with a breakdown of NLI errors on the human-gold subset, explicitly checking whether misclassifications align with warrant-gap instances. This will strengthen the justification for using WSP as a proxy. revision: yes
Circularity Check
No circularity: claims rest on external benchmarks and human gold labels
full rationale
The provided abstract and context describe SIFT and WSP evaluated on FEVER, SciFact, 5PILS, and DP benchmarks, with WSP calibrated directly against human gold evidence (AUC 0.92, precision 0.98). No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the text. The central results are presented as empirical outcomes on independent test sets rather than reductions to the method's own inputs or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NLI models reliably detect entailment between evidence spans and full claims
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[4]
Psychometrika , volume=
Note on the sampling error of the difference between correlated proportions or percentages , author=. Psychometrika , volume=. 1947 , publisher=
1947
-
[5]
Journal of the Royal statistical society: series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal statistical society: series B (Methodological) , volume=. 1995 , publisher=
1995
-
[7]
Spearman , journal =
C. Spearman , journal =. The Proof and Measurement of Association between Two Things , urldate =
-
[8]
Mathematical contributions to the theory of evolution.—VII
I. Mathematical contributions to the theory of evolution.—VII. On the correlation of characters not quantitatively measurable , author=. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character , volume=. 1900 , publisher=
1900
-
[9]
Towards Debiasing Fact Verification Models
Schuster, Tal and Shah, Darsh and Yeo, Yun Jie Serene and Roberto Filizzola Ortiz, Daniel and Santus, Enrico and Barzilay, Regina. Towards Debiasing Fact Verification Models. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019....
-
[16]
arXiv preprint arXiv:2311.01453 , year=
Ppi++: Efficient prediction-powered inference , author=. arXiv preprint arXiv:2311.01453 , year=
-
[26]
2026 , eprint=
Debating the Unspoken: Role-Anchored Multi-Agent Reasoning for Half-Truth Detection , author=. 2026 , eprint=
2026
-
[27]
Advances in Neural Information Processing Systems , volume=
Averitec: A dataset for real-world claim verification with evidence from the web , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the Fifth Workshop on Scholarly Document Processing (SDP 2025) , pages=
From RAG to Reality: Coarse-Grained Hallucination Detection via NLI Fine-Tuning , author=. Proceedings of the Fifth Workshop on Scholarly Document Processing (SDP 2025) , pages=
2025
-
[29]
arXiv preprint arXiv:2506.13342 , year=
Verifying the verifiers: Unveiling pitfalls and potentials in fact verifiers , author=. arXiv preprint arXiv:2506.13342 , year=
-
[30]
Towards Understanding Sycophancy in Language Models , url =
Sharma, Mrinank and Tong, Meg and Korbak, Tomek and Duvenaud, David and Askell, Amanda and Bowman, Sam and DURMUS, Esin and Hatfield-Dodds, Zac and Johnston, Scott and Kravec, Shauna and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and Yan, Da and Zhang, Miranda and Perez, Ethan , booktitle =. Towards U...
-
[34]
2003 , publisher=
The uses of argument , author=. 2003 , publisher=
2003
-
[36]
, title =
Wei, Jerry and Yang, Chengrun and Song, Xinying and Lu, Yifeng and Hu, Nathan and Huang, Jie and Tran, Dustin and Peng, Daiyi and Liu, Ruibo and Huang, Da and Du, Cosmo and Le, Quoc V. , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[37]
Fact-Checking With Contextual Narratives: Leveraging Retrieval-Augmented LLMs for Social Media Analysis , year=
Dey, Arka Ujjal and Awan, Muhammad Junaid and Channing, Georgia and Witt, Christian Schroeder de and Collomosse, John , journal=. Fact-Checking With Contextual Narratives: Leveraging Retrieval-Augmented LLMs for Social Media Analysis , year=
-
[38]
IEEE Transactions on Artificial Intelligence , year=
TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking , author=. IEEE Transactions on Artificial Intelligence , year=
-
[39]
Findings of the Association for Computational Linguistics: EMNLP 2025 , year=
GraphCheck: Multipath Fact-Checking with Entity-Relationship Graphs , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , year=
2025
-
[40]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Fact Verification on Knowledge Graph via Programmatic Graph Reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[41]
IEEE Transactions on Computational Social Systems , year=
AMIR: An Automated Misinformation Rebuttal System--A COVID-19 Vaccination Datasets-Based Exposition , author=. IEEE Transactions on Computational Social Systems , year=
-
[42]
IEEE Transactions on Computational Social Systems , year=
Believe in artificial intelligence? A user study on the ChatGPT’s fake information impact , author=. IEEE Transactions on Computational Social Systems , year=
-
[43]
IEEE Transactions on Computational Social Systems , volume=
Integrating social explanations into explainable artificial intelligence (XAI) for combating misinformation: Vision and challenges , author=. IEEE Transactions on Computational Social Systems , volume=. 2024 , publisher=
2024
-
[44]
IEEE Transactions on Computational Social Systems , volume=
Detecting and mitigating the dissemination of fake news: Challenges and future research opportunities , author=. IEEE Transactions on Computational Social Systems , volume=. 2022 , publisher=
2022
-
[45]
science , volume=
The spread of true and false news online , author=. science , volume=. 2018 , publisher=
2018
-
[46]
fake news
The economics of “fake news” , author=. IT Professional , volume=. 2017 , publisher=
2017
-
[47]
Journal of economic perspectives , volume=
Social media and fake news in the 2016 election , author=. Journal of economic perspectives , volume=. 2017 , publisher=
2016
-
[48]
Communications of the ACM , volume=
Wikidata: a free collaborative knowledgebase , author=. Communications of the ACM , volume=. 2014 , publisher=
2014
-
[49]
arXiv preprint arXiv:2305.14292 , year=
WikiChat: Stopping the hallucination of large language model chatbots by few-shot grounding on Wikipedia , author=. arXiv preprint arXiv:2305.14292 , year=
-
[50]
arXiv preprint arXiv:2010.03743 , year=
Visual news: Benchmark and challenges in news image captioning , author=. arXiv preprint arXiv:2010.03743 , year=
arXiv 2010
-
[51]
AIMS public health , volume=
The impact of misinformation on the COVID-19 pandemic , author=. AIMS public health , volume=
-
[52]
Social Network Analysis and Mining , volume=
Fake news, disinformation and misinformation in social media: a review , author=. Social Network Analysis and Mining , volume=. 2023 , publisher=
2023
-
[53]
arXiv preprint arXiv:2410.23850 , year=
The automated verification of textual claims (averitec) shared task , author=. arXiv preprint arXiv:2410.23850 , year=
-
[54]
Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER) , pages=
RAG-Fusion Based Information Retrieval for Fact-Checking , author=. Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER) , pages=
-
[55]
arXiv preprint arXiv:2503.22877 , year=
Understanding Inequality of LLM Fact-Checking over Geographic Regions with Agent and Retrieval models , author=. arXiv preprint arXiv:2503.22877 , year=
-
[56]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[57]
Transactions of the Association for Computational Linguistics , volume=
Justilm: Few-shot justification generation for explainable fact-checking of real-world claims , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[58]
arXiv preprint arXiv:2501.11403 , year=
Verifying cross-modal entity consistency in news using vision-language models , author=. arXiv preprint arXiv:2501.11403 , year=
-
[59]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sniffer: Multimodal large language model for explainable out-of-context misinformation detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[60]
The library quarterly , volume=
Posttruth, truthiness, and alternative facts: Information behavior and critical information consumption for a new age , author=. The library quarterly , volume=. 2017 , publisher=
2017
-
[61]
Political communication , volume=
A picture paints a thousand lies? The effects and mechanisms of multimodal disinformation and rebuttals disseminated via social media , author=. Political communication , volume=. 2020 , publisher=
2020
-
[62]
arXiv preprint arXiv:2502.00752 , year=
Zero-Shot Warning Generation for Misinformative Multimodal Content , author=. arXiv preprint arXiv:2502.00752 , year=
-
[63]
arXiv preprint arXiv:2104.05893 , year=
Newsclippings: Automatic generation of out-of-context multimodal media , author=. arXiv preprint arXiv:2104.05893 , year=
-
[64]
2023 , eprint=
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , author=. 2023 , eprint=
2023
-
[65]
Journal of computational and applied mathematics , volume=
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author=. Journal of computational and applied mathematics , volume=. 1987 , publisher=
1987
-
[66]
IEEE transactions on pattern analysis and machine intelligence , number=
A cluster separation measure , author=. IEEE transactions on pattern analysis and machine intelligence , number=. 1979 , publisher=
1979
-
[67]
uncheckable: How opinion-based claims can impede corrections of misinformation , author=
Unchecked vs. uncheckable: How opinion-based claims can impede corrections of misinformation , author=. Mass communication and society , volume=. 2021 , publisher=
2021
-
[68]
2024 , eprint=
Improved Baselines with Visual Instruction Tuning , author=. 2024 , eprint=
2024
-
[69]
2023 , eprint=
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[70]
arXiv preprint arXiv:2111.09543 , year=
Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing , author=. arXiv preprint arXiv:2111.09543 , year=
-
[71]
IEEE signal processing letters , volume=
Joint face detection and alignment using multitask cascaded convolutional networks , author=. IEEE signal processing letters , volume=. 2016 , publisher=
2016
-
[72]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[73]
CVPR , year=
Facenet: A unified embedding for face recognition and clustering , author=. CVPR , year=
-
[74]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Places: A 10 million Image Database for Scene Recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[75]
arXiv preprint arXiv:2402.06782 , year=
Debating with more persuasive llms leads to more truthful answers , author=. arXiv preprint arXiv:2402.06782 , year=
-
[76]
arXiv preprint arXiv:2411.06116 , year=
Supernotes: Driving Consensus in Crowd-Sourced Fact-Checking , author=. arXiv preprint arXiv:2411.06116 , year=
-
[77]
International Journal of Multimedia Information Retrieval , volume=
Verite: a robust benchmark for multimodal misinformation detection accounting for unimodal bias , author=. International Journal of Multimedia Information Retrieval , volume=. 2024 , publisher=
2024
-
[78]
, title =
Urbani, S. , title =. Essential Guides , year =
-
[79]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[80]
arXiv preprint arXiv:2404.10702 , year=
Retrieval Augmented Verification for Zero-Shot Detection of Multimodal Disinformation , author=. arXiv preprint arXiv:2404.10702 , year=
-
[81]
2024 , eprint=
RED-DOT: Multimodal Fact-checking via Relevant Evidence Detection , author=. 2024 , eprint=
2024
-
[82]
2025 , eprint=
DEFAME: Dynamic Evidence-based FAct-checking with Multimodal Experts , author=. 2025 , eprint=
2025
-
[83]
arXiv preprint arXiv:2406.08772 , year=
Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms , author=. arXiv preprint arXiv:2406.08772 , year=
-
[84]
arXiv preprint arXiv:2407.13488 , year=
Similarity over Factuality: Are we making progress on multimodal out-of-context misinformation detection? , author=. arXiv preprint arXiv:2407.13488 , year=
-
[86]
Reuters Institute for the Study of Journalism , year=
Understanding the promise and limits of automated fact-checking , author=. Reuters Institute for the Study of Journalism , year=
-
[87]
Fact-checking
“Fact-checking” fact checkers: A data-driven approach , author=. Harvard Kennedy School Misinformation Review , year=
-
[88]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Detecting and grounding multi-modal media manipulation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[89]
2025 , eprint=
LLM-Consensus: Multi-Agent Debate for Visual Misinformation Detection , author=. 2025 , eprint=
2025
-
[90]
arXiv preprint arXiv:2101.06278 , year=
Cosmos: Catching out-of-context misinformation with self-supervised learning , author=. arXiv preprint arXiv:2101.06278 , year=
-
[91]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Open-domain, content-based, multi-modal fact-checking of out-of-context images via online resources , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[93]
2025 , publisher=
Journalism, media, and technology trends and predictions 2025 , author=. 2025 , publisher=
2025
-
[94]
PNAS nexus , volume=
Unveiling the hidden agenda: Biases in news reporting and consumption , author=. PNAS nexus , volume=. 2024 , publisher=
2024
-
[95]
Proceedings of the ACM on Human-Computer Interaction , volume=
Did the Roll-Out of Community Notes Reduce Engagement With Misinformation on X/Twitter? , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2024 , publisher=
2024
-
[96]
arXiv preprint arXiv:2502.14132 , year=
Can Community Notes Replace Professional Fact-Checkers? , author=. arXiv preprint arXiv:2502.14132 , year=
-
[97]
Sahar Abdelnabi, Rakibul Hasan, and Mario Fritz. 2022. Open-domain, content-based, multi-modal fact-checking of out-of-context images via online resources. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14940--14949
2022
-
[98]
Mubashara Akhtar, Michael Schlichtkrull, and Andreas Vlachos. 2026. https://doi.org/10.1162/TACL.a.647 Ev2r: Evaluating evidence retrieval in automated fact-checking . Transactions of the Association for Computational Linguistics, 14:530--561
-
[99]
Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. 2023. Ppi++: Efficient prediction-powered inference
2023
-
[100]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological), 57(1):289--300
1995
-
[101]
Eunsol Choi, Jennimaria Palomaki, Matthew Lamm, Tom Kwiatkowski, Dipanjan Das, and Michael Collins. 2021. https://doi.org/10.1162/tacl_a_00377 Decontextualization: Making sentences stand-alone . Transactions of the Association for Computational Linguistics, 9:447--461
-
[102]
Arka Ujjal Dey, Muhammad Junaid Awan, Georgia Channing, Christian Schroeder de Witt, and John Collomosse. 2026. https://doi.org/10.1109/TCSS.2026.3669799 Fact-checking with contextual narratives: Leveraging retrieval-augmented llms for social media analysis . IEEE Transactions on Computational Social Systems, pages 1--12
-
[103]
Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. 2023. https://doi.org/10.18653/v1/2023.acl-long.910 RARR : Researching and revising what language models say, using language models . In Proceedings of the 61st Annual Meeting of the Association for Co...
-
[104]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.