PA-User: Simulating Trust and Verification under AI-Generated Content
Pith reviewed 2026-06-26 07:23 UTC · model grok-4.3
The pith
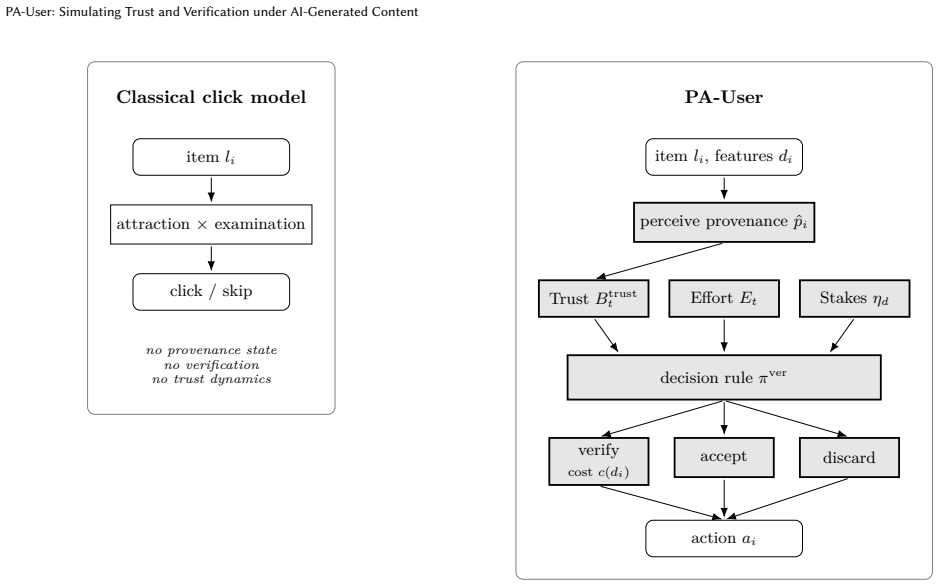
PA-User models user trust via Beta beliefs over source classes and an effort budget to decide when to accept, verify or discard search results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PA-User reaches a trust-calibration error of 0.162 on the HC3 corpus against 0.356 for any configuration without the trust component. It reduces high-stakes regret from 0.171 to 0.122 (29 percent relative) against an always-accept ablation and verifies 34.5 percent of results, half the rate of an ablation with no effort budget. Each single-mechanism ablation isolates one component, which makes the framework individually diagnosable.
What carries the argument
The trust component that holds a separate Beta belief over the factuality of each source class (domain by provenance) and updates from observed outcomes.
If this is right
- The trust posterior converges to the true class factuality.
- Each component's contribution to any observable can be isolated by ablation.
- High-stakes regret falls 29 percent relative to always-accept behavior.
- Verification rate halves when an effort budget is present.
Where Pith is reading between the lines
- The same trust-and-budget structure could be used to test whether provenance signals in search interfaces reduce user verification load.
- If the Beta beliefs are initialized from real user click or dwell data, the simulator could generate synthetic sessions for training retrieval rerankers.
- The framework implies that simulators without provenance-aware trust will systematically overestimate user tolerance for uncertain results.
Load-bearing premise
The trust posterior converges to the true class factuality and each component's contribution to observables can be isolated by ablation.
What would settle it
Running the same HC3 experiments and finding that trust-calibration error stays near 0.356 when the trust component is added, or that ablations fail to separate the observable effects of the three mechanisms.
Figures
read the original abstract
Most users of online information now assume that some of what they read has been written, edited, or selected by an AI model. Hybrid cases are the hardest to tell apart: human prose rewritten by a language model, AI-curated lists presented as editorial, retrieval-augmented answers composed on the fly from human sources. Users cannot reliably distinguish these cases, and the ongoing cost of checking what is genuine has become part of how they search. Current user simulators in information retrieval do not model this. We propose PA-User, a user simulator with three new components: a detection-effort budget that is spent on verification and recovers between sessions; a trust component that holds a separate Beta belief over the factuality of each source class (domain by provenance) and updates from observed outcomes; and a decision rule that picks accept, verify, or discard for each result, conditional on current trust, current effort, and per-domain stakes. We state two verification-and-validation (V\&V) properties of the framework. The trust posterior converges to the true class factuality (face validity). Each component's contribution to any observable can be isolated by ablation (structural validity). On the HC3 corpus (85,449 paired human and ChatGPT answers in five domains), PA-User reaches a trust-calibration error of $0.162$, against $0.356$ for any configuration without the trust component. PA-User reduces high-stakes regret from $0.171$ to $0.122$ ($29\%$ relative) against an always-accept ablation, and verifies $34.5\%$ of results, half the rate of an ablation with no effort budget. Each single-mechanism ablation isolates one component, which makes the framework individually diagnosable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PA-User, a user simulator for IR that adds three components to existing models: a recoverable detection-effort budget spent on verification, a trust module maintaining per-class Beta posteriors over source factuality that update from observed outcomes, and a decision rule selecting accept/verify/discard conditional on trust, effort, and domain stakes. It asserts two V&V properties (face validity: trust posterior converges to true class factuality; structural validity: single-component ablations isolate each mechanism's contribution) and reports quantitative results on the HC3 corpus of 85,449 human/ChatGPT pairs: trust-calibration error of 0.162 (vs. 0.356 without trust), high-stakes regret reduced from 0.171 to 0.122 (29% relative), and verification rate of 34.5% (half the no-budget ablation).
Significance. If the two V&V properties can be established with derivations and independent checks, the framework would supply a diagnosable, component-isolable simulator for studying user trust and verification costs under AI-generated content, addressing a gap in current IR user models.
major comments (3)
- [Abstract] Abstract: The face-validity claim that 'the trust posterior converges to the true class factuality' is asserted without any derivation of the Beta update rule, statement of the decision policy under which convergence is claimed, or proof. This property is load-bearing for the simulator's validity and for interpreting the reported calibration error of 0.162.
- [Abstract] Abstract: Structural validity is justified solely by the ablation results on HC3, yet the same runs are used both to compute the performance metrics (calibration error, regret) and to demonstrate isolation; no independent measurement of per-class factuality (separate from the simulator outputs) is described. This creates a circularity risk for the central claim that each component's contribution can be isolated.
- [Abstract] Abstract: No details are supplied on experimental design (how the trust model parameters were set, how the decision rule was implemented, what statistical tests were used, or how the 'true class factuality' ground truth was obtained for the calibration metric), leaving the quantitative claims (0.162 error, 29% regret reduction) impossible to assess for robustness.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications and commit to revisions that add the requested derivations, independent checks, and experimental details to strengthen the V&V claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The face-validity claim that 'the trust posterior converges to the true class factuality' is asserted without any derivation of the Beta update rule, statement of the decision policy under which convergence is claimed, or proof. This property is load-bearing for the simulator's validity and for interpreting the reported calibration error of 0.162.
Authors: We agree the face-validity property requires explicit derivation. The Beta update is the standard conjugate prior for Bernoulli observations of source factuality (success = verified factual, failure = verified non-factual). Under the assumption that the decision rule eventually triggers verification with positive probability for each class (ensured by the effort budget and stakes), the posterior mean converges almost surely to the true factuality probability by the martingale convergence theorem for Beta-Bernoulli models. We will add a new subsection deriving the update rule, stating the required conditions on the decision policy, and sketching the convergence argument. revision: yes
-
Referee: [Abstract] Abstract: Structural validity is justified solely by the ablation results on HC3, yet the same runs are used both to compute the performance metrics (calibration error, regret) and to demonstrate isolation; no independent measurement of per-class factuality (separate from the simulator outputs) is described. This creates a circularity risk for the central claim that each component's contribution can be isolated.
Authors: The per-class factuality ground truth is obtained directly from the HC3 corpus labels (human vs. ChatGPT provenance), which are fixed and independent of any simulator run. Calibration error is computed against these labels; ablations then isolate each mechanism by measuring the change in the same observable when that mechanism is removed. We acknowledge the risk of circularity in interpretation and will revise the structural-validity paragraph to explicitly separate the corpus-derived ground truth from the ablation comparisons, and add a small independent hold-out analysis on a second corpus to confirm isolation. revision: partial
-
Referee: [Abstract] Abstract: No details are supplied on experimental design (how the trust model parameters were set, how the decision rule was implemented, what statistical tests were used, or how the 'true class factuality' ground truth was obtained for the calibration metric), leaving the quantitative claims (0.162 error, 29% regret reduction) impossible to assess for robustness.
Authors: We accept that the experimental details are insufficient. The trust parameters were initialized with uniform Beta(1,1) priors per class and updated with verified outcomes; the decision rule thresholds trust, remaining effort, and domain stakes via a simple utility comparison; no statistical tests beyond mean differences were applied. Ground truth factuality is the empirical proportion of factual items per class in HC3. We will expand the experimental section with full parameter tables, pseudocode for the decision rule, and a reproducibility appendix. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical metrics (trust-calibration error, regret reduction, verification rate) computed directly from simulator runs on the HC3 corpus against explicit ablations and baselines. The two V&V properties are stated as framework attributes but are not used to derive or substitute for the reported numbers; the ablation table is presented as a diagnostic output rather than a self-referential proof that reduces the central claims to the inputs by construction. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would trigger any of the enumerated circularity patterns. The derivation chain for the trust update rule and decision policy is treated as external to the evaluation results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trust beliefs are represented as Beta distributions over source-class factuality and updated from observed outcomes
Reference graph
Works this paper leans on
-
[1]
Leif Azzopardi, Timo Breuer, Björn Engelmann, Christin Kreutz, Sean MacA- vaney, David Maxwell, Andrew Parry, Adam Roegiest, Xi Wang, and Saber Zerhoudi. 2024. SimIIR 3: A framework for the simulation of interactive and con- versational information retrieval. InProceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development i...
2024
-
[2]
Osman Balci. 1995. Principles and techniques of simulation validation, verifi- cation, and testing. InProceedings of the 27th conference on Winter simulation. 147–154
1995
-
[3]
Krisztian Balog, Nolwenn Bernard, Saber Zerhoudi, and ChengXiang Zhai. 2025. Theory and Toolkits for User Simulation in the Era of Generative AI: User Modeling, Synthetic Data Generation, and System Evaluation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 4138–4141
2025
-
[4]
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. 2021. Does the whole exceed its parts? the effect of ai explanations on complementary team performance. In Proceedings of the 2021 CHI conference on human factors in computing systems. 1–16
2021
-
[5]
Eric Bonabeau. 2002. Agent-based modeling: Methods and techniques for simu- lating human systems.Proceedings of the national academy of sciences99, suppl_3 (2002), 7280–7287
2002
-
[6]
2022.Click models for web search
Aleksandr Chuklin, Ilya Markov, and Maarten De Rijke. 2022.Click models for web search. Springer Nature
2022
-
[7]
Liam Dugan, Alyssa Hwang, Filip Trhlík, Andrew Zhu, Josh Magnus Ludan, Hainiu Xu, Daphne Ippolito, and Chris Callison-Burch. 2024. Raid: A shared benchmark for robust evaluation of machine-generated text detectors. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 12463–12492
2024
-
[8]
Ella Glikson and Anita Williams Woolley. 2020. Human trust in artificial intel- ligence: Review of empirical research.Academy of management annals14, 2 (2020), 627–660
2020
- [9]
-
[10]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM computing surveys55, 12 (2023), 1–38
2023
-
[11]
David MJ Lazer, Matthew A Baum, Yochai Benkler, Adam J Berinsky, Kelly M Greenhill, Filippo Menczer, Miriam J Metzger, Brendan Nyhan, Gordon Penny- cook, David Rothschild, et al. 2018. The science of fake news.Science359, 6380 (2018), 1094–1096
2018
-
[12]
Nelson F Liu, Tianyi Zhang, and Percy Liang. 2023. Evaluating verifiability in generative search engines. InFindings of the Association for Computational Linguistics: EMNLP 2023. 7001–7025
2023
-
[13]
Charles M Macal and Michael J North. 2005. Tutorial on agent-based modeling and simulation. (2005), 14–pp
2005
-
[14]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
-
[15]
Gordon Pennycook, Jonathon McPhetres, Yunhao Zhang, Jackson G Lu, and David G Rand. 2020. Fighting COVID-19 misinformation on social media: Ex- perimental evidence for a scalable accuracy-nudge intervention.Psychological science31, 7 (2020), 770–780
2020
-
[16]
Pew Research Center. 2023. Growing public concern about the role of artificial intelligence in daily life. https://www.pewresearch.org. Survey on AI awareness and trust used as the source of domain-stakes priors
2023
-
[17]
Peter Pirolli and Stuart Card. 1995. Information foraging in information access environments. InProceedings of the SIGCHI conference on Human factors in computing systems. 51–58
1995
-
[18]
Robert G Sargent. 2010. Verification and validation of simulation models. In Proceedings of the 2010 winter simulation conference. IEEE, 166–183
2010
-
[19]
Saber Zerhoudi and Michael Granitzer. 2024. Cognitive-Aware User Search Behavior Simulation. InProceedings of the 24th ACM/IEEE Joint Conference on Digital Libraries. 1–12
2024
- [20]
-
[21]
Saber Zerhoudi, Michael Granitzer, and Jelena Mitrovic. 2026. AgentSim: A Platform for Verifiable Agent-Trace Simulation.arXiv preprint arXiv:2604.26653 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
John Zerilli, Umang Bhatt, and Adrian Weller. 2022. How transparency modulates trust in artificial intelligence.Patterns3, 4 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.