From Structural Equation Modelling to Double Machine Learning: Robustness Analysis for Survey-Based Research
Pith reviewed 2026-07-02 16:08 UTC · model grok-4.3
The pith
A staged framework uses SEM then OLS then double machine learning to check which survey relationships are stable across methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
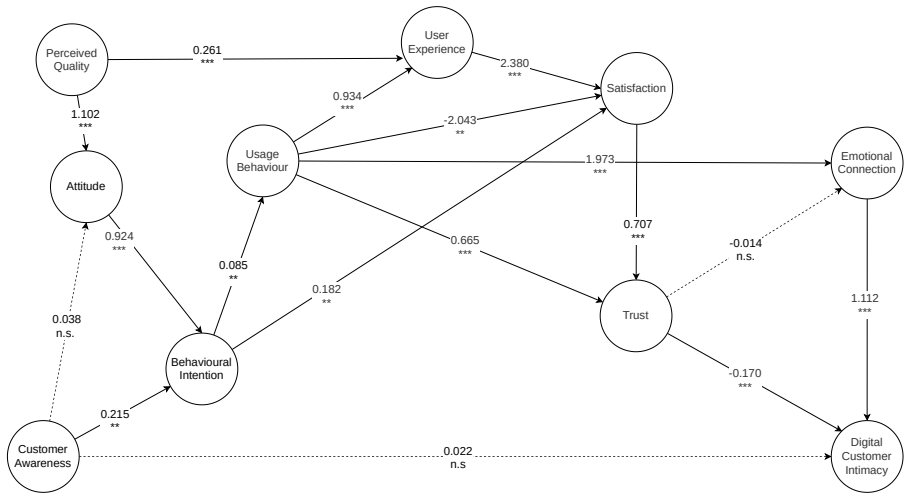
The paper claims that by first using SEM to refine the measurement structure and retain the full structural path system, then testing with OLS and DML residualisation, researchers can identify which relationships remain stable and which are sensitive to the estimation method, as demonstrated in the FinTech survey application.
What carries the argument
The staged robustness analysis framework sequencing SEM baseline estimation, OLS on construct scores, and DML-style residualisation with learner sensitivity checks.
If this is right
- Stable relationships across the three methods support more confident interpretation.
- Relationships that change under DML-style checks warrant cautious interpretation.
- The framework supplies a reusable template for other survey studies via the public Colab workbook.
- Learner-sensitivity and reverse-direction diagnostics help assess method dependence.
Where Pith is reading between the lines
- The method could be applied in other social science fields that rely on latent variable models from surveys.
- It may reveal cases where traditional SEM overlooks nonlinear or complex control effects captured by machine learning.
- Widespread use might lead to more hybrid SEM-ML workflows in empirical research.
Load-bearing premise
SEM-refined construct scores can be used as inputs to OLS and DML without the staged process introducing bias that invalidates the robustness comparisons.
What would settle it
If re-estimating the FinTech model with direct DML on raw items instead of SEM scores produces materially different stability conclusions, that would indicate the framework's staging introduces artifacts.
Figures
read the original abstract
Structural equation modelling (SEM) is widely used in survey-based business and information systems research to assess latent constructs and theory-driven structural relationships. However, SEM path significance is obtained within a particular model specification and may not show whether findings remain stable under alternative estimation frameworks. This study develops and demonstrates a staged robustness analysis framework that connects SEM, ordinary least squares (OLS) regression, and Double Machine Learning (DML). SEM is first used to refine the measurement structure and estimate the robustness-baseline SEM model, in which the full theory-specified structural path system is retained for downstream robustness analysis before final structural path evaluation. OLS regression is then applied to SEM-derived construct scores as a transparent regression benchmark. Finally, DML-style residualisation is used to examine whether each tested focal relationship remains stable after flexible machine-learning-based adjustment for observed controls. Learner-sensitivity checks compare Random Forest, Gradient Boosting, and Support Vector Machine learners, and selected reverse-direction diagnostics are used to examine directional sensitivity. The framework is demonstrated using a FinTech Digital Customer Intimacy survey model. The findings identify which relationships are stable across SEM, OLS, and DML-style checks, and which require more cautious interpretation. A reproducible Google Colab workbook and generated result files are publicly available, providing a reusable template that researchers and students can adapt to other survey-based latent-construct studies. The paper contributes a practical robustness workflow and interpretation guide for survey-based researchers seeking to complement SEM with conventional and machine-learning-based robustness checks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a staged robustness analysis framework for survey-based research with latent constructs: SEM is used first to refine measurement structure and estimate a baseline model retaining the full structural path system; SEM-derived construct scores are then fed into OLS regression as a benchmark; finally, DML-style residualisation (with learner-sensitivity checks across RF, GB, and SVM) examines stability of focal relationships after flexible ML adjustment for controls, supplemented by reverse-direction diagnostics. The framework is demonstrated on a FinTech Digital Customer Intimacy survey dataset to identify which relationships remain stable across the three approaches and which warrant cautious interpretation. A reproducible Google Colab workbook is provided as a reusable template.
Significance. If the two-stage procedure can be shown to support valid comparisons, the workflow supplies survey researchers in business and IS fields with a concrete, reusable template for complementing SEM with transparent regression and ML-based checks, potentially increasing the credibility of structural findings. The public release of the Colab notebook and result files is a clear strength that directly aids reproducibility and adaptation by other researchers.
major comments (1)
- [Abstract / framework description] Abstract and framework description (staged process): the sequential workflow extracts SEM construct scores and treats them as fixed observed inputs for the subsequent OLS benchmark and DML residualisation stages, with no mention of joint estimation, bootstrap correction for measurement error, or delta-method adjustment for first-stage uncertainty. In latent-variable settings this separation risks biased second-stage coefficients or understated variability, so that apparent stability across methods may reflect score-construction artifacts rather than true invariance of the structural relationships. This directly undermines the central claim that the framework reliably flags stable versus cautionary relationships.
minor comments (2)
- [Methods] The abstract states that 'the full theory-specified structural path system is retained for downstream robustness analysis before final structural path evaluation'; clarify in the methods section whether this means the SEM structural paths are held fixed or re-estimated at each stage.
- [Results] Learner-sensitivity checks are mentioned but no quantitative comparison (e.g., stability of DML estimates across RF/GB/SVM) is summarized in the abstract; ensure the results section reports these metrics explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the single major comment below, acknowledging its validity while clarifying the intended scope of the framework.
read point-by-point responses
-
Referee: [Abstract / framework description] Abstract and framework description (staged process): the sequential workflow extracts SEM construct scores and treats them as fixed observed inputs for the subsequent OLS benchmark and DML residualisation stages, with no mention of joint estimation, bootstrap correction for measurement error, or delta-method adjustment for first-stage uncertainty. In latent-variable settings this separation risks biased second-stage coefficients or understated variability, so that apparent stability across methods may reflect score-construction artifacts rather than true invariance of the structural relationships. This directly undermines the central claim that the framework reliably flags stable versus cautionary relationships.
Authors: We thank the referee for this important observation. The framework is intentionally staged to deliver a transparent, practitioner-accessible sequence of checks rather than a joint or corrected estimator. We agree that treating SEM-derived scores as fixed observed inputs omits measurement-error correction and first-stage uncertainty propagation, which can bias second-stage coefficients and understate variability. This is a genuine limitation of the two-stage design. The paper's central claim is that the workflow helps identify relationships whose sign and significance are stable across SEM, OLS, and DML-style specifications for more cautious interpretation, not that the procedure yields statistically efficient or unbiased estimates. In the revision we will (i) explicitly describe the two-stage nature and its statistical consequences in the abstract and framework section, (ii) add a dedicated limitations paragraph discussing the risk of score-construction artifacts, and (iii) qualify the interpretation of 'stable' relationships accordingly. These changes will prevent over-interpretation while preserving the practical utility of the template. revision: yes
Circularity Check
No circularity: procedural workflow without derivations or fitted predictions
full rationale
The paper proposes a staged robustness analysis workflow connecting SEM, OLS, and DML for survey data. No equations, predictions, or first-principles results are claimed that could reduce to inputs by construction. The abstract and description frame the contribution as a practical sequence of steps (SEM refinement → score extraction → OLS benchmark → DML residualisation) with learner-sensitivity checks, not a mathematical derivation. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear. The framework is self-contained as a methodological template; any validity concerns (e.g., two-stage uncertainty) fall under statistical assumptions rather than circularity. This matches the default expectation for non-derivational papers.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Assumptions underlying structural equation modelling for latent variables and path analysis
- ad hoc to paper Validity of using SEM-derived construct scores in subsequent regression and ML analyses
- domain assumption Double machine learning can flexibly adjust for observed controls without residual confounding in this context
Reference graph
Works this paper leans on
-
[1]
C., and Gerbing, D
Anderson, J. C., and Gerbing, D. W. (1988). Structural equation modeling in practice: A review and recommended two-step approach. Psychological Bulletin, 103(3), 411--423
1988
-
[2]
S., and Spindler, M
Bach, P., Chernozhukov, V., Kurz, M. S., and Spindler, M. (2022). DoubleML---An object-oriented implementation of double machine learning in Python. Journal of Machine Learning Research, 23(53), 1--6
2022
-
[3]
D., Ibeling, D., and Icard, T
Bareinboim, E., Correa, J. D., Ibeling, D., and Icard, T. (2022). On Pearl's hierarchy and the foundations of causal inference. In H. Geffner, R. Dechter, and J. Y. Halpern (Eds.), Probabilistic and causal inference: The works of Judea Pearl (pp. 507--556). ACM Books
2022
-
[4]
Bhattacherjee, A. (2001). Understanding information systems continuance: An expectation-confirmation model. MIS Quarterly, 25(3), 351--370
2001
-
[5]
Bollen, K. A. (1989). Structural equations with latent variables. John Wiley & Sons
1989
-
[6]
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5--32
2001
-
[7]
Brunner, J. (2023). Structural equation models: An open textbook (Edition 0.10). Department of Statistical Sciences, University of Toronto
2023
-
[8]
Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. (2018). Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal, 21(1), C1--C68
2018
-
[9]
Cortes, C., and Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273--297
1995
-
[10]
Davis, F. D. (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly, 13(3), 319--340
1989
-
[11]
Downing, C. E. (1999). System usage behavior as a proxy for user satisfaction: An empirical investigation. Information & Management, 35(4), 203--216. https://doi.org/10.1016/S0378-7206(98)00090-1
-
[12]
Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29(5), 1189--1232
2001
-
[13]
W., and Boudreau, M.-C
Gefen, D., Straub, D. W., and Boudreau, M.-C. (2000). Structural equation modeling and regression: Guidelines for research practice. Communications of the Association for Information Systems, 4, Article 7
2000
-
[14]
Liu, Q., Chan, K.-C., and Chimhundu, R. (2024a). Fintech research: Systematic mapping, classification, and future directions. Financial Innovation, 10(1), Article 24
-
[15]
Liu, Q., Chan, K.-C., and Chimhundu, R. (2024b). From customer intimacy to digital customer intimacy. Journal of Theoretical and Applied Electronic Commerce Research, 19(4), 3386--3411
-
[16]
Liu, Q., Chan, K.-C., Tiwari, S., and Chimhundu, R. (2026). From adoption to intimacy: Experiential and emotional pathways of digital customer intimacy in FinTech. Manuscript under review
2026
-
[17]
B., Podsakoff, P
MacKenzie, S. B., Podsakoff, P. M., and Podsakoff, N. P. (2011). Construct measurement and validation procedures in MIS and behavioral research: Integrating new and existing techniques. MIS Quarterly, 35(2), 293--334
2011
-
[18]
Pearl, J. (2009). Causality: Models, reasoning, and inference (2nd ed.). Cambridge University Press
2009
-
[19]
M., MacKenzie, S
Podsakoff, P. M., MacKenzie, S. B., Lee, J.-Y., and Podsakoff, N. P. (2003). Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88(5), 879--903
2003
-
[20]
Ratnawati, S., Durachman, Y., and Saputra, A. (2022). Analyzing factors influencing intention to use and actual use of mobile fintech applications free interbank money transfer Flip using UTAUT 2 model with trust and perceived security. In 2022 10th International Conference on Cyber and IT Service Management (CITSM). https://doi.org/10.1109/CITSM56380.202...
-
[21]
F., and Tudoran, A
Richter, N. F., and Tudoran, A. A. (2024). Elevating theoretical insight and predictive accuracy in business research: Combining PLS-SEM and selected machine learning algorithms. Journal of Business Research, 173, Article 114453
2024
-
[22]
Shi, B., Mao, X., Yang, M., and Li, B. (2025). What, why, and how: An empiricist's guide to double/debiased machine learning. Information Systems Research. Advance online publication
2025
-
[23]
Treacy, M., and Wiersema, F. (1993). Customer intimacy and other value disciplines. Harvard Business Review, 71(1), 84--93
1993
-
[24]
G., Davis, G
Venkatesh, V., Morris, M. G., Davis, G. B., and Davis, F. D. (2003). User acceptance of information technology: Toward a unified view. MIS Quarterly, 27(3), 425--478
2003
-
[25]
Wu, B., Ding, Y., Xie, B., and Zhang, Y. (2024). FinTech and inclusive green growth: A causal inference based on double machine learning. Sustainability, 16(22), Article 9989. https://doi.org/10.3390/su16229989
-
[26]
Yan, Z., Dong, Y., Niemi, V., and Yu, G. (2013). Exploring trust of mobile applications based on user behaviors: An empirical study. Journal of Applied Social Psychology, 43(3), 638--659. https://doi.org/10.1111/j.1559-1816.2013.01044.x
-
[27]
(2016, August 29)
Zorfas, A., and Leemon, D. (2016, August 29). An emotional connection matters more than customer satisfaction. Harvard Business Review. https://hbr.org/2016/08/an-emotional-connection-matters-more-than-customer-satisfaction
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.