Cross-Modality Structural Guidance in 3D Latent Diffusion for Robust FLAIR Super-Resolution
Pith reviewed 2026-06-25 21:04 UTC · model grok-4.3
The pith
High-resolution T1w images supply structural attention maps to guide 3D latent diffusion super-resolution of thick-slice FLAIR without hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
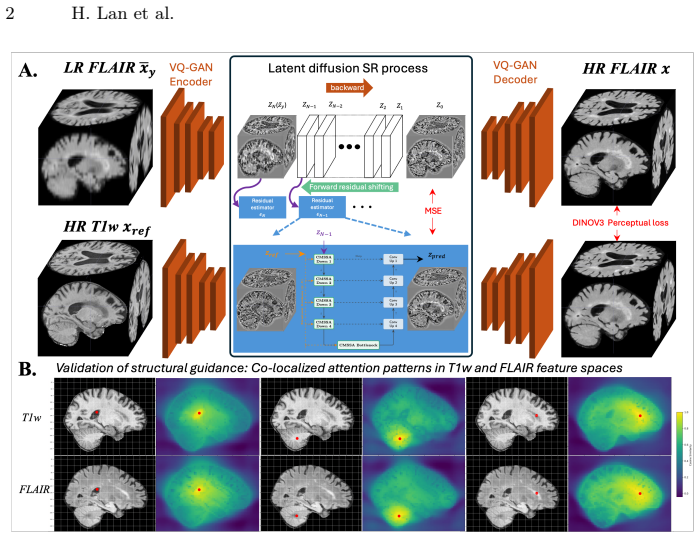
MR-DiffuSR introduces cross-modality structural swin-attention that derives structural attention maps from the HR T1w and applies them to the low-resolution FLAIR latent features. This design disentangles anatomical structure from modality-specific contrast, effectively preventing hallucinations. The framework operates in 3D latent space, employs mixed-scale degradation to handle varying downsampling factors, and optimizes with a DINOv3-based perceptual loss to preserve high-frequency semantic details.
What carries the argument
cross-modality structural swin-attention that derives structural attention maps from HR T1w and applies them to low-resolution FLAIR latent features
If this is right
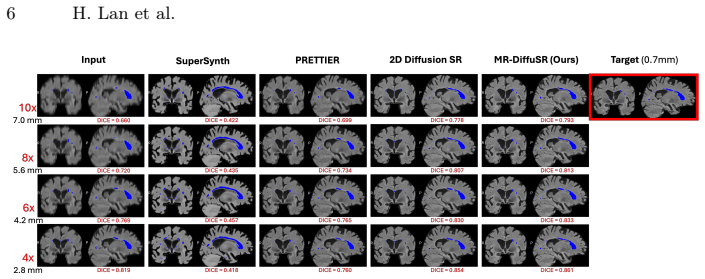
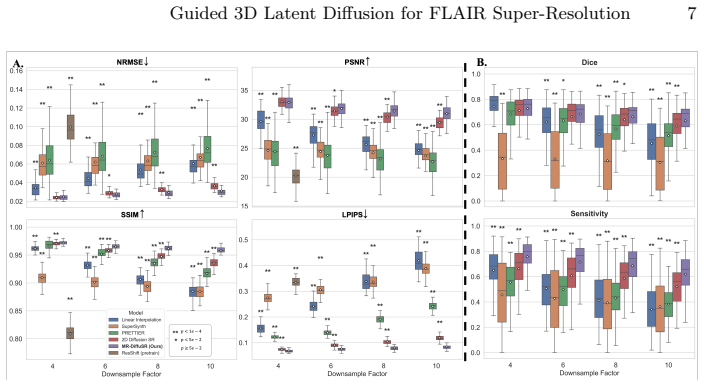
- Achieves average PSNR of 32.46 dB, SSIM of 0.97, and LPIPS of 0.07 across all tested downsampling factors on ADNI-4.
- Maintains Dice score of 0.63 in downstream white matter hyperintensity segmentation at 10x downsampling where baselines fall to 0.51.
- Remains effective at 7 mm equivalent slice thickness through mixed-scale training.
- Outperforms both CNN-based and 2D diffusion super-resolution methods.
Where Pith is reading between the lines
- The same attention-transfer idea could be tested on other modality pairs such as T1w-to-T2w or FLAIR-to-PD without retraining the full diffusion backbone.
- Because the model runs in latent space, it may scale to whole-brain volumes at higher isotropic resolutions than voxel-space diffusion approaches allow.
- If registration between T1w and FLAIR is imperfect in real clinical data, an explicit alignment-correction step before attention transfer would be needed to keep the hallucination-prevention benefit.
Load-bearing premise
T1w and FLAIR images are assumed to be perfectly aligned and to share identical underlying anatomy so attention maps transfer without misalignment artifacts.
What would settle it
Performance drop or introduction of structural errors on test cases where T1w and FLAIR volumes are deliberately shifted by 1-2 voxels before super-resolution.
Figures

read the original abstract
High-resolution (HR) MRI acquisition is often hampered by scan time constraints, resulting in anisotropic or low-resolution scans (e.g., thick-slice FLAIR) that limit diagnostic accuracy. While deep learning-based super-resolution (SR) methods show promise, they often hallucinate anatomical details, which can compromise brain structural integrity. To mitigate this limitation, we introduce MR-DiffuSR, a Multi-Resolution Diffusion-based Super-Resolution framework that incorporates HR T1w structural image priors to guide the restoration of thick-slice FLAIR scans and operates in the 3D latent space. Our architecture introduces cross-modality structural swin-attention, which derives structural attention maps from the HR T1w and applies them to the low-resolution FLAIR latent features. This design disentangles anatomical structure from modality-specific contrast, effectively preventing hallucinations. Furthermore, we employ a mixed-scale degradation strategy, training the model on a continuum of downsampling factors to ensure robustness to varying slice thicknesses, while optimizing with a DINOv3-based perceptual loss to preserve high-frequency semantic details. Evaluated on the ADNI-4 dataset, MR-DiffuSR surpasses both CNN and 2D diffusion approaches, achieving an average PSNR of 32.46dB, SSIM of 0.97, and LPIPS of 0.07 across all downsampling factors. In downstream white matter hyperintensity segmentation, our model demonstrates exceptional robustness. While baseline performance collapses at 10x down-sampling (Dice: 0.51), MR-DiffuSR maintains a Dice score of 0.63, preserving utility even at 7mm equivalent slice thickness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MR-DiffuSR, a 3D latent diffusion framework for super-resolving low-resolution (thick-slice) FLAIR MRI using high-resolution T1w structural priors. The core component is a cross-modality structural Swin-attention module that extracts attention maps from the HR T1w image and applies them to LR FLAIR latent features to disentangle anatomy from modality-specific contrast, thereby preventing hallucinations. Training incorporates a mixed-scale degradation strategy and a DINOv3-based perceptual loss; evaluation on ADNI-4 reports aggregate metrics (PSNR 32.46 dB, SSIM 0.97, LPIPS 0.07) and improved downstream white-matter hyperintensity Dice scores relative to CNN and 2D diffusion baselines.
Significance. If the alignment assumption holds and the attention mechanism demonstrably suppresses hallucinations, the approach could meaningfully improve robustness of diffusion-based MRI super-resolution for clinical use, especially given the downstream segmentation evaluation and the mixed-scale training for variable slice thicknesses. The explicit use of a perceptual loss grounded in DINOv3 is a constructive design choice.
major comments (2)
- [Abstract] Abstract: The central claim that cross-modality structural Swin-attention prevents hallucinations rests on the unstated premise that T1w and FLAIR volumes are registered to sub-voxel accuracy and share identical underlying anatomy. No registration procedure, alignment verification, or robustness experiment (e.g., synthetic shifts) is described; modest misalignment would cause the transferred attention maps to impose incorrect structural constraints, potentially creating rather than suppressing hallucinations.
- [Abstract] Abstract: Reported metrics are aggregates without error bars, per-subject standard deviations, or statistical tests. No ablation isolating the contribution of the cross-modality Swin-attention module is mentioned, leaving the load-bearing architectural claim unsupported by controlled evidence.
minor comments (1)
- [Abstract] The abstract states results 'across all downsampling factors' but does not enumerate the tested factors or confirm that the mixed-scale training distribution matches the evaluation distribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify important gaps in the description of data assumptions and in the quantitative support for the core architectural claim. We respond to each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that cross-modality structural Swin-attention prevents hallucinations rests on the unstated premise that T1w and FLAIR volumes are registered to sub-voxel accuracy and share identical underlying anatomy. No registration procedure, alignment verification, or robustness experiment (e.g., synthetic shifts) is described; modest misalignment would cause the transferred attention maps to impose incorrect structural constraints, potentially creating rather than suppressing hallucinations.
Authors: We acknowledge that the manuscript does not explicitly describe the registration procedure or include robustness experiments. In the revised version we will add a dedicated preprocessing subsection specifying the registration method (affine registration via ANTs with mutual information), alignment verification (e.g., landmark-based checks and overlap metrics on segmented structures), and a new experiment that applies controlled synthetic shifts (1–3 voxels) to the T1w prior and reports the resulting change in PSNR, LPIPS, and downstream Dice to quantify sensitivity of the attention module. revision: yes
-
Referee: [Abstract] Abstract: Reported metrics are aggregates without error bars, per-subject standard deviations, or statistical tests. No ablation isolating the contribution of the cross-modality Swin-attention module is mentioned, leaving the load-bearing architectural claim unsupported by controlled evidence.
Authors: We agree that aggregate metrics alone are insufficient. In the revision we will report per-subject standard deviations, error bars on all tables and figures, and paired statistical tests (Wilcoxon signed-rank) against the CNN and 2D diffusion baselines. We will also add an ablation study that removes or replaces the cross-modality Swin-attention module with standard self-attention and quantifies the resulting drops in PSNR, SSIM, LPIPS, and WMH Dice scores across downsampling factors. revision: yes
Circularity Check
No circularity: architectural proposal with no self-referential derivations
full rationale
The paper proposes a new diffusion-based super-resolution architecture (MR-DiffuSR) that incorporates cross-modality structural swin-attention to transfer maps from HR T1w to LR FLAIR latents. No equations, parameter fits, or uniqueness theorems are described that reduce any claimed result to the inputs by construction. The central mechanism is presented as an architectural design choice rather than a derivation; no self-citation chains, fitted-input predictions, or ansatz smuggling appear in the provided text. The method is self-contained as an empirical architecture evaluated on ADNI-4, consistent with the reader's assessment of minimal circularity risk.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption T1w and FLAIR volumes share identical underlying anatomy and can be aligned without residual error
invented entities (1)
-
cross-modality structural swin-attention module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Journal of Imaging11(4), 104 (2025)
Amoros, M., Curado, M., Vicent, J.F.: Evaluating super-resolution models in biomedical imaging: applications and performance in segmentation and classifi- cation. Journal of Imaging11(4), 104 (2025)
2025
-
[2]
In: International conference on medical image computing and computer-assisted intervention
Cohen, J.P., Luck, M., Honari, S.: Distribution matching losses can hallucinate fea- tures in medical image translation. In: International conference on medical image computing and computer-assisted intervention. pp. 529–536. Springer (2018)
2018
-
[3]
Bmj 341(2010)
Debette, S., Markus, H.: The clinical importance of white matter hyperintensities on brain magnetic resonance imaging: systematic review and meta-analysis. Bmj 341(2010)
2010
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021)
2021
-
[5]
Nature reviews neurology6(2), 67–77 (2010)
Frisoni, G.B., Fox, N.C., Jack Jr, C.R., Scheltens, P., Thompson, P.M.: The clinical use of structural mri in alzheimer disease. Nature reviews neurology6(2), 67–77 (2010)
2010
-
[6]
Frontiers in Neuroscience18, 1473132 (2024)
Giraldo, D.L., Khan, H., Pineda, G., Liang, Z., Lozano-Castillo, A., Van Wijmeer- sch, B., Woodruff, H.C., Lambin, P., Romero, E., Peeters, L.M., et al.: Perceptual super-resolution in multiple sclerosis mri. Frontiers in Neuroscience18, 1473132 (2024)
2024
-
[7]
Magnetic resonance imaging20(5), 437–446 (2002)
Greenspan, H., Oz, G., Kiryati, N., Peled, S.: Mri inter-slice reconstruction using super-resolution. Magnetic resonance imaging20(5), 437–446 (2002)
2002
-
[8]
Science advances9(5), eadd3607 (2023)
Iglesias, J.E., Billot, B., Balbastre, Y., Magdamo, C., Arnold, S.E., Das, S., Edlow, B.L., Alexander, D.C., Golland, P., Fischl, B.: Synthsr: A public ai tool to turn heterogeneous clinical brain scans into high-resolution t1-weighted images for 3d morphometry. Science advances9(5), eadd3607 (2023)
2023
-
[9]
arXiv–2509 (2025)
Liu, C., Chen, Y., Shi, H., Lu, J., Jian, B., Pan, J., Cai, L., Wang, J., Zhang, Y., Li, J., et al.: Does dinov3 set a new medical vision standard? arXiv e-prints pp. arXiv–2509 (2025)
2025
-
[10]
arXiv preprint arXiv:2509.00549 (2025)
Liu, P., Puonti, O., Hu, X., Gopinath, K., Sorby-Adams, A., Alexander, D.C., Kimberly, W.T., Iglesias, J.E.: A modality-agnostic multi-task foundation model for human brain imaging. arXiv preprint arXiv:2509.00549 (2025)
-
[11]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[12]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017) 10 H. Lan et al
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Nature communications15(1), 4677 (2024)
Lu, C., Chen, K., Qiu, H., Chen, X., Chen, G., Qi, X., Jiang, H.: Diffusion-based deep learning method for augmenting ultrastructural imaging and volume electron microscopy. Nature communications15(1), 4677 (2024)
2024
-
[14]
PixelGen: Improving Pixel Diffusion with Perceptual Supervision
Ma, Z., Xu, R., Zhang, S.: Pixelgen: Pixel diffusion beats latent diffusion with perceptual loss. arXiv preprint arXiv:2602.02493 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Alzheimer’s & Dementia20(10), 7232–7247 (2024)
Miller, M.J., Diaz, A., Conti, C., Albala, B., Flenniken, D., Fockler, J., Kwang, W., Sacrey, D.T., Ashford, M.T., Skirrow, C., et al.: The adni4 digital study: A novel approach to recruitment, screening, and assessment of participants for ad clinical research. Alzheimer’s & Dementia20(10), 7232–7247 (2024)
2024
-
[16]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Poot, D.H., Van Meir, V., Sijbers, J.: General and efficient super-resolution method for multi-slice mri. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 615–622. Springer (2010)
2010
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[18]
Schmidt, P.: Bayesian inference for structured additive regression models for large- scale problems with applications to medical imaging. Ph.D. thesis, lmu (2017)
2017
-
[19]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
IEEE transactions on medical imag- ing29(6), 1310–1320 (2010)
Tustison, N.J., Avants, B.B., Cook, P.A., Zheng, Y., Egan, A., Yushkevich, P.A., Gee, J.C.: N4itk: improved n3 bias correction. IEEE transactions on medical imag- ing29(6), 1310–1320 (2010)
2010
-
[22]
Concepts in Magnetic Resonance Part A40(6), 306– 325 (2012)
Van Reeth, E., Tham, I.W., Tan, C.H., Poh, C.L.: Super-resolution in magnetic resonance imaging: a review. Concepts in Magnetic Resonance Part A40(6), 306– 325 (2012)
2012
-
[23]
The Lancet Neurology12(8), 822–838 (2013)
Wardlaw, J.M., Smith, E.E., Biessels, G.J., Cordonnier, C., Fazekas, F., Frayne, R., Lindley, R.I., T O’Brien, J., Barkhof, F., Benavente, O.R., et al.: Neuroimaging standards for research into small vessel disease and its contribution to ageing and neurodegeneration. The Lancet Neurology12(8), 822–838 (2013)
2013
-
[24]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Yue, Z., Wang, J., Loy, C.C.: Efficient diffusion model for image restoration by residual shifting. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[26]
American Journal of Neuroradiology46(1), 41–48 (2025)
Zhang, S., Zhong, M., Shenliu, H., Wang, N., Hu, S., Lu, X., Lin, L., Zhang, H., Zhao, Y., Yang, C., et al.: Deep learning–based super-resolution reconstruction on undersampled brain diffusion-weighted mri for infarction stroke: a comparison to conventional iterative reconstruction. American Journal of Neuroradiology46(1), 41–48 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.