Dependency-Aware Circuit Scheduling for Multi-Core Quantum Systems to Minimize Makespan
Pith reviewed 2026-07-02 12:41 UTC · model grok-4.3
The pith
A greedy scheduler that dispatches quantum gates the instant their dependencies and cores are free cuts total execution time by 40 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
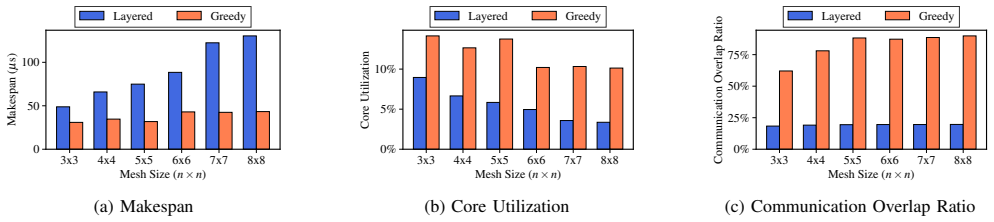
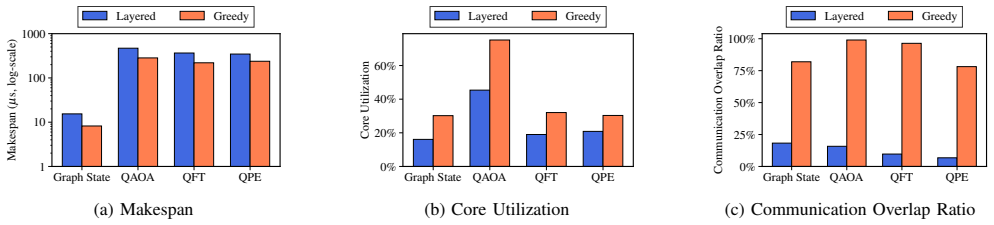
The paper establishes that a greedy, dependency-aware scheduler, which releases each quantum gate the moment all its predecessor gates have completed and the required cores plus communication links are available, produces an average 40 percent reduction in makespan and higher core utilization than a layered baseline on real quantum circuit benchmarks.
What carries the argument
The greedy scheduler that tracks per-gate dependencies and per-core resource availability to start each gate at the earliest feasible moment.
If this is right
- Multi-core systems can hide inter-core communication behind useful computation more effectively than layer-by-layer execution allows.
- Existing quantum algorithms can complete in less wall-clock time on the same multi-core hardware without any change to the circuit itself.
- Core utilization rises because idle time between layers shrinks when gates are released individually.
- The performance gap between layered and greedy scheduling widens on circuits whose gate dependencies are not perfectly aligned with layer boundaries.
Where Pith is reading between the lines
- In systems with many cores the same greedy logic may need to incorporate dynamic estimates of communication cost between distant cores.
- Pairing this scheduler with qubit-mapping tools that minimize inter-core moves could produce additive speed-ups.
- The approach may remain useful once error-corrected logical qubits are placed across multiple cores, provided the dependency graph is updated to reflect logical operations.
Load-bearing premise
The simulation of gate dependencies, communication latency, and core availability matches the timing behavior of actual multi-core quantum hardware.
What would settle it
Running the same benchmark circuits on physical multi-core quantum hardware and observing that the measured makespan reduction is substantially smaller than 40 percent.
Figures



read the original abstract
Multi-core quantum computing architectures have emerged as a promising solution to the qubit scalability limitations of monolithic NISQ devices. Quantum algorithms are expressed as quantum circuits composed of single- and two-qubit gates. However, circuit scheduling in multi-core quantum systems remains largely unexplored. Reducing overall execution time (makespan), increasing core utilization, and hiding communication latency behind computation depends on effective scheduling. In this paper, we first introduce a layered scheduling approach as a baseline where quantum gates within the same layer are executed in parallel, while layers themselves are executed sequentially. We then propose a greedy scheduling strategy which schedules each gate as soon as all its dependencies and required resources are available. This allows fine-grained parallelism across cores. Our evaluation shows that on real benchmarks, greedy scheduling achieves an average 40% reduction in makespan and improvement in core utilization. The results suggest that the use of intelligent circuit scheduling to exploit parallelism can greatly enhance the speed of circuit execution in multi-core quantum architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a layered baseline scheduler for quantum circuits on multi-core architectures (gates in a layer run in parallel, layers sequentially) and proposes a greedy dependency-aware scheduler that dispatches each gate as soon as its dependencies and resources are free. On real benchmarks the greedy method is reported to deliver an average 40% makespan reduction together with higher core utilization, obtained from a simulation that models gate dependencies, inter-core communication latency, and resource contention.
Significance. If the simulation model is faithful to hardware, the result would show that fine-grained dependency tracking can substantially improve execution time and utilization in multi-core quantum systems, an increasingly relevant engineering problem as monolithic devices scale. The contribution is mainly algorithmic and empirical rather than theoretical.
major comments (1)
- [Evaluation] Evaluation section (and abstract claim): the headline 40% makespan reduction and utilization improvement rest entirely on an unvalidated simulation of gate dependencies, communication latency, and core availability. No calibration data, comparison to physical multi-core devices (modular ion-trap or multi-chip superconducting modules), or sensitivity analysis to latency assumptions is provided; this directly undermines the empirical central claim.
minor comments (1)
- [Abstract] Abstract and introduction: the phrases 'real benchmarks' and 'simulation model' are used without any enumeration of the benchmark suite, number of cores tested, or concrete latency and parallelism parameters, making it impossible to assess reproducibility from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the evaluation below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract claim): the headline 40% makespan reduction and utilization improvement rest entirely on an unvalidated simulation of gate dependencies, communication latency, and core availability. No calibration data, comparison to physical multi-core devices (modular ion-trap or multi-chip superconducting modules), or sensitivity analysis to latency assumptions is provided; this directly undermines the empirical central claim.
Authors: We agree that the reported 40% makespan reduction is obtained from simulation rather than physical hardware execution, and that no calibration data or direct comparison to existing modular devices is provided. The simulation incorporates standard models for gate dependencies, inter-core communication latency, and resource contention drawn from the literature on multi-core quantum architectures. In revision we will add a sensitivity analysis over the key latency parameter, include an explicit discussion of modeling assumptions and limitations in both the abstract and evaluation section, and qualify the 40% figure as relative to the layered baseline under the modeled conditions. These changes will clarify the scope of the empirical results. revision: partial
- Direct empirical comparison against physical multi-core quantum hardware, as such systems remain emerging and not generally available for large-scale circuit benchmarking.
Circularity Check
No circularity: empirical scheduling evaluation independent of inputs
full rationale
The paper introduces a baseline layered scheduler and a greedy dependency-aware scheduler, then reports simulation results on benchmarks showing 40% average makespan reduction. No mathematical derivation chain, fitted parameters, or self-citations are used to generate the headline result; the comparison is direct and external to any self-defined quantities. The evaluation relies on a simulation model whose validity is an assumption, but this does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Super- conducting Quantum Computers with Chiplet Architectures,
K. N. Smith, G. S. Ravi, J. M. Baker, and F. T. Chong, “Scaling Super- conducting Quantum Computers with Chiplet Architectures,” in55th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2022, pp. 1092–1109
2022
-
[2]
Quantum Computing in the NISQ era and beyond,
J. Preskill, “Quantum Computing in the NISQ era and beyond,”Quan- tum, vol. 2, p. 79, 2018
2018
-
[3]
Interconnect Fabrics for Multi-Core Quantum Processors: A Context Analysis,
P. Escofet, S. B. Rached, S. Rodrigo, C. G. Almudever, E. Alarc ´on, and S. Abadal, “Interconnect Fabrics for Multi-Core Quantum Processors: A Context Analysis,” inProceedings of the 16th International Workshop on Network on Chip Architectures, 2023, pp. 34–39
2023
-
[4]
From Designing Quantum Processors to Large-Scale Quantum Com- puting Systems,
C. G. Almudever, R. Wille, F. Sebastiano, N. Haider, and E. Alarcon, “From Designing Quantum Processors to Large-Scale Quantum Com- puting Systems,” inDesign, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2024, pp. 1–10
2024
-
[5]
Scalable multi-chip quantum architectures enabled by cryogenic hybrid wireless/quantum-coherent network-in- package,
E. Alarc ´on, S. Abadal, F. Sebastiano, M. Babaie, E. Charbon, P. H. Bol´ıvar, M. Palesi, E. Blokhina, D. Leipold, B. Staszewski, A. Garcia- S´aez, and C. G. Almudever, “Scalable multi-chip quantum architectures enabled by cryogenic hybrid wireless/quantum-coherent network-in- package,” inIEEE International Symposium on Circuits and Systems (ISCAS), 2023, pp. 1–5
2023
-
[6]
Decentralized Frame- work for Teleportation in Quantum Core Interconnects,
P. R. Suance, R. Gupta, M. Palesi, and J. Jose, “Decentralized Frame- work for Teleportation in Quantum Core Interconnects,” inIEEE Com- puter Society Annual Symposium on VLSI (ISVLSI), vol. 1, 2025, pp. 1–6
2025
-
[7]
A Modular Quantum Com- pilation Framework for Distributed Quantum Computing,
D. Ferrari, S. Carretta, and M. Amoretti, “A Modular Quantum Com- pilation Framework for Distributed Quantum Computing,”IEEE Trans- actions on Quantum Engineering, vol. 4, pp. 1–13, 2023
2023
-
[8]
Mapping Quantum Circuits to Modular Architectures with QUBO,
M. Bandic, L. Prielinger, J. N ¨ußlein, A. Ovide, S. Rodrigo, S. Abadal, H. Van Someren, G. Vardoyan, E. Alarcon, C. G. Almudeveret al., “Mapping Quantum Circuits to Modular Architectures with QUBO,” in IEEE International Conference on Quantum Computing and Engineer- ing (QCE), vol. 1, 2023, pp. 790–801
2023
-
[9]
TeleSABRE: Heuristic Layout Synthesis in Multi-Core Quantum Sys- tems with Teleport Interconnect,
E. Russo, E. Vinciguerra, M. Palesi, D. Patti, G. Ascia, and V . Catania, “TeleSABRE: Heuristic Layout Synthesis in Multi-Core Quantum Sys- tems with Teleport Interconnect,” inIEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2025, pp. 749–758
2025
-
[10]
Entanglement Request Scheduling in Quantum Datacenter Networks,
F. Vista, S. DiAdamo, E. Kaur, H. Shapourian, and R. Nejabati, “Entanglement Request Scheduling in Quantum Datacenter Networks,” IEEE Network, 2025
2025
-
[11]
Execution Management of Distributed Quantum Computing Jobs,
D. Ferrari, M. Bandini, and M. Amoretti, “Execution Management of Distributed Quantum Computing Jobs,” inIEEE International Confer- ence on Quantum Computing and Engineering (QCE), vol. 2, 2024, pp. 150–154
2024
-
[12]
Modelling Short-range Quantum Teleportation for Scalable Multi-Core Quantum Computing Architectures,
S. Rodrigo, S. Abadal, C. G. Almud ´ever, and E. Alarc ´on, “Modelling Short-range Quantum Teleportation for Scalable Multi-Core Quantum Computing Architectures,” inProceedings of the 8th Annual ACM International Conference on Nanoscale Computing and Communication (NANOCOM), 2021, pp. 1–7
2021
-
[13]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Crosset al., “Quantum computing with Qiskit,”arXiv preprint arXiv:2405.08810, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Is Circuit Depth Accurate for Com- paring Quantum Circuit Runtimes?
M. Tremba, P. Hovland, and J. Liu, “Is Circuit Depth Accurate for Com- paring Quantum Circuit Runtimes?” inIEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2025, pp. 368–374
2025
-
[15]
Netrace: Dependency-Driven Trace-Based Network-on-Chip Simulation,
J. Hestness, B. Grot, and S. W. Keckler, “Netrace: Dependency-Driven Trace-Based Network-on-Chip Simulation,” inProceedings of the Third International Workshop on Network on Chip Architectures, 2010, pp. 31–36
2010
-
[16]
MQT Bench: Benchmark- ing Software and Design Automation Tools for Quantum Computing,
N. Quetschlich, L. Burgholzer, and R. Wille, “MQT Bench: Benchmark- ing Software and Design Automation Tools for Quantum Computing,” Quantum, vol. 7, p. 1062, 2023
2023
-
[17]
Analysing the Effect of Quantum Network Interconnect on the Per- formance of Distributed Quantum Computing,
S. Bahrani, R. Wang, R. Oliveira, R. Nejabati, and D. Simeonidou, “Analysing the Effect of Quantum Network Interconnect on the Per- formance of Distributed Quantum Computing,” inIEEE Optical Fiber Communications Conference and Exhibition (OFC), 2023, pp. 1–3
2023
-
[18]
Efficient generation of multi-partite entanglement between non-local superconducting qubits using classical feedback,
A. Hashim, M. Yuan, P. Gokhale, L. Chen, C. J ¨unger, N. Fruitwala, Y . Xu, G. Huang, K. Nowrouzi, L. Jianget al., “Efficient generation of multi-partite entanglement between non-local superconducting qubits using classical feedback,”APL Quantum, vol. 2, no. 4, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.