Cross-Domain Feature Expansion for Tabular Medical Data via Knowledge Graphs Injection
Pith reviewed 2026-07-01 06:11 UTC · model grok-4.3
The pith
MedKGTab infers uncollected biomedical features in tabular data by injecting SPOKE knowledge graph correlations into a dual-attention model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedKGTab operates directly on raw structured tabular data using a row-column dual-attention mechanism that captures exact numerical distributions, then modulates the resulting representations with injected biomedical knowledge from the SPOKE graph to ensure generated features respect empirical medical research, yielding high data fidelity in cross-domain feature expansion.
What carries the argument
Row-column dual-attention architecture whose data-channel representations are modulated by SPOKE knowledge graph injection, creating synergy between statistical priors and medical correlations.
If this is right
- MedKGTab can infer missing features within a single medical dataset while preserving numerical distributions.
- The same model generalizes to expand features across different medical cohorts without retraining.
- Generated data achieves higher fidelity than outputs from SOTA medical large models such as Baichuan M3-plus.
- MedKGTab outperforms specialized tabular data-generation models designed for medical use.
- The approach works for both within-domain completion and true cross-domain expansion tasks.
Where Pith is reading between the lines
- The same dual-attention-plus-knowledge-injection pattern could be tested on non-medical tabular domains that have domain-specific graphs available.
- One could measure whether performance scales with the size or coverage of the injected knowledge graph.
- Real-world deployment would require checking that generated features do not create spurious clinical correlations absent from the original data.
- The method suggests hybrid statistical-knowledge models may reduce reliance on large language models for structured data tasks.
Load-bearing premise
The SPOKE biomedical knowledge graph supplies accurate, relevant medical correlations that can be injected into the data channel without introducing bias or inconsistency.
What would settle it
Generate expanded features on a held-out medical cohort and compare their statistical distributions and clinical correlations directly against newly collected real measurements from the same patients.
Figures
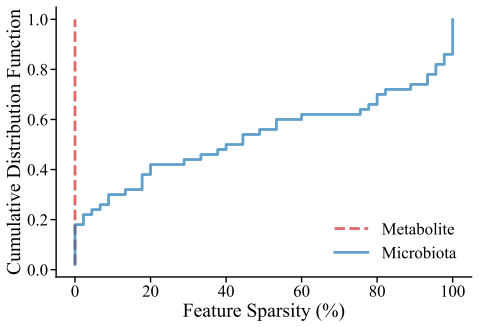
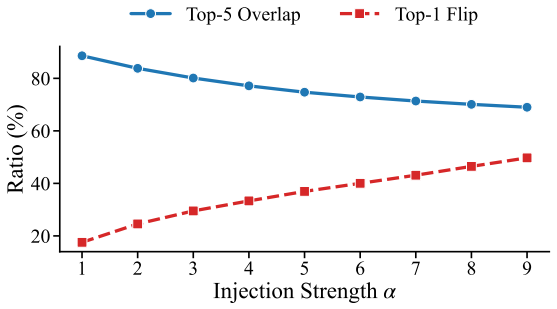
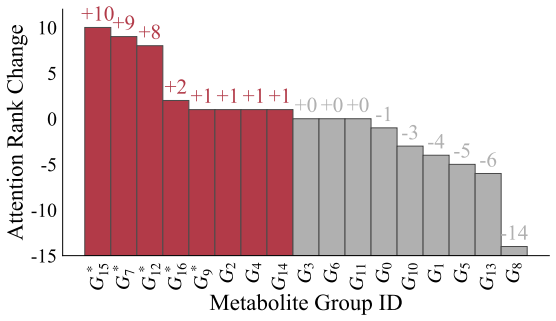
read the original abstract
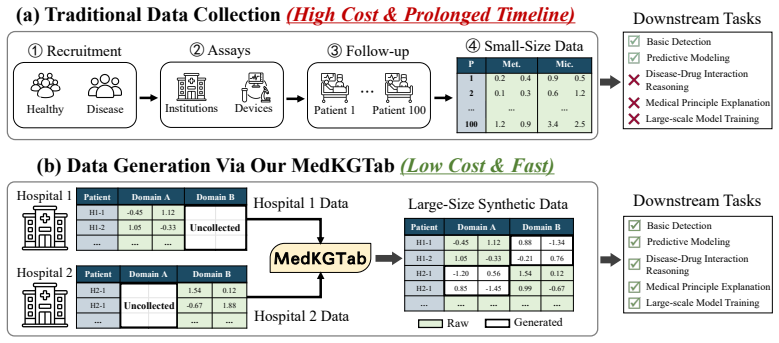
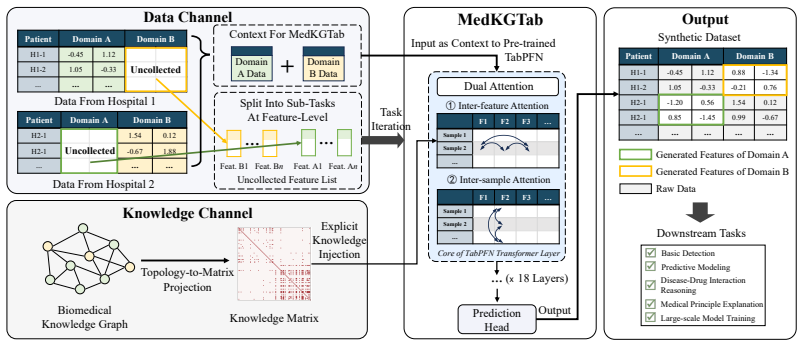
Acquiring comprehensive cross-domain biomedical profiles is often costly and time-consuming, resulting in severe data scarcity in medical research. To address this challenge, we propose MedKGTab, a knowledge-injected framework specifically engineered for cross-domain feature expansion in tabular medical data. MedKGTab seeks to infer uncollected biomedical features from available ones by exploiting their inherent statistical dependencies and established medical correlations. By employing a row-column dual-attention mechanism, MedKGTab operates directly on raw structured tabular data, inherently capturing exact numerical distributions without the structural loss caused by tokenization. Crucially, MedKGTab integrates data-driven statistical priors with the SPOKE biomedical knowledge graph, achieving an optimal synergy between the data and knowledge channels. Within this synergy, the representations derived from the data channel are modulated by the injected biomedical knowledge, ensuring the final generated data are grounded in empirical medical research. Experimental results demonstrate that MedKGTab achieves high data fidelity and realistic data representation in cross-domain feature expansion. It outperforms both SOTA medical large models (e.g., Baichuan M3-plus) and specialized tabular models designed for medical data generation. Furthermore, MedKGTab consistently delivers superior performance across various data generation scenarios, whether inferring missing features within the same dataset or generalizing across different medical cohorts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MedKGTab, a framework for cross-domain feature expansion in tabular medical data. It employs a row-column dual-attention mechanism directly on raw structured data to capture numerical distributions, then injects representations from the SPOKE biomedical knowledge graph to modulate data-driven statistical priors. The central claim is that this produces high-fidelity generated features grounded in empirical medical research, outperforming both SOTA medical LLMs (e.g., Baichuan M3-plus) and specialized tabular models, with consistent superiority whether inferring missing features within a dataset or generalizing across cohorts.
Significance. If the empirical claims hold with rigorous validation, the work could meaningfully address data scarcity in biomedical research by enabling realistic cross-domain feature inference that combines statistical dependencies with established medical correlations. The decision to operate on raw tabular data without tokenization is a clear technical strength that preserves exact numerical properties. However, the absence of any reported metrics, protocols, or ablation results in the abstract makes it impossible to assess whether the claimed data-knowledge synergy delivers measurable gains or merely introduces domain-specific artifacts.
major comments (2)
- [Abstract] Abstract: the abstract asserts 'high data fidelity and realistic data representation' and outperformance over Baichuan M3-plus and specialized tabular models, yet supplies no quantitative metrics (e.g., fidelity scores, distributional distances, downstream task performance), experimental protocols, baseline details, or validation splits; without these the central claim lacks visible empirical support.
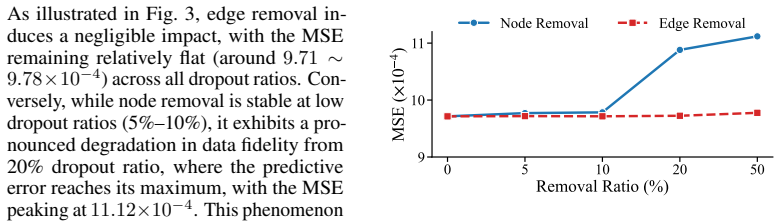
- [Abstract] Abstract (and implied § on knowledge injection): the claimed 'optimal synergy' whereby SPOKE-derived representations modulate dual-attention outputs is asserted without describing the modulation operator, any conflict-resolution rule between statistical priors and KG edges, or an ablation showing that KG injection improves fidelity rather than introducing inconsistencies or bias when generalizing across cohorts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the clarity of our technical claims. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts 'high data fidelity and realistic data representation' and outperformance over Baichuan M3-plus and specialized tabular models, yet supplies no quantitative metrics (e.g., fidelity scores, distributional distances, downstream task performance), experimental protocols, baseline details, or validation splits; without these the central claim lacks visible empirical support.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. The full manuscript reports these details in Sections 4 (experimental setup, baselines including Baichuan M3-plus and tabular models, validation splits) and 5 (fidelity scores, distributional distances, downstream performance). In revision we will condense the key metrics into the abstract while preserving its length. revision: yes
-
Referee: [Abstract] Abstract (and implied § on knowledge injection): the claimed 'optimal synergy' whereby SPOKE-derived representations modulate dual-attention outputs is asserted without describing the modulation operator, any conflict-resolution rule between statistical priors and KG edges, or an ablation showing that KG injection improves fidelity rather than introducing inconsistencies or bias when generalizing across cohorts.
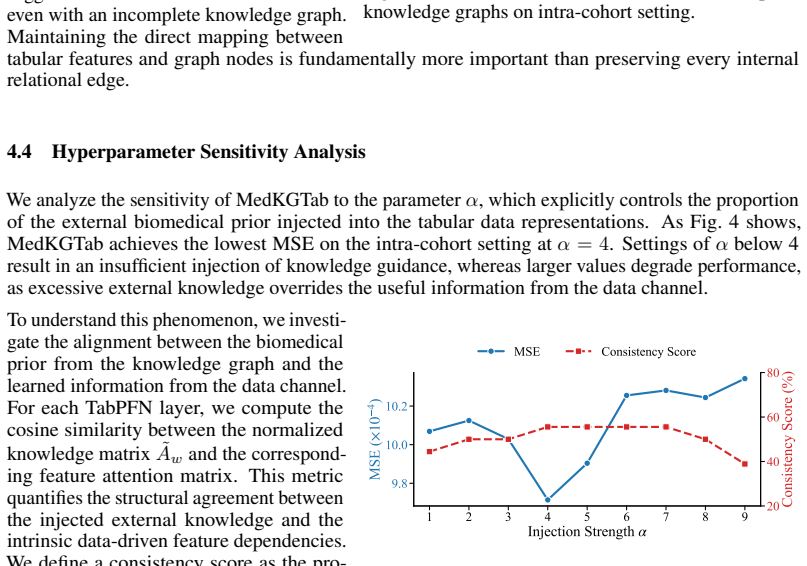
Authors: Section 3.2 defines the modulation operator (element-wise scaling of dual-attention outputs by SPOKE embeddings) and the conflict-resolution rule (attention-weighted fusion that prioritizes KG edges only when statistical priors are weak). Section 5.3 contains the requested ablation across cohorts, showing fidelity gains and no measurable bias increase. To improve visibility we will add one sentence to the abstract summarizing the modulation approach. revision: partial
Circularity Check
No circularity identified from available text
full rationale
The abstract describes integration of data-driven priors with SPOKE KG to achieve synergy and ground generated features, but supplies no equations, derivation steps, fitted parameters presented as predictions, or self-citations. No load-bearing reduction of the central claim to its own inputs by construction is exhibited. The method is presented as a proposed framework whose performance is evaluated externally; the derivation chain remains self-contained against the given material.
Axiom & Free-Parameter Ledger
free parameters (1)
- dual-attention parameters
axioms (1)
- domain assumption SPOKE biomedical knowledge graph encodes accurate and relevant medical correlations usable for feature grounding.
Reference graph
Works this paper leans on
-
[1]
Neural additive models: Interpretable machine learning with neural nets
Rishabh Agarwal, Levi Melnick, Nicholas Frosst, et al. Neural additive models: Interpretable machine learning with neural nets. InProc. of NeurIPS, 2021
2021
-
[2]
Walker, et al
Cengiz Atasoglu, Carmen Valdés, Nicola D. Walker, et al. De novo synthesis of amino acids by the ruminal bacteria Prevotella bryantii B14, Selenomonas ruminantium HD4, and Streptococcus bovis ES1.Applied and Environmental Microbiology, 64(8):2836–2843, 1998
1998
-
[3]
Efi Athieniti and George M. Spyrou. A guide to multi-omics data collection and integration for translational medicine.Computational and Structural Biotechnology Journal, 21:134–149, 2023
2023
-
[4]
Danets: Deep abstract networks for tabular data classification and regression
Jintai Chen, Kuanlun Liao, Yao Wan, et al. Danets: Deep abstract networks for tabular data classification and regression. InProc. of AAAI, 2022
2022
-
[5]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProc. of SIGKDD, 2016
2016
-
[6]
Medtranstab: Advancing medical cross-table tabular data generation
Yuyan Chen, Qingpei Guo, Shuangjie You, et al. Medtranstab: Advancing medical cross-table tabular data generation. InProc. of WSDM, 2025
2025
-
[7]
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Zeming Chen, Alejandro Hernández-Cano, Angelika Romanou, et al. Meditron-70b: Scaling medical pretraining for large language models.arXiv preprint arXiv:2311.16079, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
GRAM: graph-based attention model for healthcare representation learning
Edward Choi, Mohammad Taha Bahadori, Le Song, et al. GRAM: graph-based attention model for healthcare representation learning. InProc. of KDD, 2017
2017
-
[9]
Chengfeng Dou, Fan Yang, Fei Li, et al. Baichuan-m3: Modeling clinical inquiry for reliable medical decision-making.arXiv preprint arXiv:2602.06570, 2026
-
[10]
TABGEN-ICL: residual-aware in-context example selection for tabular data generation
Liancheng Fang, Aiwei Liu, Hengrui Zhang, et al. TABGEN-ICL: residual-aware in-context example selection for tabular data generation. InFindings of ACL, 2025
2025
-
[11]
Distinct genetic and functional traits of human intestinal Prevotella copri strains are associated with different habitual diets.Cell Host & Microbe, 25(3):444–453.e3, 2019
Francesca De Filippis, Edoardo Pasolli, Adrian Tett, et al. Distinct genetic and functional traits of human intestinal Prevotella copri strains are associated with different habitual diets.Cell Host & Microbe, 25(3):444–453.e3, 2019
2019
-
[12]
Xiao Gai, Peng Qian, Benqiong Guo, et al. Heptadecanoic acid and pentadecanoic acid crosstalk with fecal-derived gut microbiota are potential non-invasive biomarkers for chronic atrophic gastritis.Frontiers in Cellular and Infection Microbiology, 12:1064737, 2023
2023
-
[13]
Tabr: Tabular deep learning meets nearest neighbors
Yury Gorishniy, Ivan Rubachev, Nikolay Kartashev, et al. Tabr: Tabular deep learning meets nearest neighbors. InProc. of ICLR, 2024
2024
-
[14]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, et al. Revisiting deep learning models for tabular data. InProc. of NeurIPS, 2021
2021
-
[15]
Why do tree-based models still outperform deep learning on typical tabular data? InProc
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? InProc. of NeurIPS, 2022
2022
-
[16]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8044):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, et al. Accurate predictions on small data with a tabular foundation model.Nature, 637(8044):319–326, 2025
2025
-
[17]
Kegg: kyoto encyclopedia of genes and genomes.Nucleic acids research, 28(1):27–30, 2000
Minoru Kanehisa and Susumu Goto. Kegg: kyoto encyclopedia of genes and genomes.Nucleic acids research, 28(1):27–30, 2000
2000
-
[18]
Tabddpm: Modelling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, et al. Tabddpm: Modelling tabular data with diffusion models. InProc. of ICML, 2023
2023
-
[19]
InFindings of the Association for Com- putational Linguistics: ACL 2023, pages 8003–8017
Yanis Labrak, Adrien Bazoge, Emmanuel Morin, et al. Biomistral: A collection of open-source pretrained large language models for medical domains.arXiv preprint arXiv:2402.10373, 2024
-
[20]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProc. of ACL, 2021. 10
2021
-
[21]
Yunxiang Li, Zihan Li, Kai Zhang, et al. Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge.arXiv preprint arXiv:2303.14070, 2023
-
[22]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Talent: A tabular analytics and learning toolbox
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, et al. Talent: A tabular analytics and learning toolbox. Journal of Machine Learning Research, 26(226):226:1–226:16, 2025
2025
-
[24]
Lalani, and Mohan Pammi
Srinivasan Mani, Seema R. Lalani, and Mohan Pammi. Genomics and multiomics in the age of precision medicine.Pediatric Research, 97(4):1399–1410, 2025
2025
-
[25]
Morris, Karthik Soman, Rabia E
John H. Morris, Karthik Soman, Rabia E. Akbas, et al. The scalable precision medicine open knowledge engine (SPOKE): a massive knowledge graph of biomedical information. Bioinformatics, 39(2), 2023
2023
-
[26]
The synthetic data vault
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. The synthetic data vault. InProc. of DSAA, 2016
2016
-
[27]
Curated LLM: Synergy of LLMs and data curation for tabular augmentation in low-data regimes
Nabeel Seedat, Nicolas Huynh, Boris van Breugel, et al. Curated LLM: Synergy of LLMs and data curation for tabular augmentation in low-data regimes. InProc. of ICML, 2024
2024
-
[28]
Towards Expert-Level Medical Question Answering with Large Language Models
Karan Singhal, Shekoofeh Azizi, Tao Tu, et al. Towards expert-level medical question answering with large language models.arXiv preprint arXiv:2305.09617, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
A data-efficient strategy for building high-performing medical foundation models.Nature Biomedical Engineering, 9:539–551, 2025
Yuqi Sun, Weimin Tan, Zhuoyao Gu, et al. A data-efficient strategy for building high-performing medical foundation models.Nature Biomedical Engineering, 9:539–551, 2025
2025
-
[30]
Undisclosed, unmet and neglected challenges in multi-omics studies.Nature Computational Science, 1(6):395–402, 2021
Sonia Tarazona, Angeles Arzalluz-Luque, and Ana Conesa. Undisclosed, unmet and neglected challenges in multi-omics studies.Nature Computational Science, 1(6):395–402, 2021
2021
-
[31]
Towards generalist biomedical AI.arXiv preprint arXiv:2307.14334, 2023
Tao Tu, Shekoofeh Azizi, Hyung Won Chung, et al. Towards generalist biomedical AI.arXiv preprint arXiv:2307.14334, 2023
-
[32]
Eegdiffuser: Label-guided eeg signals synthesis via diffusion model for bci applications.Neurocomputing, 670:132636, 2026
Jiquan Wang, Sha Zhao, Zhiling Luo, et al. Eegdiffuser: Label-guided eeg signals synthesis via diffusion model for bci applications.Neurocomputing, 670:132636, 2026
2026
-
[33]
Data whisperer: Efficient data selection for task-specific LLM fine-tuning via few-shot in-context learning
Shaobo Wang, Xiangqi Jin, Ziming Wang, et al. Data whisperer: Efficient data selection for task-specific LLM fine-tuning via few-shot in-context learning. InProc. of ACL, 2025
2025
-
[34]
Meditab: Scaling medical tabular data predictors via data consolidation, enrichment, and refinement
Zifeng Wang, Chufan Gao, Cao Xiao, et al. Meditab: Scaling medical tabular data predictors via data consolidation, enrichment, and refinement. InProc. of IJCAI, 2024
2024
-
[35]
Wright, Catriona G
Damian P. Wright, Catriona G. Knight, Shanthi G. Parkar, et al. Cloning of a mucin-desulfating sulfatase gene from Prevotella strain RS2 and its expression using a Bacteroides recombinant system.Journal of Bacteriology, 182(11):3002–3007, 2000
2000
-
[36]
Wright, Douglas I
Damian P. Wright, Douglas I. Rosendale, and Anthony M. Roberton. Prevotella enzymes involved in mucin oligosaccharide degradation and evidence for a small operon of genes expressed during growth on mucin.FEMS Microbiology Letters, 190(1):73–79, 2000
2000
-
[37]
Switchtab: Switched autoencoders are effective tabular learners
Jing Wu, Suiyao Chen, Qi Zhao, et al. Switchtab: Switched autoencoders are effective tabular learners. InProc. of AAAI, 2024
2024
-
[38]
Modeling tabular data using condi- tional GAN
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, et al. Modeling tabular data using condi- tional GAN. InProc. of NeurIPS, 2019
2019
-
[39]
Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later
Han-Jia Ye, Huai-Hong Yin, De-Chuan Zhan, et al. Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later. InProc. of ICLR, 2025. 11 A Appendix A.1 Prompt Templates for LLM-based Baselines To facilitate reproducibility, we detail the prompt templates utilized for the LLM-based baselines. As discussed in the main text, we com...
2025
-
[40]
Each real sample is a JSON object containing BOTH metabolite fields and microbiota fields
Analyze the provided real samples carefully. Each real sample is a JSON object containing BOTH metabolite fields and microbiota fields
-
[41]
When given metabolite-only samples, infer and generate the missing microbiota fields based on patterns learned from the real samples
-
[42]
Maintain realistic relationships/correlations between metabolite and microbiota fields as reflected in the real samples. IMPORTANT (must-follow): - For each metabolite-only sample, you MUST copy the metabolite fields and their values EXACTLY as provided. Do NOT change, normalize, round, reorder, rename, or regenerate metabolite values. - ONLY generate the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.