Sifei at SemEval-2026 Task 8: Hybrid Retrieval and Query Rewriting for Multi-Turn RAG
Pith reviewed 2026-06-30 10:45 UTC · model grok-4.3
The pith
A training-free hybrid retrieval pipeline with dense-sparse fusion and query rewriting outperforms baselines on multi-turn RAG queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
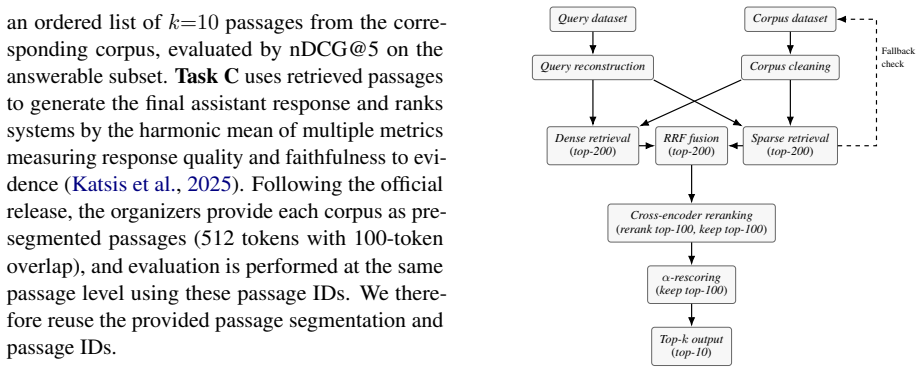
The authors show that combining dense retrieval, sparse retrieval, controlled query rewriting, and cross-encoder reranking produces a retrieval pipeline that ranks third on the SemEval-2026 Task 8 test set with an nDCG@5 of 0.5453, exceeding the strongest baseline score of 0.4795, while the same passages support a generation stage that scores 0.5312 on the harmonic mean of relevance and faithfulness.
What carries the argument
Hybrid retrieval pipeline that fuses dense retrieval, sparse retrieval, controlled query rewriting, and cross-encoder reranking to track evolving user intent across conversation turns.
If this is right
- Dense-plus-sparse fusion plus rewriting reduces the impact of conversational noise on retrieval quality.
- Reusing the same retrieved passages for generation preserves both relevance and faithfulness without extra retrieval cost.
- All retrieval components being open-source allows direct reuse on other multi-turn datasets.
- The pipeline respects strict context limits by limiting the number of passages passed downstream.
- Ranking third among 38 teams indicates the method is competitive with other submitted systems on this task distribution.
Where Pith is reading between the lines
- The training-free design suggests the same components could be swapped into other conversational search settings with minimal adaptation.
- Query rewriting appears to be the main lever for handling intent drift, so isolating its contribution on additional datasets would be a direct next measurement.
- Because retrieval is decoupled from generation, the approach could be paired with different language models without retraining the retriever.
- The gap over the baseline implies that hybrid methods may close performance differences that single-retriever baselines leave on noisy dialogues.
Load-bearing premise
The chosen mix of dense and sparse search plus rewriting will handle shifts in user intent and conversational noise more effectively than the baseline on the SemEval-2026 Task 8 data.
What would settle it
A new test collection of multi-turn queries on which the same pipeline scores below 0.4795 nDCG@5 would show the performance gain does not hold.
Figures
read the original abstract
Multi-turn retrieval-augmented generation (RAG) is challenging due to evolving user intent, conversational noise, and strict context limits. We propose a training-free hybrid retrieval pipeline for SemEval-2026 Task 8 that combines dense and sparse retrieval with controlled query rewriting and cross-encoder reranking. On the official test set of Task A, our system achieves 0.5453 nDCG@5, ranking third among 38 teams and outperforming the strongest baseline score of 0.4795. For Task C, we reuse the documents retrieved for Task A and apply a lightweight generation pipeline guided by the official prompt, achieving 0.5312 as the harmonic mean of relevance and faithfulness and ranking 15th among 29 teams. All retrieval components are open-source, while query rewriting and answer generation rely on LLM APIs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports Sifei's system for SemEval-2026 Task 8 on multi-turn RAG. It describes a training-free hybrid pipeline that combines dense and sparse retrieval, controlled query rewriting, and cross-encoder reranking. On the official Task A test set the system obtains 0.5453 nDCG@5 (3rd of 38 teams), exceeding the strongest baseline of 0.4795. For Task C the same retrieved documents are fed to a lightweight LLM generation stage, yielding a harmonic mean of relevance and faithfulness of 0.5312 (15th of 29 teams). Retrieval components are stated to be open-source.
Significance. If the reported scores are reproducible, the work supplies a concrete, competitive empirical result on a shared-task benchmark that isolates the contribution of a hybrid retrieval-plus-rewriting pipeline to conversational retrieval. The explicit release of the retrieval modules is a modest but useful community contribution. Because the paper is a system description rather than a methodological advance, its longer-term significance rests on whether the combination generalizes beyond the 2026 Task 8 data distribution.
minor comments (2)
- The abstract and introduction should explicitly state the exact dense and sparse retrievers (model names, indexes) and the query-rewriting prompt template so that the 0.5453 nDCG@5 figure can be reproduced from the open-source retrieval code alone.
- Section describing Task C should clarify whether any additional retrieval or rewriting occurs or whether the documents are used exactly as returned for Task A; the current wording leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation to accept. The report contains no major comments requiring point-by-point response.
Circularity Check
No significant circularity
full rationale
The manuscript is a purely empirical shared-task report describing a training-free hybrid retrieval pipeline and its measured nDCG@5 and harmonic-mean scores on the official SemEval-2026 test sets. No equations, derivations, fitted parameters, or predictions are presented; performance figures are direct experimental outcomes rather than reductions of any internal model. No self-citations are invoked to justify uniqueness or load-bearing premises. The work is therefore self-contained against external benchmarks with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Engineering and Applied Sciences Technology , year=
Optimizing RAG with Hybrid Search and Contextual Chunking , author=. Journal of Engineering and Applied Sciences Technology , year=
-
[2]
2024 , eprint=
Multi-Reranker: Maximizing performance of retrieval-augmented generation in the FinanceRAG challenge , author=. 2024 , eprint=
2024
-
[3]
2025 , url =
Zhiyu Chen and Biancen Xie and Sidarth Srinivasan and Qun Liu and Manikandarajan Ramanathan and Raj Maragoud , title =. 2025 , url =
2025
-
[4]
Transactions of the Association for Computational Linguistics , volume =
Katsis, Yannis and Rosenthal, Sara and Fadnis, Kshitij and Gunasekara, Chulaka and Lee, Young-Suk and Popa, Lucian and Shah, Vraj and Zhu, Huaiyu and Contractor, Danish and Danilevsky, Marina , title =. Transactions of the Association for Computational Linguistics , volume =. 2025 , month =. doi:10.1162/TACL.a.19 , url =
-
[5]
2025 , eprint=
Jasper-Token-Compression-600M Technical Report , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
HyPA-RAG: A Hybrid Parameter Adaptive Retrieval-Augmented Generation System for AI Legal and Policy Applications , author=. 2025 , eprint=
2025
-
[7]
2024 , eprint=
Searching for Best Practices in Retrieval-Augmented Generation , author=. 2024 , eprint=
2024
-
[8]
2025 , eprint=
Hybrid AI for Responsive Multi-Turn Online Conversations with Novel Dynamic Routing and Feedback Adaptation , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
Meta-Chunking: Learning Text Segmentation and Semantic Completion via Logical Perception , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Reconstructing Context: Evaluating Advanced Chunking Strategies for Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[11]
arXiv preprint arXiv:2502.13595 (2025) https://doi.org/10.48550/arXiv.2502.13595
Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and Márton Kardos and Ashwin Mathur and David Stap and Jay Gala and Wissam Siblini and Dominik Krzemiński and Genta Indra Winata and Saba Sturua and Saiteja Utpala and Mathieu Ciancone and Marion Schaeffer and Gabriel Sequeira and Diganta Misra and Shreeya Dhakal and Jonathan Rystrøm and Roman Solomatin...
-
[12]
2024 , eprint=
SPLADE-v3: New baselines for SPLADE , author=. 2024 , eprint=
2024
-
[13]
2025 , eprint=
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author=. 2025 , eprint=
2025
-
[14]
2026 , eprint=
MTRAG-UN: A Benchmark for Open Challenges in Multi-Turn RAG Conversations , author=. 2026 , eprint=
2026
-
[15]
Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , address=
SemEval-2026 Task 8: MTRAGEval: Evaluating Multi-Turn RAG Conversations , author=. Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , address=. 2026 , organization=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.